0. 사전학습
1) 강화 학습 (Reinforcement Learning)
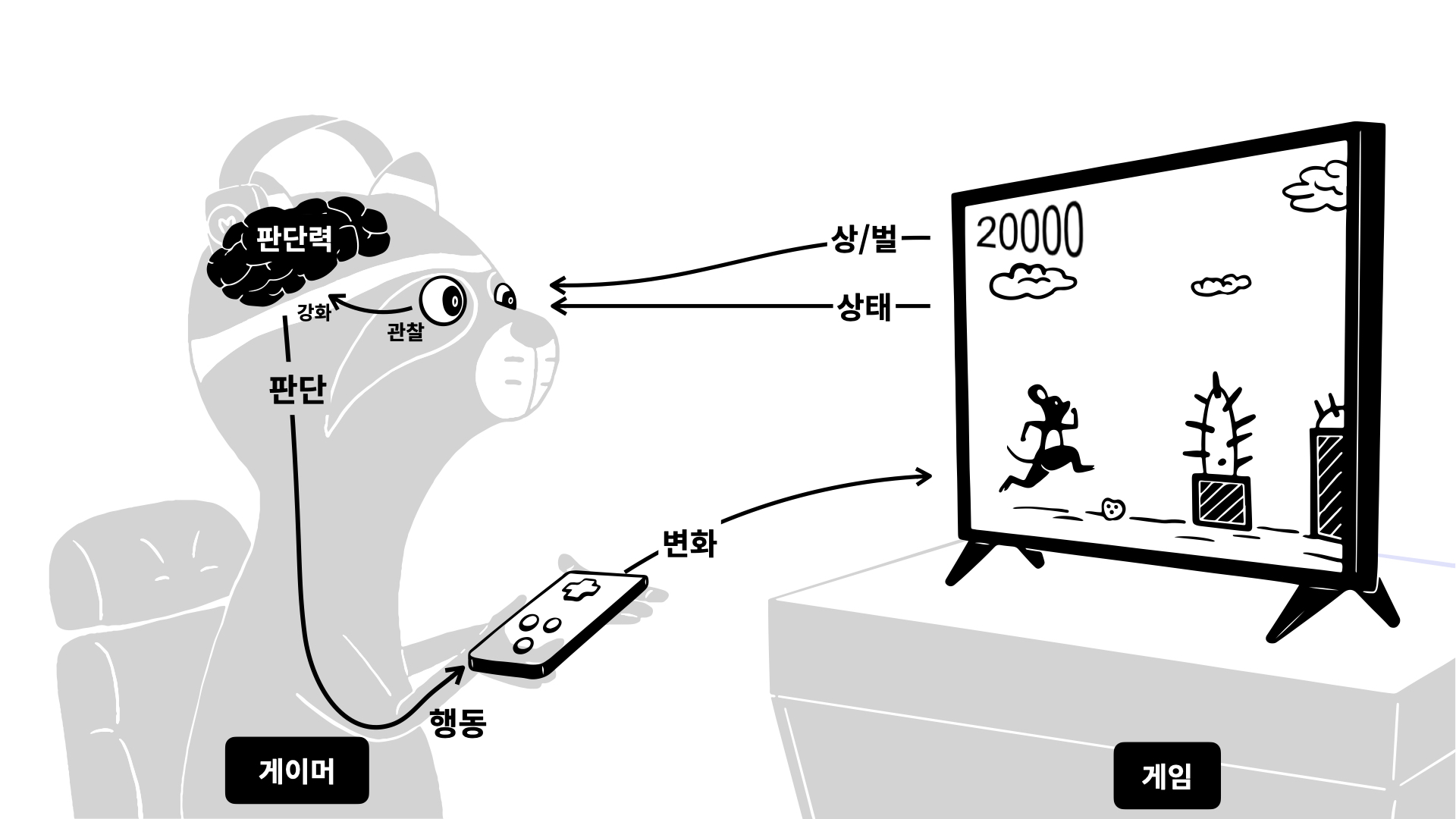
강화 학습은 '시시비비'가 아니라 '보상'으로 배우는 방식입니다. 마치 강아지에게 "앉아"를 가르칠 때 앉으면 간식을 주고 안 앉으면 아무것도 주지 않는 것과 같습니다.
- 에이전트(Agent): 주인공(AI). 게임을 플레이하는 주체입니다.
- 상태(State): 현재 상황. 게임 화면 속 캐릭터의 위치, 적의 유무 등입니다.
- 행동(Action): 주인공이 할 수 있는 선택. (왼쪽 이동, 점프, 공격 등)
- 보상(Reward): 행동의 결과로 얻는 점수.
2) Q-Learning (Q-러닝)
Q-러닝은 '미래 가치 계산기'입니다. 단순히 지금 점수를 얻는 것뿐만 아니라, "지금 이 행동을 하면 나중에 얼마나 큰 이득이 올까?"를 수치화한 것이 Q-값입니다.
- 핵심: 모든 상황에서 각 행동에 대한 점수표(Q-table)를 만드는 작업입니다. 예를 들어 "적 앞에 있을 때 공격" 행동의 Q-값이 높다면 AI는 그 행동을 선택하게 됩니다.
3) CNN (Convolutional Neural Network, 합성곱 신경망)
이 논문의 혁신은 AI에게 '눈(Vision)'을 달아준 것입니다. 이전의 AI는 데이터(좌표값 등)를 숫자로 입력받아야 했지만 CNN 덕분에 게임 화면 그 자체(이미지)를 보고 상황을 판단할 수 있게 되었습니다.
- 역할: 화면 속의 픽셀들을 분석해 "이건 공이고, 저건 벽이다"라는 특징을 스스로 추출합니다.
4) DQN (Deep Q-Network)
이 논문의 제목인 "Deep Reinforcement Learning"이 바로 이 개념입니다. CNN(Deep Learning)과 Q-Learning을 합친 것이죠.
- 왜 합쳤나?
- 기존의 방식은 게임의 모든 상황을 기록한 '거대한 점수표(Q-table)'가 필요했습니다. 하지만 게임 속 경우의 수가 너무 많아 표를 만드는 것이 물리적으로 불가능했습니다.
- 해결 방법
- 인공지능이 모든 경우의 수를 외우는 대신 CNN을 통해 "지금 눈앞에 보이는 화면"의 특징을 실시간으로 파악하게 했습니다.
- 그 정보로 "이 상황에서는 이 행동의 점수가 가장 높겠네"라고 즉석에서 계산하도록 만들어 본 적 없는 상황에서도 유연하게 대처할 수 있게 한 것입니다.
5) t-SNE
t-SNE는 수천 개의 변수를 가진 복잡한 데이터를 2차원 평면에 점으로 찍어 보여주는 기술입니다.
- 핵심 원리: 원래 데이터 공간에서 서로 비슷했던 데이터들은 2차원 평면에서도 가깝게 모이고 달랐던 데이터들은 멀리 떨어지게 만듭니다.
1. 연구 배경 및 목표
-
기존 RL agent들은 feature를 수작업으로 설계하거나 low-dimensional state space에 국한되어 있었습니다.
-
본 연구에서는 이러한 한계를 극복하고 여러 환경에서 픽셀 데이터(화면)와 게임 점수만을 input 으로 받아들이면서도 인간 전문가 수준의 성능을 달성했습니다. → 범용 인공지능(AGI)의 시작
💡 AGI(Artificial General Intelligence): 인간과 동등하거나 그 이상의 지능을 갖고 스스로 학습하며 모든 인지적 작업을 수행할 수 있는 범용적인 AI
2. 핵심 방법론
1) Reinforcement Learning의 목적 함수
강화 학습의 에이전트는 환경과 상호작용하며 누적 보상을 최대화하는 최적 행동 가치 함수 를 학습합니다. 이는 벨만 방정식(Bellman Equation)이라는 재귀적 관계를 기초로 합니다.
| 요소 | 이름 | 의미 |
|---|---|---|
| 최적 행동 가치 함수 | 상황()에서 행동()을 했을 때, 게임 끝날 때까지 얻을 수 있는 '최종 합계 점수의 기댓값'입니다. | |
| (State) | 상태 | 현재 상황입니다. 아타리 게임에서는 화면 픽셀 데이터(이미지)가 곧 상태입니다. |
| (Action) | 행동 | 현재 상황에서 내가 누른 버튼입니다. (예: 왼쪽 이동, 공격 등) |
| 기댓값 | 환경()의 불확실성을 고려한 평균치입니다. 적이 무작위로 움직일 수도 있으니, 다음에 올 상황()들에 대한 평균 점수를 계산한다는 뜻입니다. | |
| (Reward) | 즉각 보상 | 행동을 하자마자 지금 바로 받는 점수입니다. |
| (Gamma) | 할인율 | 미래 점수의 가치를 깎는 비율(보통 0.99)입니다. "내일의 100점보다 오늘 당장의 100점이 더 가치 있다"는 것을 수학적으로 나타냅니다. |
| 최대화 | 다음 상황()이 되었을 때, 에이전트가 바보같이 행동하지 않고 '가장 높은 점수를 주는 행동()'을 선택할 것이라는 가정입니다. | |
| 다음 상태 가치 | 다음 상황()에서 할 수 있는 최고의 행동 가치입니다. |
- 의미: 란, 상태 에서 행동 를 했다는 조건이 주어졌을 때(), 즉시 얻는 보상()과 다음 상황의 미래 가치()를 합친 것의 평균값()이다.
- 한계: 기존 Q-learning은 모든 상태-행동 쌍을 테이블 형태로 기록해야 했으므로 아타리 게임처럼 상태가 무한에 가까운 경우 일반화가 불가능했습니다.
2) CNN의 활용
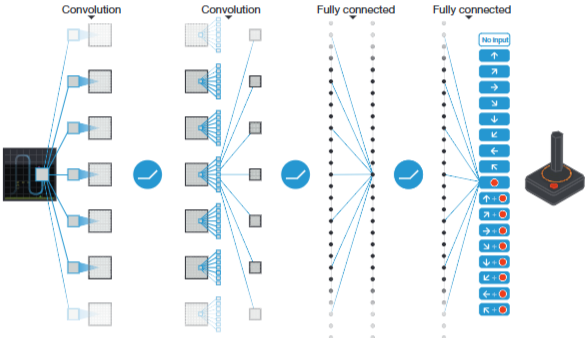
DQN은 Q-함수를 근사하기 위해 CNN을 사용합니다. 이는 전처리된 픽셀 데이터에서 특징을 추출하여 최적의 행동을 추론하는 구조입니다.
(신경망의 최종 출력은 각 가능한 행동에 대한 Q-값이다.)
아키텍처 세부 구성
- 입력층: 이미지. (연속된 4개 프레임을 쌓아 물체의 가속도와 방향 정보를 확보)
- 합성곱 층(Convolutional Layers)
- Layer 1: 32개의 8x8 필터, Stride 4.
- Layer 2: 64개의 4x4 필터, Stride 2.
- Layer 3: 64개의 3x3 필터, Stride 1.
- 완전 연결 층(Fully Connected Layers): 512개의 유닛을 거쳐 최종적으로 가능한 각 행동의 Q-value를 출력합니다.
- 특징: 단 한 번의 연산(Forward pass)으로 현재 상태에서 가능한 모든 행동의 가치를 동시에 산출하여 효율성을 극대화했습니다.
3) 학습 안정화 기법
신경망(CNN)을 강화 학습에 도입할 때 발생하는 수치적 불안정성(발산 및 진동)을 해결하기 위해 두 가지 장치를 도입했습니다.
① Experience Replay (경험 재생)
에이전트의 경험 데이터 를 리플레이 메모리()에 저장하고 학습 시 무작위로 추출한 미니배치를 사용합니다.
- 데이터 효율성: 하나의 경험 데이터를 여러 번 학습에 재사용할 수 있습니다.
- 상관관계 제거: 연속된 데이터 사이의 시간적 상관관계를 끊어 수렴 성능을 높입니다.
- 안정성: 행동 분포를 평활화(Smoothing)하여 파라미터가 급격히 변하거나 국소 최적해에 빠지는 것을 방지합니다.
② Separate Target Network (타겟 네트워크 분리)
학습 목표가 되는 Target Value를 계산할 때, 현재 학습 중인 가중치()가 아닌 별도의 타겟 가중치()를 사용합니다.
- 작동 방식: 타겟 네트워크는 일정 주기( step)마다 현재 네트워크의 가중치를 복제하여 업데이트합니다. 이를 통해 학습 목표가 실시간으로 변동하는 것을 막아 안정적인 수렴을 유도합니다.
4) 손실 함수 및 정규화 (Loss Function & Regularization)
학습의 목표는 벨만 방정식의 좌변()과 우변(Target) 사이의 평균 제곱 오차(MSE)를 최소화하는 것입니다.
| 요소 | 의미 | 역할 |
|---|---|---|
| 손실(Loss) | 현재 신경망이 얼마나 엉터리로 예측하고 있는지를 나타내는 '벌점'입니다. 이 값이 0에 가까울수록 똑똑한 AI입니다. | |
| 무작위 추출 | 리플레이 메모리()에서 과거 경험을 균일한 확률()로 무작위로 꺼내서 평균을 낸다는 뜻입니다. | |
| 타겟(Target) | "정답지"입니다. 타겟 네트워크()를 이용해 계산한 "이랬어야 해"라는 목표값입니다. | |
| 예측값 | "나의 대답"입니다. 현재 학습 중인 네트워크()가 내놓은 추측치입니다. | |
| 제곱 오차 | 정답과 내 대답의 차이를 제곱합니다. 차이가 클수록 벌점이 기하급수적으로 커지게 만듭니다. |
- 의미: 손실 함수()란, 리플레이 메모리에서 무작위로 꺼낸 과거 경험들을 바탕으로 '에이전트가 만든 정답(Target)'과 '현재의 예측값()' 사이의 거리를 측정하여 반성하는 지표이다.
5. 훈련 세부 사항 및 탐색 전략
- Frame Skipping: 연산 효율을 위해 4프레임마다 한 번씩 행동을 결정하고 그 사이 프레임은 이전 행동을 유지합니다.
- -greedy: 초기에는 무작위 행동(Exploration)을 많이 하다가 점진적으로 학습된 최적 행동(Exploitation)의 비중을 높여 탐색과 활용의 균형을 맞춥니다.
- 최적화: 총 5,000만 프레임의 게임 경험을 학습하며 RMSProp 옵티마이저를 사용해 가중치를 업데이트합니다.
6. 요약
💡- 플레이 (경험 수집): [5. 탐색 전략]인 -greedy를 사용하여 행동하고 [2. CNN]으로 처리된 화면 데이터를 기반으로 발생한 경험을 쌓습니다.
- 복습 (데이터 정제): [3-①. Experience Replay]를 통해 메모리에 저장된 과거 경험을 무작위로 추출합니다. 이는 데이터 간 상관관계를 끊어 학습의 안정성을 확보하는 핵심 과정입니다.
- 비교 (목표 설정): [3-②. Target Network]가 제시한 '고정된 정답(Target)'과 현재 Q-network의 '예측치'를 대조합니다. 이 과정은 [1. 목적 함수]의 좌변()과 우변()을 맞추는 작업입니다.
- 교정 (최적화): 둘 사이의 차이를 [4. 손실 함수]로 계산하고 가중치를 업데이트합니다. 이 결과로 에이전트의 예측은 점차 정교해집니다.
3. 평가 및 결과
1) 성능 평가
- 아타리 2600의 49개 게임 중 29개 게임에서 인간 전문가 수준(75% 이상)의 성능 달성하였습니다. → 범용성 입증
- 기존의 선형 학습 모델보다 압도적인 성능 우위 확인하였습니다.
2) 학습 표현의 시각화 (t-SNE 분석)
DQN이 단순히 픽셀을 외우는 것이 아니라, 게임의 맥락적 의미를 학습했는지 확인하기 위해 고차원 데이터를 2차원으로 투영했습니다.
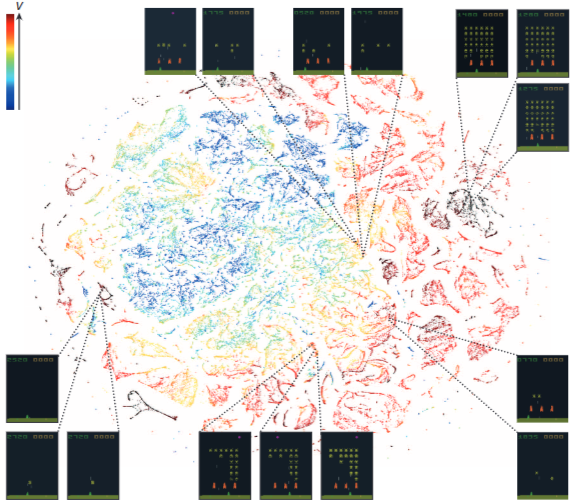
<DQN 에이전트가 학습을 완료하고 게임을 플레이하면서 경험한 상태들을 시각화>
💡-
각각의 점들: 수많은 게임 상태들의 표현을 나타냅니다. 각 점은 하나의 게임 상태를 나타내며 점의 색깔은 해당 상태의 예측된 가치(V)를 나타냅니다.
-
클러스터 및 군집: 비슷한 색상의 점들이 모여 클러스터를 형성하는 것을 볼 수 있습니다. 이는 DQN이 유사한 상태들을 비슷한 방식으로 인식하고 표현한다는 것을 의미합니다.
-
상태 가치 (V)와의 상관관계
- 높은 가치 → 빨간색
- 낮은 가치 → 파란색
분석 결과
- 군집화: 게임 화면의 픽셀 구성은 다르더라도 보상 가치가 비슷한 상태들은 평면상에서 가깝게 모였습니다.
- 의미 파악: 예를 들어 적군이 거의 다 죽어가는 고득점 직전의 상황들을 AI는 서로 비슷한 '중요한 상태'로 분류했습니다.
결론: DQN은 화면을 사진 찍듯 외우는 게 아니라, 어떤 상황이 유리한지 그 '전략적 가치'를 스스로 추상화해서 학습하고 있음을 시각적으로 보여줍니다.
3) 학습의 안정성 확인
학습이 진행됨에 따라 AI가 예측하는 점수(Q-value)와 실제 얻는 점수가 어떻게 변하는지 추적했습니다.
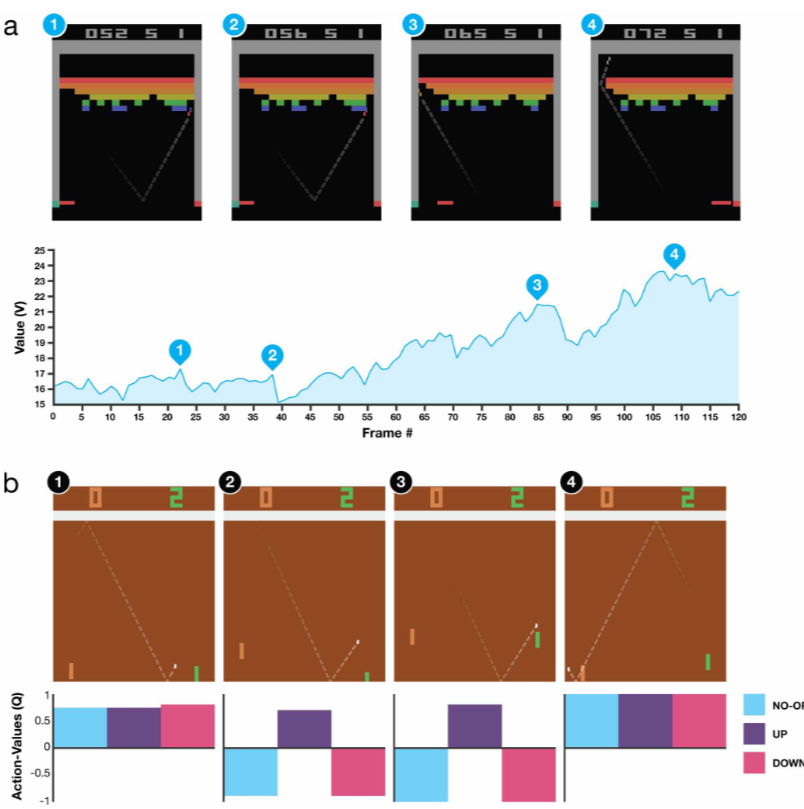
- 안정적인 상승: 시간이 지날수록 평균 점수와 예상 가치가 부드럽게 상승했습니다.
- 불안정성 극복: 앞서 언급한 Experience Replay와 Target Network 덕분에, 학습 데이터가 요동쳐도 AI가 혼란에 빠지지 않고 안정적으로 실력을 쌓아가는 모습을 확인했습니다.
4. 결론
- 최초의 범용 AI: 동일한 모델과 설정값으로 수십 가지의 서로 다른 게임을 마스터한 최초의 에이전트입니다.
- 시각 정보와 행동의 결합: 복잡한 화면 데이터(픽셀)에서 직접 최적의 행동을 도출하는 기술적 진보를 이뤘습니다.
- 생물학적 영감: 뇌의 기억 원리를 본뜬 'Experience Replay'를 도입해 딥러닝과 강화 학습의 결합을 안정시켰습니다.
- 미래 가능성: 머신러닝과 생물학적 메커니즘을 결합하면 인간 수준의 강력한 AI를 구축할 수 있음을 증명했습니다.
"생물학적 기억 원리를 활용해 복잡한 화면을 스스로 학습하고 정복하는 최초의 범용 AI 시대를 열었다.”
