본 내용은 빅데이터를 지탱하는 기술 (니시다 케이스케) 책을 정리한 내용입니다.
Chapter 2 빅데이터의 탐색 2-1 ~ 2-2

2-1 크로스 집계의 기본
데이터 집계 -> 데이터 마트 -> 시각화
데이터의 집계와 시각화 사이에 있는 것이 데이터 마트다.
- 데이터 마트가 작을수록
- 시각화하는 것이 간단해짐.
- 원래 데이터에 포함된 정보를 잃어버리게 되어 시각화 프로세스에서 할 수 있는 일이 적어짐.
- 피벗 테이블과 BI 도구를 사용해 대화적인 데이터 검색한다면, 정보 부족으로 곤란한 상황 발생
- 데이터 집계의 프로세스에서 많은 정보를 남기게 되면
- 데이터 마트가 거대화되어 좋은 시각화를 할 수 없음
이는 Trade off의 관계에 있으며, 필요에 따라 어느 정도의 정보를 남길 것인가를 결정해야 한다.
즉, 데이터 마트의 크기에 따라 시스템 구성이 결정된다.
2-2 열 지향 스토리지에 의한 고속화
메모리에 다 올라가지 않을 정도의 대량의 데이터를 신속하게 집계하려면, 미리 데이터를 집계에 적합한 형태로 변환하는 것이 필요하다.
데이터베이스의 지연을 줄이기
데이터양이 증가함에 따라 집계에 걸리는 시간은 길어진다.
3계층의 데이터 집계 시스템
- 데이터 레이크 -> 데이터 마트 -> 시각화 도구
- 원 데이터는 용량적인 제약이 적어서 대량의 데이터를 처리할 수 있는 데이터 레이크와 데이터 웨어하우스에 저장한다.
- 거기에서 원하는 데이터를 추출하여 데이터 마트를 구축하고 여기에서는 항상 초 단위의 응답을 얻을 수 있도록 한다.
데이터 처리의 지연
데이터 처리의 응답이 빠르다는 것은 '대기시간이 적다', '지연이 적다'라고 한다.
데이터 마트를 만들 때는 가급적 지연이 적은 데이터베이스가 있어야 한다. 크게 두 가지 선택이 있다.
1. 모든 데이터를 메모리에 올리는 것
- 만일 한 레코드 크기가 500byte라고 하면 천만 레코드는 5GB가 된다. 이 정도는 MySQL이나 PostgreSQL 등의 일반적인 RDB가 데이터 마트에 적합하다.
- RDB는 원래 지연이 적고, 많은 수의 클라이언트가 동시 접속해도 성능이 나빠지지 않으므로 많은 사용자가 사용하는 실제 운영 환경의 데이터 마트로 특히 우수하다.
- but RDB는 메모리가 부족하면 급격히 성능이 떨어진다.
2. '압축'과 '분산'에 의해 지연 줄이기 - MPP 기술
- 고속화를 위해 사용되는 기법이 '압축'과 '분산'이다. 데이터를 가능한 한 작게 압축하고 그것을 여러 디스크에 분산함으로써 데이터 로드에 따른 지연을 줄인다.
- 분산된 데이터를 읽어 들이려면 멀티 코어를 활용하면서 디스크 I/O를 병렬 처리하는 것이 효과적이다.
- 이러한 아키텍쳐를 MPP(massive parallel processing, 대규모 병렬 처리)라고 부르며 대량의 데이터를 분석하기 위해 데이터베이스에서 널리 사용되고 있다. (ex. Amazon Redshift, Google BigQuery)
- MPP는 데이터 집계에 최적화되어 있으며, 데이터 웨어하우스와 데이터 분석용의 데이터베이스에서 특히 많이 사용된다.
열 지향 데이터베이스 접근
행 지향 데이터베이스
빅데이터로 취급되는 데이터 대부분은 디스크 상에 있기 때문에 쿼리에 필요한 최소한의 데이터만을 가져옴으로써 지연이 줄어들게 된다. 이를 위해 사용되는 방법이 '칼럼 단위로의 데이터 압축'이다. 이를 '행 지향 데이터베이스(row-oriented database)'라고 부른다.
Oracle Database, MySQL 같은 일반적인 RDB는 행 지향 데이터베이스이다.
- 행 지향 데이터베이스에서는 테이블의 각 행을 하나의 덩어리로 디스크에 저장한다.
- 새 레코드를 추가할 때, 파일의 끝에 데이터를 쓸 뿐이므로 빠르게 추가할 수 있다.
- 매일 발생하는 대량의 트랜잭션을 지연없이 처리하기 위해 데이터 추가를 효율적으로 하는 것이 특징이다.
- 데이터 검색을 고속화하기 위해 Index를 만든다.
- but 데이터 분석에는 어떤 칼럼이 사용되는지 미리 알 수 없기에 Index가 도움이 되지 않는다. 필연적으로 대량의 데이터 분석은 항상 디스크 I/O를 동반한다. 따라서 인덱스에 의지하지 않는 고속화 기술이 필요하다.
열 지향 데이터베이스
데이터 분석에 사용되는 데이터베이스는 칼럼 단위의 집계에 최적화되어 있으며, '열 지향 데이터베이스(column-oriented databse)' 또는 '칼럼 지향 데이터베이스(columnar database)'라고 한다.
Teradata, Amazon Redshint 등이 열 지향 데이터베이스이다.
- 데이터를 미리 칼럼 단위로 정리해둠으로써 필요한 칼럼만을 로드하여 데이터 I/O를 줄인다.
- 데이터의 압축 효율이 우수하다. 데이터의 종류에 따라 다르지만, 압축되지 않은 행 지향 데이터베이스와 비교하면 1/10 이하로 압축할 수 있다.
MPP 데이터베이스의 접근 방식
쿼리 지연을 줄일 또 다른 방법은 MPP 아키텍쳐에 의한 데이터 처리의 병렬화다.
- 행 지향 데이터베이스에서
- 보통 하나의 쿼리는 하나의 스레드에서 실행된다. 많은 쿼리를 동시에 실행함으로써 여러 개의 CPU 코어를 활용할 수 있지만, 개별 쿼리가 분산 처리되는 것은 아니다.
- 각 쿼리는 짧은 시간에 끝나는 것으로 생각하므로, 하나의 쿼리를 분산 처리하는 상황은 가정하지 않는다.
- 열 지향 데이터베이스에서
- 디스크에서 대량의 데이터를 읽기 때문에 1번의 쿼리 실행 시간이 길어진다.
- 압축된 데이터의 전개 등으로 CPU 리소스를 필요로 하므로 멀티 코어를 활용하여 고속화하는 것이 좋다.
MPP에서는 하나의 쿼리를 다수의 작은 task로 분해하고 이를 가능한 한 병렬로 실행한다.
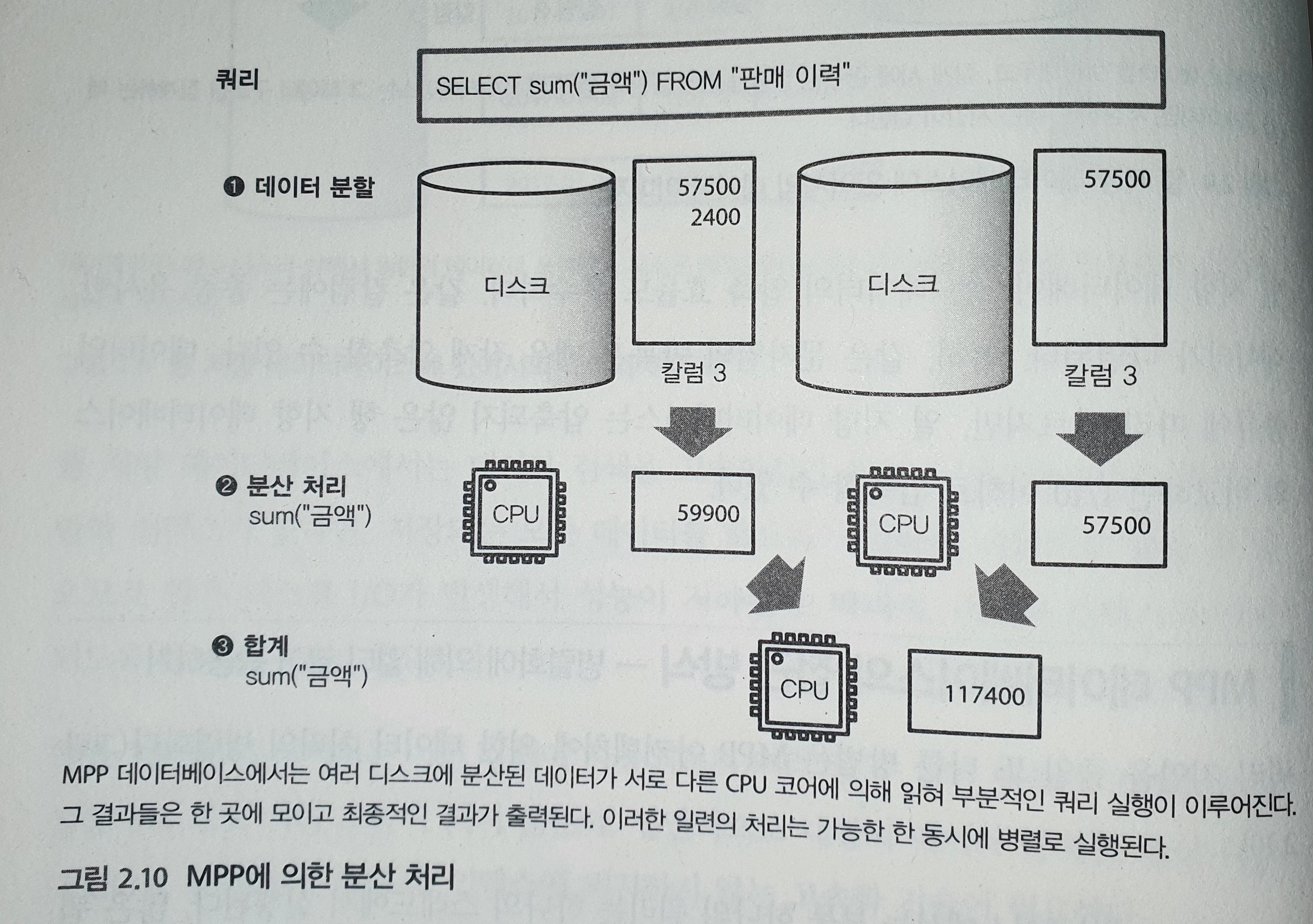
MPP 데이터베이스와 대화형 쿼리 엔진
쿼리가 잘 병렬화할 수 있다면, MPP를 사용한 데이터의 집계는 CPU 코어 수에 비례하여 고속화된다.
단, 디스크로부터 로드가 병목 현상이 발생하지 않도록 데이터가 고르게 분산되어야 한다.
하드웨어 수준에서 데이터 집계에 최적화된 데이터베이스를 MPP 데이터베이스라고 한다.
MPP의 아키텍처는 Hadoop과 함께 사용되는 대화형 쿼리 엔진으로도 채택되고 있다. 이 경우 데이터를 저장하는 것은 분산 스토리지의 역할이다. 그러나 데이터를 열 지향으로 압축하지 않는 한 MPP 데이터베이스와 동등한 성능은 되지 못한다. 그래서 Hadoop 상에서 열 지향 스토리지를 만들기 위해 여러 라이브러리가 개발되고 있다.
수억 레코드를 초과하는 데이터 마트의 지연을 작게 유지하기 위해서는 데이터를 열 지향의 스토리지 형식으로 저장해야 한다.
