Multi Sample Dropout
Dropout
- Model 정규화 방법 중 하나로, train 단계에서 일부러 모델에서 랜덤으로 퍼셉트론을 지우고 학습하는 방법이다. 그 과정에서 그 퍼셉트론에 연결된 가중치들도 의미없는 값이 된다.
- 구현할 때는 일단 계산한 후 0 or 1 마스크를 곱해 결과값을 0으로 만들어버리는 방식으로 구현한다. 매번 미니 배치가 들어올 때마다 무작위로 다른 퍼셉트론들을 끊어낸다. 이 과정에서 약간씩 다른, 엄청 다양한 구조가 학습된다고 생각할 수 있다. 한번 끊은 퍼셉트론이 다시 연결이 안 되는 경우에는 퍼셉트론이 가지치기(pruning)되었다고 이야기한다.
- 쉽게 말하면 원래 촘촘히 학습 시킬 것을 오버 피팅을 막기 위해 느슨하게 학습시키는 방식이다.
(참고: https://deepestdocs.readthedocs.io/en/latest/004_deep_learning_part_2/0042/)
Multi Sample Dropout
논문 : https://arxiv.org/pdf/1905.09788.pdf
Multi Sample Dropout 개요
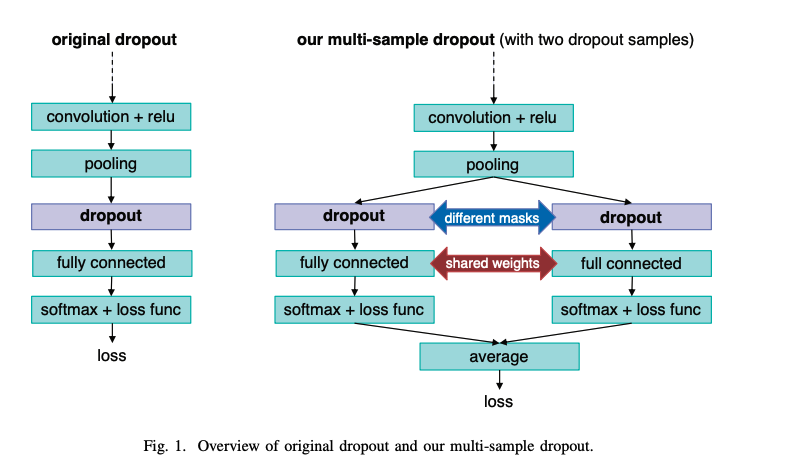
- Multi Sample Dropout은 Dropout을 하나만 사용하는 것이 아니라, 여러 개의 dropout 후보군을 두고 그 결과를 평균을 취해 결과 값을 내보내는 방식이다.
- Multi Sample Dropout에서는 dropout 레이어와 dropout 레이어 뒤에 오는 레이어들이 여러개 존재한다.(위 그림에서는 'dropout', 'fully connected', 'softmax+loss func'가 2개씩 있다.)
- 각 Dropout sample에서는 다른 mask를 사용하여 각 dropout 레이어는 서로 다른 퍼셉트론을 끊어낸다. 즉, 뉴런의 서로 다른 부분 집합을 사용한다.
- 하지만 여러 개의 dropout sample들은 파라미터는 공유한다.
- 각 dropout sample 마다 같은 loss 함수를 사용하여 loss를 구하고, 이를 평균 내서 최종 loss를 구한다.
- 그림에서는 2개의 dropout samples 을 보여줬지만, 논문에선 64 samples 까지 시도한다.
Multi Sample Dropout을 쓰는 게 왜 좋은걸까?
-
Higher accuracy
- dropout이 추가되는 등 noise가 있는 모델을 학습시킬 때에는 noise 상에서의 marginal likelihood를 최적화해야 한다. ->
- SGD optimizer는 유한한 개수의 sample을 바탕으로 근사 marignal likelihood를 objective function으로 활용하여 사용한다.(SGD에서 파생된 다른 optimizer들도 해당된다) ->
- 이 때 SGD likelihood는 marginal likelihood의 lower bound가 되는데, dropout을 여러 개 사용할수록 이 높아져서 lower bound를 더 타이트하게 만든다고 밝혀졌다고 한다.(논문)
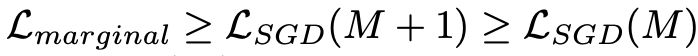
- 즉 dropout을 여러개 사용할수록 최적화하고자 하는 likelihood의 lower bound를 좁힐 수 있고, 이로 인해 accuracy가 더 높게 나올 수 있다.
-
학습 속도 가속 (매 이터레이션 학습 속도는 느려지지만, 전체적으로 보면)
-
같은 입력에 대해 서로 다른 ouput을 적용하여 n개의 sample을 뽑기 때문에 mini-batch의 크기를 n개 만큼 뻥튀기 시키는 효과를 가져온다.
-
다시 말해 <A, B> 라는 인풋이 들어오면 <A, A', B, B'> 샘플로 학습하는 효과를 낼 수 있다. 물론, Dropout이 없어서 <A, A, B, B> 를 학습하게 되면, 즉, sample간의 diversity가 없어지게 되면 multi-sample dropout 을 적용하는 의미가 없어진다.
-
또한 mini-batch를 늘리는 효과를 가져와서 더 다양한 경우를 학습하는 효과를 낼 수 있다.
-
-
직관적으로 보면 Self-Ensemble 효과도 있다고한다.
(참고 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=wpdls6012&logNo=221987417356)
실험 결과
Trends in error rates for validation set and training set against training time for original dropout and multi-sample dropout
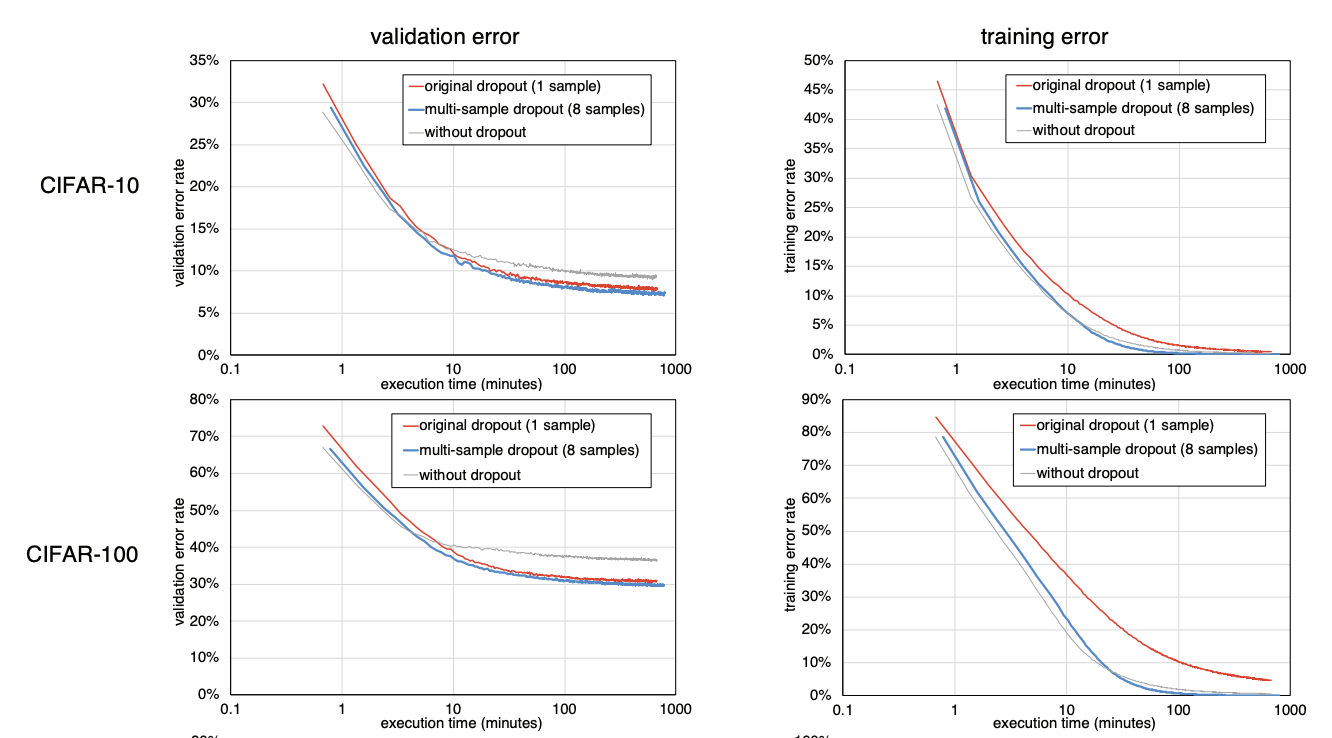
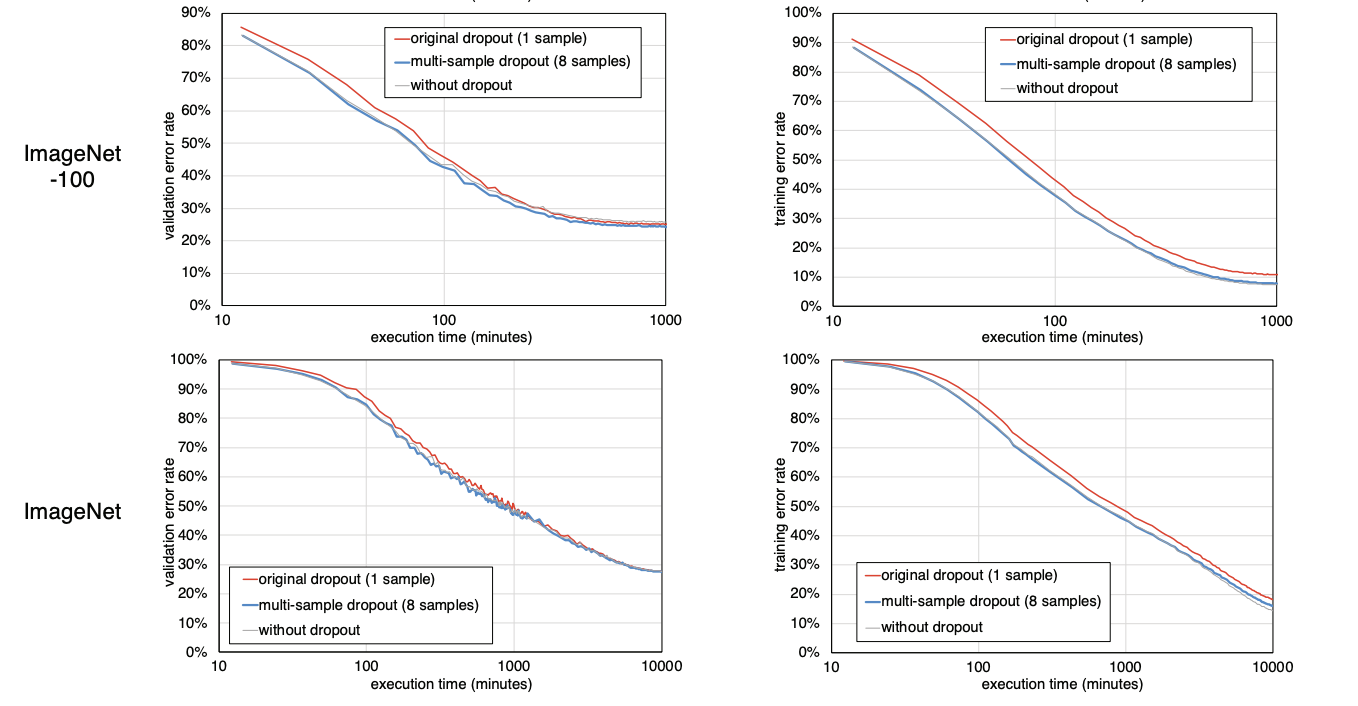
- Image Classification에 활용되는 대표적인 데이터셋 4개를 대상으로 dropout 하나를 이용하는 것과 multi-sample dropout(sample 8)을 이용하는 것의 error rate을 비교한 그래프이다.
- 대체적으로 multi-sample dropout 방식이 시작 error rate이 작고 계속 감소함을 유지하는 것을 알 수 있다.
- 하지만 시작을 제외하면 감소 추이는 그냥 dropout 하나랑 비슷하고, 오히려 학습 시간이 어느 정도 지나면 둘이 비슷해 지는 것 같긴하다.
- 논문 실험결과에서 적정 dropout sample size는 8, 16 정도가 합리적이라고 나오는 데 이건 경우에 따라 달라질 것 같다.
Pretrained Model에서 활용
- Transfer learning: 모델 학습을 위한 데이터가 충분하지 않을 때, 유사한 task를 목적으로 이미 학습된 모델을 가져와서 하고자 하는 프로젝트 task에 맞게 조정하여 학습하는 방식을 말한다.
- Pretrained Model : Transfer learning을 할 때 사용하는 이미 학습된 모델을 말한다.
- Pretrained Model을 사용할 때에는 대부분 모델의 내부 구조를 변경하지 않는다. 특히 새로 학습을 시키지 않고 학습된 weight을 사용하기 위해서는 모델의 내부 구조를 변경하지 않는 것이 좋다.
- 따라서 Pretrained Model을 사용할 때에 오버피팅이 되는 경우, dropout을 넣고 싶어도 모델 내부 레이어마다 dropout을 끼워 넣기보다 fine tunning 하려는 레이어에서 다양하게 dropout을 주고자 할 때 Multi sample Dropout을 사용할 수 있다.
(참고 : https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/discussion/100961)
Multi Sample Dropout 구현
- 코드로 Multi Sample Dropout을 구현하면 다음과 같다.
class BertForJigsawV2(BertPreTrainedModel):
def __init__(self, config, out_dim=8):
super(BertForJigsawV2, self).__init__(config)
self.out_dim = out_dim
self.bert = BertModel(config)
# dropout samples 생성
self.dropouts = nn.ModuleList([
nn.Dropout(0.5) for _ in range(5)
])
self.linear = nn.Linear(config.hidden_size, out_dim)
self.apply(self.init_bert_weights)
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None):
_, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
# Sample 마다 다르게 dropout 적용, 그 이후 linear layer는 sample끼리 weight 공유
for i, dropout in enumerate(self.dropouts):
if i == 0:
h = self.linear(dropout(pooled_output))
else:
h += self.linear(dropout(pooled_output))
return h / len(self.dropouts)(참고 : https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/discussion/100961)
참고 자료
-
관련 블로그 포스트
-
사용한 캐글 수상자 게시글: https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/discussion/100961
