0. 사전학습
- 생성 모델 (Generative Model): 데이터의 확률 분포를 학습하여 그와 유사한 새로운 데이터를 생성해내는 모델입니다.
- 판별 모델 (Discriminative Model): 입력 데이터가 어떤 클래스에 속하는지, 혹은 진짜인지 가짜인지 분류하는 모델입니다.
- 다층 퍼셉트론 (MLP): 여러 개의 은닉층을 가진 기본적인 신경망 구조입니다.
- 역전파 (Backpropagation): 신경망의 가중치를 업데이트하기 위해 오차를 뒤에서부터 앞으로 전달하는 알고리즘입니다.
- 마르코프 체인 (Markov Chain): 과거의 상태와 무관하게 현재 상태에 의해서만 미래 상태가 결정되는 확률 과정입니다. 기존 생성 모델들은 이를 활용했으나 연산 비용이 컸습니다.
- 동전 앞뒤를 예측하는 것은 독립시행이기 때문에 n번째 상태가 n+1번째 상태에 영향을 주지 않으므로 마르코프 성질이 없다.
- 반면 날씨 예측과 같이 직관적으로 오늘 날씨에 의해 내일 날씨가 결정될 수 있으므로 마르코프 성질이 있다.
- 게임 이론 (Minimax Game): 한쪽은 이득을 최대화하고 다른 쪽은 손실을 최소화하려는 전략적 대결 상황을 의미합니다.
1. 연구 배경 및 목표
연구 배경
- 그동안 딥러닝은 고차원의 센서 입력을 클래스 레이블로 매핑하는 판별 모델에서 큰 성공을 거두었습니다. 이는 역전파와 드롭아웃, 선형 유닛(ReLU 등)의 발전 덕분이었습니다.
- 반면 딥 생성 모델은 판별 모델에 비해 큰 두각을 나타내지 못했습니다. 그 이유는 다음과 같습니다.
- 최대 가능도 추정(Maximum Likelihood Estimation) 과정에서 발생하는 복잡한 확률 연산을 근사하기가 매우 어렵습니다.
- 판별 모델에서 효과적이었던 선형 유닛들의 장점을 생성 모델에 적용하기 어려웠습니다.
연구 목표
- 복잡한 확률 계산이나 마르코프 체인 없이도 학습이 가능한 새로운 생성 모델 프레임워크를 제안하는 것입니다.
- 오직 역전파와 드롭아웃만을 사용하여 학습하고 순전파만으로 샘플을 생성할 수 있는 시스템을 구축하고자 합니다.
2. 핵심 방법론 (Generative Adversarial Nets)
기존의 생성 모델들은 수학적으로 매우 복잡하고 다루기 힘들었습니다.
→ GAN 의 해결책: "수학적으로 확률 분포를 정의하지 말자! 대신 가짜를 만드는 기계()와 가짜를 찾는 기계()를 싸우게 만들자."
생성자 (Generator, )
- 입력: 의미 없는 무작위 노이즈()
- 출력: 실제 데이터와 똑같이 생긴 가짜 데이터()
- 목표: 판별자()를 완벽하게 속이는 것
판별자 (Discriminator, )
- 입력: 실제 데이터() 또는 생성자가 만든 가짜()
- 출력: 입력 데이터가 '진짜'일 확률 (0에서 1 사이의 값)
- 목표: 진짜와 가짜를 구별해내는 것
미니맥스(Minimax) 게임의 수식 풀이
- 좌변
- : 와 가 벌이는 게임의 가치 함수(Value Function)입니다. 쉽게 말해 '판별자 의 점수'라고 생각하면 됩니다.
- : 판별자()는 자신의 점수인 를 최대한 높이려고 노력합니다.
- : 생성자()는 판별자의 점수인 를 최대한 낮추려고 노력합니다.
- 우변
- 첫번째 항 (진짜를 진짜라고 맞히기)
- : 실제 데이터 분포()에서 뽑은 진짜 데이터()를 의미합니다.
- (Expectation): 기댓값입니다. 데이터를 여러 번 뽑았을 때 나오는 값들의 평균을 내겠다는 뜻입니다.
- : 진짜 데이터()를 보고 판별자가 내놓은 "진짜일 확률"입니다. (0~1 사이의 값)
- :
- 판별자가 진짜를 진짜라고 잘 판단하면(가 1에 가까우면), 이 됩니다.
- 판별자가 진짜를 가짜라고 오판하면(가 0에 가까우면), 가 되어 점수가 매우 낮아집니다.
- 즉, 판별자()는 이 값을 0(최대치)으로 유지하려고 노력합니다.
- 두번째 항 (가짜를 가짜라고 맞히기)
- : 무작위로 생성된 노이즈()입니다.
- : 생성자()가 노이즈를 받아 만들어낸 가짜 데이터입니다.
- : 판별자가 가짜 데이터()를 보고 판단한 "진짜일 확률"입니다.
- : 판별자가 가짜를 보고 "이건 가짜야"라고 올바르게 판단할 확률입니다.
- :
- 판별자가 가짜를 가짜라고 잘 잡아내면(가 0에 가까우면), 이 되어 점수가 높아집니다.
- 반대로 생성자가 판별자를 완벽히 속이면(가 1에 가까우면), 가 되어 판별자의 점수가 깎입니다.
- 첫번째 항 (진짜를 진짜라고 맞히기)
GAN의 학습 과정과 최종 목표
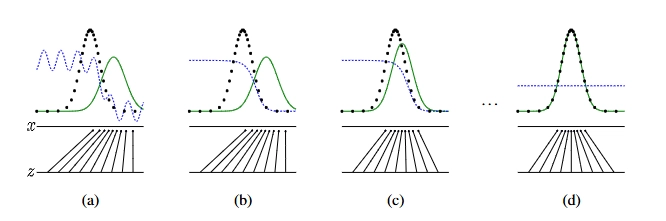
- 검은 점선 : 실제 데이터의 분포입니다. 우리가 닮고 싶어 하는 '정답'입니다.
- 초록 실선: 생성자()가 만들어낸 가짜 데이터의 분포입니다.
- 파란 파선: 판별자의 분포입니다. 값이 높으면 진짜라고 판단하고, 낮으면 가짜라고 판단하는 '기준선'입니다.
- 아래쪽 수평선: 생성자의 입력으로 들어가는 노이즈 공간입니다.
- 위쪽 수평선: 실제 데이터가 존재하는 공간입니다.
- 화살표: 노이즈를 생성자에 넣었을 때, 실제 데이터 공간의 어느 지점으로 매핑되는지를 보여줍니다.
3. 실험
1) 사용된 데이터셋
- MNIST: 손글씨 숫자 데이터.
- TFD (Toronto Face Database): 얼굴 표정 데이터.
- CIFAR-10: 사물 이미지 데이터.

2) 모델 구조 (사용된 기술)
- 생성자 (): ReLU 활성화 함수와 Sigmoid를 섞어서 사용했습니다. 노이즈()는 맨 아래 층에만 입력했습니다.
- 판별자 (): Maxout 활성화 함수를 사용했고 과적합을 막기 위해 Dropout 기술을 적용했습니다.
3) 성능 평가 방법: Parzen Window
GAN은 생성된 결과물이 실제와 얼마나 유사한지 수치화하기가 매우 어렵습니다. 그래서 이 논문은 가우시안 Parzen 창(Gaussian Parzen Window)이라는 방법을 썼습니다.
- 방법: 생성자가 만든 샘플들을 주변으로 가우시안 분포를 씌워 전체적인 확률 밀도를 추정하는 방식입니다.
- 작동 원리
-
샘플 준비
생성자()를 이용해 가짜 이미지 샘플들을 아주 많이(예: 수천 장) 뽑아냅니다. 이 샘플들은 공간 위에 흩뿌려진 점들이 됩니다. -
가우시안 분포 씌우기 (번지게 하기)
각각의 점(샘플) 위에 종 모양의 가우시안(Gaussian) 분포를 하나씩 얹습니다.
- 그러면 뾰족했던 점들이 주변으로 부드럽게 번지게 됩니다.
- 이때 얼마나 넓게 번지게 할지를 결정하는 값이 논문에 나온 (표준편차)입니다.
-
전체 합치기
번진 수많은 종 모양들을 모두 더합니다.
- 점들이 몰려 있는 곳은 산처럼 높게 솟아오르고 점이 없는 곳은 낮게 유지됩니다.
- 이렇게 합쳐진 전체 모양이 바로 생성자가 만든 가짜 데이터의 확률 밀도 함수()가 됩니다.
-
- 작동 원리
- 결과: GAN은 기존의 유명한 모델보다 더 높은 로그 가능도(Log-likelihood) 수치를 기록하며 우수함을 입증했습니다.
모델 MNIST (정확도 ↑) TFD (정확도 ↑) DBN Deep GSN GAN
4. 장점과 단점
단점 (부족한 점)
- 수치화의 어려움: "이 이미지가 진짜일 확률이 몇 %인가?"라는 질문에 정확한 숫자로 답하기 어렵습니다.
- 학습의 불안함: 생성자가 판별자를 너무 빨리 이겨버리면, 맨날 똑같은 이미지(치트키)만 만드는 '모드 붕괴' 현상이 일어납니다.
장점 (좋은 점)
- 속도와 간결함: 복잡한 수학적 절차 없이 딥러닝 기본 원리(역전파)만으로 아주 빠르게 학습합니다.
- 설계의 자유: 어떤 신경망이든 가져다 쓸 수 있어 응용 범위가 넓습니다.
- 선명함: 기존 모델들보다 훨씬 또렷하고 진짜 같은 이미지를 만듭니다.
5. 향후 계획
- 조종하기: "고양이 그려줘"처럼 내가 원하는 결과를 고를 수 있게 만들기 (cGAN)
- 분류하기: 사진이 뭔지 맞히는 인공지능 학습에 활용하기 (준지도 학습)
- 효율 높이기: 생성자와 판별자가 더 효율적으로 경쟁하는 방법 찾기
GAN의 분야별 활용 사례
- 이미지 및 영상 분야
- 이미지 합성 및 변환
- 화질 개선
- 이미지 복원
- 딥페이크
- 음성 및 오디오 분야
- 음성 합성
- 노이즈 제거
- 악기 소리 변환
- 의료 및 과학 분야
- 의료 데이터 증강
- 신약 개발
- 보안 및 기타
- 이상 탐지
- 텍스트 생성
강화학습과의 차이점
(생성자가 판별자의 피드백을 받아 성능을 개선한다는 점은 강화학습의 '보상' 개념과 매우 유사해 보인다.)
가장 핵심적인 차이는 생성자가 "어떻게 고쳐야 할지 구체적으로 아느냐" 아니면 "잘했는지 못했는지만 아느냐"의 차이입니다.
- GAN (미분 가능한 통로): 판별자는 생성자에게 "너의 픽셀 중 이 부분이 어색해서 가짜라고 판단했어"라는 정보를 경사도(Gradient)라는 수치를 통해 직접 전달합니다. 생성자는 이 통로(역전파)를 통해 어디를 어떻게 수정해야 할지 구체적인 방향을 즉시 알 수 있습니다.
- 강화학습 (보상 수치): 에이전트(생성자 역할)는 행동을 한 뒤에 "10점" 또는 "-5점" 같은 스칼라 보상(Reward)만 받습니다. 왜 그 점수를 받았는지, 어느 부분을 고쳐야 점수가 오르는지는 스스로 수많은 시행착오(Exploration)를 거치며 깨달아야 합니다.

낮에는 AI 엔지니어로, 밤에는 대학원생으로 인공지능을 탐구하며 기록하는 공간입니다.