
출처
백준 - 단어 공부
🔎 문제
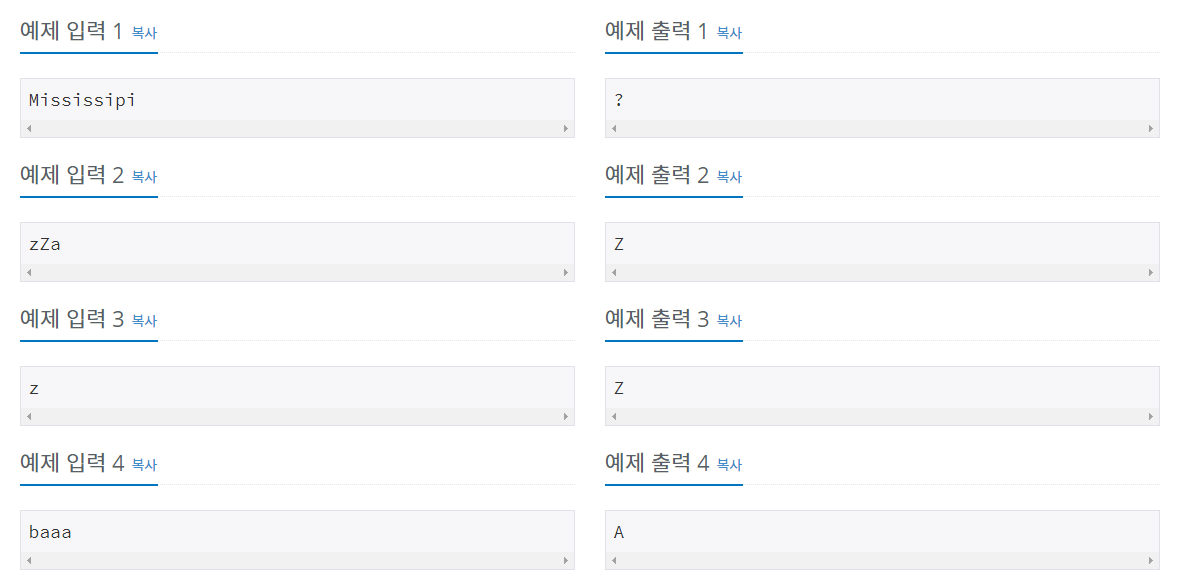
알파벳 대소문자로 된 단어가 주어지면, 이 단어에서 가장 많이 사용된 알파벳이 무엇인지 알아내는 프로그램을 작성하시오. 단, 대문자와 소문자를 구분하지 않는다.
🚫 입력 및 출력
<입력>
첫째 줄에 알파벳 대소문자로 이루어진 단어가 주어진다.
주어지는 단어의 길이는 1,000,000을 넘지 않는다.
<출력>
첫째 줄에 이 단어에서 가장 많이 사용된 알파벳을 대문자로 출력한다.
단, 가장 많이 사용된 알파벳이 여러 개 존재하는 경우에는 ?를 출력한다.
💻 입출력 예
📄🤔 코드 및 풀이과정
🔹 1번
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.HashMap;
import java.util.Iterator;
public class Baekjoon1157 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
String input = br.readLine().toUpperCase();
HashMap<Character, Integer> hm = new HashMap<>();
int max = 1;
char one;
for (int i = 0; i < input.length(); i++) {
one = input.charAt(i);
if(hm.containsKey(one)) {
int value = hm.get(one);
if(max<value + 1) max = value + 1;
hm.replace(input.charAt(i), value + 1);
}else {
hm.put(one, 1);
}
}
char result = ' ';
Iterator<Character> ir = hm.keySet().iterator();
while (ir.hasNext()) {
Character key = ir.next();
if(hm.get(key)==max) {
result = (result == ' ') ? key : '?';
}
}
bw.write(result);
bw.flush();
bw.close();
br.close();
}
}🔸 1번 풀이
처음 코드는
우선 BufferedReader로 문자열을 읽어오고
이를 toUpperCase 메서드를 사용해 대문자로 변환하여
대소문자 구분을 하지 않는다는 문제의 조건에 맞췄다.
그 뒤엔 HashMap을 활용하여
key로 알파벳을, value로 알파벳 갯수를 저장하고
최대 알파벳 갯수를 max에 저장했다.
이후에 Iterator로 value값들을 가져와 max와 비교하고
삼항연산자를 통해 중복이 없을 경우 해당 알파벳을,
중복이 있을 경우 '?' 를 저장하여 BufferedWriter로 출력했다.
위의 로직으로 문제를 통과했지만
메모리는 40924KB / 처리시간 308ms
으로 꽤나 묵직하고 비효율적인 코드라는 결과를 얻었다.
처음에 배열을 사용할까 고민하다 컬렉션을 사용해봤는데
결과를 보니 구지여 컬렉션을 사용할 필요가 있는 문제일까?
라는 생각이 들어 배열을 사용해 문제를 다시 풀어보았다.
🔹 2번
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Baekjoon1157 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
char[] charArr = br.readLine().toUpperCase().toCharArray();
int[] cnt = new int[26];
int max = 1;
int one;
for (int i = 0; i < charArr.length; i++) {
one = charArr[i]-65;
if(++cnt[one]>max) {
max=cnt[one];
}
}
int maxValue = 0;
int maxCount = 0;
for (int i = 0; i < cnt.length; i++) {
if(cnt[i] == max) {
maxCount++;
maxValue = i;
}
}
if(maxCount==1) {
System.out.print((char)(maxValue+65));
}else {
System.out.print('?');
}
br.close();
}
}🔸 2번 풀이
이번엔 입력값을 받는 동시에 toUpperCase로 대문자로 변환한 뒤
toCharArray() 메서드로 문자들을 charArr라는 배열에 넣었다.
그리고 A~Z까지의 알파벳 갯수는 26개이니
26의 크기를 가지고 각 알파벳의 등장 횟수를 카운트할
cnt 배열을 생성했다.
그 뒤에 알파벳의 아스키코드값-65를 한 값에 해당하는
cnt 배열의 인덱스 값을 1 증가시켜 알파벳 갯수를 카운트하고
max 변수에 최대 알파벳 갯수를 저장하도록 했다.
이후 최대 알파벳 갯수를 가진 알파벳이 1개인지 여러개인지 확인을 위해
maxCount 변수에 최대 알파벳 갯수를 가진 알파벳 수를 저장하고
maxValue에는 최대 알파벳 갯수를 가진 알파벳값을 저장했다.
이를 활용해 최대 알파벳 갯수를 가진 알파벳이 1개라면
maxValue에 저장된 값을 활용하여 해당 알파벳을 출력하고
최대 알파벳 갯수를 가진 알파벳이 여러개라면 ? 가 출력되도록 했다.
1번 코드보다 낭비를 줄이고 가독성을 높여
메모리 26296KB / 처리시간 212ms
라는 결과를 얻어 메모리는 14000, 처리시간은 90정도를 단축했다.
하지만 아직도 아쉬움이 남았다.
자바 8 기준 1등의 처리시간을 보니 104ms 로
나보다 2배 이상 빠른 코드를 같은 언어에서 구현했다.
적어도 같은 100단위에는 들어야 하지 않을까? 하고
전의를 불태우며 또다시 코드를 작성해보기로 했다.
🔹 3번
import java.io.IOException;
public class Baekjoon1157 {
public static void main(String[] args) throws NumberFormatException, IOException {
int one = 0;
int[] cnt = new int[26];
int max = 0;
while((one = System.in.read()) != '\n') {
if(one>=97) one -= 32;
if(++cnt[one-65] > max) {
max= cnt[one-65];
}
}
int maxCount = 0;
int maxValue = 0;
for (int i = 0; i < cnt.length; i++) {
if(cnt[i]==max) {
maxCount++;
maxValue = i;
}
}
char result = ' ';
if(maxCount==1) result = (char)(maxValue+65);
else result = '?';
System.out.println(result);
}
}🔸 3번 풀이
이번 코드를 작성하며 중점을 둔 부분은
입력을 받는 과정에서 좀 더 효율적으로 받을 수 없을까? 였다.
기존에는 readLine()으로 한줄을 받아와 각 문자를 대문자로 변환하고
이를 배열에 넣어 저장하도록 했다.
이 과정에서 발생하는 대문자 변환, 한 문자씩 자르기를 없애
어떻게든 조금이라도 더 줄여보려 노력하다 System.in.read()가 떠올랐다.
System.in.read()는
입력된 내용 중 첫 문자를 읽어들여 문자의 아스키코드값을
int형으로 반환환해주고, 나머지 입력은 버퍼에 남겨둔다.
다시 System.in.read()가 실행되면
버퍼에 남아있는 첫 문자를 반환하고
나머지 문자들은 버퍼에 또다시 남는 특성과 while문을 활용해
입력한 문자열을 한 문자씩 int형으로 얻어올 수 있다.
System.in.read()는 입력값을 입력하고 엔터를 누를 경우
엔터에 해당하는 13, 개행에 해당하는 10('\n) 값도 입력되어
while문에서 개행값(\n)을 가져오기 전까지
System.in.read()를 반복하도록 했다.
이러한 과정에서 문자열을 하나하나 분리하는 과정을 없앨 수 있었고
대문자로 모든 문자를 변환하기보단 소문자 값이 입력되면
32를 빼서 대문자 아스키코드값과 동일하게 만들어 변환 과정을 없앴다.
몇시간동안 머리를 부여잡으며 노력한 결과에 부응하듯이
메모리 11648KB / 처리시간 120ms
라는 2번보다 훨씬 빨라진 결과가 나왔으며
자바 8 기준 전체인원 4900명중 19등이 될 정도로 좋은 결과가 나왔다!
😳❕ 소감 & 느낀점
알고리즘 문제를 풀면서 매번 느끼는 것이지만
정말 한 문제에 대한 무궁무진한 풀이법이 존재하는 것 같다.
마치 어떠한 장소를 찾아갈 때 이용할 수 있는 길이
지름길, 평범한 길, 돌아가는 길과 같이 여럿이듯
문제도 결과에 도달할 수 있는 무수히 많은 길이 있다.
아무리 멀리 돌아가더라도 목적지에 도달할 수 있다면
그 길이 오답은 아니겠지만, 좋은 답은 아닐 것이다.
알고리즘 풀이를 하며 계속 더 많은 지식을 습득하고,
더 많은 생각을 하며 다양한 시도를 해 보는 것이
문제 해결에 대한 지름길을 찾는 방법을 배우는 과정이라 생각한다.
개발자가 되기 위한 공부를 시작한지 얼마 되지 않아
아직은 평범한 길이나 돌아가는 길을 선택하는 일이 많은데
앞으로도 꾸준히 알고리즘 공부, 여러 클래스와 메서드들을 공부하며
지름길을 찾는 방법들을 익혀나가야겠다 :)
