04-1 통계로 요약하기
기술통계
- 기술통계: 자료의 내용을 압축하여 설명하는 방법(요약통계)
- 정량적인 수치로 전체 데이터의 특징을 요약하거나 이해하기 쉬운 간단한 그래프를 사용.
- 대표적인 통계량: 평균, 표준편차
- 탐색적 데이터 분석
describe() 메서드
- 수치형 열에 대한 요약 통계를 보여준다.
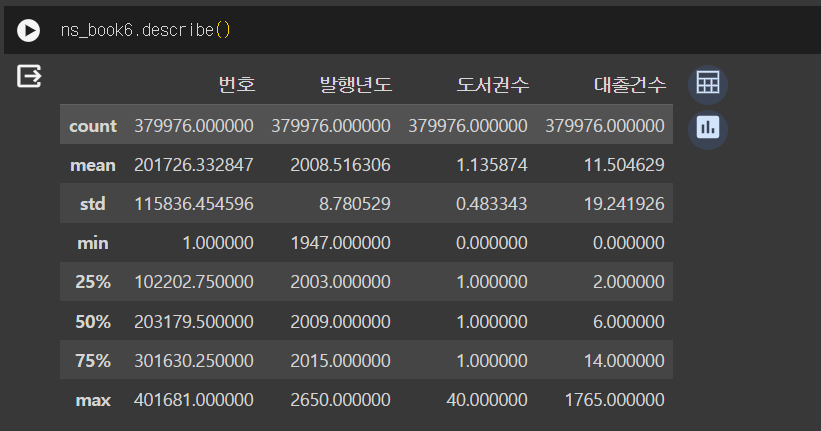
- count: 누락된 값을 제외한 데이터 개수를 나타낸다.
- mean: 평균
- std: 표준편차
- min: 최솟값
- 50%: 중앙값
- 25%, 75%: 순서대로 늘어놓았을 때 25% 지점과 75% 지점에 놓인 값
- max: 최댓값
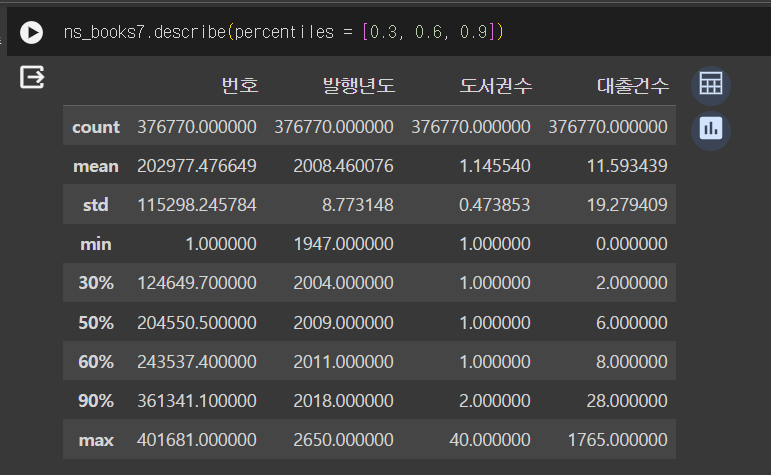
percentiles: 4분위 수 말고 다른 지점의 숫자 확인 가능
include: 데이터타입이 수치가 아니니 다른 데이터 타입의 열의 기술통계 확인
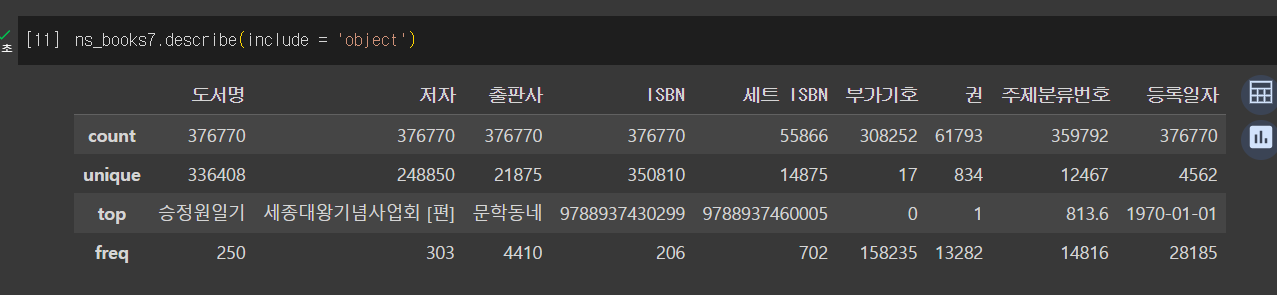
- count: 누락된 값을 제외한 데이터 개수
- unique: 고유한 값의 개수
- top: 가장 많이 등장하는 값
- freq: top행에 등장하는 항목의 빈도수
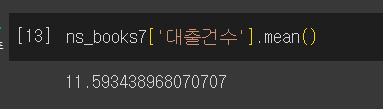
평균
mean()
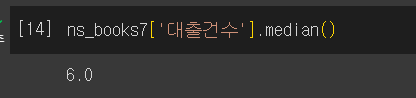
중앙값
- 전체 데이터를 순서대로 늘어놓았을 때 중앙에 위차한 값
median()
- 데이터 개수가 짝수일 때 중앙값 구하는 법: 가운데 두 개의 값을 평균하여 중앙값을 결정한다.
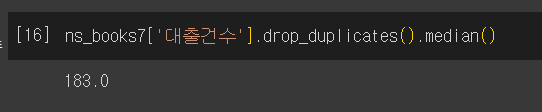
- 중복값 제거하고 중앙값 구하기
drop_duplicates().median()
최솟값, 최댓값
min(),max()

분위수
- 분위수(quantile): 데이터를 순서대로 늘어 놓아씅ㄹ 때 이를 균등한 간격으로 나누는 기준점.
- ex.이분위수: 전체 데이터를 두 구간으로 나눈 수 = 중앙값
- 사분위 수: 순서대로 정렬된 데이터를 네 구간으로 나눈 수.
- 25%, 50%, 75%- 25%- 1분위수, 50%- 2분위수, 75%- 3분위수
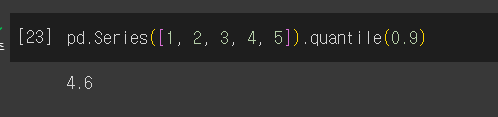
quantile()

분위수에 딱 들어맞지 않을 때는?
- interpolation 매개변수에서 중간값을 계산하는 방법으로 결정.
- interpolation 매개변수를 따로 지정하지 않을 때는 기본값인 linear방식으로 결정됨. (linear: 양쪽 분위수에 비례하여 결정)
- liear외 보간방식
- midpoint: 중앙값
- nearest: 두 수 중에서 가까운 값
- lower: 두 수 중 더 작은 값
- higher: 두 수 중 더 큰 값

백분위 구하기
- 대출건수 10이 위치한 백분위수 찾는 방법
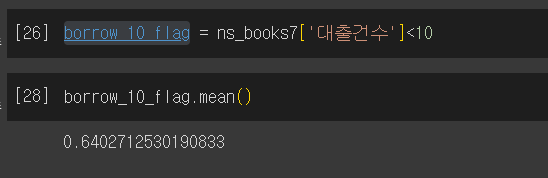
(잘 모르겠군...)
분산
- 분산: 평균으로부터 데이터가 얼마나 퍼져있는지를 나타내는 통계량
- 데이터가 가운데 모여있다면 분산이 작고, 넓게 퍼져있다면 분산이 크다
- 분산 구하기: 각 값에서 평균을 뺀 다음 제곱한 후 개수로 나눈다.
var()
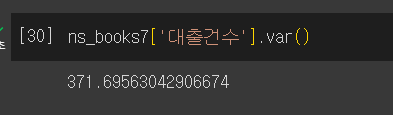
- 분산은 제곱을 했기 때문에 데이터가 평균에서 멀어질수록 값이 급격히 커진다. 이를 보완하기 위해 분산에 제곱근을 취한 표준편차를 사용한다.
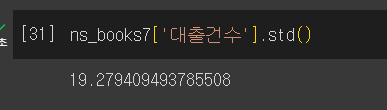
표준편차
- 분산에 제곱근을 한 것.
std()
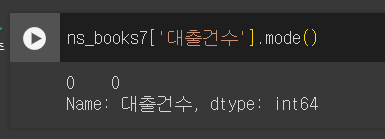
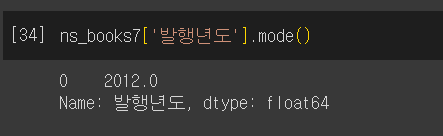
최빈값
- 데이터에서 가장 많이 등장하는 값
mode()
04-2 분포 요약하기
전체 데이터를 한눈에 파악하려면 그래프가 가장 좋은 방법.
데이터를 그림으로 요약할 수 있는 방법: 산점도, 히스토그램, 상자수염그림
산점도 그리기
맷플롯립
- 그래프를 그리는데 사용하는 대표적 패키지
plt.show()그래프 출력
산점도
- 데이터를 화면에 뿌리듯 그리는 그래프
scatter()
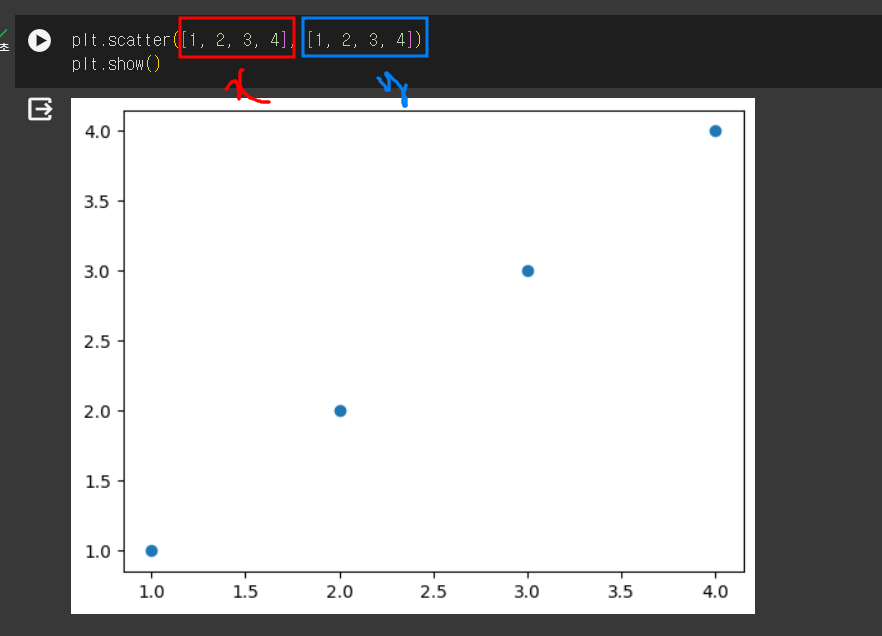
- 데이터프레임의 열 값을
scatter()함수의 매개변수로 사용
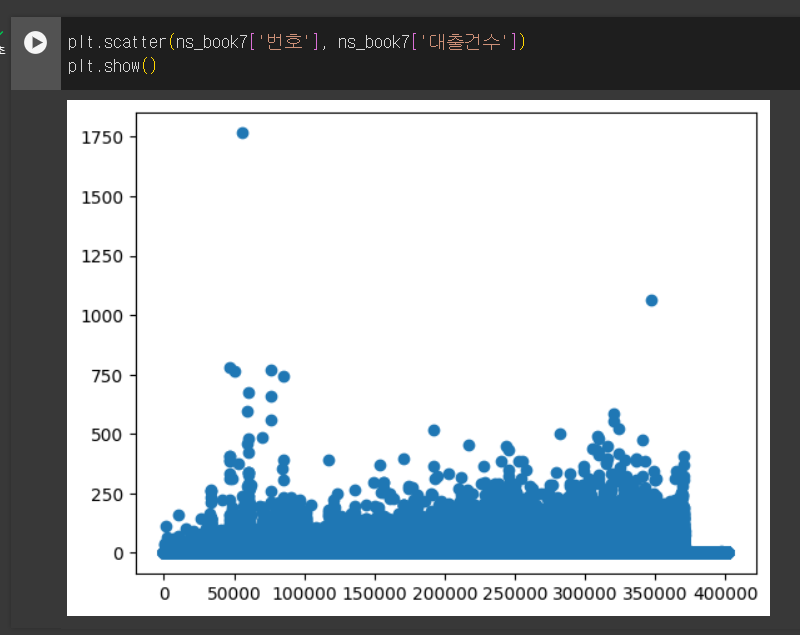
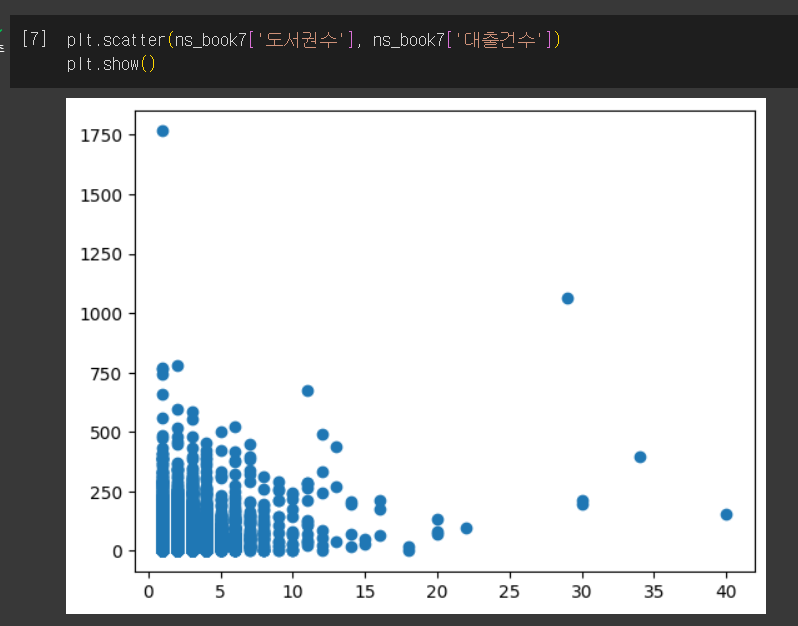
- 도서권수와 대출건수의 산점도
산점도 투명도 조절
alpha
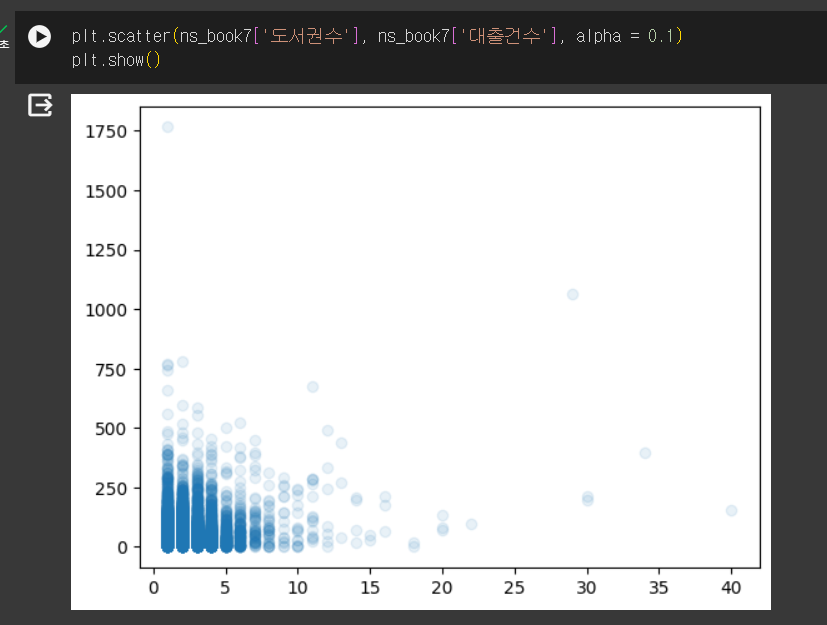
상관관계 있는 값 산점도로 그리기
- 양의 상관관계
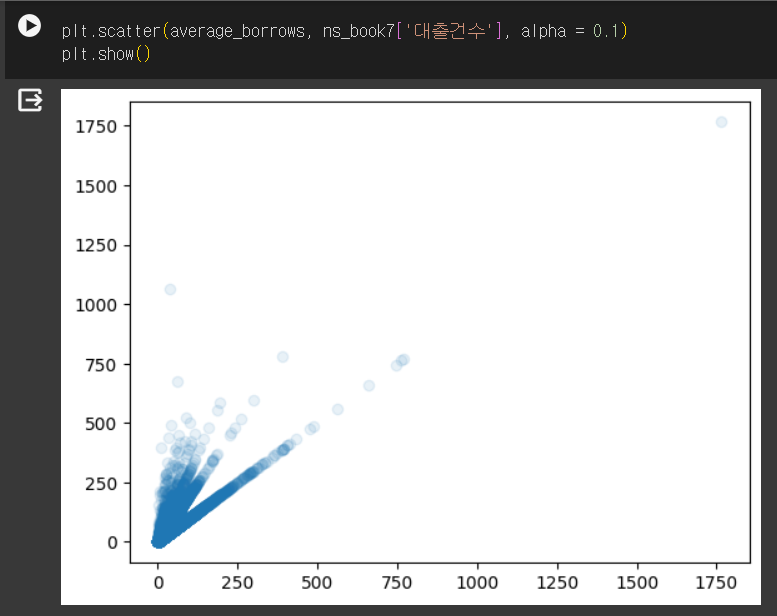
히스토그램
- 히스토그램: 수치형 특성의 값을 일정한 구간으로 나누어 구간 안에 포함된 데이터 개수를 막대 그래프로 그린 것.
- 도수: 구간 안에 속한 데이터 개수
- 도수분포표: 히스토그램에 나오는 구간과 도수를 표로 요약한 것
hist()
- bins : 구간의 개수
histogram_bin_edges()히스토그램의 구간 확인

- 첫번째 구간: 0~2.6- 가상으로 히스토그램 그리기.
randn()함수 이용
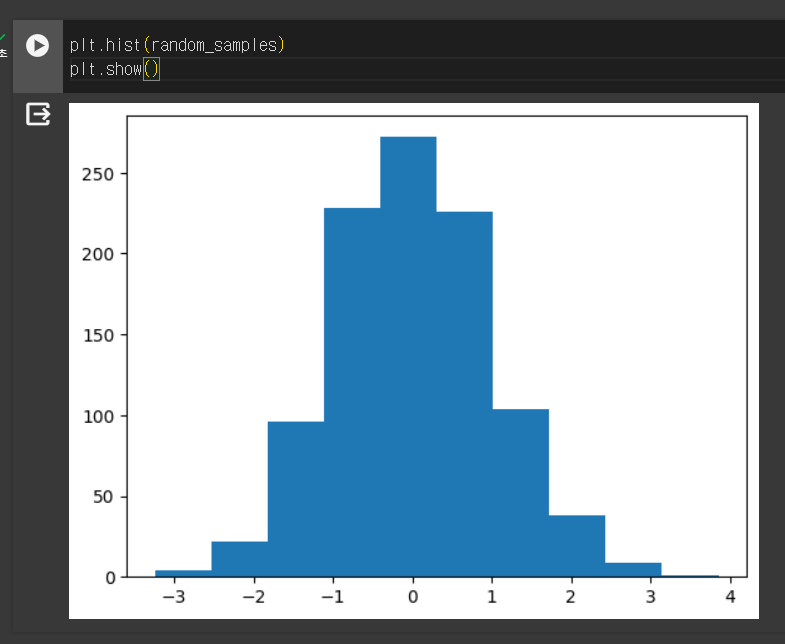
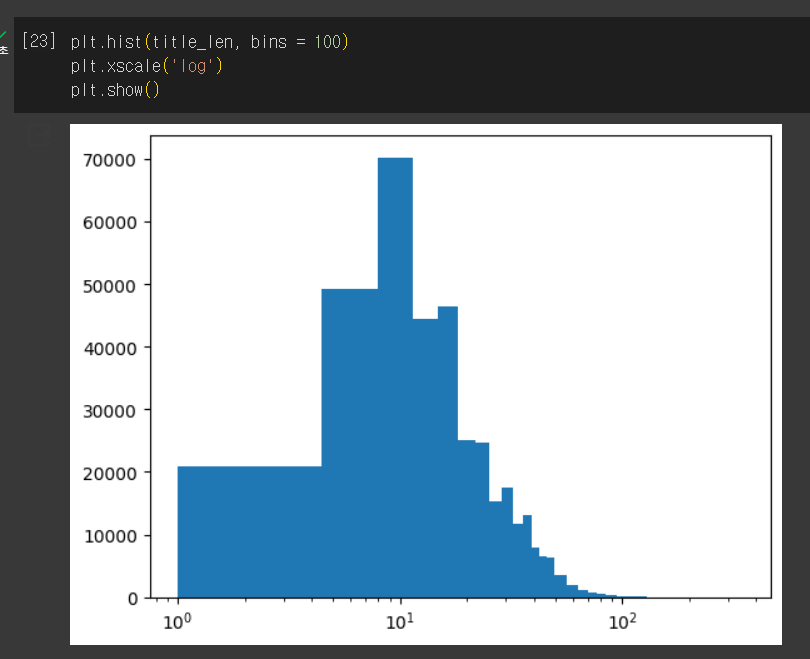
- 남산도서관 대출데이터 대출건수 히스토그램
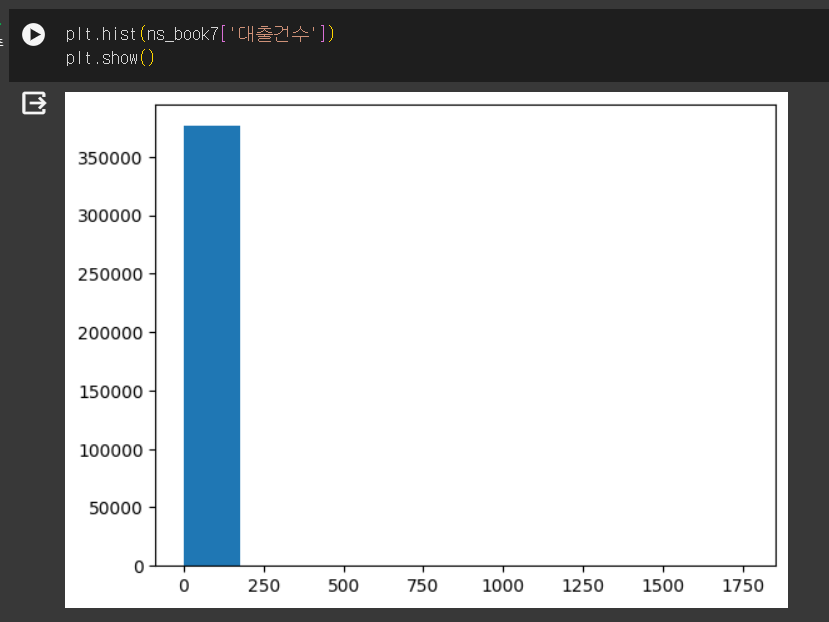
구간 조정하기 - 로그스케일로 y축 값 조정
plt.yscale()
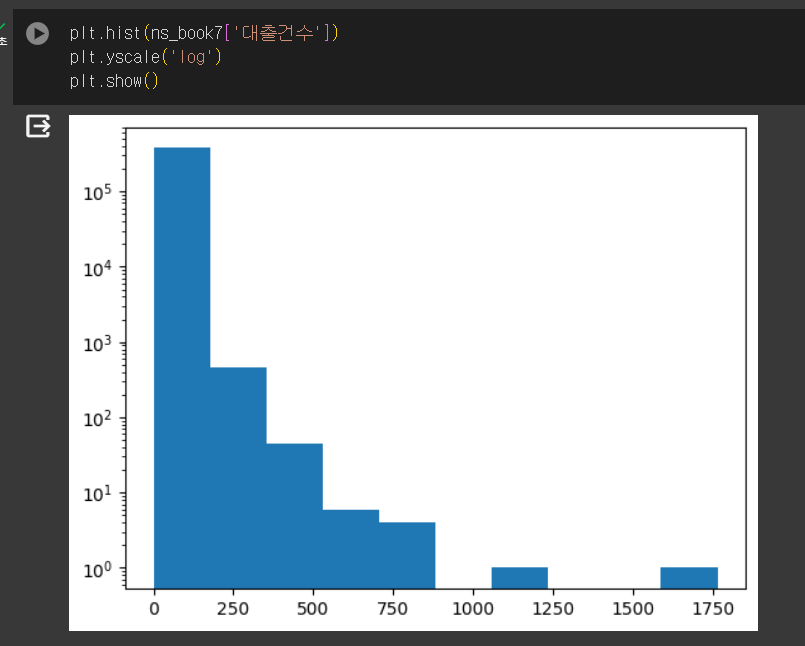
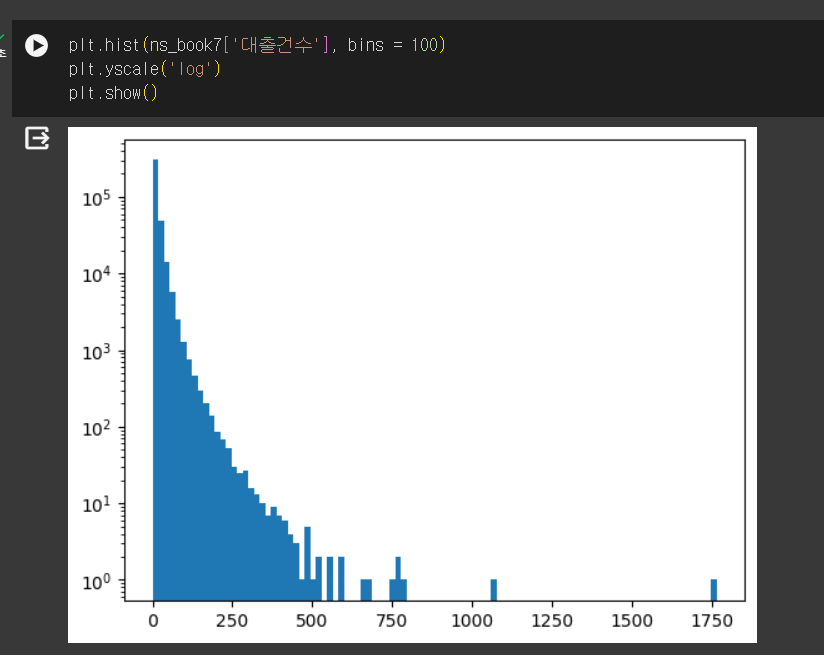
구간 조정하기 - bins로 구간 개수 조정
- bins
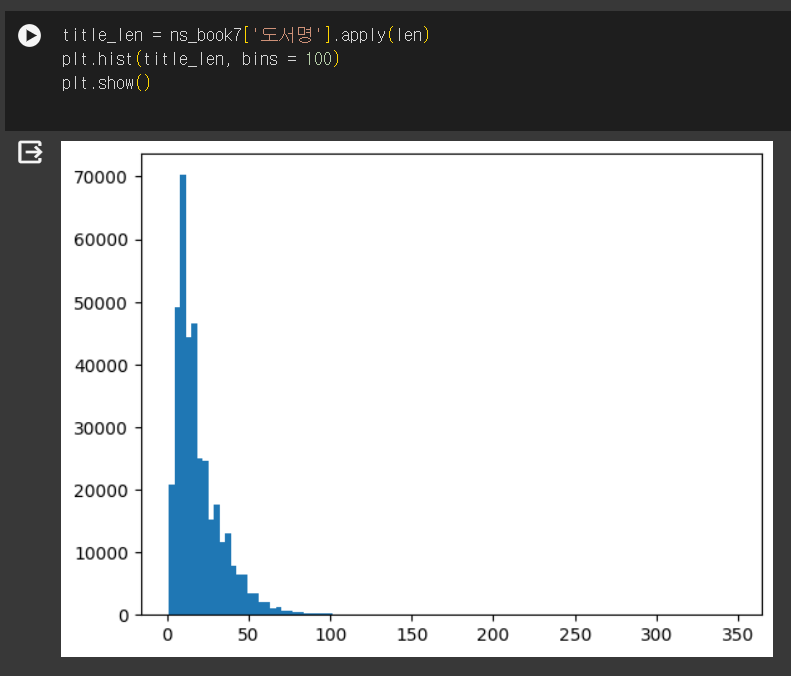
- 도서명 그려보기
x축에 데이터 골고루 그려지게 바꾸기
plt.xscale()
상자 수염 그림 그리기
- 최솟값, 세 개의 사분위수, 최댓값을 사용해 데이터를 요약하는 그래프를 그립니다.
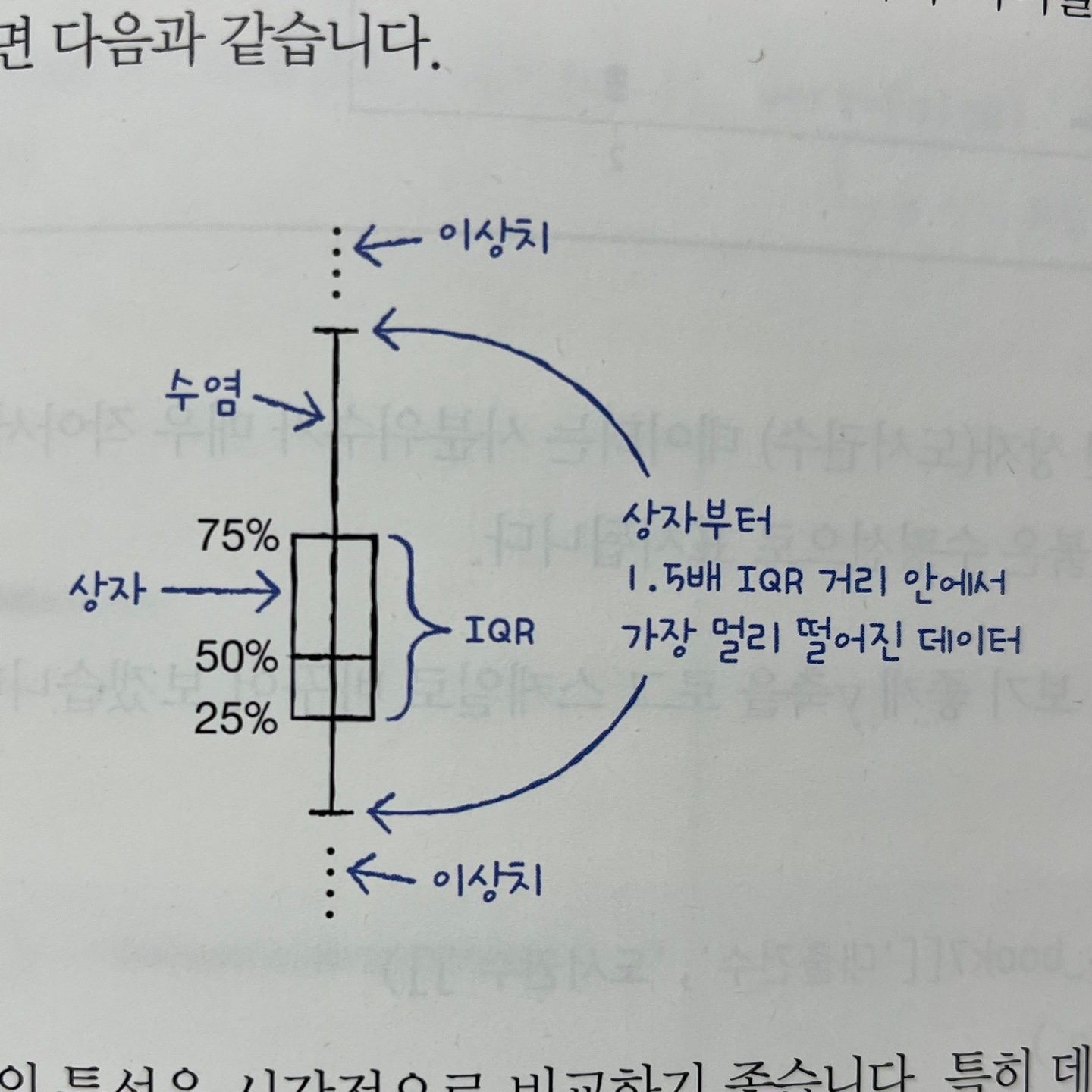
- IQR: 제1사분위수와 제3사분위수 사이의 거리
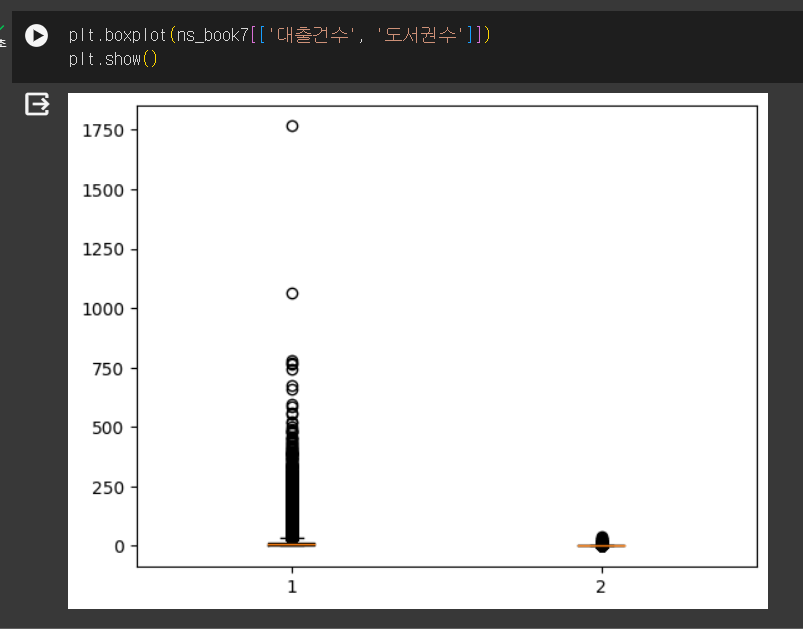
boxplot()
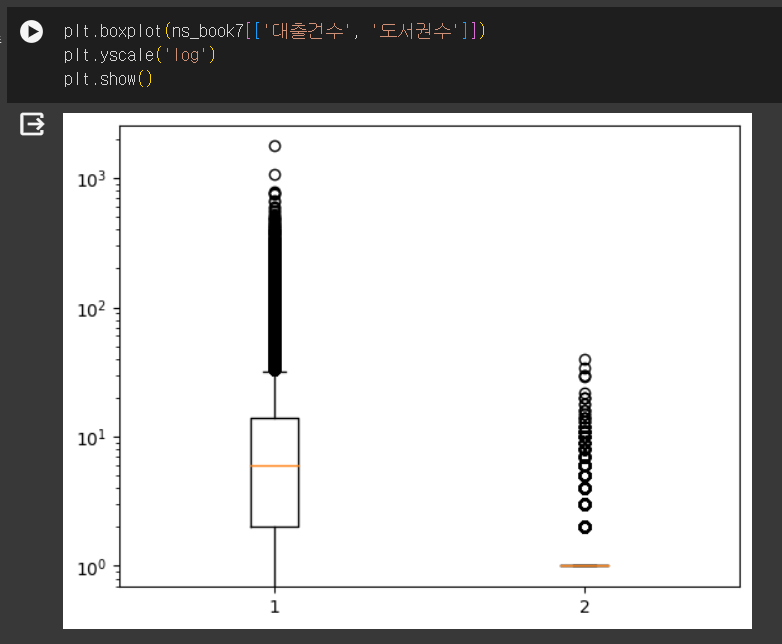
- 잘 안보여서 로그스케일로
상자수염그림 수평으로 그리기
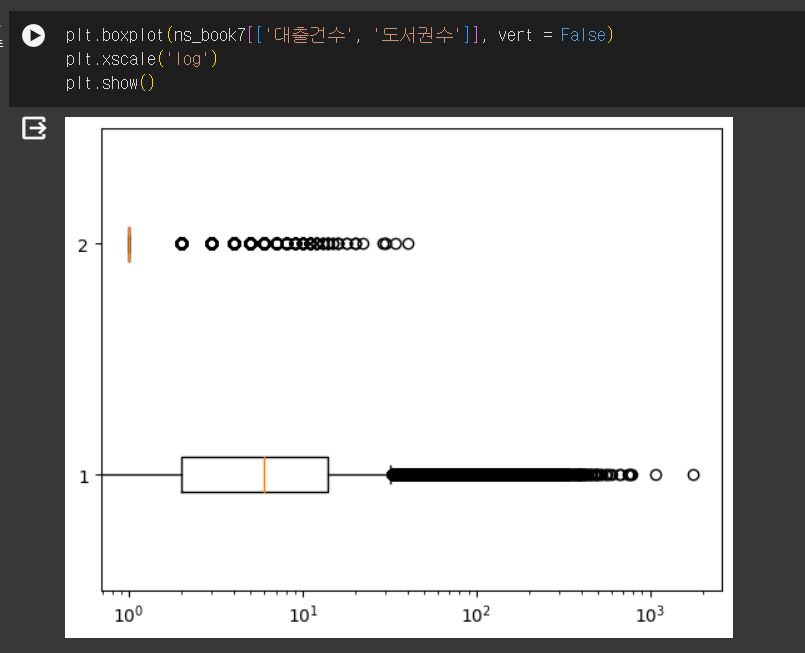
수염길이 조정하기
- 기본적으로 수염의 길이는 IQR의 1.5배
- whis 매개변수에서 조정 가능
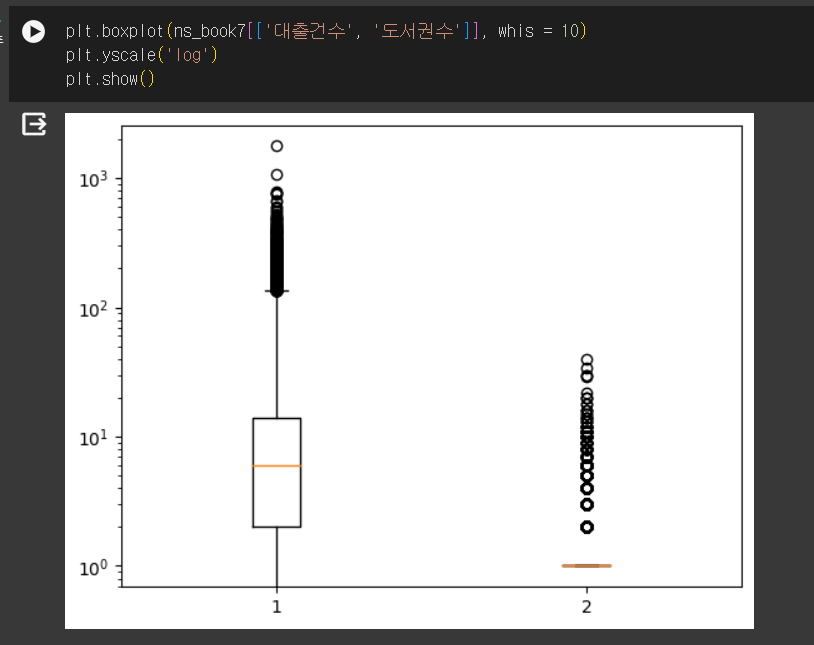
- 위아래로 백분율로 지정 가능
- whis = (10, 90) : 10%, 90% 백분위수에 해당하는 데이터까지 그린다.- whis = (0,100): 마지막 데이터까지 그린다
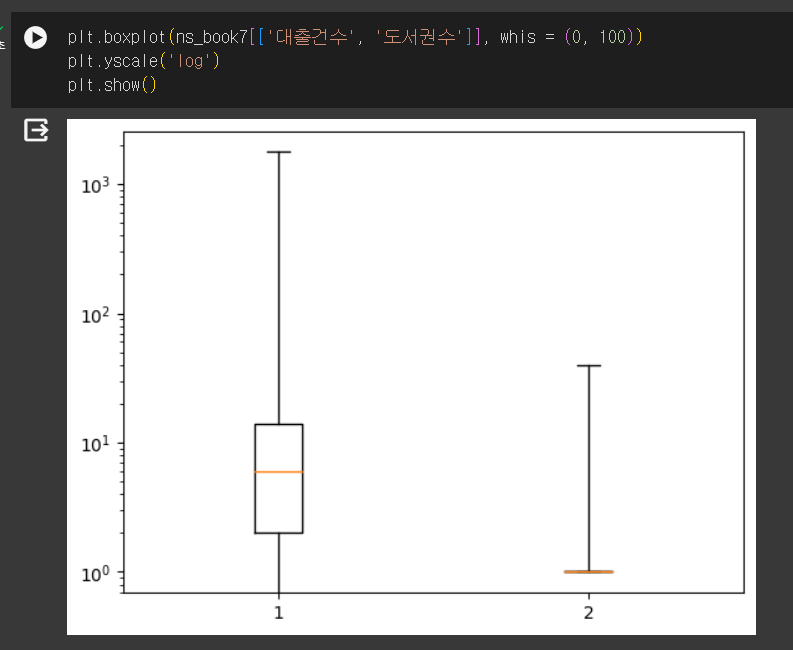
- whis = (0,100): 마지막 데이터까지 그린다
기본 미션
p. 279의 확인 문제 5번 풀고 인증하기
- ns_book7 남산도서관 대출 데이터에서 1980년~2022년 사이에 발행된 도서를 선택하여 '발행년도'열의 히스토그램 그리기
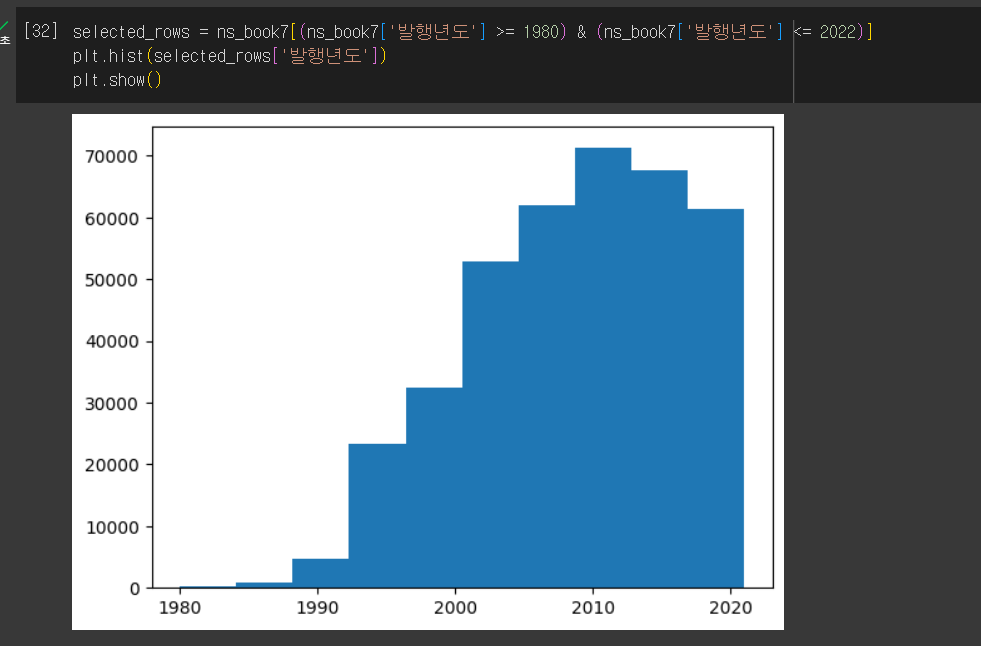
책 정답이랑은 다르네용~
선택 미션
Ch.04(04-1)에서 배운 8가지 기술통계량(평균, 중앙값, 최솟값, 최댓값, 분위수, 분산, 표준편차, 최빈값)의 개념을 정리하기
위에 정리함~~
