
✏️ 주요 용어
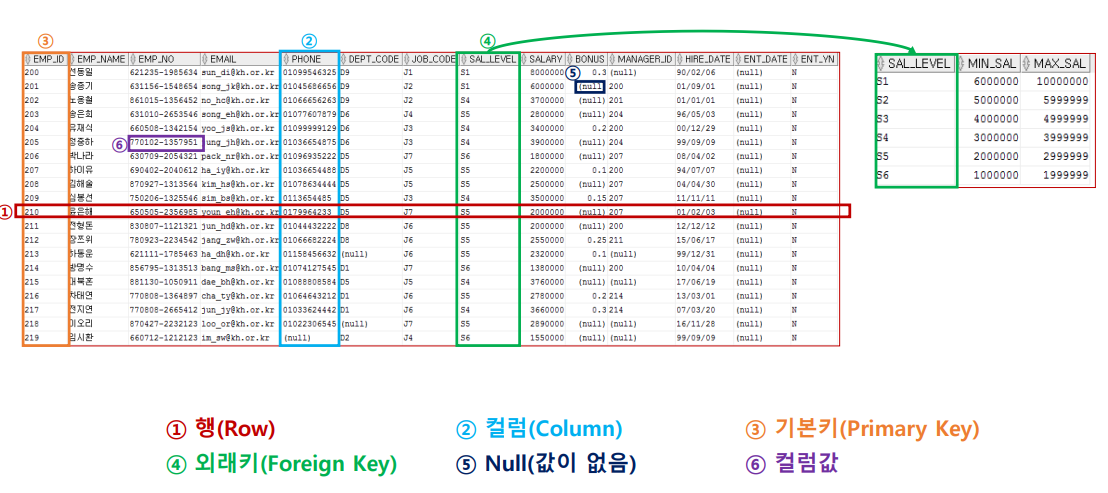
📝 SQL(Structured Query Language)
관계형 데이터베이스에서 데이터를 조회하거나 조작하기 위해 사용하는 표준 검색 언어
-> 원하는 데이터를 찾는 방법이나 절차를 기술하는 것이 아닌 조건을 기술하여 작성
| 분류 | 용도 | 명령어 |
|---|---|---|
| DQL(Data Query Language) | 데이터 검색 | SELECT (SELECT는 DML로도 분류됨) |
| DML(Data Manipulation Language) | 데이터 조작 | INSERT, UPDATE, DELETE |
| DDL(Data Definition Language) | 데이터 정의 | CREATE, DROP, ALTER |
| DCL(Data Control Language) | 데이터 제어 | GRANT, REVOKE |
| TCL(Transaction Control Language) | 트랜젝션 제어 | COMMIT, ROLLBACK |
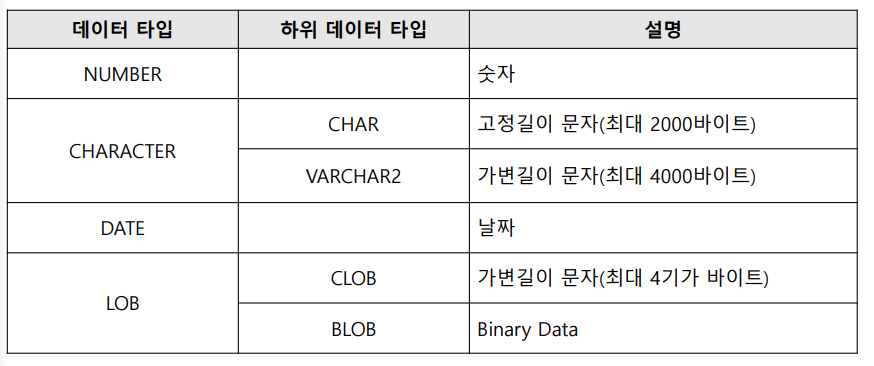
✏️ 주요 데이터 타입
📝 DQL
💡 SELECT
데이터 조회
- 데이터를 조회(SELECT)하면 조건에 맞는 행들이 조회됨
-> 이때, 조회된 행들의 집합을 "RESULT SET"이라고 함- RESULT SET에는 0개 이상의 행이 포함될 수 있음
-> 왜? 조건이 맞는 행이 없을 수도 있기 때문에
다양한 예제를 통해 SELECT 사용법을 알아보자.
✏️ SELECT 알아보기
- EMPLOYEE
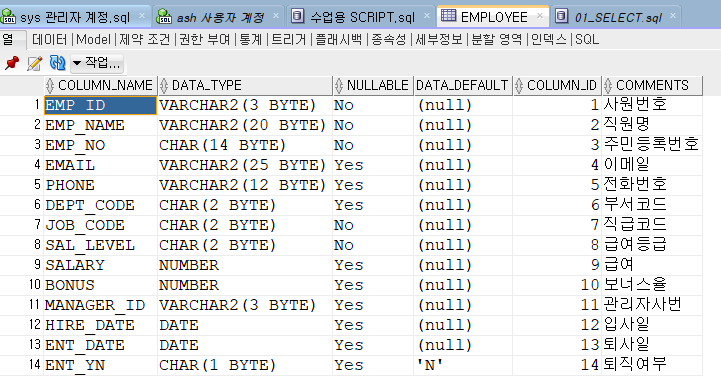
- 01_SELECT.sql
/* SELECT (DML 또는 DQL) : 조회 */
-- EMPLOYEE 테이블에서 모든 사원의 정보를 조회
-- '*' : ALL, 모든, 전부
SELECT * FROM EMPLOYEE;
-- [ SELECT 컬럼명 FROM 테이블명]
-- EMPLOYEE 테이블에서 모든 사원의 이름만 조회
SELECT EMP_NAME FROM EMPLOYEE;
-- [ SELECT 컬럼명, 컬럼명, .... FROM 테이블명]
-- EMPLOYEE 테이블에서 모든 사원의 사번, 이름, 전화번호 조회
SELECT EMP_ID, EMP_NAME, PHONE FROM EMPLOYEE;
-- EMPLOYEE 테이블에서 모든 사원의 사번, 이름, 이메일, 입사일 조회
SELECT EMP_ID, EMP_NAME, EMAIL, HIRE_DATE FROM EMPLOYEE;
-- DEPARTMENT 테이블에 있는 모든 행 조회
SELECT * FROM DEPARTMENT;✏️ 컬럼 값 산술 연산
-- 컬럼 값 : 테이블의 한 칸(== 한 셀)에 작성된 값(DATA)
-- SELECT문 작성 시 컬럼명에 산술 연산을 작성하면
-- 조회되는 결과 컬럼 값에 산술 연산이 반영된다.
-- EMPLOYEE 테이블에서 모든 사원의 사번, 이름, 급여, 급여 + 100만 을 조회
SELECT EMP_ID, EMP_NAME, SALARY, SALARY + 1000000
FROM EMPLOYEE;
-- EMPLOYEE 테이블에서 모든 사원의 이름, 급여, 연봉(급여 * 12개월)을 조회
SELECT EMP_NAME, SALARY, SALARY * 12
FROM EMPLOYEE;✏️ 오늘 날짜 조회
SELECT SYSDATE FROM DUAL;
-- SYSDATE : 시스템 상의 현재 날짜
-- (년, 월, 일, 시, 분, 초 단위까지 표현 가능하지만,
-- 디벨로퍼의 날짜 표기 방법이 년/월/일로 지정되어 있는 것이다.)
-- * 날짜 설정 바꾸기
-- 환경설정 - 데이터베이스 - NLS - 날짜 형식 - YYYY-MM-DD HH24:mi:ss
-- DUAL(DUmmy tAbLe) : 가짜 테이블(임시 테이블, 단순 조회 테이블)
-- ** DB는 날짜 데이터의 연산(+, -)이 가능하다. (일 단위) **
SELECT SYSDATE, SYSDATE + 1, SYSDATE - 1 FROM DUAL;
-- EMPLOYEE 테이블에서 이름, 입사일, 오늘까지 근무한 날짜 조회
SELECT EMP_NAME, HIRE_DATE, (SYSDATE - HIRE_DATE) / 365
FROM EMPLOYEE;✏️ 컬럼 별칭 지정
-- SELECT 조회 결과의 집합인 RESULT SET에 컬럼명을 지정
/*
1) 컬럼명 AS 별칭 : 띄어쓰기 X, 특수문자 X, 문자 O
2) 컬럼명 별칭 : 1)번에서 AS 생략만 한 것
3) 컬럼명 AS "별칭" : 띄어쓰기 O, 특수문자 O, 문자 O
4) 컬럼명 "별칭" : 3)에서 AS만 생략한 것
*/
-- EMPLOYEE 테이블에서
-- 사번, 이름, 급여(원), 근무 일수를 모두 조회
SELECT EMP_ID AS 사번,
EMP_NAME 이름,
SALARY AS "급여(원)",
SYSDATE - HIRE_DATE "근무 일수"
FROM EMPLOYEE;✏️ 리터럴 표기법
-- 리터럴 : 값 자체
-- DB에서 리터럴 : 임의로 지정한 값을 기존 테이블에 존재하는 값처럼 사용
--> 리터럴 표기법 ''(홑따옴표)
SELECT EMP_NAME, SALARY, '원' AS 단위
FROM EMPLOYEE; ✏️ DISTINCT
-- DISTINCT : 조회 시 컬럼에 포함된 중복 값을 한 번만 표시할 때 사용
-- (주의사항)
-- 1) DISTINCT는 SELECT문에 딱 한 번만 작성할 수 있다.
-- 2) DISTINCT는 SELECT문 가장 앞에 작성 되어야 한다.
-- EMPLOYEE 테이블에 저장된 직원들이 속해있는 부서 코드 종류 조회
SELECT DISTINCT DEPT_CODE FROM EMPLOYEE;✏️ WHERE절
-- 테이블에서 조건을 충족하는 값을 가진 행만 조회하고자 할 때 사용
-- 비교 연산자 : >, <, >=, <=, =(같다), !=, <>(같지 않다)
-- EMPLOYEE 테이블에서 급여가 3백만원 초과인 직원의
-- 사번, 이름, 급여, 부서 코드를 조회
/*해석 순서*/
/*3*/SELECT EMP_ID, EMP_NAME, SALARY, DEPT_CODE
/*1*/FROM EMPLOYEE
/*2*/WHERE SALARY > 3000000;
-- EMPLOYEE 테이블에서
-- 부서 코드가 'D9'인 직원의
-- 사번, 이름, 부서 코드, 전화번호 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, PHONE
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';✏️ 논리 연산자 (AND, OR)
-- EMPLOYEE 테이블에서 급여가 200만 이상이고
-- 부서 코드가 'D6'인 직원의
-- 이름, 급여, 부서코드를 조회
SELECT EMP_NAME, SALARY, DEPT_CODE
FROM EMPLOYEE
WHERE SALARY >= 2000000
AND DEPT_CODE = 'D6';
-- EMPLOYEE 테이블에서
-- 급여가 300만 이상, 500만 이하의 직원의
-- 사번, 이름, 급여 조회
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY >= 3000000 AND SALARY <= 5000000;
-- EMPLOYEE 테이블에서
-- 부서 코드가 'D6' 또는 'D9'인 사원의
-- 사번, 이름, 부서 코드 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE = 'D6' OR DEPT_CODE = 'D9';✏️ 컬럼명 BETWEEN A AND B
-- 컬럼명 BETWEEN A AND B : 컬럼 값이 A 이상 B 이하인 경우
-- EMPLOYEE 테이블에서
-- 급여가 300만 이상, 500만 이하의 직원의
-- 사번, 이름, 급여 조회
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY BETWEEN 3000000 AND 5000000;✏️ 컬럼명 NOT BETWEEN A AND B
-- 컬럼명 NOT BETWEEN A AND B : 컬럼 값이 A 이상 B 이하가 아닌 경우
-- == 컬럼 값이 A 미만, B 초과인 경우
-- EMPLOYEE 테이블에서
-- 급여가 200만 미만, 500만 초과인 직원의
-- 사번, 이름, 급여 조회
SELECT EMP_ID, EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY NOT BETWEEN 2000000 AND 5000000;
/* BETWEEN을 이용한 날짜 비교 */
-- EMPLOYEE 테이블에서
-- 입사일이 1990/01/01 ~ 1999/12/31인 (90년도 입사자)
-- 직원의 사번, 이름, 입사일 조회
SELECT EMP_ID, EMP_NAME, HIRE_DATE
FROM EMPLOYEE
WHERE HIRE_DATE BETWEEN '1990/01/01' AND '1999/12/31';
/*** '1990/01/01' 날짜를 문자열 형식으로 작성하게 되면
DB가 알아서 판단하여 날짜 타입(DATE)으로 형변환을 진행함 ***/✏️ LIKE / NOT LIKE
/* LIKE
- 비교하려는 값이 특정한 패턴을 만족시키면 조회하는 연산자
[작성법]
WHERE 컬럼명 LIKE '패턴'
-- LIKE 패턴(와일드카드) : '%' (포함), '_' (글자 수)
'%' 예시
1) 'A%' : 문자열이 A로 시작하는 모든 컬럼 값
2) '%A' : 문자열이 A로 끝나는 모든 컬럼 값
3) '%A%' : 문자열에 A가 포함되어 있는 모든 컬럼 값
'_' 예시
1) 'A_' : A 뒤에 아무거나 한 글자
2) '___A' : A 앞에 아무거나 세 글자 (4글자 문자열이면서 A로 끝나야 함)
*/
-- EMPLOYEE 테이블에서 성이 '이'씨인 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE EMP_NAME LIKE '이%';
-- EMPLOYEE 테이블에서 이름에 '하'가 포함된 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE EMP_NAME LIKE '%하%';
-- EMPLOYEE 테이블에서
-- 전화번호가 010으로 시작하는 사원의 사번, 이름, 전화번호 조회
SELECT EMP_ID, EMP_NAME, PHONE
FROM EMPLOYEE
WHERE PHONE LIKE '010%';
SELECT EMP_ID, EMP_NAME, PHONE
FROM EMPLOYEE
WHERE PHONE LIKE '010________';
-- 010으로 시작하지 "않는" 사람들 조회
--> NOT LIKE (LIKE 결과 부정)
SELECT EMP_ID, EMP_NAME, PHONE
FROM EMPLOYEE
WHERE PHONE NOT LIKE '010%';
-- EMPLOYEE 테이블에서
-- 이메일에 _ 앞글자가 세 글자인 사원 사번, 이름, 이메일 조회
SELECT EMP_ID, EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE EMAIL LIKE '____%';
-- 문제점 : 와일드카드 문자(_)와 패턴에 사용된 일반 문자(_)의 모양이 같아서 문제 발생
-- 해결 방법 : ESCAPE OPTION을 이용하여 일반 문자로 처리할 '_', '%' 앞에 아무 특수문자나 붙임
SELECT EMP_ID, EMP_NAME, EMAIL
FROM EMPLOYEE
WHERE EMAIL LIKE '___$_%' ESCAPE '$';
--> $ 뒤 한 글자만(_)을 일반 문자 취급✏️ 연습 문제
-- 1. EMPLOYEE 테이블에서 이름 끝이 '연'으로 끝나는 사원의 이름 조회
SELECT EMP_NAME
FROM EMPLOYEE
WHERE EMP_NAME LIKE '%연';
-- 2. EMPLOYEE 테이블에서 전화번호 처음 3자리가 010이 아닌 사원의 이름, 전화번호를 조회
SELECT EMP_NAME, PHONE
FROM EMPLOYEE
WHERE PHONE NOT LIKE '010%';
-- 3. EMPLOYEE 테이블에서 메일 주소 '_'의 앞이 4글자이면서 DEPT_CODE가 D9 또는 D6이고
-- 고용일이 90/01/01 ~ 00/12/01이고, 급여가 270만 이상인 사원의 전체를 조회
SELECT *
FROM EMPLOYEE
WHERE EMAIL LIKE '____$_%' ESCAPE '$'
AND (DEPT_CODE = 'D9' OR DEPT_CODE = 'D6')
AND HIRE_DATE BETWEEN '1990/01/01' AND '2000/12/01'
AND SALARY >= 2700000;✏️ ORDER BY 절
- SELECT문의 조회 결과(RESULT SET)를 정렬할 때 작성하는 구문
- ***** SELECT문 가장 마지막에 해석 *****
[작성법]
3 : SELECT 컬럼명 AS 별칭, 컬럼명, 컬럼명, ...
1 : FROM 테이블명
2 : WHERE 조건식
4 : ORDER BY 컬럼명 | 별칭 | 컬럼 순서 [정렬 방식(오름/내림)] [NULLS FIRST | LAST]
*/
-- EMPLOYEE 테이블에서 급여 "오름차순"으로 이름, 급여 조회
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY ASC; --(ASCENDING)
-- EMPLOYEE 테이블에서 급여 "내림차순"으로 이름, 급여 조회
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC; --(DESCENDING)
-- 급여가 200만 이상인 사원을 오름차순 정렬
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
WHERE SALARY >= 2000000
ORDER BY SALARY /*ASC 생략 가능*/;
-- ORDER BY 정렬 방식은 기본적으로 오름차순
-- ** 정렬은 숫자, 문자, 날짜 모두 사용 가능 **
-- 이름 오름차순 정렬
SELECT EMP_NAME
FROM EMPLOYEE
ORDER BY EMP_NAME;
-- 고용일 내림차순 정렬
SELECT EMP_NAME, HIRE_DATE
FROM EMPLOYEE
--ORDER BY HIRE_DATE DESC;
ORDER BY 2 DESC; --> 컬럼 순서
-- 연봉 내림차순 정렬
SELECT EMP_NAME, SALARY * 12 AS 연봉
FROM EMPLOYEE
WHERE SALARY * 12 >= 5000000
--WHERE 연봉 >= 5000000 - 해석 순서가 별칭 해석 전이기 때문에 오류 발생
--ORDER BY SALARY * 12 DESC; -- 컬럼명
--ORDER BY 2 DESC; -- 컬럼 순서
ORDER BY 연봉 DESC; -- 별칭
-- 보너스 정렬
SELECT EMP_NAME, BONUS
FROM EMPLOYEE
--ORDER BY BONUS; -- NULLS LAST 기본값
--ORDER BY BONUS DESC; -- NULLS FIRST 기본값
ORDER BY BONUS NULLS FIRST;
-- 오름차순 정렬 시 NULLS LAST가 기본값
-- 내림차순 정렬 시 NULLS FIRST가 기본값
/* 정렬 중첩 (큰 분류를 먼저 정렬하고 내부에 작은 분류를 정렬) */
-- EMPLOYEE 테이블에서 부서코드 오름차순 정렬 후
-- 부서별 급여 내림차순 정렬
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
ORDER BY DEPT_CODE, SALARY DESC;💡 연산자
✏️ 연산자 우선 순위
- 산술연산자
- 연결연산자
- 비교연산자
- IS NULL / IS NOT NULL, LIKE, IN / NOT IN
- BETWEEN AND / NOT BETWEEN AND
- NOT(논리연산자)
- AND(논리연산자)
- OR(논리연산자)
💡 IN 연산자
비교하려는 값과 목록에 작성된 값 중 일치하는 것이 있으면 조회하는 연산자
-> OR 연산을 연달아 작성한 효과
- 작성법
컬럼명 IN (값1, 값2, 값3, ...)
✏️ 예제
-- EMPLOYEE 테이블에서
-- 부서코드가 D1 또는 D6 또는 D9인 사원의 사번, 이름, 부서코드 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE
FROM EMPLOYEE
-- WHERE DEPT_CODE = 'D1' OR DEPT_CODE = 'D6' OR DEPT_CODE = 'D9';
WHERE DEPT_CODE IN ('D1', 'D6', 'D9');
-- 사번이 200, 205, 210인 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE EMP_ID IN (200, 205, 210);
-- 사번이 200, 205, 210이 아닌 사원의 사번, 이름 조회
SELECT EMP_ID, EMP_NAME
FROM EMPLOYEE
WHERE EMP_ID NOT IN (200, 205, 210);💡 연결 연산자( || )
여러 값을 하나의 컬럼 값으로 연결하는 연산자
-> (자바의 문자열 + (이어쓰기) 효과)
✏️ 예제
SELECT EMP_NAME || '의 급여는 ' || SALARY || '원 입니다.' AS 결과
FROM EMPLOYEE;- 질의 결과

💡 NULL 처리 연산자
- JAVA에서 NULL : 참조하는 객체가 없다.
- DB에서 NULL : 컬럼 값이 없다.
1) IS NULL : 컬럼 값이 NULL인 경우 조회
2) IS NOT NULL : 컬럼 값이 NULL이 아닌 경우 조회
✏️ 예제
-- EMPLOYEE 테이블에서 전화번호가 없는 사원의 사번, 이름, 전화번호 조회
SELECT EMP_ID, EMP_NAME, PHONE
FROM EMPLOYEE
WHERE PHONE IS NULL;
-- EMPLOYEE 테이블에서 보너스를 받는 사원의 이름, 보너스 조회
SELECT EMP_NAME, BONUS
FROM EMPLOYEE
WHERE BONUS IS NOT NULL;
풀스택 개발자 기록집 📁