Overview
모놀리식 시스템에서 데이터 조회를 어떻게 할 지 고민해본 적 있을까, 없다! 왜냐면 모놀리식 시스템에는 모든 데이터가 하나의 데이터베이스에 모두 존재하기 때문이다.
클라이언트가 API를 호출하면 필요로하는 데이터를 join해 잘 담아서 json 형태로 응답을 넣어주면 된다.
하지만 MSA로 설계, 개발할 경우 이마저도 고민이 된다. 데이터베이스가 쪼개진 마이크로서비스만큼 N개 존재하여 DB단에서 Join이 불가능하고 데이터가 분산되어있기 때문이다.
우리가 해봐야하는 고민
SW마에스트로에서 MSA로 설계 개발하여 다음과 같은 고민에 부딪혔다.
현재 상황은 이벤트스토밍을 활용하여 마이크로서비스를 도출하였다. 각 마이크로서비스는 바운디드 컨텍스트 단위로 쪼개져 있고 그 안에서 애그리거트에 해당하는 데이터에 대한 책임을 가지고 있다. 애그리거트 패턴 원칙에 따라 애그리거트끼리는 직접 참조하지 않고 기본키로 간접참조를 하였으며 하나의 트랜잭션에서는 하나의 애그리거트만 처리하도록, 즉 두개 이상의 애그리거트를 동시에 처리하지 않도록 한다.
포인트 애그리거트와 스탬프 애그리거트가 있다.
클라이언트가 포인트와 스탬프를 동시에 하나의 컴포넌트에 보여주고자 한다면 API 설계를 어떻게 해야할까?? 라는 고민이다.
가장 쉽고 편리한 방법은 클라이언트가 포인트 조회 API와 스탬프 조회 API를 두번 호출하는 방법이겠다. 하지만 이 방법은 문제점이 딱봐도 보인다. API를 2개만 호출하면 그나마 다행이지만 상황에 따라 더 많은 API를 호출해야할 수있고 이 과정에서 클라이언트는 자기가 필요한 데이터 뿐만 아니라 불필요한 데이터도 다수 받게 되며 이 과정에서 불필요한 네트워크 리소스를 낭비한다는 점이다.
다음은 카카오 기술블로그에서 퍼온 불필요한 데이터 json 예시이다.
// GET/user/get_profile
{
message: "성공"
profile: {
uid: 1234,
nickname: "치즈",
email: "cheese@test.com",
create_dt: "1995-01-31 00:00:00" // 실제 화면에는 필요하지 않은 값
user_id: "5678" // 실제 화면에는 필요하지 않은 값
}
response_time: "2022-03-03 17:49:39" // 실제 화면에는 필요하지 않은 값
result_code: 0
}
// GET/store/view/cash
{
total_balance: 37560
message: "성공"
response_time: "2022-03-03 17:49:39" // 실제 화면에는 필요하지 않은 값
result_code: 0
}이와 같은 고민에 대해 어떻게 해결할 수 있을까 방법을 알아보았고 API Composition Pattern과 CQRS Pattern가 있음을 알게됐다.
우리는 그 중 API Composition Pattern으로 문제를 해결했으나 그 외에 패턴도 알아보겠다!
1. API Composition Pattern
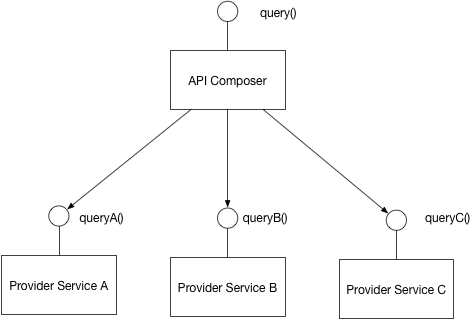
API Composition Pattern이란 이름에서 유추가 가능하듯이 API를 결합해주는 레이어를 앞에 두고 각각의 서비스에서 필요한 데이터를 가져와 리턴해주는 패턴이다.
클라이언트가 하나의 API 리퀘스트를 보내면 Composer가 각 서비스들로 요청을 보내 응답을 모아서 하나로 받아 응답으로 보내주는 것이다.
장점
- 같은 네트워크 상이기에 인터넷 상에서 각각 가져오는 것보다 속도가 빠르다.
- request 횟수를 줄일 수 있다.
단점
- 대규모 데이터를 조합할 때 해당 패턴을 사용하면
N + 1과 유사한 문제나 심각한 메모리 내 조인 문제를 불러올 수 있다.
우리도 무언가 페이징하는 과정에서 해당 패턴을 적용했는데 N + 1 과 같이 여러번 쿼리를 날리는 문제점이 있었다.
2. CQRS Pattern
CQRS는 Command Query Responsibility Segregation 의 약자로 단어 그대로 해석하면 "명령 조회 책임 분리"이다. 쉽게 이해하면 CQRS 패턴이란 CRUD 연산이 있다고 하면 CUD와 R의 책임을 분리하는 패턴이다.
CQRS에서 명령은 시스템의 상태를 변경하는 작업을 의미하며 조회는 시스템의 상태를 반환하는 작업을 의미한다.
조회용 마이크로서비스를 별도로 구현하고 "명령" 은 각 마이크로서비스에서 수행, 각 명령에 대한 이벤트를 조회용 마이크로서비스에 받아 갱신하여 사용자가 "조회" 를 요청하면 조회용 마이크로서비스에서 Join해서 보여주는 형태이다.
CQRS 패턴의 장점 중 하나는 명령과 조회의 책임을 물리적으로 분리할 경우 명령에는 NoSQL을, 조회에는 RDB를 사용하는 형태로 각각의 책임에 최적화된 DB를 선택해서 사용할 수 있다는 것이다.
예시
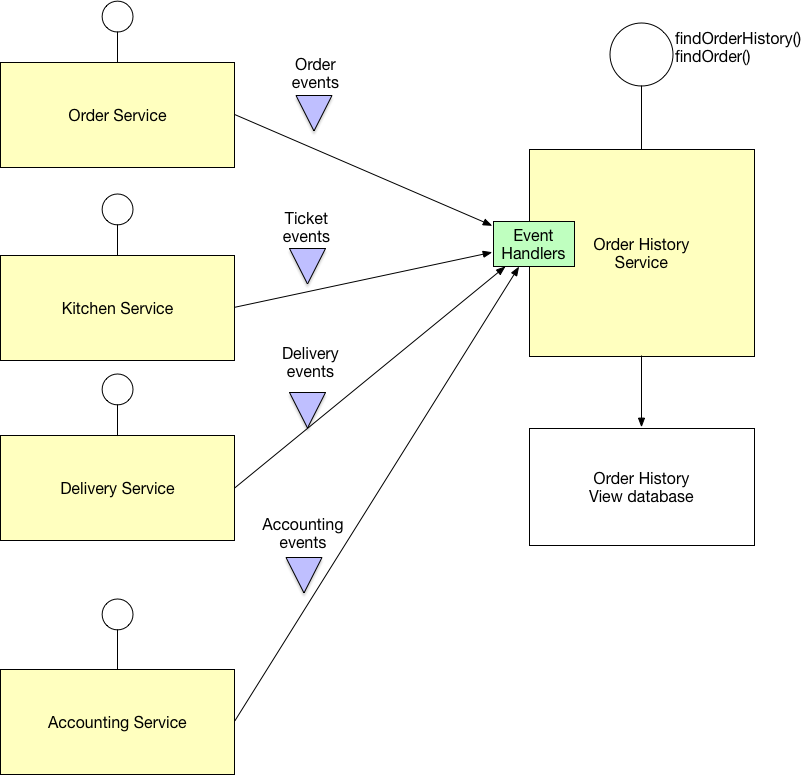
microservices.io에서 퍼온 이미지이다. Order, Kitchen, Delivery 등 다양한 서비스에서 CUD 명령을 수행하고 그에 대한 이벤트를 Order History Service라는 조회용 서비스에 전달해 갱신한다.
Order History Service는 자신이 책임지는 디비에 모든 데이터를 가지고 있으므로 필요에 따라 join하여 사용자에게 보여줌으로써 문제를 해결할 수 있다.
딱봐도 유의해야할 점이 보인다. CUD 명령이 수행됐다고 바로 조회가 될 것 같지 않다. 분산 시스템 환경에서는 결과적 일관성을 고려해야한다.
분산 시스템 환경에서는 결과적 일관성을 고려해야한다.
너무나도 좋은 게시글이 있어 공유로 대체하겠다!
참고자료
https://fe-developers.kakaoent.com/2022/220310-kakaopage-bff/
