Training & Inference
- Loss, Optimizer, Metric
Overview
-
본격적으로 모델 학습을 진행해보자
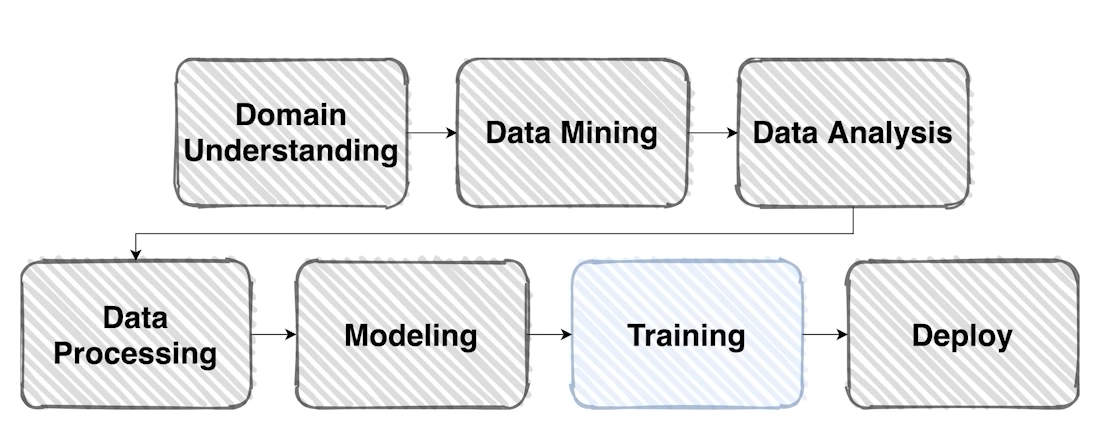
-
학습 프로세스에 필요한 요소는 크게 세 가지이다.
Loss
복습 : (오차) 역전파
- Error Backpropagation
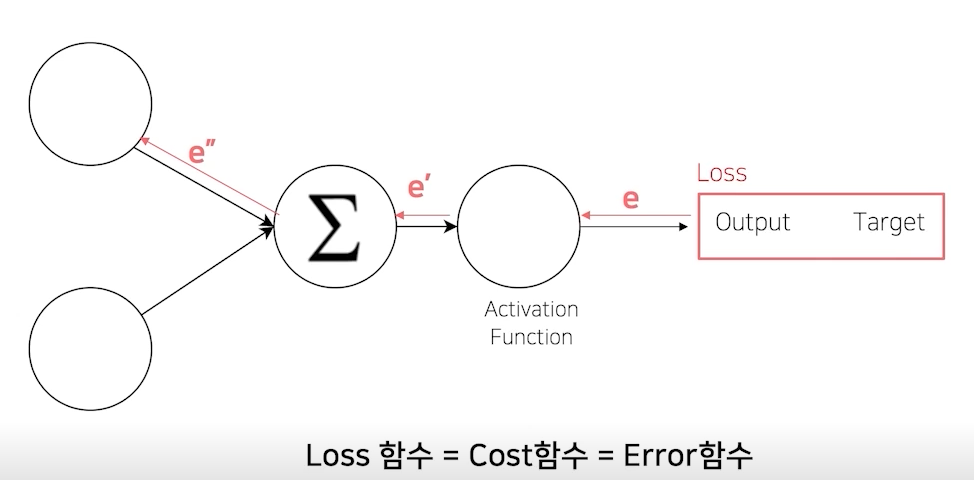
Loss도 사실은 nn.Module Family
- nn 패키지에서 찾을 수 있다.
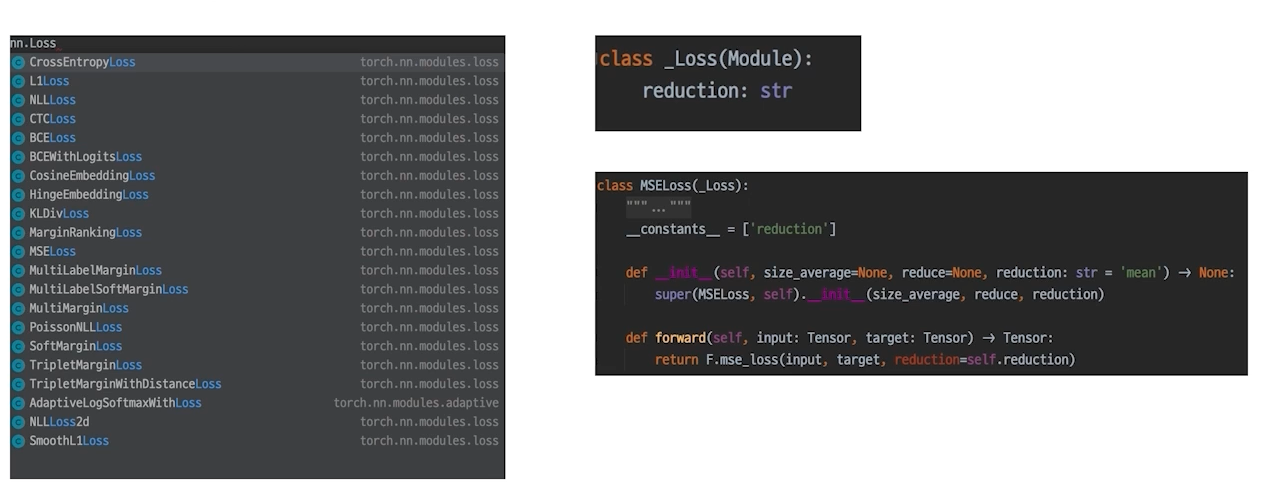
- loss.backward()
- 이 함수가 실행되면 모델의 파라미터의 grad값이 업데이트 된다. (requires_grad=false만 빼고)
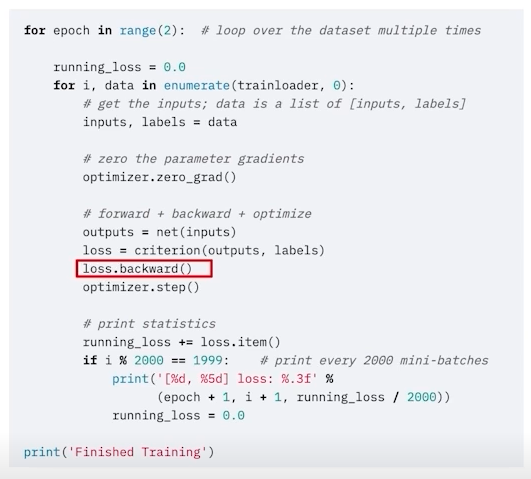
- 모델의 파라미터랑 loss.backward와 어떻게 연결?
- 결국 모델, loss, criterion도 module로부터 상속받음
- 또한 모델로 인해 input과 output의 chain이 생김
- 그 뒤에 criterion으로 인해 input 부터 output, loss까지 chain이 생김
- 이 함수가 실행되면 모델의 파라미터의 grad값이 업데이트 된다. (requires_grad=false만 빼고)
Example : 조금 특별한 loss
- 쉽게 말해서 error를 만들어내는 과정에 양념을 치는 것
- Focal Loss
- Class Imbalance 문제가 있는 경우, 맞춘 확률이 높은 Class는 조금의 loss를, 맞춘 확률이 낮은 Class는 Loss를 훨씬 높게 부여(이번에 이용해보기)
- Label Smoothing Loss
- Class target label을 Onehot표현으로 사용하기 보다는,
(ex. [0, 1, 0, 0, 0, ...])
조금 soft하게 표현해서 일반화 성능을 높이기 위함, 즉 칼같이 자르는 게 아니라 유연하게 표현
(ex. [0.025, 0.9, 0.025, ...])
- Class target label을 Onehot표현으로 사용하기 보다는,
Optimizer
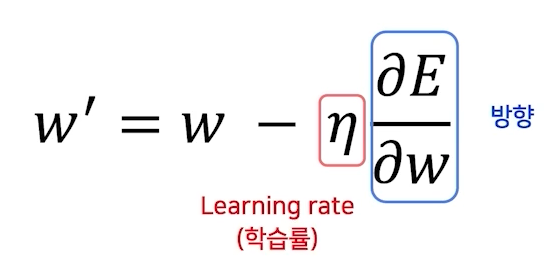
어느 방향으로, 얼마나 움직일지?
-
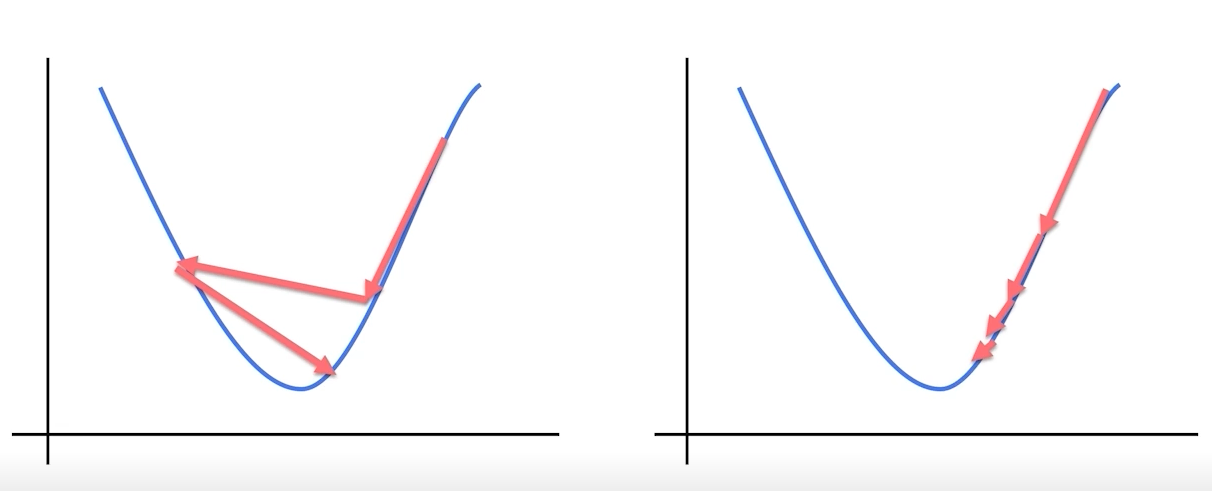
영리하게 움직일수록 수렴은 빨라진다.
-
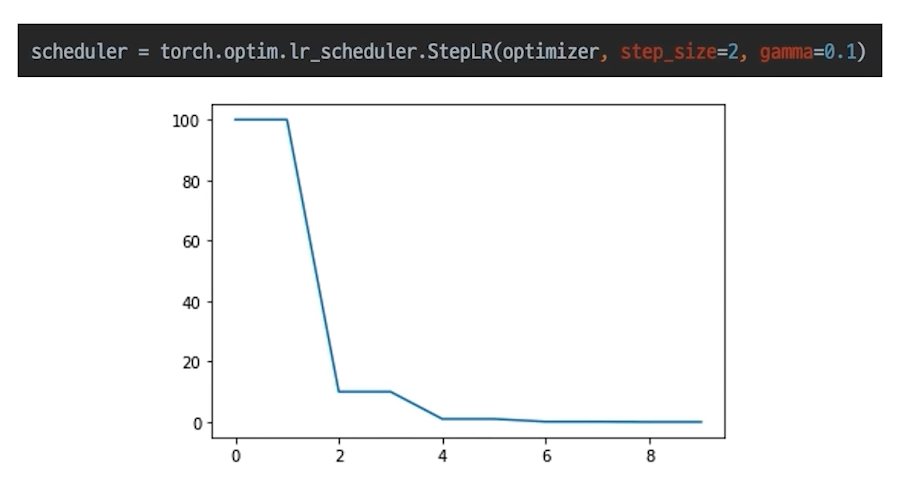
학습 시에 Learning Rate을 동적으로 조절할 수는 없을까?
- StepLR : 특정 Step마다 LR 감소
- CosineAnnealingLR : Cosine 함수 형태처럼 LR을 급격히 변경
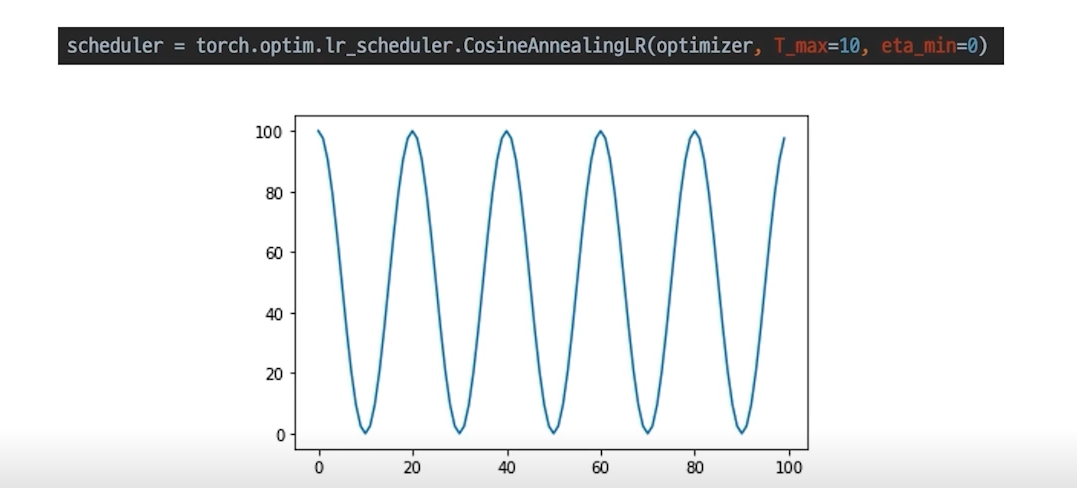
- ReduceLROnPlateau: 더 이상 성능 향상이 없을 때 LR 감소(보통 많이 사용)
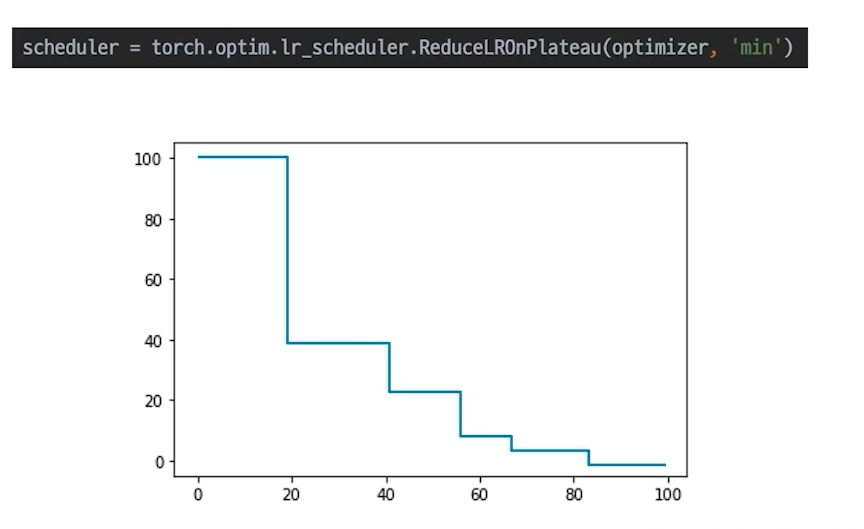
- StepLR : 특정 Step마다 LR 감소
Metric
모델의 평가
- Classification : Accuracy, F1-score, precision, recall, ROC & AUC
- Regression: MAE, MSE
- Ranking(추천 시스템): MRR, NDGC, MAP
- 학습에 직접적으로 사용되는 것은 아니지만,
학습된 모델을 객관적으로 평가할 수 있는 지표가 필요
Metric의 허와 실
- 만든 모델의 정확도가 90% -> 정말 좋은 모델일까?
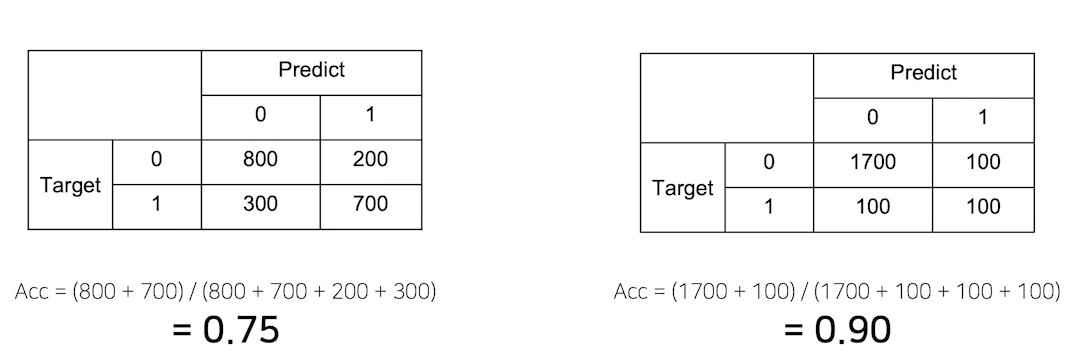
- 두번째 모델은 Accuracy가 높지만, 1을 그냥 반반 찍기로 맞추고 있다..(200개 중 100개 맞춤)
- 데이터 불균형이 있을 때 accuracy가 높아도 모델이 좋은 모델이 아닐 수 있다.
올바른 Metric의 선택
- 데이터의 상태에 따라 적절한 Metric을 선택하는 것이 필요
- class 별로 밸런스가 적절히 분포 : accuracy
- class 별 밸런스가 좋지 않아서 각 클래스 별로 성능을 잘 낼 수 있는지 확인 필요 : F1-score
- Process
Overview
- 학습과 추론 프로세스의 과정을 이해하는 것이 목표!

Training Process
Training 준비
- 학습 한 번 하기 위해 지금까지 만든 결과물
- model.train() : 모델을 train할 수 있게 설정해줌
- train, eval 에 따라 dropout, batchnorm이 달라짐(관련 논문 읽어보기)
Training 프로세스 이해
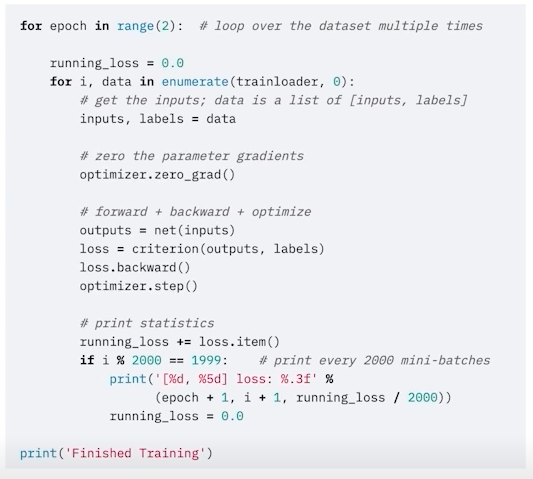
-
optimizer.zero_grad() : 이전 배치에서 각각의 파라미터가 얻은 gradient를 없애줌
-> 그냥 초기값으로 초기화만 하기에는 loss가 대치가 안되고 쌓이게 되므로 zero_grad() 해주는 것이 좋음
-> optimizer가 파라미터를 가지고 있으므로 optimizer에다가 zero_grad()
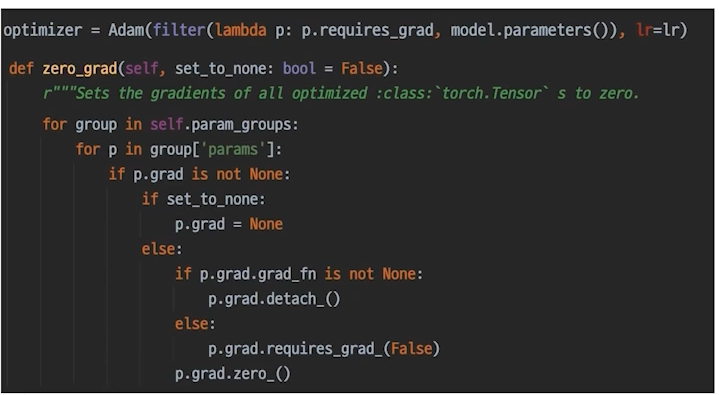
-
loss = criterion(outputs, labels)
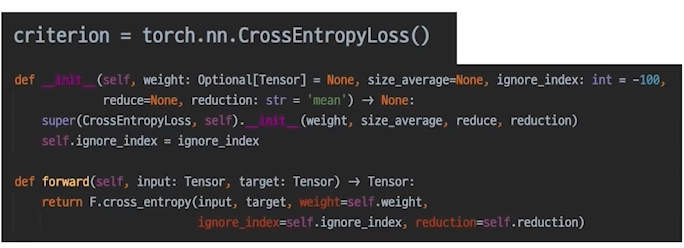
-
loss를 마지막으로 chain 생성
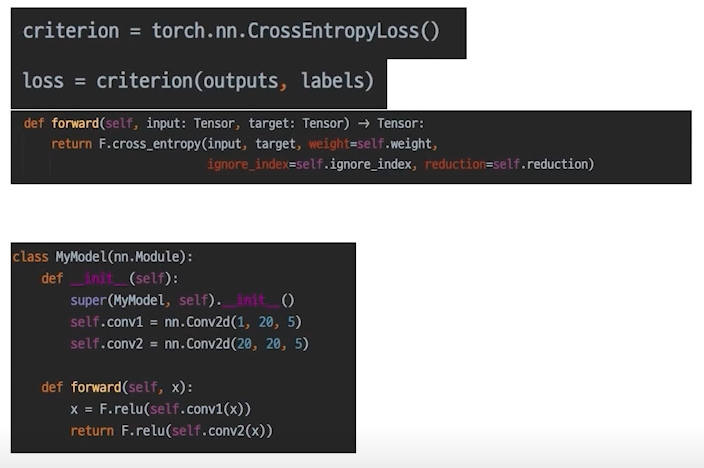
-
loss의 grad_fn chain -> loss.backward()
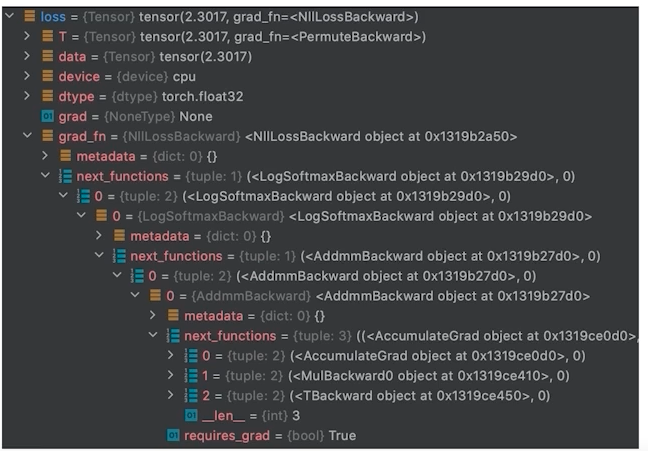
- grad_fn에 파라미터들이 연결되어 있으므로 backward하면 모든 파라미터의 gradient 값 구할 수 있음
-
optimizer.step()
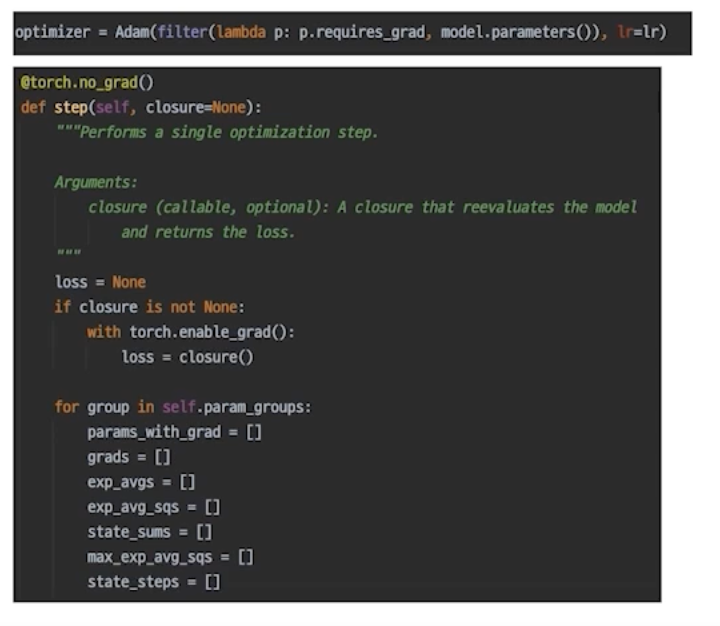
More:Gradient Accumulation
- 지금까지의 모든 과정을 이해했다면 이를 응용하는 것도 가능하다.
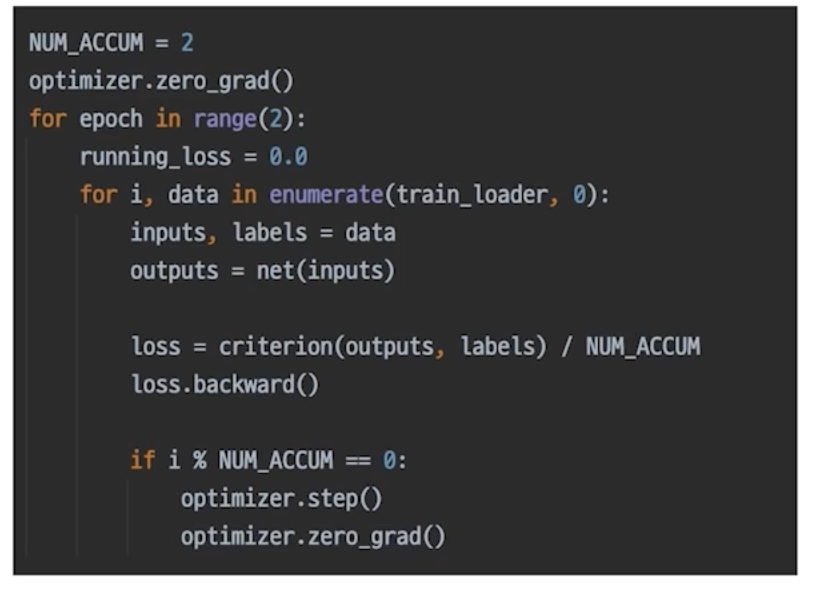
- 보통은 하나의 batch 마다 optimizer step
- 모든 batch 마다 optimizer 업데이트 하는 게 아니라 띄엄띄엄 step을 하면 어떨까? => gradient accumulation(위의 그림!)
- loss가 쌓이다가 그 쌓인 loss를 가지고 한 번에 step
- 이 경우 매번 zero_grad()하면 안됨..! step하고 나서 해야 됨
Inference Process
Inference Process의 이해
- model.eval() = self.train(False) : dropout, batchnorm 다르게 작용
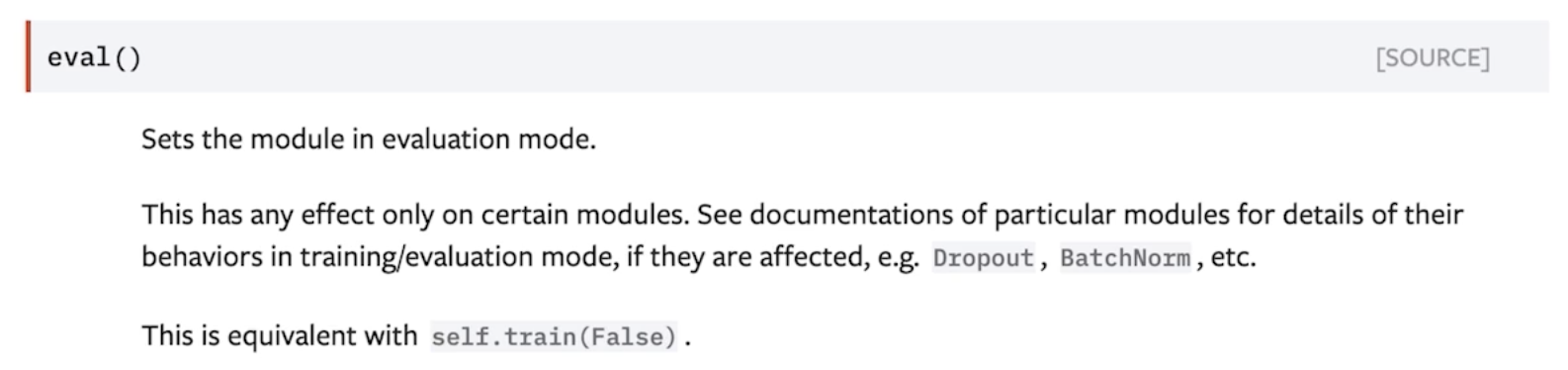
- with torch.no_grad():
- 이 안의 모든 텐서들은 gradient 업데이트 안함, 파라미터 변화 없음
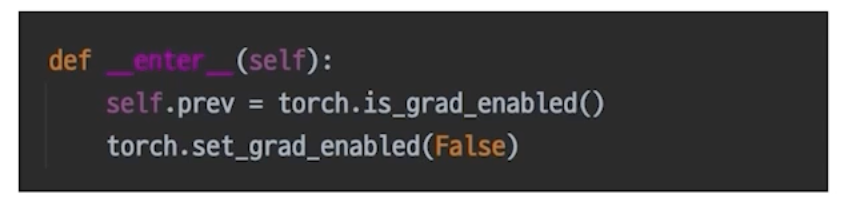
- 이 안의 모든 텐서들은 gradient 업데이트 안함, 파라미터 변화 없음
Validation 확인
- 추론 과정에 Validation 셋이 들어가면 그게 검증이다.
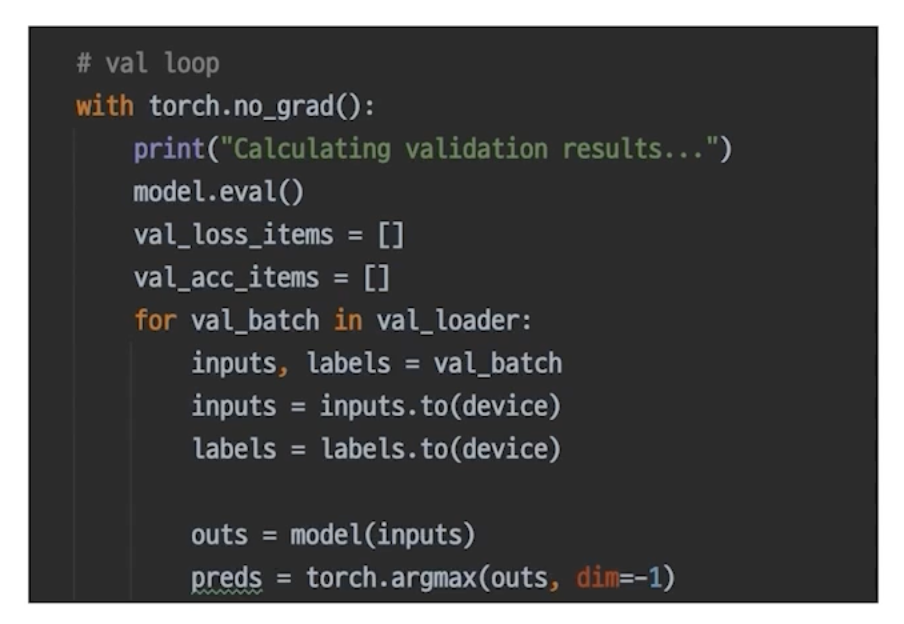
Checkpoint
- 그냥 직접 짜면 된다.
- torch.save() -> model 저장
- loss 상태 확인
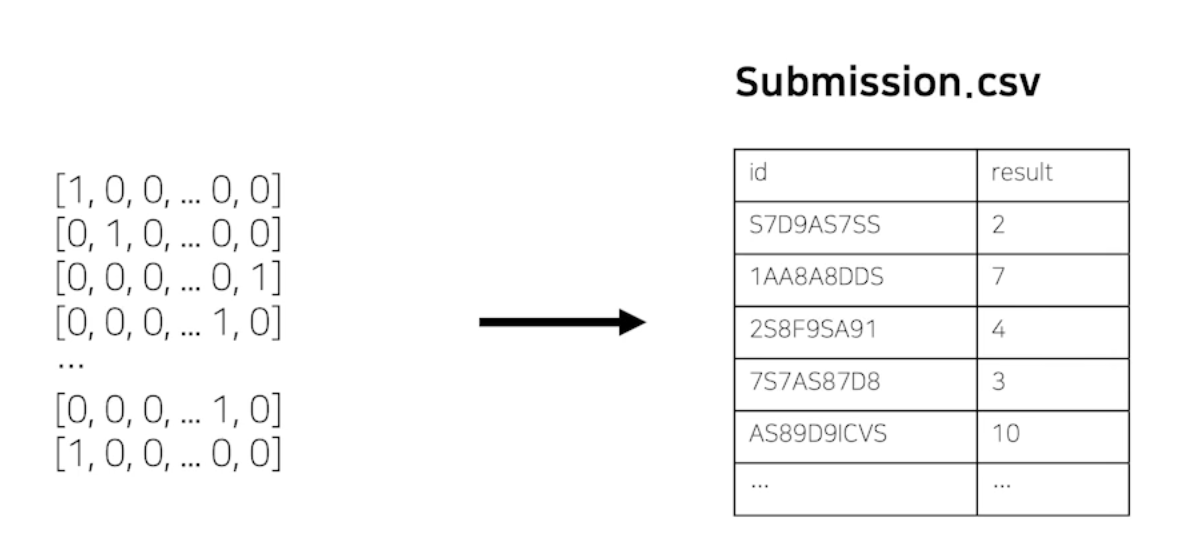
최종 output, submission 형태로 변환
- 최종 submission 스펙을 확인 후 변환하여 제출
Appendix: PyTorch Lightening
- Keras 코드를 보듯 정리가 되어 있다.

- 그래도 공부는 pytorch로 하면 좋다. 충분한 이해가 되지 않은 상태로 lightening을 이용하면 오히려 독이 될 수 있다.
- pytorch로 공부해야 코드로부터 머신러닝 프로세스를 배울 수 있고 자유롭게 응용할 수 있다.
Special Mission
-
우리가 중간중간 모델의 결과를 저장하고 싶은 경우가 있습니다. 학습되는 중간에 좋은 성능의 모델이 발견이 되었으면 모델을 저장하는 것이 좋은데요. 이러한 체크포인트 저장 과정을 Evaluation에 추가해서 체크포인트 모델이 저장되도록 설계하세요.
-
모델 평가에 Metric을 올바르게 사용하는 것도 중요합니다. Evaluation 과정에서 모델 학습 결과를 Loss와 Accuracy만 보는것 보다는 다른 Metric도 참고하는 것도 좋습니다. F1-score Metric 을 구현 or 코드를 찾아서 추가하고, 매 에폭마다 결과를 확인할 수 있도록 설계하세요.
-
Training Process에 어느정도 익숙해지셨다면 Gradient Accumulation을 내 프로젝트에 적용시켜보세요. 적용한다고 반드시 성능이 올라가는 것은 아닐겁니다. 적용을 했다면 전후 성능 비교를 해봐야겠지요?
-
Optimizer의 스케줄러가 종류에 따라 어떻게 Learning rate를 변경해 가는지, 옵션에 따라 또 어떻게 스케쥴링하게 되는지 확인해보세요. 대표적으로 많이 사용하는 SGD 와 Adam Optimizer를 각각 구현해 보고 비교해 봅시다. 아래 Further Reading에 좋은 예제가 있습니다.
-
새로운 Loss를 만들어 봅시다. 새로운 Loss를 적용해서 학습에 사용해보겠습니다. (Label smoothing, Focal Loss, F1 Loss 등) 무엇이든지 상관없습니다. 구현 후 학습에 활용해서 비교해보세요!
Further Reading
-
Optimizer scheduler plot 분석 : https://www.kaggle.com/isbhargav/guide-to-pytorch-learning-rate-scheduling
-
학습에 진전이 없을 때, 일찍 끝내고 싶을때 등의 경우에 파이토치 프레임워크 위에서 사용할 수 있는 여러 라이브러리들의 코드를 참고하는 것도 좋아요. (Ignite, Catalyst)
-
캐글에는 다양한 학습 및 추론에 대한 코드가 공유되고 있습니다. 그 코드들을 하나하나 따라가다보면 효율적이고 성능을 높일 수 있는 학습 방법을 발굴할 수도 있어요. 예시로 SE-ResNeXT를 이미지 분류 문제에 학습시키는 코드가 Bengali 대회에 공유되었어요. 링크
-
Pretrained Model에 대해 최신 기술을 매우 빠르게 업로드하고 간단하게 사용할 수 있게 공유해주는 레포가 있어요. 이를 참고해서 최고의 모델을 통해 문제에 가장 적합한 모델을 학습해보세요. 링크
-
어떠한 loss 함수를 써야할지 고민이 되신다구요? Label Smoothing, F1 Loss (F1 Score를 목표로 하는 손실함수)와 같이 다양한 손실함수를 찾아보실 수 있어요.
