다루는 내용
정보이론
- information
- entropy
- cross entropy
- KL divergence
- mutual information
- chain rule
- jensen's inequality
Information
Information(정보)란 무엇일까요?
정보이론에서는 불확실성을 줄이는 데 기여하는 데이터를 의미합니다.
불확실성을 줄인다는 것은 어떤 사건이 일어날 가능성을 알게 됨으로써 얻는 새로운 지식의 양을 의미합니다.
이게 무슨 소리냐?
예를 들어, "지구는 자전한다"라는 진술을 생각해봅시다. 우리가 당연하다고 알고 있는 이 내용은 우리에게 중요한 정보일까요? 정보이론에서는 그렇지 않다고 말합니다. 왜냐하면, 이 진술은 과학적으로 확립된 사실로 참일 확률이 매우 높고 거의 확실한 사건이기 때문입니다. 너무나도 당연하고 바뀔 가능성이 적은 사실, 즉 확률이 매우 높은 사건은 이미 우리가 잘 알고 있는 사실입니다. 이러한 사실은 새로운 정보를 거의 제공하지 않기 때문에, 우리가 가진 불확실성을 줄이는 데 크게 기여하지 않습니다. 따라서 "지구는 자전한다"라는 진술이 제공하는 정보의 양은 거의 0에 가깝습니다.
즉, 확률과 정보량은 다음과 같이 정리할 수 있습니다.
확률과 정보량
- 확률이 높은 사건: 이미 잘 알려진 사실이므로, 그 사건이 일어났다고 해서 우리의 지식이 크게 변화하지 않습니다. 따라서 이런 사건이 제공하는 정보는 적습니다.
- 확률이 낮은 사건: 일어나기 어려운 일이 일어났다면, 이는 우리의 예상을 크게 벗어나는 새로운 지식이 됩니다. 따라서 이런 사건이 제공하는 정보는 많습니다.
그래서 어떤 사건이 발생할 확률이 클수록, 그 사건이 제공하는 정보는 적고, 반대로 확률이 작을수록 제공하는 정보는 많다고 할 수 있습니다.
쉽게 말해, 예상치 못한 일일수록 우리에게 더 많은 정보를 준다는 것입니다.
수식
이를 수학적으로 표현한 것이 정보량 공식입니다:
- : 사건 가 발생했을 때 제공되는 정보의 양
- : 사건 가 발생할 확률
- : 밑 를 가진 로그 함수, bit(2진수)로 표현하기 위해 보통 를 사용한다.
여기서 는 사건 가 발생할 확률이고, 정보는 이 확률의 를 붙여서 표현합니다. (확률과 정보가 반비례 관계에 있으므로 역수에 로그는 취하는 것)
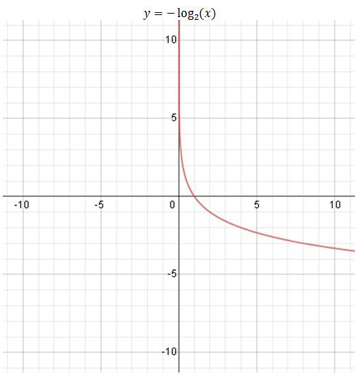
즉, 확률은 0과 1 사이의 값으로 제한되므로 위 그래프처럼 확률이 낮으면 값이 커지고, 확률이 높으면(1에 가까우면) 값이 작아집니다(0에 가까워집니다).
참고로, 가 정보의 최소 단위인 Bit(0또는 1의 이진 데이터)인 이유는, 는 밑이 2인 로그 함수로, 주어진 숫자를 2의 거듭제곱 형태로 표현할 때 필요한 지수를 반환합니다. 즉, 는 를 2의 몇 제곱으로 표현할 수 있는지 나타내는 지표라고 볼 수 있습니다.
entropy
그렇다면 entropy는 무엇일까요?
entropy는 어떤 확률 분포 p의 정보의 양을 측정하는 방법으로, 정보의 기댓값(평균)을 계산하여 구하고 다음과 같이 표현됩니다.
수식
- : 확률 변수 의 엔트로피
- : 확률 변수 가 값을 가질 확률
- : 밑 를 가진 로그 함수
차근차근 수식을 살펴보면, 사건 가 실제 일어날 확률을 라 할 때, (가 나올 확률)x(사건 에 대한 정보) 를 모든 사건 에 대해서 더하므로
결국 분포의 평균적인 정보양(불확실성)을 의미하는 것입니다.
이해를 돕고자, 모든 면이 나올 확률이 으로 같은 이상적인 주사위가 있다고 생각해봅시다. 이 주사위의 엔트로피는 높을까요, 낮을까요?
정답은 높다입니다.
주사위의 엔트로피 를 직접 계산해보면 다음과 같습니다.
(bit)
2.58 bit를 가지는 것을 알 수 있죠.
그렇다면 숫자 1만 나오는 특이한 주사위가 있다고 생각해봅시다. 이 주사위의 엔트로피는 어떨까요?
정답은 낮다 입니다.
주사위의 엔트로피 를 직접 계산해보면 다음과 같습니다.
이 경우에는 엔트로피가 0입니다.
즉, uniform (flat) 분포에 가까운 확률 분포일수록 어떠한 값이 나올지 불확실하다는 것이기에 높은 엔트로피를 가집니다. 하지만 반대로 특정 값의 확률이 높은 sharp한 분포일수록 어느 정도 어떠한 값이 나올지 예상할 수 있기 때문에 낮은 엔트로피를 가집니다.
cross entropy
그렇다면 cross entropy 는 무엇일까요?
AI에서 loss로 굉장히 많이 사용되는 cross entropy는 확률 분포 P를 다른 확률 분포 Q로 표현했을 때의 필요한 평균적인 정보의 양(비트 수)을 의미합니다.
즉, 실제 분포 P에서 발생한 사건에 대한 정보가 예측한 Q와의 차이로 인해 얼마나 손실되는지를 의미합니다. 즉, 가 클수록 모델이 실제 분포를 잘 예측하지 못하고 있는 상황이며, 이는 손실되는 정보가 많다는 것입니다.
수식
수식을 살펴보면, 사건 가 실제 일어날 확률을 , 내가 예측한 사건 발생 확률을 라고 했을 때, (실제 가 나올 확률)x(내가 예측한 사건 에 대한 정보) 를 모든 사건 에 대해서 더하므로 결국 의 정보를 에 대해 평균을 구한 것이라고 볼 수 있습니다.
--> 실제 분포 P를 기반으로 모델 Q의 예측을 평가
이 때, 확률은 0에서 1사이에 값을 가지므로
-
P와 Q가 완전히 다르면 (예측 결과가 완전히 오답이면) 무한대의 값이 나옵니다.
예를 들어 가 0.9이고 가 0.1이면 가 매우 커져 최종적으로 매우 큰 값이 됩니다. 물론, 가 0.1이고 가 0.9일 때는 아주 작은 값이 아니냐 라고 생각하실 수도 있겠지만, 그래프를 보시면 아시다시피 가 클 때 값이 작아지는 정도보다 가 작을 때 값이 커지는 정도가 훨씬 큽니다. 그러므로 최종적으로는 P와 Q의 차이가 클수록(예측이 틀릴수록) cross entropy는 큰 값이 나옵니다. -
반면, P와 Q가 비슷하면 (예측 결과가 정답에 가까우면) 원래 P의 entropy와 비슷한 값이 나옵니다.
cross entropy를 AI 모델의 loss로 사용하여 loss가 낮아지도록 학습시킨다는 것은 결국 모델이 정답을 더 잘 예측할 수 있도록 한다는 것을 의미합니다.
KL divergence
이번에는 Kullback-Leibler Divergence(KL divergence)에 대해서 알아봅시다.
KL divergence는 확률 분포 와 사이의 차이를 측정하는 지표로 수식은 다음과 같습니다.
왜 이렇게 수식이 정의되는 것일까요?
차근차근 생각해보면 간단합니다.
앞서 설명했듯이, cross entropy에서 P와 Q가 다를수록 값이 커지고, 같을수록 P의 entropy와 가까워집니다.
그렇다면 오로지 P와 Q가 얼마나 다른지 그 차이값을 알고 싶다면 cross entropy에서 P의 entropy를 빼면 됩니다. 이렇게 하면 P와 Q가 다를수록 값이 커지고, 같아지면 차이는 0이 됩니다.
이것이 바로 KL divergence 입니다.
실제로 수식을 유도를 해보면
인 것을 알 수 있습니다.
이를 통해 KL divergence 의 특성에 대해서도 쉽게 파악할 수 있는데
-
첫 번째로 비대칭성입니다.
수식에서 알 수 있듯이, P와 Q의 순서가 다르면 값이 다르기 때문에 단순히 두 분포 사이의 거리(distance)를 측정하는 지표가 아닙니다. -
두 번째로 비음수성입니다.
인 경우에만 값이 이 되고 달라지면 0보다 커집니다.
이런 KL divergence는 VAE, diffusion 과 같은 생성모델을 수식적으로 이해할 때 필수적으로 알아야하는 기초 개념입니다.
항상 0 이상의 값을 가진다는 것과, 정의를 잘 기억해두시면 생성모델 수식을 전개하는 과정에서 도움이 될 것 같습니다.
참고로, (diffusion 수식 약간 추가 예정)
mutual information
이번에는 mutual information 에 대해서 알아봅시다.
mutual information 은 두 변수가 얼마나 많이 서로 관련되어 있는지 그 상호 의존성을 측정하는 지표입니다.
일단 수식을 먼저 보게 되면, ...
- chain rule
- jensen's inequality

유익하군요