📌 keepalived란?
C언어로 작성된 로드밸런싱 및 고가용성을 제공하는 프레임워크이다.
이중화 구성을 위해 VRRP 프로토콜 사용한다.
VRRP란?
VRRP(Virtual Router Redundancy Protocol)로, 게이트워이 장애 복구를 위한 프로토콜이다.
VRRP의 이중화 구성의 경우 Filaover 목적으로 Master / Slave 전환을 위해 사용한다.
Master와 Slave는 하나의 VIP(Vitural IP)로 묶여 있으며, 각각 RIP(Real IP)를 가지고 있다.
(Master: Active / Slave: Stand-By 상태)
만약 Master 장비 장애 발생 시 Slave 장비가 VIP를 가져와 Master 역할 수행하게 된다.
Master 살아있는지 확인하는 방법
핵심: 헬스 체크패킷 전송
- Master 장비는 패킷을 Slave 그룹에 반복적으로 전송
- Slave는 Master가 전송한 패킷을 받으며 Master 장비가 살아있다고 판단 (Standby 유지)
- 일정 시간동안 패킷이 수신되지 않으면 Master가 죽었다고 판단
- Slave에서 자신이 Master가 되기 위해 패킷 전송 Packet 전송 → failover
📌 keepalived 구성
환경
- rocky 8버전
- kt cloud 환경에서 구축
테스트 목표
서버에 node exporter을 설치하여 이중화 구성을 진행하겠다.
Master의 node exporter 프로세스가 죽으면, Slave의 서버에서 node exporter 프로세스가 실행되고(failover) Master 서버가 복구되면 다시 Master 서버에서 node exporter가 실행되도록 한다(failback).
** node exporter는 모니터링 툴로, 테스트를 위해 설치한 것이다. 이중화 하고 싶은 다른 프로그램을 사용하여도 무방하다.
keepalived 구성
1. 서버 생성 (master, slave) 및 node exporter 설치
서버는 모두 kt cloud에서 생성하였다.
Master 서버와 Slave 서버에 node exporter 모두 설치해주고, 실행은 Master 서버에만 해주었다.
# master 서버에서 node exporter 실행하여, 9100 포트가 up 되었음
$ netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1/systemd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 950/sshd
tcp6 0 0 :::9100 :::* LISTEN 42877/node_exporter
tcp6 0 0 :::111 :::* LISTEN 1/systemd
tcp6 0 0 :::22 :::* LISTEN 950/sshd2. VIP 생성
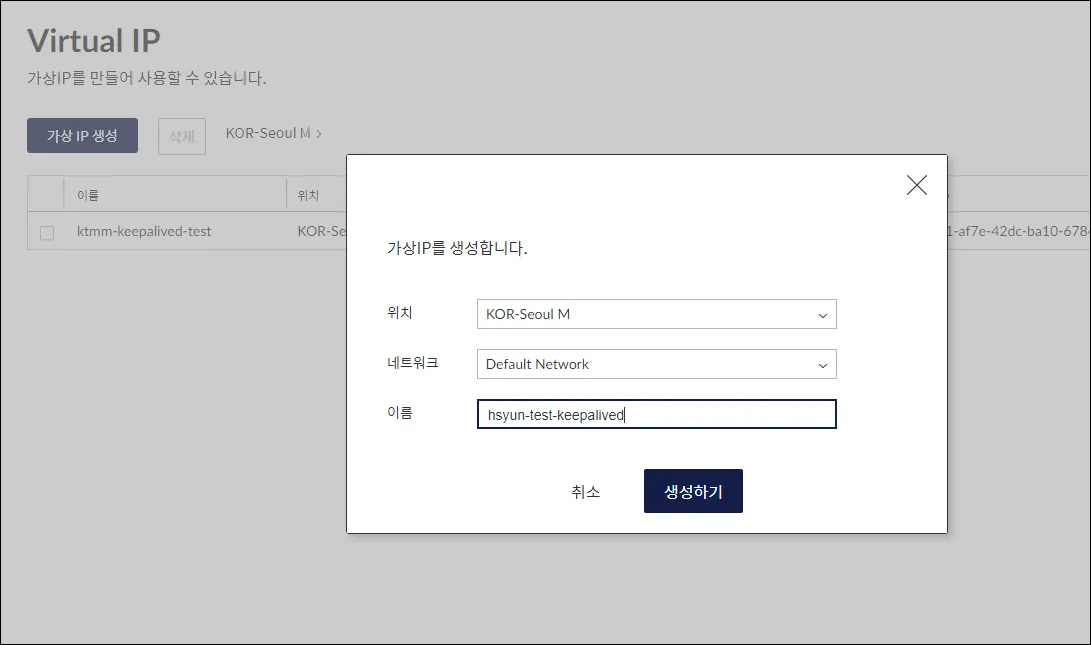
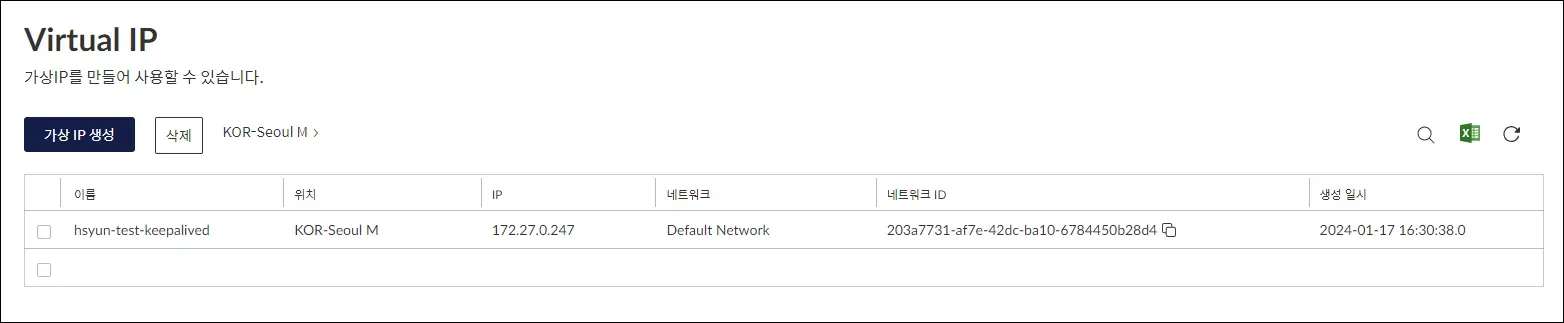
kt cloud에서 VIP 생성해주었다.
해당 VIP는 서버에 연결할 필요 없으며, keepalived에 설정해주면 된다.
3. keepalived 설치 및 설정
간단하게 패키지 매니저로 설치해주었다.
dnf install -y keepalived설정 파일은 기본적으로 /etc/keepalived/keepalived.conf 에 위치해있다.
Master Server 설정
# keepalived.conf
vrrp_track_process track_node_exporter {
process node_exporter
interval 2 # every 2 seconds
}
vrrp_instance VI_1 {
state MASTER # MASTER 또는 BACKUP 지정
interface eth0 # interface to monitor
virtual_router_id 251 # MASTER, BACKUP 같은 router_id 에 있어야 함
priority 100 # MASTER가 더 높은 우선순위를 가짐
virtual_ipaddress {
172.27.0.247 # virtual ip address
}
track_process {
track_node_exporter
}
notify_fault "systemctl start node_exporter.service"
}-
vrrp_track_process [이름]: 특정 프로세스의 상태를 모니터링 설정- process: 프로세스 지정
- interval: node_exporter 프로세스를 2초마다 확인
-
vrrp_instance [이름]: 서버 설정-
state: MASTER, BACKUP 서버에 맞게 작성
-
interface: 헬스체크 패킷 오고갈 NIC 선택
-
virtual_router_id: 1~255 할당 가능, 같은 대역대 안에서 사용 중인 id 사용한다면 에러 발생
-
priority: 우선순위 높을 수록 높은 값 작성
-
virtual_ipaddress: VIP 입력(master, backup 동일하게)
-
track_script: 인터페이스에서 추적할 스크립트 추가
위의 vrrp_script에서 등록한 [이름]을 기입
-
Slave(Backup) Server 설정
vrrp_instance VI_1 {
state BACKUP # BACKUP 으로 설정
interface eth0
virtual_router_id 251
priority 99
virtual_ipaddress {
172.27.0.247
}
notify_master "systemctl start node_exporter.service"
notify_backup "systemctl stop node_exporter.service"
}Master 서버 설정과 거의 유사하지만, state에 BACKUP으로 꼭 설정해주어야 한다.
- notify_master: master 서버 되었을 시 실행하는 스크립트
- notify_backup: backup 서버 되었을 시 실행하는 스크립트
- notify_fault: fault 서버 되었을 시 발생하는 스크립트 (fault: 헬스체크 실패)
설정이 완료되었으면, keepalived를 실행해주면 된다.
systemctl start keepalived📌 keeplived 테스트
MASTER 서버에서 node exporter 서비스 다운 시 다음과 같이 상태가 변경된다.
MASTER 서버: FAULT → BACKUP → MASTER
BACKUP 서버: MASTER → BACKUP
각 서버의 사설 IP 상황은 다음과 같다.
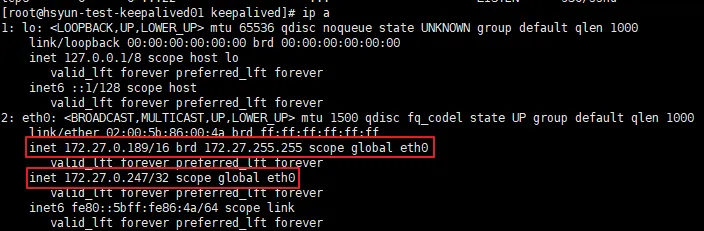
Master
- 기존 사설 IP + VIP
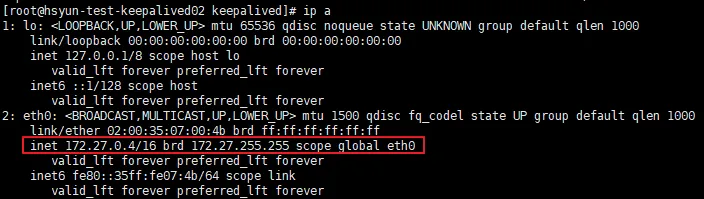
Slave
- 사설 IP만 보유
이제 테스트를 위해 Master 서버의 node exporter를 내려보자.
systemctl stop node exporterMaster 서버에서는 다음과 같은 변화가 일어났다.
- Node Exporter stop → FAULT STATE로 변경
- 자동으로 Node Exporter Start → BACKUP STATE로 변경
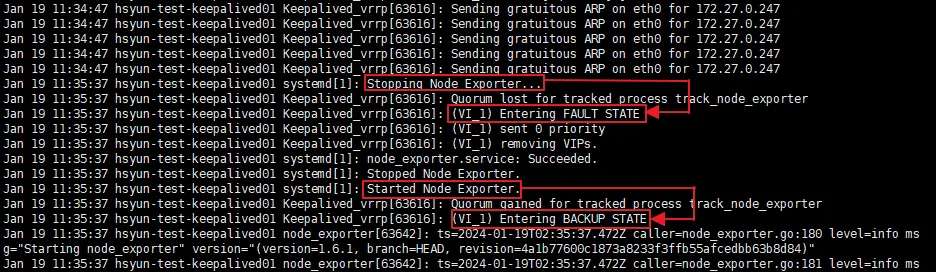
Slave 서버에서는 BACKUP에서 MASTER로 상태가 변경됐다.
- MASTER 서버에서 Node Exporter stop → MASTER STATE로 변경
- 동시에 Node Exporter start
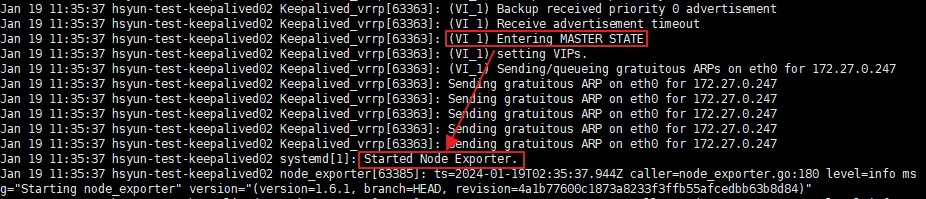
이 때 VIP는 Slave 서버로 넘어가게 되며, 자동으로 failover가 된 것을 볼 수 있다.
이후 설정한 우선순위로 인해 기존 Master 서버가 BACKUP 상태에서 MASTER 상태로 변경된다.
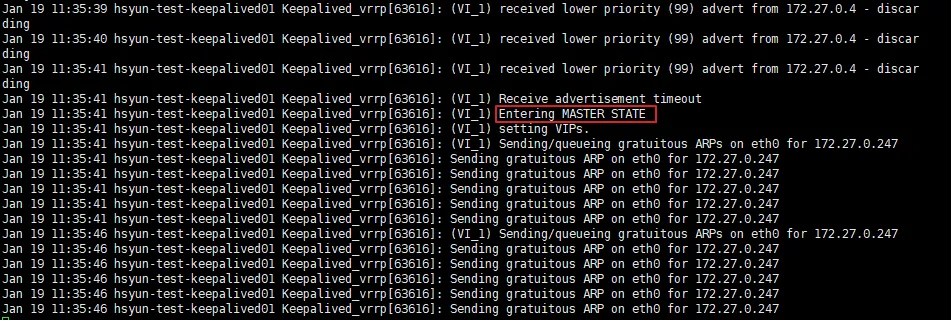
그리고 Slave 서버는 MASTER 상태에서 다시 BACKUP 상태로 변경되었다.
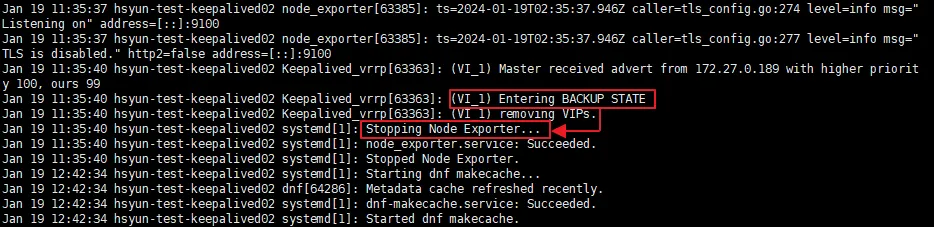
VIP는 다시 Master 서버로 복구되며, 자동으로 failback까지 된 것을 볼 수 있다.
