go언어의 Map 자료구조에 대해 알아보고, 활용 방안에 대해 적어보려고 한다.
Map
맵은 키와 값 형태로 데이터를 저장하는 자료구조 이다.
언어에 따라 해시테이블, 해시맵, 딕셔너리 등으로 불리는데,
Go언어에서는 맵(map)이라고 한다.
키-값 쌍으로 데이터를 저장하며, 사전과 같다.
사전에 단어를 입력하면 단어의 의미를 알 수 있듯이
단어가 키(Key)가 되고, 단어의 의미가 값(value)이 된다.
또한 container 패키지가 아닌 Go 기본 내장 타입으로 패키지를 가져오지 않고 사용할 수 있다.
Map의 원리
맵은 해시 테이블을 기반으로 구현되어 있다.
해시 테이블은 키-값 쌍을 효율적으로 저장하고 검색하기 위한 데이터 구조로, 메모리 내부에서 배열과 포인터를 사용하여 구현된다.
맵의 키가 해시 함수를 통해 해시값으로 변환되고,
이 해시값을 인덱스로 사용하여 배열의 특정 위치에 버킷이라고 불리는 곳에 키-값 쌍이 저장된다.
맵의 원리를 제대로 파헤치기 위해 해시 함수와 해시 맵에 대해 더 알아보자.
해시 함수
해시(Hash)란 잘게 부순다는 뜻이다.(감자를 잘게 부순 해시브라운처럼)
해시 함수는 3가지 특징을 만족해야 한다.
1. 같은 입력이 들어오면 같은 결과가 나온다.
2. 다른 입력이 들어오면 되도록 다른 결과가 나온다.
3. 입력값의 범위는 무한대이고 결과는 특정 범위를 갖는다.
f(x) = sin(x) 삼각 함수를 예로 들 수 있다.
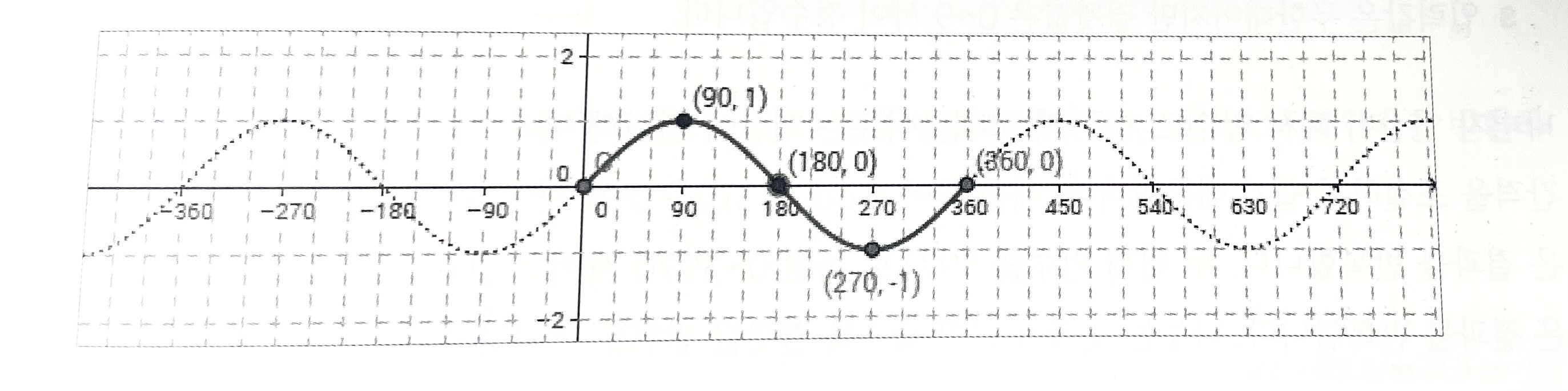
- 같은 입력이 들어오면 같은 결과 반환 - sin(90)은 언제나 1
- 서로 다른 값을 넣으면 다른 결과 반환 - sin(90) != sin(91)
- 입력값의 범위는 무한대 이지만, 결과값은 -1 ~ 1 사이로 고정
해시 테이블
해시 테이블은 배열로 구성된 버킷이라는 공간으로 이루어져 있다.
각 버킷은 해시값에 해당하는 인덱스를 가지고 있고,
해당 인덱스에는 키-값 쌍이 저장되는 자료구조이다.
즉, 해시 함수를 사용하여 키를 해시값으로 변환하고
-> 이 해시값을 배열의 인덱스로 사용하여 데이터를 저장한다.
해시를 맵으로
해시 테이블을 이해했다면, 맵으로 다시 돌아가보자.
Go의 맵은 해시 테이블을 기반으로 구현되어 있는데, 메모리 내부에서 배열과 포인터를 사용하여 구현된다.
삼각 함수보다 쉬운 나머지 연산을 예시로 설명해보자면..
package main
const M = 10
func hash(d int) int {
return d % M
}
func main() {
m := [M]int{}
m[hash(23)] = 10 // 키 23에 10 이라는 값을 설정
m[hash(259)] = 50 // 키 259에 50 이라는 값을 설정- 나머지 연산에서 나누는 수를 배열의 크기로 삼는다
- 10으로 나누기 때문에 해시 함수의 결과가 1 ~ 9 범위를 갖기 때문
- hash() 함수로 배열 인덱스를 계산해 저장할 위치를 계산해 저장
해시 함수는 요소 개수와 상관없이 고정된 시간을 갖는 함수이기 때문에 해시 함수를 사용하는 맵은 읽기, 쓰기에서 O(1)의 시간값을 갖게 된다.
또한 키가 크다고 해서 해시 함수 결과값이 커지는 것도 아니기 때문에 맵은 키와 무관하고, 입력 순서와도 무관한 순서로 순회한다.
해시 충돌
23과 259는 10으로 나눈 나머지가 3, 9로 다르기 때문에 상관 없지만
예를 들어,
m[hash(23)], m[hash(33)] 이라면 어떻게 될까?
23과 33은 10으로 나눈 나머지가 3으로 갖기 때문에 인덱스의 위치가 3으로 같아버린다.
이것을 해시 충돌이라고 한다.
키 값(인덱스 값)이 같아 충돌하는 현상을 해시 충돌이라고 하는데,
단순한 방법으로는 '리스트 저장' 방법이 있다.
m[hash(23)] = 10
m[hash(33)] = 10두 값 모두 인덱스 3에 저장되는데,
이 때 키 값과 함께 리스트로 저장하는 방법이다.
즉, index 3위치에 (23, 10), (33, 50) 두 개의 값을 리스트로 저장하는 것이다.
이렇게 되면, 데이터를 읽을 때 해당 인덱스에 링크된 모든 리스트를 조사해 매칭되는 키의 값을 반환하면 해시 충돌 문제에 벗어나게 된다.
Map 활용
맵은 Go에서 아래와 같이 사용할 수 있다.
package main
import "fmt"
func main() {
m := make(map[string]string)
m["이화랑"] = "서울시 광진구"
m["송하나"] = "서울시 강남구"
m["백두산"] = "부산시 사하구"
m["백두산"] = "청주시 상당구"
fmt.Printf("송하나의 주소는 %s입니다.", m["송하나"])
}- make() 함수로 맵을 만든다.
make(key)value형태로 key와 vaule의 데이터 타입을 정의한다.- 예문에서
map[string]string는 key와 value가 모두 string으로 지정된 것이다. - 키에 해당하는 값이 없으면 추가되고, 이미 값이 존재한다면 값이 변경된다
- 따라서 '백두산'의 값은 '부산시 사하구'에서 '청주시 상당구'로 변경되었다.
- []안에 key를 넣으면 value를 읽을 수 있다.
맵의 반환값을 두개로 받을 수 도 있다.
v, ok := m["이화랑"]v: 값
ok: 값이 존재하는지 알려주는 boolean
반환값을 두 개로 받아 요소가 존재하는지 확인해볼 수 있다.
맵의 속도는 굉장히 빠르다.
- 추가: O(1)
- 삭제: O(1)
- 읽기: O(1)
따라서 맵을 사용하면 데이터를 매우 빠르게 처리할 수 있다.
맵 활용 예시
그렇다면 맵 자료구조는 언제 활용하는 것이 좋을까?
- 데이터의 순서가 중요하지 않고 키를 기반으로 빠른 데이터 처리가 필요할 때
- 고유한 키와 값이 필요한 경우
- 데이터의 동적인 증가와 변화가 있을 경우
: 맵은 크기가 동적으로 조절되며, 추가 제거가 쉽기 때문에 데이터의 동적인 증가와 변화에 유연하다. - 검색 속도가 중요한 경우
- 집합의 표현이 필요한 경우
: 값 부분을 활용하지 않고 키만 사용하면, 집합으로 사용될 수 있다. 고유한 키들의 컬렉션을 효과적으로 표현할 수 있기 때문이다.
맵을 집합(set)으로 사용할 때
웹 사이트의 방문자 로그를 기록하는 상황을 가정해보자.
각 방문자는 고유한 아이디를 갖고있다.
이러한 방문자 정보를 맵을 사용하여 표현할 수 있다.
이때 맵의 값 부분을 활용하지 않고 키 부분만 사용하여 고유한 방문자들의 정보를 저장한다.
package main
import "fmt"
func main() {
// 맵을 집합으로 사용
visitors := make(map[string]bool)
// 방문자 추가
visitors["user123"] = true
visitors["user456"] = true
visitors["user789"] = true
// 중복 방문자 확인
if visitors["user123"] {
fmt.Println("user123은 이미 방문한 사용자입니다.")
}
// 새로운 방문자 추가
newVisitor := "user999"
if !visitors[newVisitor] {
fmt.Printf("%s는 새로운 방문자입니다. 추가됩니다.\n", newVisitor)
visitors[newVisitor] = true
}
// 모든 방문자 출력
fmt.Println("전체 방문자 목록:")
for visitor := range visitors {
fmt.Println(visitor)
}
}맵을 단순히 고유한 값의 집합으로 사용한다.
중복 방문자 여부를 효과적으로 처리할 수 있다 -> 존재의 여부를 효과적으로 확인할 수 있다.
나는 이 방법을 SNS 서비스를 개발했을 때, 팔로잉 조회 기능에서 사용했었다.
사용자 리스트에서 팔로잉 여부를 구분할 때, 팔로잉 map에 사용자 아이디를 검색하여 팔로잉 여부를 확인할 수 있었다.
맵의 속성을 이해하고 적절한 때에 활용하면 더 빠른 속도를 낼 수 있을 것이다.
이처럼 어떤 자료구조가 어떤 동작에서 더 빠른지를 알면 더 효과적으로 프로그램을 작성할 수 있다.
