03. 데이터 정제하기
03-1. 불필요한 데이터 삭제하기
데이터 정제란?
- 데이터에서 손상되거나 부정확한 부분을 수정하고, 불필요한 데이터를 삭제하거나 불완전한 값을 교체하는 등의 작업
- 데이터 랭글링, 데이터 먼징 - 데이터를 분석 목적에 맞게 변환하는 것
- 데이터 정제는 데이터 랭글링, 데이터 먼징의 일부
열 삭제하기
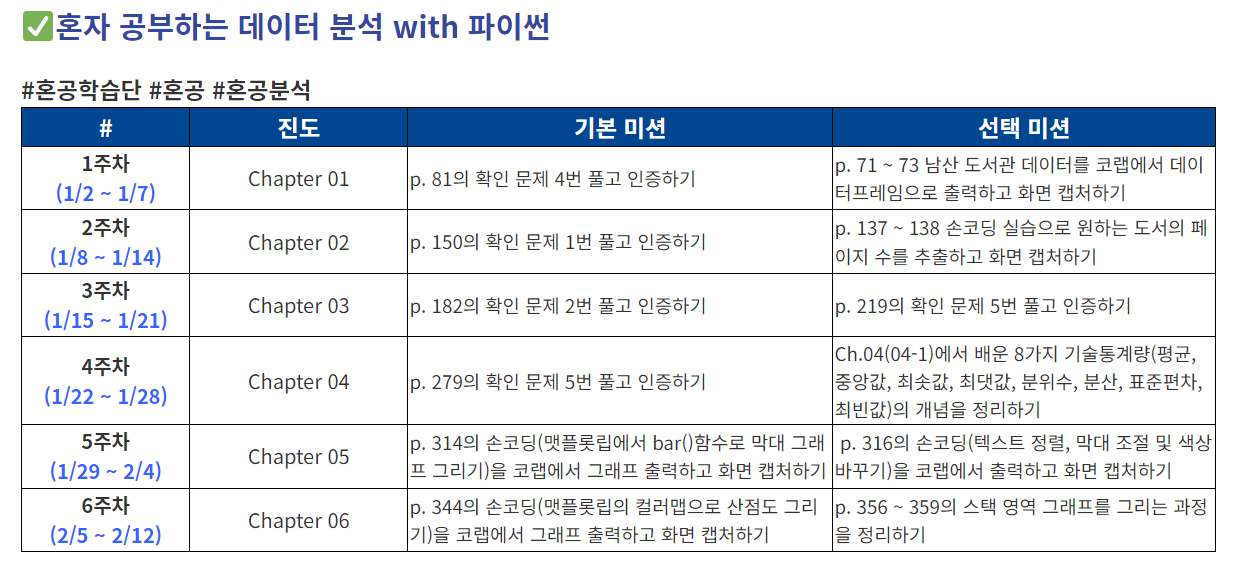
슬라이싱을 이용
- Unnamed:13열은 csv파일 각 라인의 끝에 콤마가 있어서 판다스가 자동으로 추가한 것. 불필요한 열이기 때문에 삭제한다
번호컬럼 부터등록일자컬럼까지
ns_df.loc[:, '번호':'등록일자']불리언 배열을 이용
- 중간에 있는 컬럼도 빼고 싶다면? 불리언배열을 이용
# 불리언 배열을 selected_columns에 담는다.
selected_columns = ns_df.columns != 'Unnamed: 13'
ns_book = ns_df.loc[:, selected_columns]
ns_book.head()drop()을 이용
- 여러개도 지울 수 있다
ns_book = ns_df.drop(['부가기호', 'Unnamed: 13'], axis = 1)
ns_book.head()- inplace
- 새 변수에 지정하지 않고, 데이터 프레임을 바로 수정
dropna()
NaN이 하나 이상 포함된 행이나 열을 삭제how = 'all모든 값이 NaN인 열 삭제
ns_book = ns_df.dropna(axis = 1, how = 'all')
ns_book.head()행 삭제하기
drop()
- 행은 axis = 0으로 지정. 디폴트가 axis=0이기 때문에 생략 가능
- 0,1번째 행을 drop한다
슬라이싱
- 2번째 행부터 선택한다. (0,1번째 행을 drop하는 것과 같음)
불리언 배열을 사용
- 원하는 행은 True로 표시, 제외할 행은 False로 표시
- 조건줘서 표출
- 조건
==,>같다, 크기 비교 등의 조건 가능
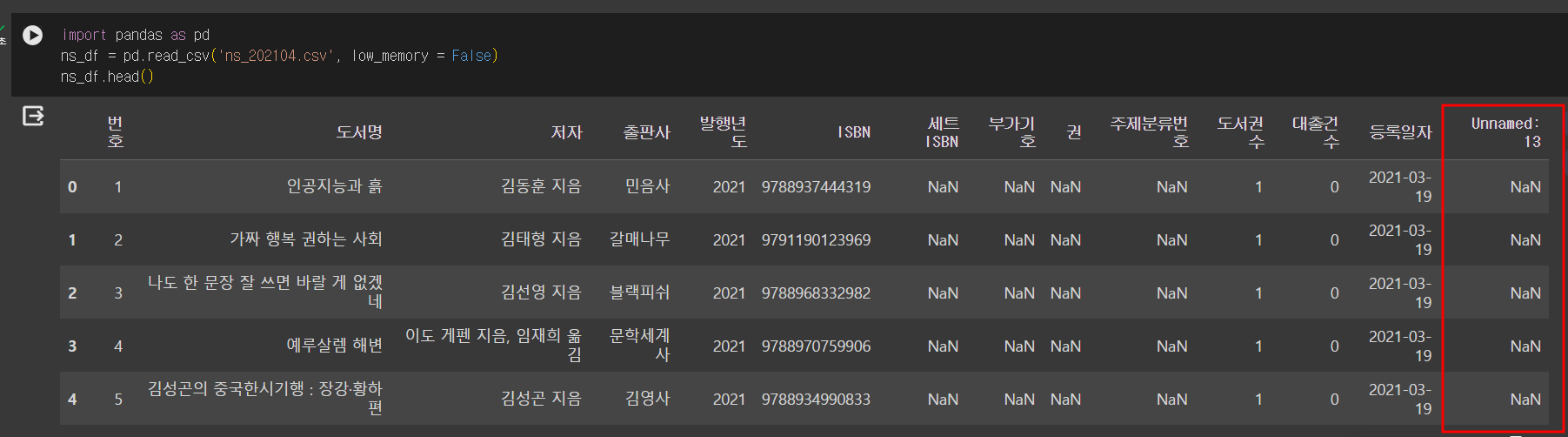
중복된 행 찾기
duplicated()
# 모든 열을 기준으로 중복된 행을 찾는다. (모든 값이 같은 행을 찾는다.
sum(ns_book.duplicated())- subset : 일부 컬럼을 기준으로 중복된 행을 찾는다.
# 도서명, 저자, ISBN을 기준으로 중복된 행을 찾음
um(ns_book.duplicated(subset = ['도서명', '저자', 'ISBN']))keep = False: 중복된 행을 True로 반환
dup_rows = ns_book.duplicated(subset = ['도서명', '저자', 'ISBN'], keep = False)그룹별로 모으기
groupby()
by행을 합칠 때 기준이 되는 열 지정groupby()메서드는 기본적으로 by 매개변수에 지정된 열에 NaN이 포함되어 있으면 해당 행을 삭제한다.dropna()매개변수를 False로 지정하면 연산할 때 NaN이 있는 행도 포함한다.

원본 데이터 업데이트하기
copy()데이터 프레임의 복사본을 만든다.copy()메서드를 사용하지 않으면 업데이트한 데이터프레임이 별도의 메모리 공간에 저장되는지 보장하지 않는다. (원본 데이터가 바뀔 수도 있음)
원본 데이터프레임 인덱스 설정하기 set_index()
set_index()지정한 컬럼을 인덱스로 설정한다.
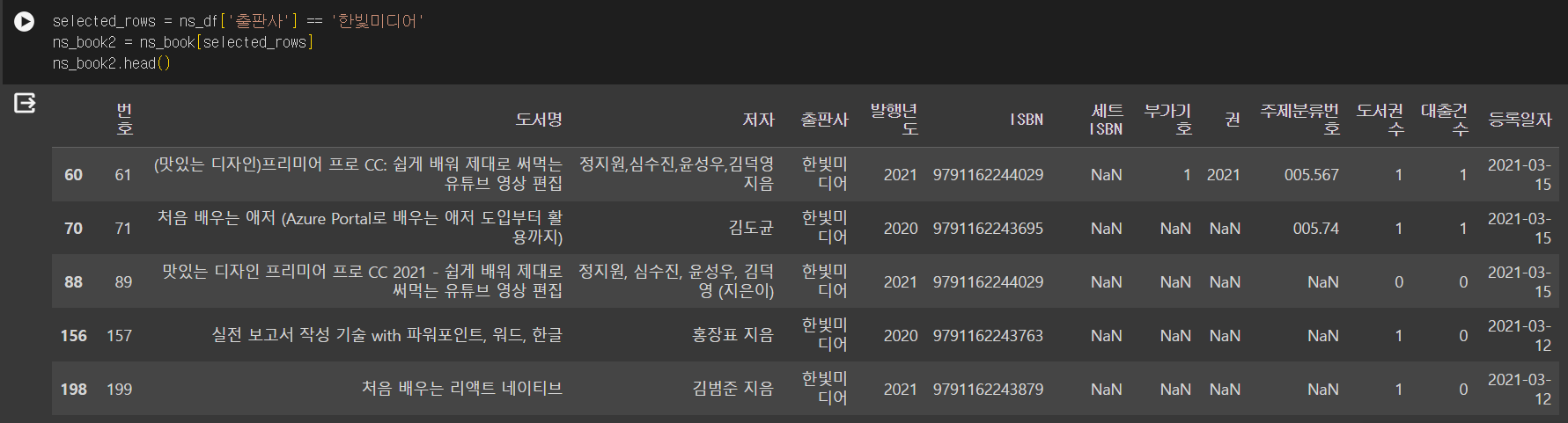
업데이트 update()
update()다른 데이터프레임을 사용해 원본 데이터프레임의 값을 업데이트
인덱스 열 해제
reset_index()
다른 데이터 프레임 비교 equals()
new_ns_book4 = data_cleaning('ns_202104.csv')
ns_book4.equals(new_ns_book4)기본미션
p. 182의 확인 문제 2번 풀고 인증하기
2. df 데이터프레임에서 'col1' 열의 합을 계산하는 명령으로 올바르지 않은 것은?
4번
1. col1 시리즈의 sum
2. col1만 있는 데이터프레임의 sum
3. col1만 있는 데이터프레임의 sum
4. col3의 sum
선택미션
p. 219의 확인 문제 5번 풀고 인증하기
5. 다음과 df 데이터프레임에서 df.replace(r'ba.*', 'new', regex = True)의 결과 값은 무엇인가요?
1번
- 정규표현식
- 'ba.*' ba뒤에 어떤 문자가 들어가더라도~ new로 바꿔라~
