06-1 인덱스 개념을 파악하자
인덱스
인덱스의 개념
- 책 뒤의 '찾아보기'와 같은 개념
- 인덱스가 반드시 필요한 것은 아니다.
- 실무에서는 반드시 인덱스를 사용해야 한다. 실무에서는 데이터량이 많기 때문.
인덱스의 문제점
- 인덱스를 무리하게 많이 쓰면 시스템에 무리가 갈 수 있다.
- 너무 많이 등장하는 단어는 인덱스를 안 만드는게 낫다
인덱스의 장점과 단점
장점
- SELECT 문으로 검색하는 속도가 매우 빨라진다.
- 전체적으로 시스템 성능이 향상된다.
단점
- 추가적인 공간이 필요하다. (10~20%)
- 처음에 인덱스를 만드는데 시간이 오래 걸릴 수 있다. (인덱스를 먼저 만드는 것이 낫다.)
인덱스의 종류
클러스터형 인덱스
- 사전 스타일
- 책 자체가 인덱스
보조 인덱스
- 책의 찾아보기 스타일
- 책 뒤에 인덱스가 있다.
자동으로 생성되는 인덱스
- PRIMARY KEY를 생성하면 자동으로 클러스터형 인덱스가 생성된다.
- ex. mem_id를 PK로 설정하면 mem_id는 클러스터형 인덱스가 자동 생성되고, 자동 정렬된다.
- UNIQUE를 생성하면 보조인덱스가 자동으로 생성된다.
자동으로 정렬되는 클러스터형 인덱스
- 클러스터형 인덱스를 생성하는 순간 정렬된다.
- 클러스터형 인덱스는 테이블 당 한개만 지정할 수 있다.
정렬되지 않는 보조 인덱스
- 책 뒤에 찾아보기가 만들어진다.
- 책의 내용은 변경되지 않는다. (UNIQUE키를 지정해도 순서가 바뀌지 않는다)
- UNIQUE키는 여러개 지정할 수 있다.
06-2 인덱스의 내부 작동
균형트리
- 루트, 중간, 리프

(이 부분이 들어가면 게시글이 비공개처리가 된다..왜지? 캡처로 대체)
균형트리의 페이지 분할
- 결론: SELECT는 빠르나 INSERT, UPDATE, DELETE는 느리다
- 루트페이지는 한 페이지만 있어야 한다.
- INSERT가 금방되는 경우 있고, 느려지는 경우 있는데 페이지가 많이 분할 될 때 INSERT가 느리다
구조
- 보조인덱스: 데이터페이지는 그대로 있고, 찾아보기가 만들어진다.
- 찾아보기는 정렬됨
인덱스에서 데이터 검색하기
- 클러스터형 인덱스가 조금 더 빠르다
06-3 인덱스의 실제 사용
인덱스의 생성
CREATE (UNIQUE) INDEX 인덱스이름
ON 테이블이름 (열이름)- UNIQUE : 인덱스 컬럼 값에 중복값을 허용하지 않는다
인덱스의 제거
DROP INDEX 인덱스이름 ON 테이블이름인덱스의 사용
- 전체 행을 조회할 때는 인덱스를 사용하지 않는다
= Full Table Scan을 할 때는 인덱스를 사용하지 않는다. - SELECT 뒤의 내용은 인덱스와 상관이 없다.
- WHERE 뒤에 인덱스 열 내용이 나와야 인덱스를 사용한다.
- MySQL이 인덱스를 사용하지 않는 것이 더 효율적이라고 판단하면 사용하지 않는다.
- 인덱스 열에 가공을 하면 인덱스를 사용하지 않는다.
- ex.WHERE 컬럼명 *2 >14 - 인덱스를 사용하고 싶다면 열에 가공하지 말아라.
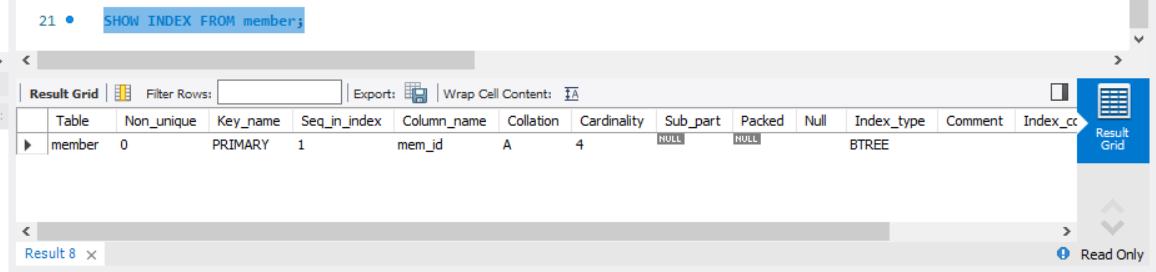
기본미션
p. 310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡처하기
선택미션
인덱스 생성, 제거하는 기본 형식 작성하기
위에 있음~
