오늘은 온디바이스에 대해서 가볍게 적어보려고 한다. 인터넷 자료에 의지를 많이 했다보니 내용 검증은 더 필요하다ㅎ;; 아무튼... 온디바이스 AI는 클라우드 서버 대신 기기 내부에서 AI 추론을 수행하는 방식이다. 보안, 지연시간, 오프라인 가용성, 비용 측면에서 이점이 있으며, 이를 실현하기 위해 양자화(Quantization), 병렬 연산(Parallel Computing), 캐시 최적화(Cache Optimization) 등이 사용된다.
온디바이스 AI
(이미지출처: http://tech.kobeta.com/새로운-ai-패러다임의-시작-온디바이스-ai/)
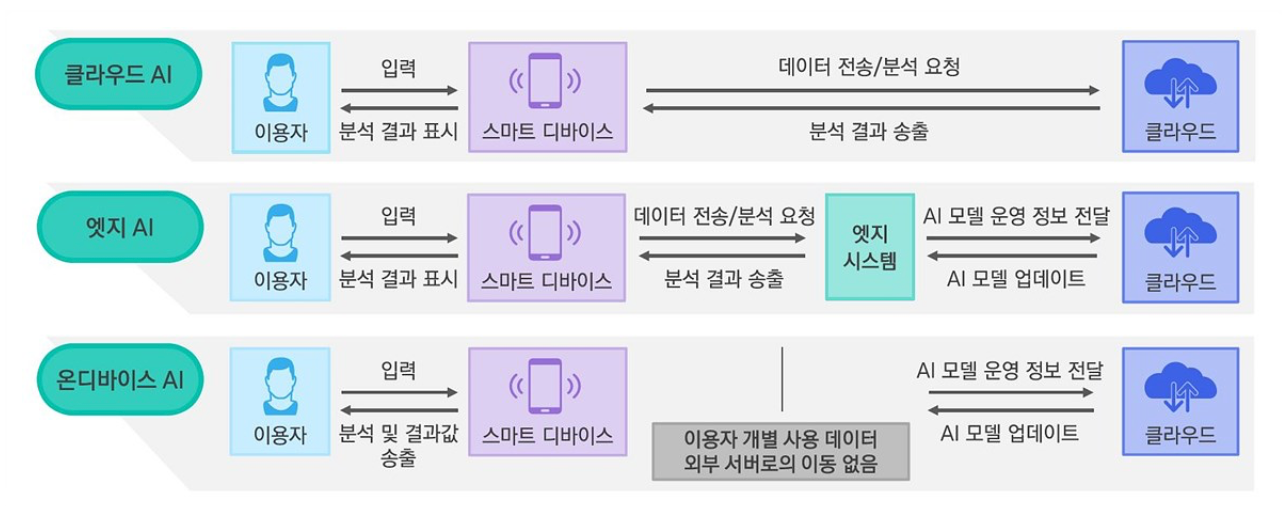
온디바이스(On-device) AI는 말 그대로 기기(device) 내부에서 AI 모델의 추론(inference)을 수행하는 구조를 뜻한다.
기존의 일반적인 AI 서비스 구조는 클라우드 기반이다. 사용자가 입력을 보내면 데이터가 인터넷을 통해 원격 서버로 전송되고, 서버에서 모델이 추론을 수행한 뒤 결과를 다시 사용자에게 반환한다. ChatGPT, Gemini, Copilot 등 대부분의 생성형 AI 서비스가 이 방식으로 동작한다. 서버 측에 수천억 개의 파라미터를 가진 대규모 언어 모델(LLM)을 올려놓고, 수만 개의 GPU가 연산을 처리하는 구조다.
온디바이스 AI는 이 과정을 기기 내부의 하드웨어 자원만으로 대체한다. 모델이 스마트폰이나 노트북의 NPU(Neural Processing Unit), GPU, CPU 위에서 직접 실행되며, 데이터가 기기 밖으로 나가지 않는다.
온디바이스 AI가 필요한 이유
온디바이스 AI가 주목받는 이유는 크게 네 가지로 정리할 수 있다.
보안과 프라이버시.
데이터가 기기 밖으로 전송되지 않으므로, 네트워크 구간에서 발생할 수 있는 유출 위험이 원천적으로 제거된다. 얼굴 인식, 음성 데이터, 건강 정보 등 민감한 개인정보를 다루는 서비스에서 이 점은 특히 중요하다. 기존 클라우드 AI에서는 아무리 암호화를 적용해도 ‘전송’이라는 행위 자체가 기기 내부에서만 처리하는 것에 비해 취약할 수 밖에 없다.
저지연성(Low Latency).
클라우드 기반 추론에서는 네트워크 왕복 시간이 불가피하게 발생한다. 서버 측 연산이 아무리 빨라도 물리적 거리에 의한 지연은 제거할 수 없다. 온디바이스 추론은 이 네트워크 지연을 최대한 줄인다. 실시간 카메라 필터, 음성 인식, AR 같은 서비스에서 체감 차이가 크다.
오프라인 가용성.
네트워크 연결 없이도 AI 기능이 작동한다. 항공기 내, 지하 터널, 통신 인프라가 부족한 지역에서도 동일한 수준의 서비스를 제공할 수 있다.
비용 구조의 변화.
클라우드 AI는 사용량에 비례하여 서버 비용이 증가한다. 수많은 사람들이 동시에 요청을 보내면 GPU 클러스터 운영 비용은 천문학적으로 불어난다. 기기 측에서 추론을 처리하면 서비스 제공자의 인프라 부담이 크게 줄어든다.
제한된 자원에서 모델을 돌리는 법
클라우드 서버에는 수많은 RAM과 연산 코어들이 있다. 반면 스마트폰의 메모리는 몇 GB 수준이고, 연산 능력도 비교할 수 없이 작다. 이 간극을 메우기 위해 세 가지 방향의 최적화가 필요하다.
(1) 계산량 자체를 줄이고 — 양자화(Quantization)
(2) 주어진 연산 자원을 최대한 활용하고 — 병렬화(Parallelization)
(3) 메모리 접근 병목을 해소한다 — 캐시 최적화(Cache Optimization)
이 세 가지는 독립적으로 작동하는 것이 아니라, 서로 맞물려 하나의 추론 파이프라인을 구성한다. 하나씩 살펴보자.
양자화(Quantization) — 정밀도를 낮춰 계산을 줄인다
개념. AI 모델의 가중치(weight)는 기본적으로 32비트 부동소수점(FP32) 형식으로 저장된다. 양자화는 이 가중치의 숫자 표현을 더 낮은 비트 수로 변환하는 기술이다. FP32 → INT8(8비트 정수)로 변환하면 가중치 하나당 메모리 사용량이 4바이트에서 1바이트로 줄어든다. 최근에는 INT4, 심지어 INT2까지 적용하는 연구도 활발하다.
쉽게 말하면. 소수점 이하 열 자리까지 기록하던 성적표를 반올림해서 정수로만 적는 것과 비슷하다. 98.37254901을 98로 표기해도 석차를 매기는 데는 거의 영향이 없다. 약간의 정밀도를 포기하는 대신, 저장 공간과 계산량을 4배 이상 절약할 수 있다.
기술적 디테일. 양자화에는 크게 두 가지 방식이 있다. PTQ(Post-Training Quantization)는 이미 학습이 끝난 모델에 사후 적용하는 방식으로, 별도의 재학습 없이 빠르게 적용할 수 있다. QAT(Quantization-Aware Training)는 학습 과정에서부터 양자화 오차를 반영하여 훈련하는 방식으로, 정확도 손실이 더 적다. 일반적으로 FP32 → INT8 변환 시 정확도 손실은 1–2% 이내로 보고된다.
+) 양자화와 함께 쓰이는 보조 기법들에는 pruning과 KD가 있다.
가지치기(Pruning).
모델의 뉴런 연결(시냅스) 중 출력에 미치는 영향이 작은 것들을 제거하는 기법이다. 가중치의 절대값이 특정 임곗값 이하인 연결을 0으로 만들면, 해당 연산을 건너뛸 수 있다. 비구조적 가지치기(Unstructured Pruning)는 개별 가중치 단위로 제거하고, 구조적 가지치기(Structured Pruning)는 필터나 채널 단위로 제거해 실제 하드웨어 가속의 이점을 얻기 쉽다.
지식 증류(Knowledge Distillation).
대규모 ‘교사(Teacher)’ 모델의 출력 분포를 작은 ‘학생(Student)’ 모델이 학습하는 방식이다. 학생 모델은 정답 레이블뿐 아니라 교사 모델이 출력하는 확률 분포(soft label)를 함께 학습하기 때문에, 단독으로 학습할 때보다 더 높은 성능을 낼 수 있다. Google의 DistilBERT가 대표적인 사례로, 원본 BERT 대비 파라미터 수를 40% 줄이면서도 성능의 97%를 유지한다.
병렬화(Parallel Computing) — 동시에 계산해서 속도를 높인다
개념. 하나의 큰 연산을 여러 조각으로 나누어 여러 프로세서가 동시에 처리하는 기술이다. 딥러닝 추론의 핵심 연산인 행렬 곱셈은 본질적으로 같은 패턴의 곱셈과 덧셈을 반복하는 구조이므로, 병렬화에 매우 적합하다.
쉽게 말하면. 혼자서 100개의 일을 하는 것보다 4명이 25개의 일을 동시에 하는 것이 빠르다.
데이터 병렬성: SIMD
SIMD(Single Instruction, Multiple Data)는 하나의 명령어로 여러 데이터를 동시에 처리하는 방식이다. 예를 들어 128비트 벡터 레지스터에 32비트 부동소수점 4개를 적재하면, 하나의 덧셈 명령으로 4개의 덧셈을 동시에 수행할 수 있다. ARM 프로세서의 NEON(128비트), x86의 AVX(256비트), AVX-512(512비트)가 대표적인 SIMD 명령어 세트다. 모바일 기기의 ARM 칩에서는 NEON이 온디바이스 AI 추론의 핵심 가속기 역할을 한다.
작업 병렬성: Multi-threading
최신 모바일 SoC(System on Chip)는 보통 4–8개의 CPU 코어를 탑재한다. 멀티스레딩은 이 코어들에 서로 다른 연산 블록을 할당하여 동시에 처리하는 방식이다. C/C++ 환경에서는 OpenMP, pthreads 등의 라이브러리로 구현한다.
실제 추론에서의 동작 구조
실제 AI 추론에서는 SIMD와 멀티스레딩이 결합된다. 전형적인 흐름은 다음과 같다.
Tiling: 큰 행렬을 캐시에 적재 가능한 크기의 작은 타일(tile)로 분할한다.
Distribution: 분할된 타일을 각 CPU 코어에 배분한다.
SIMD Execution: 각 코어는 배정받은 타일 내의 연산을 SIMD 명령어로 4–8개씩 묶어 고속 처리한다.
병렬화의 한계
이론적으로는 코어가 N개이면 속도도 N배가 되어야 한다. 하지만 현실은 다르다. 세 가지 제약이 존재한다.
오버헤드(Overhead). 작업을 분할하고 결과를 합치는 과정 자체에 비용이 든다. 작업 단위가 너무 작으면 분배 비용이 연산 비용을 초과하여 오히려 성능이 저하된다.
경쟁 조건(Race Condition). 여러 코어가 동일한 메모리 영역에 동시에 쓰기를 시도하면 데이터 정합성 문제가 발생한다. 이를 방지하기 위해 Lock(잠금)을 도입하면, 그만큼 병렬성이 감소한다.
암달의 법칙(Amdahl’s Law). 프로그램의 일부분은 구조적으로 병렬화가 불가능하다. 전체 코드의 90%를 완벽히 병렬화하더라도, 나머지 10%의 순차 실행 구간이 전체 속도 향상의 상한선을 결정한다. 코어를 무한히 늘려도 이론적 최대 속도 향상은 10배에 그친다.
캐시 최적화(Cache Optimization) — 메모리 접근 병목을 해소한다
개념. 현대 프로세서에서 연산 속도와 메모리 접근 속도의 차이는 수십~수백 배에 달한다. CPU가 아무리 빠르게 계산해도, 데이터가 제때 공급되지 않으면 유휴 상태(stall)로 대기하게 된다. 캐시 최적화는 CPU에 가까운 고속 캐시 메모리(L1/L2)의 활용률을 극대화하여 이 병목을 줄이는 기술이다.
쉽게 말하면. 요리할 때 자주 쓰는 재료를 조리대(캐시) 위에 미리 꺼내놓으면 냉장고(메인 메모리)까지 왔다 갔다 하는 시간을 줄일 수 있다. 캐시 최적화는 ‘어떤 재료를 언제, 어떤 순서로 조리대에 올려놓을 것인가’를 설계하는 작업이다.
주요 기법은 세 가지다.
타일링(Tiling). 큰 행렬 연산을 캐시 크기에 맞는 작은 블록으로 분할하여, 하나의 블록이 캐시에 머무는 동안 관련 연산을 모두 완료한다. 이렇게 하면 동일한 데이터를 메인 메모리에서 반복적으로 불러오는 비용을 제거할 수 있다.
데이터 레이아웃 최적화(Layout Optimization). 연속으로 접근할 데이터를 메모리 상에서도 연속으로 배치한다. 예를 들어 행렬을 행 우선(row-major)으로 저장할지 열 우선(column-major)으로 저장할지에 따라 캐시 적중률(cache hit rate)이 크게 달라진다.
연산 합치기(Operator Fusion). 여러 단계로 나뉜 연산(예: 행렬 곱셈 → 활성화 함수 → 정규화)을 하나의 커널로 합쳐서, 중간 결과를 메모리에 쓰고 다시 읽는 과정을 생략한다. TensorFlow Lite나 ONNX Runtime 같은 온디바이스 추론 프레임워크에서 기본적으로 적용하는 최적화 기법이다.
앞으로 AI가 서버 중심에서 점점 사용자 기기로 확장되어 간다면, 온디바이스 AI는 그 중심에 자리 잡을 가능성이 크다. 적용 범위 또한 스마트폰에 머물지 않는다. 최근에는 로봇, 자율주행, 드론, 산업용 엣지 장비 등 피지컬 AI(Physical AI) 영역에서 온디바이스 추론의 중요성이 빠르게 커지고 있다. 이러한 시스템들은 실시간으로 주변 환경을 인식하고 즉각적으로 반응해야 하기 때문에, 클라우드를 거치지 않고 기기 내부에서 바로 판단을 내리는 능력이 필수적이다. 이러한 흐름 속에서 온디바이스 AI의 중요성은 앞으로 더욱 커질 것으로 보인다.
