AI 서비스 개발 기초 : AI 현업자 특강
이활석 마스터님 : 서비스향 AI 모델 개발
1) 이력
- 카이스트 ph.D / Video codec
- Samsung Techwin / CCTV Vision Technology
- NCSOFT / 1 vs 1 battle agent, Generative Model
- Naver / Clova OCR
- Up stage CTO
2) 서비스향 AI 모델 개발 vs 연구 AI 모델 개발
- 보통 수업/ 학교/ 연구에서는 정해진 데이터셋/평가 방식에서 더 좋은 모델을 찾는다.
- 하지만 서비스 개발 시에는 핛습 데이터도 없고, 테스트 데이터셋과 테스트 방법도 없다.
- 서비스 개발 시에는 서비스 요구 사항만 있다.
- 따라서 우리는 학습 데이터부터 준비해야 한다.
3) 학습 데이터셋 준비
-
정확히는 서비스 요구 사항으로부터 학습 데이터셋의 종류/수량/정답을 정해야 한다.
- 예) 수식 사진 인식 서비스 -> 어떤 수식인지? -> 초중고 수학(종류)
-
질의 응답을 통해 데이터셋의 종류/수량/정답 관련 요구 사항을 구체화해야 한다.
- 예) 수식인식을 어떻게 사용할 것인지? -> 학생이 수식 입력을 힘들어 하므로 대신 입력 해주고자 함 -> 수식 이미지를 Latex으로 변환!(정답)
- 예) 학생들의 손글씨도 인식? -> 네 -> 손글씨/인쇄 & 초중고 수식(종류)
- 예) 그림자/형광펜/화이트 자국/종이 구겨짐/회전의 경우도 인식해야 한느가?
-
종류
- 결국 종류에 대해서도 정의를 해야 한다.
- 어디까지 '종류'로 정의해서 각각 몇 장을 수집할 것인지 정해야 한다.
- 결국 종류에 대해서도 정의를 해야 한다.
-
기술 모듈 설계
- 직접 데이터를 모으다 보면 미리 생각지 못한 경우가 발생할 수 있다.
- 예) 한 수식만 사진 찍기가 어렵다.
-> 이미지에서 수식부분만 뽑아와야 한다. - 이 경우 전체 이미지에서 수식 영역을 검출하는 모듈이 추가 되어야 한다.
- 예) 한 수식만 사진 찍기가 어렵다.
- 직접 데이터를 모으다 보면 미리 생각지 못한 경우가 발생할 수 있다.
-
정답
- 학습 데이터의 정답은 AI모델 별로 입력에 대한 출력 쌍이다.
- 예) 수식 영역 검출 모델
-> 입력: 전체 이미지, 출력 : 수식 영역들의 위치 - 예) image to latex 모델
-> 입력: 수식 이미지 하나, 출력 : latex string
- 예) 수식 영역 검출 모델
- 이처럼 AI 모델 하나에 대한 정답은 모델 설계와 맞물려 있다.
- 예) image to latex가 한 모델로 가능할까? 성능이 검증된 4가지 모델의 조합은 어떨까? -> 검출기, 인식기, 정렬기, 변환기
-> 각 모델(4개의 모델) 별로 입출력(정답)의 정의가 필요
- 예) image to latex가 한 모델로 가능할까? 성능이 검증된 4가지 모델의 조합은 어떨까? -> 검출기, 인식기, 정렬기, 변환기
- 학습 데이터의 정답은 AI모델 별로 입력에 대한 출력 쌍이다.
-
결국 학습 데이터 준비를 하려면 모델 파이프 라인 설계가 되어야 한다!
-
그런데 모델 파이프 라인을 설계하려면 어느 정도 데이터가 있어야 한다.
-
즉, 모델 설계와 데이터 수집, 서비스 요구 사항 확인이 여러번 반복하며 수렴된다.
4) 테스트 데이터셋 / 테스트 방법 준비
- 테스트 방법
- OFFLINE 테스트: 실 서비스 적용 전에 개발 환경에서의 평가
- 정량 평가: 완벽하지 않음. 여러 AI 모델을 후보로 두는 것을 권장
- 정성 평가: 각 후보 AI 모델에 대해 면밀히 분석하고 서비스 출시 버전 선택
- ONLINE 테스트: 실 서비스 적용 시에 평가
- 정량 평가: 해당 AI 모델을 서비스 시나리오에서 자동정량평가
- 정성 평가: VOC(Voice of customer), AI모델 개선 포인트 파악
(가장 중요한 단계)
- OFFLINE 테스트: 실 서비스 적용 전에 개발 환경에서의 평가
- OFFLINE 테스트와 ONLINE 테스트는 이질감이 클 수 있는데, 결국 중요한 것은 서비스에서의 품질이기 때문에 OFFLINE 테스트를 잘 설계해야 하고, 여러 후보를 두어야 한다.
5) 모델 요구사항 도출
- 처리 시간 : 하나의 입력이 처리되어 출력이 나올때까지의 시간
- 예) 수식 영역 검출
- OFFLINE TEST: 이미지 입력 후 수식 영역 정보가 출력될 때까지의 시간
- ONLINE TEST: 이미지 촬영후 이미지에서 수식 영역 정보가 화면 상에 표형되기까지의 시간
- 예) 수식 영역 검출
- 목표 정확도 : 해당 기술 모듈의 정량적인 정확도
- 예) 신용카드 인식
- OFFLINE TEST: 입력된 이미지 내 카드 번호/유효기간에 대한 edit distance
- ONLINE TEST: 사용자가 AI모델의 결과값을 수정할 확률
- 예) 신용카드 인식
- 목표 QPS(Queries Per Second) : 초당 처리 가능한 요청 수
- 향상 방법
- 장비를 늘린다.
- 처리 시간을 줄인다. = AI모델의 처리 속도를 높인다.
- 모델 크기를 줄인다. = 한 GPU에 올릴 수 있는 모델 수를 늘린다.
- 향상 방법
- Serving 방식 : 기술 모듈이 Mobile에서 동작하기를 원하는지, Local CPU/GPU Server에서 동작하기를 원하는지, Cloud CPU/GPU server에서 동작하기 원하는지
- 장비 사양 : 가끔은 serving 장비가 없어서 장비 구축까지 요구하는 경우가 있음. 이 경우 예산과 QPS에 맞춰 장비 사양도 정해야 한다.
6) 서비스향 모델 개발 기술팀의 조직 구성
- Model Develop
- Modeling(Modeler) : AI 모델 구조 제안, AI모델 성능 분석/디버깅
- Data(Data curator) : 학습 데이터 준비, 정량 평가 수립, 정성 평가 분석
- Tool(IDE Developer) : 라벨링 툴 개발, 모델 분석 툴 개발, 모델 개발 자동화 파이프라인 개발
- Model Quality Manager: 전체적으로 총괄하여 모델의 품질을 관리
- Model Serving
- Model Engineering
- mobile에서 구동하기 위해 사용 라이브러리 변경
(pytorch -> tf -> TFLite) - GPU 서버에서 구종하기 위해 사용라이브러리 변경
(Pytorch -> tf -> TensorRT) - 각 toolkit에서 지원되는 operation으로만 모델 구조 변경하여 재학습하거나 custom layer 구현
- 메모리를 줄이기 위한 경량화(lightweight) 작업
- distillation, quantization
- gpu 고속 처리를 위해 CUDA programming
- 아예 모든 연산을 C++/C로 변환
- mobile에서 구동하기 위해 사용 라이브러리 변경
- App Developer
- Mobile -> Android /Iphone
- BE Engineer
- on CPU : server farm / cloud
- on GPU : server farm / cloud
- Model Engineering
7) AI를 쌓고자 하는 분들에게 조언
- 개발자 => AI 관련 전환
- Model Engineering / Tool / Serving 은 개발력이 많이 필요한 분야이고 앞으로 점차 니즈가 많아질 것이기 때문에 바로 AI 모델링만 생각하기 보다 한단계씩 넘어가자
- 모델러
- 모델링에 대한 전문성도 중요하지만, 점점 해당 업무는 자동화 되고(AutoML, 관련 툴) 관련 인력 수도 늘어나고 있으니 주변으로 역량을 확대해야 한다.-> 프론트엔드, 백엔드, AI 기술 분야 확장 등
- AI는 트렌드에 민감해야 한다.
- AI는 기술 발전 속도가 다른 기술들에 비해 훨씬 빠르고 변화무쌍하다.
- 이것을 당연하게 여기고, 어떻게 하면 효율적으로 변화에 적응할 지 고민해야 한다.
문지형 마스터님 : 내가 만든 AI 모델은 합법일까 불법일까
1) 저작권법, 왜 알아야 할까
- 좋은 AI 모델은 좋은 데이터에서 나온다.
- 하지만 대부분의 경우 문제에 적합한 데이터가 없다.
- 따라서 새롭게 데이터를 제작해야하고, 데이터를 제작할 때 저작권을 고려하지 않으면 합법적으로 사용할 수 없게 된다.
- 합법적이지 않은 데이터로 학습한 모델 또한 완전한 합법의 영역에 있다고 보기 어렵다.
- 이익이 목적이 아닌 학계 또한 저작권과 라이센스에 대해 주목하고 있다.
2) 저작권 관련 개념
- 저작권 : 사람의 생각이나 감정을 표현한 결과물(저작물)에 대해 창작자에게 주는 권리로 '창작성'이 있다면 별도의 등록 절차 없이 자연히 발생한다.
- 저작물 : 사람의 생각이나 감정을 표현한 결과물
- 소설, 시, 논문, 강연, 연설, 각본 그 밖의 어문저작물
- 음악 저작물
- 연극 및 무용, 무언극 그 밖의 연극저작물
- 회화, 서예, 조각, 판화, 공예, 응용미술저작물 그 밖의 미술 저작물
- 건축물, 건축을 위한 모형 및 설계도서 그 밖의 건축저작물
- 사진저작물
- 영상저작물
- 지도, 도표, 설계도, 약도, 모형 그 밖의 도형 저작물
- 컴퓨터프로그램 저작물
- 저작권법에 보호받지 못하는 저작물
- 헌법, 법률, 조약, 명령, 조례, 규칙
- 국가 또는 지방자치단체의 고시, 공고, 훈령 그밖의 이와 유사한 것
- 법원의 판결, 결정, 명령 및 심판이나 행정심판절차 그 밖의 이와 유사한 절차에 의한 의결, 결정 등
- 국가 또는 지방자치단체가 작성한 것으로서 제 1호 내지 제 3호에 규정된 것의 편집물 또는 번역물
- 사실 전달에 불과한 시사보도
3) 합법적으로 데이터 사용하기
- 저작자와 협의한다
- 지적재산권 독점적/비독점적 이용허락
- 지적재산권 전부/일부에 대한 양도
- 라이센스
- 저작자에게 이용 허가 요청을 하지 않아도 저작자가 제안한 특정 조건을 만족하면 이용이 가능하도록 만든 저작물에 대한 이용허락 규약
- 라이센스를 발행하는 단체는 다양할 수 있음
- 가장 유명한 것은 creative commons라는 비영리 단체에서 제공하는 CCL
- 국내에는 문화체육관광부에서 제공하는 공공누리
- CCL(Creative Common License)
- BY: Attribution - 저작자 표시
- ND: No Derivatives - 변경 금지
- SA: Share Alike - 동일 조건 변경 허락
- NC: Non Commercial - 비영리
4) AI 개발 중에 자주 마추질 수 있는 사례
- 뉴스 데이터의 이용
- 뉴스 기사의 저작권은 언론에 있다.
- 한국 언론 진흥 재단에서 대부분 언론사의 저작권을 위탁해서 관리 중
- 따라서 뉴스 기사 합법적 사용을 위해서는
- 한국 언론 진흥 재단에 문의
- 직접 언론사에 문의
- 아~~주 드물게 CCL이 적용된 언론사의 뉴스 기사 사용(wikitree)
- 뉴스 기사의 제목은 저작권법의 보후를 받지 못함
- 데이터 판매 사이트에서 0원에 구매한 데이터는 내 마음대로 이용할 수 있을까?
- 데이터 판매회원이 정한 이용약관에 따라 다름
- KDX의 경우 기본적으로 아래 조항의 공통 이용범위 내에서만 이용 가능
- 판매회원이 추가 조건을 더 걸었다면 공통 이용 범위 외의 다른 이용도 불가할 수 있음
- 공정 이용: 아래의 경우에 대해서는 저작권자의 허락을 받지 않고도 저작물을 이용할 수 있다.
- 교육
- 재판절차 등에서의 복제
- 정치적 연설 등의 이용
- 학교교육 목적 등에 이용
- 시사 보도를 위한 이용
- 공표된 저작물의 이용
- 영리를 목적으로 하지 않은 공연 방송
- 사적 이용, 도서관, 시험 문제, 시각장애인 등을 위한 복제
- 방송사업가의 일시적 녹음, 녹화
- 미술, 사진, 건축저작물의 전시 또는 복제
- 번역 등에 의한 이용
- 시사적인 기사 및 논설의 복제
- 프로그램 코드 역분석
- 정당한 이용자에 의한 보존을 위한 프로그램 복제
오혜연 마스터님 : AI Ethics
1) Bias
- Bias : AI는 의도하든 의도하지 않았든 bias를 학습할 수도 있다는 것을 항상 염두에 두자.
2) Privacy
- Privacy: 데이터를 사용할 때, 저작권과 그 데이터를 제공한 사람들의 privacy를 보호할 수 있도록 고민하고 여러 방법을 시도해야 한다.
3) Social Inequality
- Social Inequality : 사회
4) Misinformation
- Misinformation
5) AI for Health
- AI for Health
6) AI for Environment
- AI for Environment
이준엽 마스터님 : Full Stack ML Engineer
1) Full Stack ML Engineer?
- ML Engineer : ML/DL 기술을 이애하고, 연구하고, product를 만드는 엔지니어
- Full Stack Engineer: 내가 만들고 싶은 Product를 시간만 있다면 모두 혼자 만들 수 있는 개발자
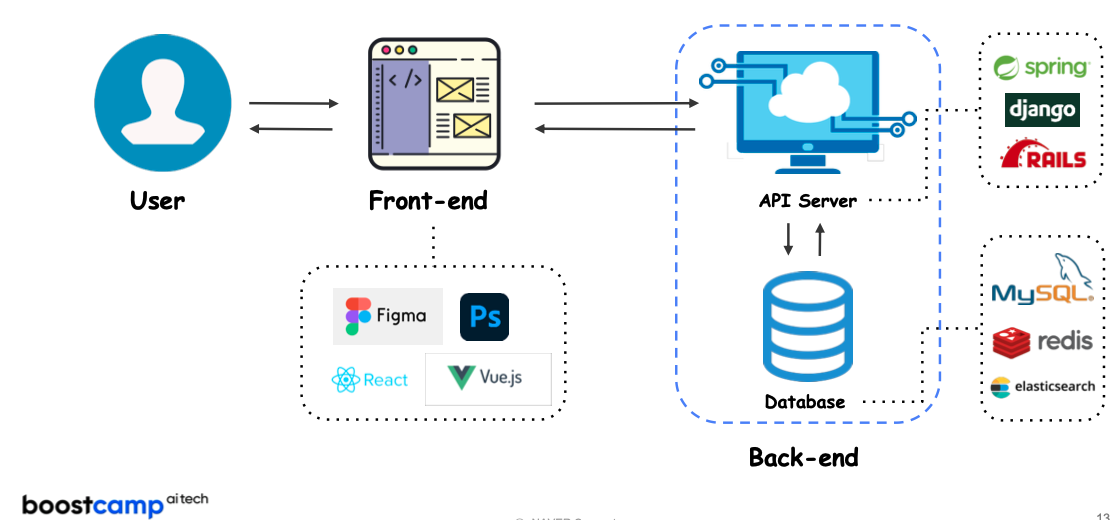
- Full Stack ML Engineer :
Deep learning research를 이애하고 + ML Product로 만들 수 있는 Engineer- ML Service
- Edge device servic
- Data collection
2) Pros and cons of Full Stack ML Engineer
- 장점
- 재미있다!: 처음부처 끝까지 내손으로 만드는 재미
- 빠른 프로토타이핑 : 검은 화면에서 돌아가는 것과 실제 제품처럼 보여주는 모델은 느낌이 다르다. 프로젝트의 go/stop을 결정하는 트리거가 될 수도. 하지만 프로토타이핑을 협업하기는 곤란한 경우가 많으므로 ML 개발자가 프로토타입까지 만들어주면 좋다.
- 기술 간 시너지: 연결되는 stack에 대한 이해가 각 stack의 깊은 이해에도 도움을 준다. 결국 하나의 서비스로 합쳐지는 기술들이기 때문에, full stack ml engineer가 되면 연결에 대한 고려가 들어간 개발 결과물을 만들어낼 수 있다.
- 팀플레이: 다른 포지션 엔지니어링에 대해 이해할 수 있고, 서로 갈등이 생길 법한 부분에서 기술적인 이해가 도움이 많이 된다.
- 성장의 다각화: 연구자 + 개발자 + 기획자가 모인 회의에서 모든 내용이 성장의 밑거름이 된다. 사람에 따라서는 매너리즘을 떨치는 방법이 되기도 한다.
- 단점
- 깊이가 없어질 수도 있다: 하나에 집중하는 것에 비해 깊이가 없어질 수 있다. CS + ML 분야는 하루가 다르게 새로운 기술, 새로운 연구가 나오기 때문에 모든 스택에서 최신 트렌드를 따라잡기가 어려운 게 당연함.
- 시간이 많이 들어간다: 물론 모든 스택을 공부하는 데 많은 시간을 쏟으면 모든 스택을 깊게 이해할 수 있다. 하지만 절대적으로 시간이 많이 소요된다.
3) ML Product, ML Team, ML Engineer
-
ML Product는 보통 다음과 같은 과정을 통해 만들어진다.
- 요구 사항 전달 -> 데이터 수집 -> ML 모델 개발 -> 실 서버 배포
- 요구 사항 전달
- 고객사 미팅(B2B) 또는 서비스 기획(B2C)
- 요구사항 + 제약 사항 정리
- ML Problem으로 회귀
- 데이터 수집
- Raw 데이터 수집
- Annotation Tool 기획 및 개발
- Annotation Guide 작성 및 운용
- ML 모델 개발
- 기존 연구 research 및 내재화
- 실 데이터 적용 실험 + 평가 및 피드백
- 모델 차원 경량화 작업
- 실 서버 배포
- 엔지니어링 경량화 작업
- 연구용 코드 수정 작업
- 모델 버전 관리 및 배포 자동화
-
ML Team
- 일반적인 ML Team 구성은 다음과 같다.
- 프로젝트 매니저 1명, 개발자 2명, 기획자 1명, 데이터 관리자 1명, 연구자 2명
- 하지만 다음과 같은 상황도 많다.
- 1명이 프로젝트 매니저 겸, 기획자 겸, 연구자 겸,...
- 1명이 개발자 겸, 연구자 겸, 데이터 관리자 겸,...
- 1명이 개발자 겸, 데이터 관리자 겸,...
- 일반적인 ML Team 구성은 다음과 같다.
-
Full Stack ML Engineer in ML Team
: Full Stack ML Engineer가 팀에서 하는 구체적인 업무-
Job 1: 실생활 문제를 ML 문제로 formulation
- 고객/서비스의 요구사항은 실생활 문제
- ML 모델이 해결 가능한 형태로 문제를 쪼개는 작업/가능한지 판단
- 기존 연구에 개한 폭 넓은 이해와 최신 연구의 수준을 파악하고 있어야 함
-
Job 2: Raw Data 수집
- 웹에서 학습 데이터를 모아야 하는 경우도 있음
- Web Crawler(Scraper) 개발해서 데이터 수집(저작권 주의)
- 사용 툴 예시 : Selenium + Chrome
-
Job 3: Annotation tool 개발
- 수집/제공 받은 데이터의 정답을 입력하는 작업을 수행하는 web application 개발
- 작업 속도와 정확성을 고려한 UI 디자인이 필요
- 다수의 Annotator들이 Client를 통해 동시에 서버로 접속. Annotation 작업을 수행
- 새로운 task에 대한 Annotation tool 기획 시 모델에 대한 이해가 필요할 수 있음
- 사용 툴 예시 : Vue.js, django, MySQL, docker
- annotation tool 예시: deeplabcut, object detection annotation tool
-
Job 4: Data version 관리 및 loader 개발
- 쌓인 데이터의 version 관리
- database에 있는 데이터를 model로 load하기 위한 loader package roqkf
- 사용 툴 예시: (빨간 애??), 파이썬
-
Job 5: Model 개발 및 논문 작성
- 기존 연구 조사 및 재현 (재현 성능은 Public benchmark 데이터로 검증)
- 수집된 서비스 데이터 적용
- 모델 개선 작업 + 아이디어 적용 -> 논문 작성
-
Job 6: Evaluation tool 혹은 demo 개발
- 모델의 prediction 결과를 채점하는 web application 개발
- 예) OCR 프로젝트 중 혼자 사용하려고 개발(정/오답 케이스 분석하는 웹페이지) -> 이후 팀에서도 활용 -> 모델 특성 파악을 위한 추가 요구 사항 발생 -> 요구 사항을 반영해 개선하다보니 모델 발전의 경쟁력이 됨
-
Job 7: 모델 실 서버 배포
- 연구용 코드를 production server에서 사용 가능하도록 정리하는 작업
- file server에 코드 + weight 파일 압축해서 version 관리
- production server에서는 Python worker에게 MQ를 통해 job을 전달
-
4) Roadmap
- Stackshare
- Frontend : Vue.js, Angular
- Backend : django, Flask, Rails
- Machine Learning : PyTorch, TensorFlow
- Database : MySQL, MariaDB, redis, amazon
- Ops : docker, github, aws
-
Full stack ML Engineer가 되기 어렵나요?
- 쉽다고는 할 수 없습니다.
- 다만 각 스택에서 점점 더 framework의 발전이 interface가 쉬워지는 방향으로 발전하고 있기 때문에, 초~중급 정도의 구현을 하는 것이 점점 더 쉬워 질 것
- ML : TensorFlow 1.0 -> PyTorch & TensorFlow 2.0
- Frontend: vanilla js -> jQuery -> React, Vue.js
- Backend: spring -> django, Flask
-
염두 할 것
-
시작이 반이다? - 시작이 80%다.
- 모든 스택이 공통적으로 시작이 가장 어렵다.
- 익숙한 언어 + 가장 적은 기능 + 가장 쉬운 Framworkd로 시작하기
- 하나를 배우고 나면 나머지를 배우는 것은 훨씬 쉽다.
-
처음부터 너무 잘하려고 하기 보단, 최대한 빨리 완성하자.
- 모든 스택의 안태 패턴을 모두 신경쓰다가 포기하기 보다는 조금 부족하더라도 완성에 집중하자.
- full stack 개발의 매력은 '완성에서 오는 재미'
- 완성된 코드에 기능을 더해가다보면 자연스레 코드도 개선될 것
- 재미를 느끼고 반복적으로 완성하면 실력이 는다.
-
전문 분야를 정하자.
- 모든 스택에서 초~ 중급 수준을 계속 유지하기 보다는 하나의 잘하는 것이 있고 다른 것들은 할 줄 아는 정도인 것이 더 낫다.
- Angrej Karpathy의 "Yes you should understand bakprop" 읽어보기
- 풀스택 개발자라도 전문 분야에 대해 요하는 깊이가 다르다.
- 적어도 한 분야는 깊이 있게 알아야 한다.
-
새로운 것에 대한 두려움을 없애기 위해 반복적으로 접하자.
- frontend개발이 어렵고 자신이 없다면, 회사에서 frontend 개발을 할 수 있는 기회를 찾아라
- 배우고 싶었던 스택에 대한 문서 + 유투브를 쉬운 것부터 재미로 보자
- 해당 스택을 잘하시는 분께 여쭤보자
-
-
어떻게 시작하는 것이 좋을까요?
- 만들 줄 알아야 만들고 싶은 것이 생기기 때문에 처음에는 주제 잡기가 어렵다..그래서 하나 추천하면
- 과제: 하나의 논문을 구현하고, demo page를 만들어보기
- ML 논문을 읽고 재현해보고 -> 터미널 말고 Web에서 이 모델을 돌려보고(backend, frontend) -> 로그인 기능 같은 것을 붙여보거나 인증 방식 붙여보기(DB)
박은정 : AI 시대의 커리어 빌딩
1) 학교를 가야 하나요? 회사를 가야 하나요?
- 먼저 두 조직의 목표의 차이를 이해하는 게 중요
- 학교는 논문을 써서 연구 성과를 만드는 것이 목표
- 회사는 서비스/상품을 만들어서 돈을 많이 버는 게 목표
- 논문을 쓰고 싶어요 : 학교 > 회사
- 회사는 논문을 쓸 시간적 여력이 부족할 수 있음
- 학교는 논문을 쓰는 방식을 지도 받을 수 있음
- 상품/서비스를 만들고 싶어요 : 학교 < 회사
- 회사는 상대적으로 데이터, 계산 자원이 풍부함
- 다 정에되어 있는 작은 규모의 토이 데이터가 아니라 어마어마한 양의 트래픽을 통해 발생되는 대규모의 리얼 데이터를 만질 수 있음 (따라서 궂은 일도 기꺼이 맡아 할 수 있어야 함)
2) AI를 다루는 회사의 종류
- AI for X : AI를 통해 기존 비즈니스를 더 잘하려는 회사
- 비용을 줄이거나, 품질을 높이는 데 AI 사용
- AI는 보조 수단, 대부분의 회사가 여기에 해당
- AI centric : AI로 새로운 비즈니스를 창출하려는 회사
- 새로운 가치창출을 하는 데 AI를 활용
- 신생 회사들이 많음(ex.테슬라)
3) How to start my AI engineering career
-
자신을 이해하라.
- 나는 기초 학문을 좋아하고 잘하는가?
- 결과가 나오지 않아도 꾸준히 팔 수 있는 인내심이 있는가?
- 나는 AI/ML 모델링 뿐만 아니라 그 과정에서 발생하는 모든 일(웹프로그래밍, 데이터 전처리)을 기꺼이 할 수 있는가?
--> 연구자 - 나는 비즈니스에 관심이 있는가?
- 내가 만든 모델을 사람들이 쓰면서 실생활에 변화가 있길 바라는가?
- 나는 AI/ML 모델링 뿐만 아니라 그 과정에서 발생하는 모든 일(웹프로그래밍, 데이터 전처리)을 기꺼이 할 수 있는가?
--> 엔지니어
-
학교를 다니는 동안 AI 관련 인턴십, 아르바이트를 하라.
- 각 포지션의 차이에 대한 이애가 더 생길 수 있음
- 각 팀이 무엇에 관심을 가지는지 체감할 수 있음
- '일'하는 방법을 알게 됨(나의 고객이 누구인지, 일정을 어떻게 세우고 맞추는지 등)
-
AI 대회를 나가보자(ex. 캐글)
- forum이 활발하고 내용이 풍부
- 머신러닝은 hands-on으로 문제를 풀어보는 게 중요
-
최신 논문을 재현해보자
- 장점: 논문에는 빠져 있는 내용이 많기 때문에, 하나의 논문을 수현하는데는 수많은 백그라운드가 필요하다
- 유의점: 업무에서 이 능력만 활용하는 사람은 매우 드물다.
- 참고 : https://paperswithcode.com/rc2020
-
FAQ
-
회사를 가기 위해 석사/박사를 해야 하나요?
- No
- 다양한 곳에 지원하고 가장 많이 성장할 수 있는 곳을 선택
- 배울 수 있는 사람이 있는가?
- 풍부한 데이터/계산 자원이 있는가?
- 집중할 수 있는 문화인가?
-
X를 꼭 배워야 하나요?
- 근본이 되는 과목인 수학, 통계, 물리 등은 아는 게 좋음
- 범위를 확장해 가면서 필요한 무기를 그 때 그 때 배워도 됨
-
어떤 역량을 쌓아야 할까요?
- '일'을 잘하는 사람
- 공통적인 기술/학문적 역량
- 컴퓨터 공학에 개한 기본적인 이해와 소프트웨어 개발 엔지니어 능력
- 최신 기술을 빠르게 습득하기 위한 영어능력
- 공통적인 soft skills
- Grit: 끈기 있는 자세
- Humility: 현재 능력에 만족하지 않고 끊임없이 공부
- Passion: 즐길 수 있는 열정
- Teamwork: 다른 사람과의 협력
- Kindness: 세상르 이롭게 하는 기술 개발
-
제가 가진 역량을 어떻게 보여줘야 할까요?
- 팀으로 일하기 때문에 다 잘할 필요는 없다.
- 실력을 보여줄 수 있는 강한 한 방이 있으면 됨
- Coding competitions : ICPC 등 규모가 큰 프로그래밍 대회에서 입상 경력이 있는지
- AI competitions: Kaggle 등 규모가 큰 AI 관련 대회에서 수상한 경력이 있는지
- Publication record: NeurIPS 등 AI 관련 주요 국제 학외나 워크샵에 1저자로 출판한 논문이 있는지
- 서비스 경험 : 경력자의 경우 실제로 라지 스케일 서비스를 다뤄봤으며 그 과정을 주도했는지
- 다른 회사 경력: 다른 AI관련 회사의 근무 경험과 성과
-
4) 요약
-
AI 관련 각 포지션의 이름은 아직 완전히 합의 된 것이 아님. 따라서 모집 공고를 꼼꼼히 읽자(같은 이름인데도 다른 업무를 할 수도 있음)
-
각 사람이 100% 하나의 역할만을 수행하는 경우는 드물다
-
나의 관심사와 능력 뿐 아니라 시장의 흐름과 수요/공급을 고려해서 커리어 방향을 정하면 더 많은 기회가 열릴 것
-
모든 것을 잘하려고 하기보다 팀에 기여할 수 있는 나만의 엣지를 키우는 것이 더 중요
질문 및 회고

오 내용 정리가 잘되어있어서 잘 봤습니다 ㅎㅎ 좋은 글 감사합니다!