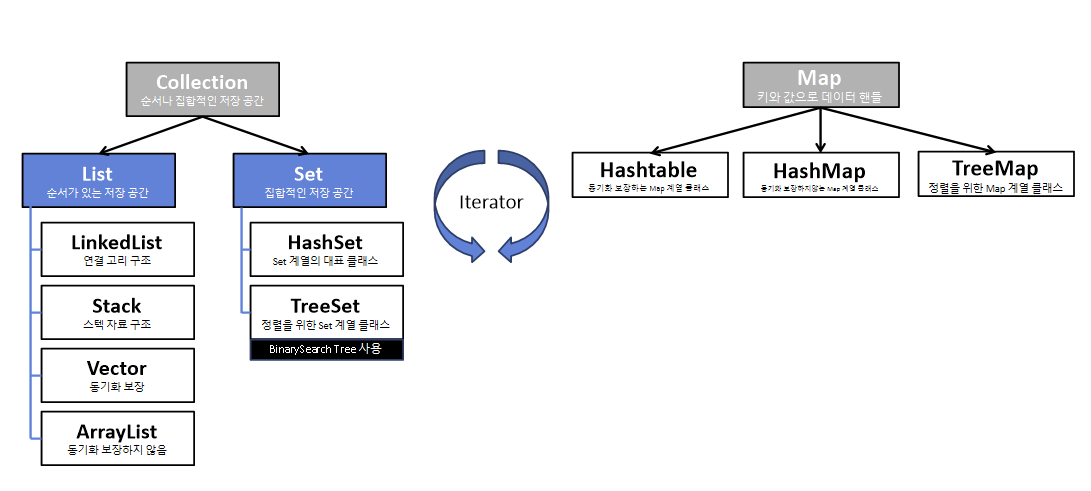
Collection Framework
- 프로그램 구현에 필요한 자료구조를 구현해놓은 JDK 라이브러리
- java.util 패키지에 구현되어 있음
[Collection Framework의 주요 Interface]
🧣 List<E>
- 객체를 순서에 따라 저장하고 관리
공통 메서드
| 기능 | 리턴 타입 | 메서드 | 설명 |
|---|---|---|---|
| 객체 추가 | void | add(int index, Object element) | 주어진 index에 객체를 추가, index 생략시 맨 뒤에 추가 |
| boolean | addAll(int index, Object element) | 주어진 index에 컬렉션을 추가, index 생략시 맨 뒤에 추가 | |
| Object | set(int index, Object element) | 주어진 index에 객체를 저장 | |
| 객체 검색 | Object | get(int index) | 주어진 인덱스에 저장된 객체를 반환 |
| boolean | isEmpty() | 해당 컬렉션이 비어있는지 확인 | |
| int | indexOf(Object o) / lastIndexOf(Object o) | 순방향 / 역방향으로 탐색하여 주어진 객체의 위치를 반환 | |
| ListIterator | listIterator() / listIterator(int index) | List의 객체를 탐색할 수 있는ListIterator 반환 / 주어진 index부터 탐색할 수 있는 ListIterator 반환 | |
| List | subList(int fromIndex, int toIndex) | fromIndex부터 toIndex에 있는 객체를 반환 | |
| 객체 삭제 | Object | remove(int index) | 주어진 인덱스에 저장된 객체를 삭제하고 삭제된 객체를 반환 |
| boolean | remove(Object o) | 주어진 객체를 삭제, 삭제 성공하면 true, 실패하면 false | |
| void | clear() | 해당 컬렉션의 모든 객체를 삭제 | |
| 객체 정렬 | void | sort(Comparator c) | 주어진 비교자(comparator)로 List를 정렬 |
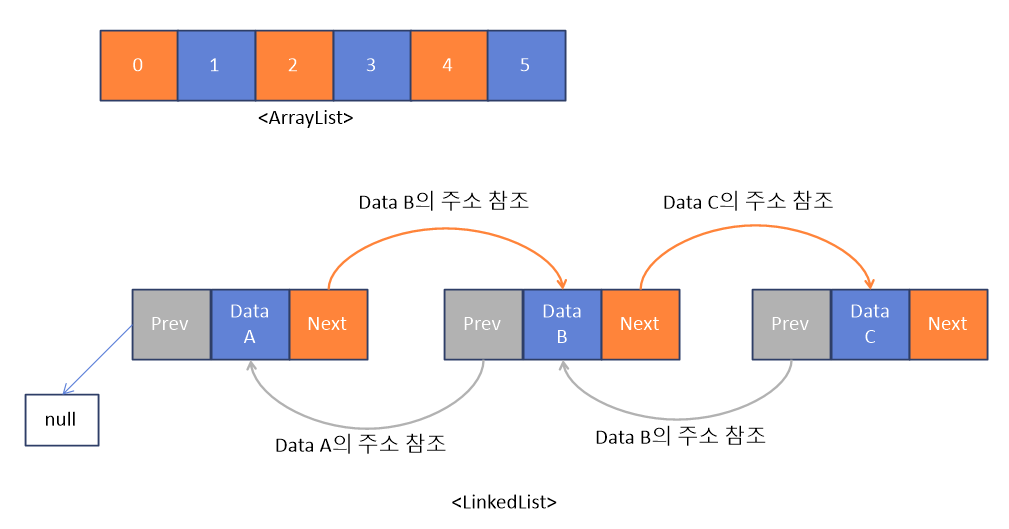
ArrayList와 LinkedList
-
ArrayList
- 데이터가 연속적으로 존재
- 해당 index를 통해 빠르게 검색 가능
- 데이터 추가/삭제시 데이터의 복사로 인해 많은 비용 발생
-
LinkedList
- 데이터가 불연속적으로 존재
- 데이터 검색시 노드들을 순회해야하기 때문에 많은 비용 발생
- 데이터 추가/삭제시 Prev/Next만 변경해주면 되므로 적은 비용 발생
🛒 Set<E>
- 순서와 관계없이 중복을 허용하지 않고 유일한 값을 관리
HashSet과 TreeSet
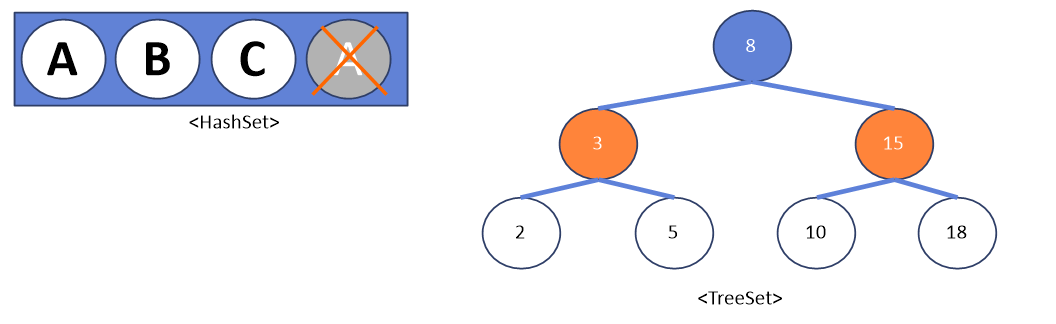
HashSet은 집합이라고 보면 되고 TreeSet의 경우 Binary Tree의 구조로 구성된다. 정렬과 검색에 특화된 자료구조이며 모든 왼쪽 자식의 값이 루트나 부모보다 작고 모든 오른쪽 자식의 값은 루트나 부모보다 크다.
Comparable과 Comparator
"컬렉션을 정렬하기 위해 제공되는 인터페이스"
Comparable은 비교대상(매개 변수)와 자기자신을 비교, Compartor는 매개 변수인 두 객체를 비교하며 Comparator의 compare() 메서드를 Overriding하여 정렬기준을 새롭게 정의할 수 있다.
Comparable Interface
public class Dictionary implements Comparable<Dictionary> {
private char alphabet;
public Dictionary(char alphabet) {
// 소문자로 변경
if(65 <= alphabet && alphabet < 91 )
this.alphabet = (char)(alphabet + 32);
else
this.alphabet = alphabet;
}
public char getAlphabet() {
return alphabet;
}
public void setAlphabet(char alphabet) {
// 소문자로 변경
if(65 <= alphabet && alphabet < 91 )
this.alphabet = (char)(alphabet + 32);
else
this.alphabet = alphabet;
}
@Override
public int compareTo(Dictionary dictionary) {
if(alphabet > dictionary.getAlphabet()){
return 1;
} else if(alphabet < dictionary.getAlphabet()){
return -1;
} else {
return 0;
}
}
}
import java.util.*;
public class ComparableTest {
public static void main(String[] args) {
Set<Dictionary> dictionaries = new TreeSet<>();
// Set<Dictionary> dictionaries = new Set<>(); // hashSet은 정렬이 되지 않음!
Dictionary dictionary1 = new Dictionary('c');
Dictionary dictionary2 = new Dictionary('b');
Dictionary dictionary3 = new Dictionary('a');
dictionaries.add(dictionary1);
dictionaries.add(dictionary2);
dictionaries.add(dictionary3);
for(Dictionary dictionary : dictionaries){
// a, b, c 순으로 출력
System.out.println(dictionary.getAlphabet());
}
}
}데이터를 c, b, a 순으로 삽입을 하였지만 출력은 a, b, c 순으로 출력이 되었다. 이는 Comparable interface를 implements하여 compareTo() 메서드를 Overriding 하여 정렬기준을 오름차순으로 지정했기 때문이다.
Comparator interface
public class Market {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Market() {}
public Market(int id , String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Market{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
import java.util.Comparator;
// 새로운 정렬 기준 정의
public class SortById implements Comparator<Market> {
@Override
public int compare(Market market1, Market market2) {
return market1.getId() - market2.getId();
}
}
import java.util.*;
public class ComparatorTest {
public static void main(String[] args) {
List<Market> markets = new ArrayList<>();
Market market1 = new Market(10, "우리 마트");
Market market2 = new Market(2, "너희 마트");
Market market3 = new Market(250, "너희 마트");
markets.add(market1);
markets.add(market2);
markets.add(market3);
// 직접 작성한 정렬 기준으로 해당 컬렉션을 정렬!
Collections.sort(markets, new SortById());
for(Market market : markets)
System.out.println(market.toString());
// Market{id=2, name='너희 마트'}
// Market{id=10, name='우리 마트'}
// Market{id=250, name='너희 마트'}
}
}Comparator interface는 직접 작성한 정렬 기준을 이용하여 정렬을 할 수 있게 해준다. 이때 compare() 메소드를 Overriding하여 정렬 기준을 설정한다.
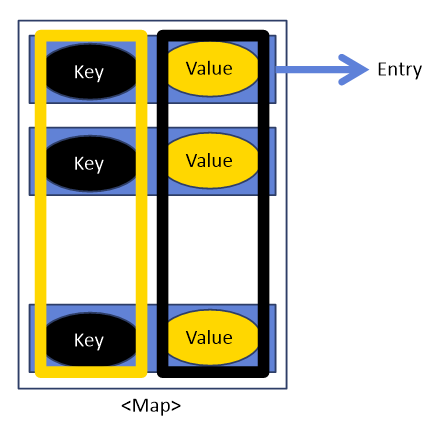
🔑 Map<K, V>
- key-value로 이루어진 객체를 관리
- key는 중복 허용하지 않음
메서드
| 기능 | 리턴 타입 | 메서드 | 설명 |
|---|---|---|---|
| 객체 추가 | Object | put(Object key, Object value) | 주어진 키로 값을 저장, 이전 값을 리턴(새로운 키 - null / 동일 키 - 이전 값) |
| 객체 검색 | boolean | containsKey(Object key) | 주어진 키가 있으면 true, 없으면 false를 리턴 |
| boolean | containsValue(Object value) | 주어진 값이 있으면 true, 없으면 false를 리턴 | |
| Set | entrySet() | 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴 | |
| Object | get(Object key) | 주어진 키에 해당하는 값을 리턴 | |
| boolean | isEmpty() | 컬렉션이 비어 있는지 확인 | |
| Set | keySet() | 모든 키를 Set 객체에 담아서 리턴 | |
| int | size() | 저장된 키-값 쌍의 총 갯수를 리턴 | |
| Collection | values() | 저장된 모든 값을 Collection에 담아서 리턴 | |
| 객체 삭제 | void | clear() | 모든 Map.Entry(키와 값)을 삭제 |
| Object | remove(Object key) | 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 리턴 |
Iterator
- Collection Framework에 저장된 요소들을 하나씩 차례로 참조
- for-each 문을 이용하여 컬렉션을 순회 가능(권고!)
| 메서드 | 설명 |
|---|---|
| boolean .hasnext() | 다음 순회할 항목이 있는지 확인 |
| Object .next() | 다음 순회할 항목을 return |
