한동안 블로그 작성을 안 했는데....못한거였던걸로~ 오늘은 spring에서 elastic search, kibana를 세팅하는 방법에 대해서 적어보도록하겠다!!
서비스에서 검색엔진을 적용시켜야했고, 따라서 Solr, Elastic Search를 비교한다음 Elastic Search를 사용하기로 했다!
0. Intro 먼저! Elastic Search와 같은 검색엔진을 "왜" 사용하는지 알아보자!
이부분은 검색엔진 원리를 알아보며 이해했는데 다른 포스팅을 통해서 자세히 적어서 다시 공유하도록 하겠다! 결론만 말하자면 아래와 같다.
- 빠르다.
- 정확하다.
- 전문 검색에 효율적이다.
- 여러 조건을 걸었을 때에도 빠르다.
한마디로 QueryDSL을 사용할 때보다 검색 성능 향상이 된다는 것이다.
🧸 전문검색이란?
전문이란?Full Text Search를 의미하는데 Full Text란 블로그 글이나 뉴스 논문 등 긴 글부터
블로그 제목 논문 제목 등과 같은 짧은 글과 같은 글의 전체 내용을 의미한다.
- 전문검색 : 여러 문서에 전문이 존재할 때, 사용자가 검색 문장을 입력했을 경우 유사도가 높은 전문을 제공해주는 검색이다.
이때, Elastic Search는 빠르고 정확한 답변을 주기 위해서 모든 전문을 "용어"단위로 분리하고
이를 "역인덱싱"하여 전문에서 나온 여러 용어들을 index로 만들고 전문을 value로 한다.
사용자가 입력한 검색문장의 용어들이 있을 때 역인덱싱한 용어들과 비교하여
해당하는 용어의 index를 가지는 value인 전문을 찾아내는 기법을 사용한다.
이번에는 세팅방법을 설명할 것이기에 자세한 내용은 추가 포스팅을 통해 알아보도록하자!
1. spring에서 Elasitc Search를 사용하는 방법
Elastic Search는 Json을 형식으로 하고 HTTP 통신을 제공하기에 직접 Elastic Search Query 문법에 맞춰서 명령어를 입력하고 이를 HTTP 통신으로 주고 받아도 된다.
하지만 나는 빠른 도입과 유지보수를 고려하여 이미 잘 만들어져있는 Elastic Search Engine의 Sprign Client인 spring-data-elasticsearch를 사용했다.
1-1. spring-data-elasticsearch
결론) spring 3.0.6에서는 elastic-cleint 8.5.3이 downlaod되기에 elastic search, kibana version은 8.5.3이 되어야한다.
- gradle
implementation("org.springframework.boot:spring-boot-starter-data-elasticsearch")gradle에서 다음과 같이 implementation을 구성하고 의존성을 설정해주면 사용할 수 있다.
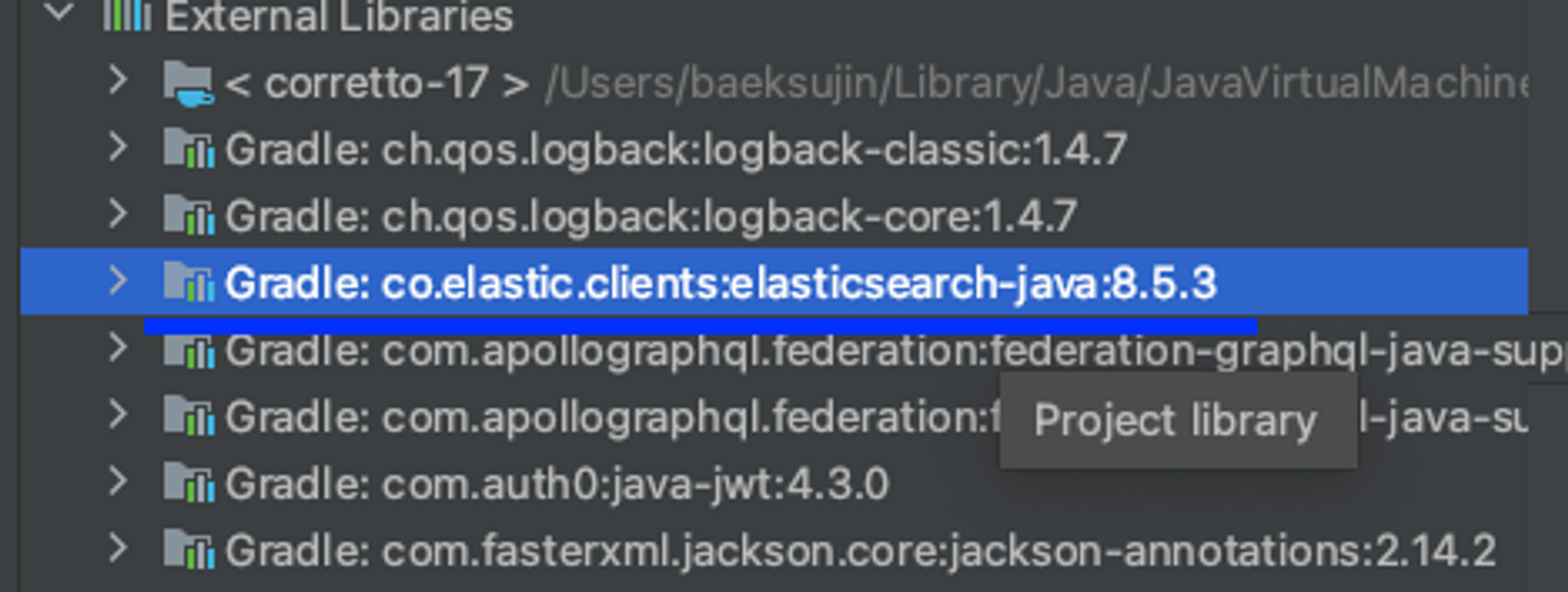
다음과 같이 library를 보면 8.5.3 version client가 설치된 것을 확인하면 되고 이 버전에 맞는 elasticsearch, kibana를 설치해줘야한다!
이부분을 먼저 체크하지 않아서 꽤나 헤맸는데 여러분들은 그러지 않기를 바랍니다,,,ㅜㅜ
그렇다면 이제는 client를 사용할 준비가 되었으니 elastic search를 다운받아서 사용하거나 docker container image를 사용해서 띄워줘야합니다.
1-2. docker image를 사용한 elastic search 환경 구성하기
version: '3.7'
services:
es:
image: docker.elastic.co/elasticsearch/elasticsearch:8.5.3
container_name: es
environment:
- node.name=es-node
- cluster.name=search-cluster
- discovery.type=single-node
- xpack.security.enabled=false
- xpack.security.http.ssl.enabled=false
- xpack.security.transport.ssl.enabled=false
ports:
- 9200:9200 # https
- 9300:9300 #tcp
networks:
- es-bridge
kibana:
image: docker.elastic.co/kibana/kibana:8.5.3
container_name: kibana
environment:
SERVER_NAME: kibana
ELASTICSEARCH_HOSTS: http://es:9200
ports:
- 5601:5601
# Elasticsearch Start Dependency
depends_on:
- es
networks:
- es-bridge
networks:
es-bridge:
driver: bridge
docker compose를 사용해서 kibana와 elasticsearch를 모두 함께 관리해줍니다.
여기서 kibana란?
🧸 Kibana란?
elastic search가 검색엔진이여서 검색 request, response를 처리해준다면
kibana는 log를 모니터링하거나 api 체크를 위해 사용하는 postman처럼 query를 날려볼 수 있는 UI
를 제공하는 elastic stack입니다.
그렇다면 docker-compose.yml file에 대해서 알아보자!
- image : docker에서 제공하는 elastic stack의 image를 넣어주면 되는데
:뒤에 version을 적어주고 우리가 사용하는 elastic search client와 맞춰준다. - container_name : 말그대로 image를 띄우면 container가 생성되는데 이때 container의 이름을 의미한다.
- environment : environment는 환경변수를 전달해줘야할때 사용한다.
1. elastic search : local에서 돌릴 것이기에 security는 false로 설정해준다.
security설정을 따로 하지 않는이상 해당 환경변수 설정이 없다면 돌아가지 않는다.
그리고 돌리다보면 memory exception이 발생할 수 있는데- ES_JAVA_OPTS=-Xms512m -Xmx512m #ERROR: Elasticsearch exited unexpectedly 대안 -> memory size up해당 줄을 environment에 추가하면 메모리를 늘릴 수 있다.
2. kibana : kibana는 어떤 elastic search와 연결할것인지 host를 정해줘야한다.
이때 우리는 container가 서로 연결이 되어있기에 es container를 사용한다. 따라서http://es:9200으로 해줘야한다. 만약에 elastic search의 image name을 es로 설정하지 않았고 elasticsearch라고 했다면?http:elasticsearch:9200이 될 것이다.
- ports
1. elastic search
docker container에서 허용할 port number를 적어줘야하는데 elasitc search는 node끼리의 통신을 하는데 이때 tcp(9300 port)를 사용하고 client와 node의 통신을 위해 http(9200 port)를 사용하게 된다.
2. kibana
kibana는 5601 port를 사용하게 된다.
- network
container들 사이의 network를 연결해줘야한다. 이때 bridge를es-bridge라는 이름을 가지도록 만들어주고 두개의 container에 각각 등록하면 된다. 이때 kibana는 elastic search가 먼저 띄워져야 작동하게끔 의존관계를 명시해야해서depends_on:es을 사용한다.
1-3. 실행
docker compose up -d
log를 보기 싫다면 background에서 돌리도록 deamon을 활용하도록 -d를 사용한다.
docker ps를 입력하면 실행중인 container를 확인할 수 있다.

지금 logstash도 같이 보이는데 logstash는 data pipeline을 위해서 사용했는데 이거는 Spring-ELK2에서 함께 살펴보도록하겠다~! 따로 살펴보는 이유는 할얘기가 많다...시행착오를 조금 생각보다 많이했다...~~!!
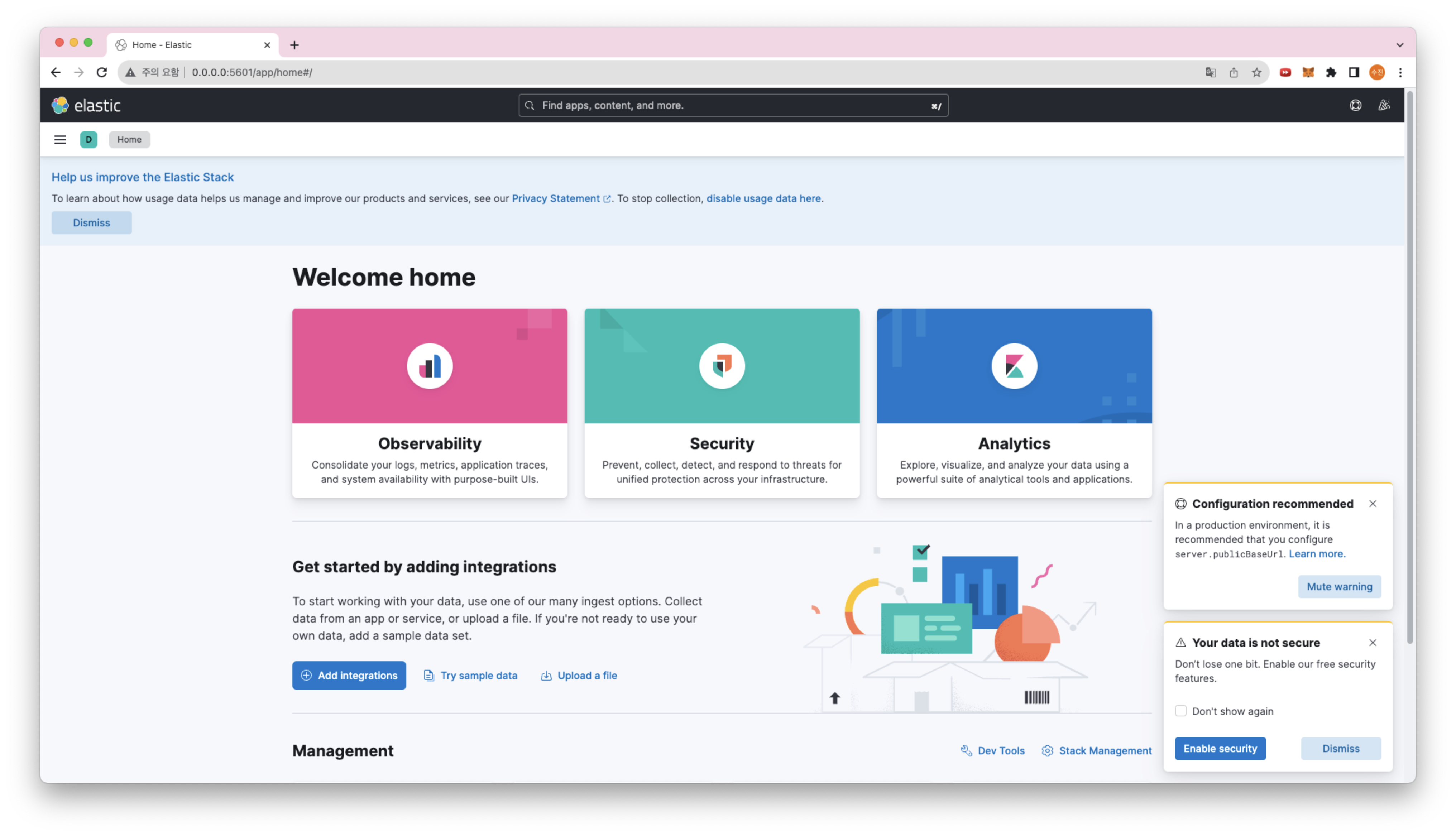
그리고, 여기서 아래와 같이 화면이 나온다면 성공이다!
-
kibana
-
logstash
2. spring에서 검색 api 만들기
api를 생성하려면? 기존에 Entity를 생성 -> Repository 생성 -> Service를 생성 -> Fetcher를 등록한다.
Fetcher단은? graphql을 사용하기 때문에 controller가 아닌 fetcher로 적었을뿐, controller단이라고 생각하면 된다.
자, 이 과정이랑 똑같다! elasitc search client의 ElasticsearchRepository를 사용해서 repository를 queryDSL을 사용하듯이 쉽게 사용할 수 있다.
그런데 우리는 지금 검색엔진을 만든다. 따라서 검색에 사용할 api라는 것인데 findById와 같은 query보다는 동적쿼리에 집중해서 알아볼 것이다.
여기서는 Criteria를 사용할 것이다.
우선 그전에, configuration을 등록해주자!
2-0. config
@Configuration
@EnableElasticsearchRepositories
@EnableConfigurationProperties(ELKProperties::class)
class ElasticSearchConfig(private val elkProperties: ELKProperties ) : ElasticsearchConfiguration() {
override fun clientConfiguration(): ClientConfiguration {
return ClientConfiguration.builder()
.connectedTo(elkProperties.host)
.build()
}
다음과 같이 구성하면 된다.
properties는 정의해서 사용하면 되는데 나는 아래와 같이 구성했다.
@ConfigurationProperties(prefix = "elastic")
data class ELKProperties(
val host: String?= null,
val username: String?= null,
val password: String?= null
)
username, password는 dev, prod환경을 위해서 넣어놨다!
2-1. criteria를 사용한 전문 검색 준비
지금부터 Item이라는 domain이 존재할때 Item 검색 api service를 만든다고 해보자!
지금 구현하려고 했던 것은, 검색어를 입력했을 때 완벽히 똑같은 구문을 포함할 때만 검색되는 것이 아닌 관련이 있다면 모두 검색하려는 것이다. 그때 Elasticsearch에서는 match_phrase를 사용하는데 spring-data-elastic client에서는 matches를 사용하면 된다.
- matches
전문 검색을 위해서 Elastic search query를 공부해보면 match가 존재한다. 이것은 완벽하게 똑같지 않아도 된다.우리가 핑크색 나이키 신발 을 검색했다고 하자.
여러 아이템들이 존재할 수 있는데 이때 핑크색, 나이키, 신발 해당하는 용어를 하나라도 가지고 있는 아이템이 존재한다면 해당 리스트들을 보여줄 수 있도록 할 것이다.
- operations
private val operations: ElasticsearchOperations
Criteria를 만들 때 의존관계를 주입해줘야한다.
ElaistcSearchOperation을 사용해서 우리는 elastic query를 사용할 수 있게 된다.
- Document
criteria는 사실 spring data jpa + queryDSL에 익숙해져서 까먹었었다!ㅎㅎㅎ
그래서 다시 문법을 살펴보고 적용했다!
원래 같으면 builder가 필수이지만, elastic criteria는 문법이 약간 다르다!
criteria는 repository이기에 그 전에는 entity를 작성하듯이 ElasticSearch에서는 Document 를 정의해줘야한다. 아래와 같이 작성하면 된다.
@Document(indexName = "item" )
@Setting(settingPath = "elastic/item-setting.json")
@Mapping(mappingPath = "elastic/item-mapping.json")
class ItemDocument(
@Id
val id: UUID,
var price: String,
var name: String,
var memo: String? = null
)
다른 feild들이 존재할 수 있지만 일단 우선으로 예제를 보여주기 위해서 다음과 같이 간단하게 작성해봤다!
- Mapping
이때, elasticsearch에서는 mapping을 사용하여 index(DB에서의 table개념)의 Field(RDB에서의 Column개념)의 type과 매핑을 해줘야한다.
직접@Fieldannotation을 사용해서 매핑해도 되지만, 만약에 많아진다고 해보자! 그럼 annotation을 필드마다 적어주면 된다. 그러나 보기싫다. ㅎㅎㅎㅎㅎㅎㅎ
따라서 관리하기 편하게@Mapping을 사용해서 mapping annotation을 사용한다.
{
"properties" : {
"id" : {"type" : "keyword"},
"price" : {"type" : "integer"},
"name": {"type": "text", "analyzer": "korean"},
"memo": {"type": "text"}
}
}keyword, text의 차이점은 text는 전문검색용이고 keyword는 해당 키워드를 완벽히 똑같이 포함해야 검색한다. ID값은 unique한 값이기에 keyword로 하고 title, content는 text여야 검색한 구문이 완벽히 똑같지 않아도 찾아낼 수 있는 것이다.
analyzer는 setting시에 등록해줘야한다. setting하는 방법은 mapping처럼 @Setting을 사용하면 된다.
- Setting
{
"analysis": {
"tokenizer": {
"whitespace_tokenizer": {
"type": "whitespace"
},
"nori_none": {
"type": "nori_tokenizer"
},
"nori_discard": {
"type": "nori_tokenizer"
},
"nori_mixed": {
"type": "nori_tokenizer"
}
},
"analyzer": {
"english": {
"type": "whitespace"
},
"korean": {
"type": "nori"
}
}
}
}나는 영어에서는 whitespace를 사용할 것이고 한국어 tokenizer는 nori를 사용할 것이다.
analyzer를 사용하려면 tokenizer가 등록되어야만 가능하다!
token화를 할 때 한 token으로 analyzer를 사용해야하기 때문이다.
- 구조
구조는 아래의 사진과 같아야한다.
resources 폴더 안에 elastic 폴더를 만들고 그 안에 item-mapping.json과 item-setting.json을 넣어놨다!
물론 디테일한 경로는 바꿔도 좋은데,resources에 넣어놔야 경로를 찾을 수 있으니 주의하자!
- nori-tokenizer download
nori tokenizer는 설치해야한다.
docker compose up -d 시에 elastic search container를 띄우는데 container에 접속해서 다운하면 된다.
https://esbook.kimjmin.net/06-text-analysis/6.7-stemming/6.7.2-nori
여기서 설치 방법을 잘 알려준다.
docker exec -it pid /bin/bash을 통해서 접속한다.
중간에 의식의 흐름대로 쓴 코드가 있는데 눈감아주면 좋겠다,,,ㅎㅎ
결국 elasticearch-plugin install analysis-nori 명령어를 사용한다.
그리고 docker restart es 를 통해서 컨테이너를 재시작해주자!
2-2. Criteria 작성
@Repository
class ItemDocumentCriteria(
private val operations: ElasticsearchOperations
) {
fun findItemsBySearch(search: ItemSearch): MutableList<ItemDocument>? {
val query: CriteriaQuery = createCriteriaQueryByCondition(search)
val searchHits: SearchHits<ItemDocument?> = operations.search(query, ItemDocument::class.java)
return searchHits.stream()
.map{ it: SearchHit<ItemDocument?> -> it.content }
.collect(Collectors.toList())
}
private fun createCriteriaQueryByCondition(search: ItemSearch): CriteriaQuery{
if (search.nameCondition == null){
return CriteriaQuery(Criteria())
}
return CriteriaQuery(Criteria("name").matches(search.nameCondition!!))
}
}name을 기반으로 했을 때 사용자가 입력한 값을 ItemSearch kolin의 dataClass에 format을 넣어두고 이를 사용했다.
현재는 Name만 사용해봤는데 dataClass에 값을 더 넣으면 여러 조건들을 기반으로 검색을 할 수 있을 것이다.
data class ItemSearch(
val nameCondition: String?= null
)
다음과 같이 작성했는데 사용자가 입력한 검색구문을 ItemSearch에 넣어준다.
이로써 사용할 repository는 작성완료했다!
이를 활용해서 나머지 Service, Fetcher를 작성하면 된다!
의문점
여기서 궁금한점이 생길 것이다. Item이 등록될 때마다 application에서 사용하는 DB에 넣어주듯이 Elastic Search에도 넣어줘야 query가 가능하다. 그러면 Item을 등록하거나 수정할 때 Elasitc Search와 DB에 둘다 넣어주려면 put Query와 update Mutation을 entity 그리고 document에 대해서 각각 api를 1번씩 총 2번 호출해야하는가?
자 이때 Logstash를 사용한다.
Logstash를 사용하면 Spring Application의 DB에 데이터가 들어갔을 때 특정 주기마다 읽어와서 Elastic Search의 DB에 저장하도록 Pipeline을 작성할 수 있게 된다.
마무리
spring에서 elasitc search 그리고 kibana를 사용하는 세팅하고 사용하는 방법에 대해서 알아봤다.
Elastic Search를 이해하고 왜 사용하는지 알려면 그 원리를 한번 제대로 이해해보면 쉽게 사용하게 될 것이라고 생각했다. 그래서 나도 그렇게 학습했는데 개념을 알고나니 사용하기 쉬워졌다. 따라서 다음 포스팅은 Elasitc Search 자체에 대해서 적어보려고한다. 그리고 Logstash를 연동하여 data pipeline을 작성하는 것을 해보자!
logstash와 동작 구현을 보여드리는 것은, 직접 project를 만들어서 예제를 보여드리기 위해서,,조금 시간이 걸릴 것 같습니당..

글 잘 봤습니다.