기계학습이란?
Machine Learning은 수학 및 통계를 사용하여 알 수 없는 값을 예측할 수 있는 모델을 만드는 기술이다. 
예를 들어, Adventure Works Cycles는 한 도시에서 자전거를 대여해주는 기업입니다. 이 회사는 충분한 스텝 인원과 자전거 양을 확보하기 위해 이전 데이터를 활용하여 하루 대여 수요를 예측할 수 있는 모델을 학습시켰습니다.
이를 위해 Advaenture Works는 특정 날에 대한 정보(요일, 예상 날씨 상황 등)를 입력값으로 받고 예상되는 대여 수를 출력값으로 하여 예측하는 기계 학습 모델을 만들 수 있었습니다.
수학적으로는 기계 학습을 항목에 대한 하나 이상의 기능(x라고 하겠습니다)에 연산을 수행하여 예측된 레이블(y)을 계산하는 함수(f라고 하겠습니다)를 정의하는 방법이라고 생각할 수 있습니다. 즉 다음과 같습니다.
f(x) = y
이 자전거 대여 예제에서는 지정된 날에 대한 세부 정보(요일, 날씨 등)가 기능(x)이고, 해당 날의 대여 수가 레이블(y)이고, 해당 날에 대한 정보를 기준으로 대여 수를 계산하는 함수(f)가 기계 학습 모델에 캡슐화됩니다.
f함수가 y를 계산하기 위해 x에 대해 수행하는 특정 연산은 만들려는 모델의 유형과 모델을 학습시키는 데 사용되는 특정 알고리즘을 비롯한 다양한 요인에 따라 달라집니다. 또한 대부분의 경우 기계 학습 모델을 학습시키는 데 사용되는 데이터에는 모델 학습을 수행하기 전에 몇 가지 전처리가 필요합니다.
기계학습 유형
기계 학습에는 감독 및 감독되지 않는 기계 학습에 대한 두 가지 일반적인 접근 방식이 있습니다. 두 방법 모두에서 예측을 수행하는 모델을 학습시킵니다.
감독되는 기계 학습(지도학습) 접근 방식을 사용하려면 알려진 레이블 값이 있는 데이터 세트로 시작해야 합니다. 감독되는 기계 학습 작업의 두 가지 유형에는 회귀 및 분류가 포함됩니다.
- 회귀: 가격, 판매 총액 또는 기타 측정값 등의 연속 값(숫자값)을 예측하는 데 사용됩니다.
- 분류: 환자가 당뇨병을 앓고 있는지 여부와 같은 이진 클래스 레이블을 결정하는 데 사용됩니다. (항목이 속한 레이블=범주=클래스를 예측하는 것)
감독되지 않은 기계 학습(비지도학습) 방법은 알려진 레이블 값이 없는 데이터 세트로 시작합니다. 감독되지 않은 기계 학습을 한 유형이 클러스터링입니다.
- 클러스터링: 조류의 측정값을 종으로 그룹화하는 경우처럼 유사한 정보를 레이블 그룹으로 그룹화하여 레이블을 결정하는 데 사용됩니다.
Azure Machine Learning Studio
효과적인 기계 학습 모델을 학습시키고 배포하려면 시간과 리소스가 많이 필요한 많은 작업을 수행해야 한다. Azure Machine Learning은 일부 태스크를 간소화하며, 데이터를 준비하고, 모델을 학습시키고, 예측 서비스를 배포하는 클라우드 기반 서비스이다.
Azure Machine Learning은 학습 모델과 관련된 많은 시간이 소요되는 태스크를 자동화하여 데이터 과학자가 효율성을 높이도록 지원하며, 실제로 사용되는 경우에만 비용을 발생시키면서 대량의 데이터를 효과적으로 처리하도록 확장되는 클라우드 기반 컴퓨팅 리소스를 사용할 수 있도록 한다.
Azure Machine Learning 작업 영역
Azure Machine Learning을 사용하려면 먼저 Azure 구독에서 작업 영역 리소스를 만듭니다. 그런 다음 이 작업 영역을 사용하여 데이터, 컴퓨팅 리소스, 코드, 모델 및 기계 학습 워크로드와 관련된 기타 아티팩트를 관리할 수 있습니다.
Azure Machine Learning 작업 영역을 만든 후 개발자 도구 또는 Azure Machine Learning 스튜디오 웹 포털을 통해 Azure Machine Learning Service를 사용하여 솔루션을 개발할 수 있습니다.
Azure Machine Learning Studio
Azure Machine Learning 스튜디오는 Azure의 기계 학습 솔루션을 위한 웹 포털이다. 여기에는 데이터 전문가들이 데이터 준비, 모델 학습, 예측 서비스 론칭 및 사용량 모니터 등에 필요한 여러 기능과 역량들이 포함되어 있습니다. 웹 포털 사용을 시작하려면 Azure Portal에서 만든 작업 영역을 Azure Machine Learning 스튜디오에 할당해야 한다. 
Azure Machine Learning 컴퓨팅
핵심은 Azure Machine Learning이 기계 학습 모델을 학습시키고 관리하기 위한 서비스이므로 학습 프로세스를 실행하기 위해 컴퓨팅이 필요하다는 사실입니다.
컴퓨팅 대상은 모델 학습 및 데이터 탐색 프로세스를 실행할 수 있는 클라우드 기반 리소스입니다.
Azure Machine Learning 스튜디오에서 데이터 과학 활동에 대한 컴퓨팅 대상을 관리할 수 있습니다. 다음 네 가지 종류의 컴퓨팅 리소스를 만들 수 있습니다.
- 컴퓨팅 인스턴스: 데이터 과학자가 데이터 및 모델을 작업하는 데 사용할 수 있는 개발 워크스테이션입니다.
- 컴퓨팅 클러스터: 실험 코드의 주문형 처리를 지원하는 확장 가능한 가상 머신 클러스터입니다.
- 유추 클러스터: 학습된 모델을 사용하는 예측 서비스의 배포 대상입니다.
- 연결된 컴퓨팅: Virtual Machines 또는 Azure Databricks 클러스터와 같은 기존 Azure 컴퓨팅 리소스에 연결합니다.
Azure 자동화된 Machine Learning이란?
Azure Machine Learning에는 여러 전처리 기술과 모델 학습 알고리즘을 자동으로 병렬 처리하는 ‘자동화된 기계 학습’ 기능이 포함되어 있습니다. 자동화된 기능은 클라우드 컴퓨팅 능력을 사용하여 데이터에 대한 최고 성능의 감독 모드 기계 학습 모델을 찾습니다.
자동화된 기계 학습을 사용하면 방대한 데이터 과학 또는 프로그래밍 지식 없이도 모델을 학습시킬 수 있습니다. 데이터 과학 및 프로그래밍에 대한 배경 지식이 있는 분들에게는 알고리즘 선택 및 하이퍼 매개 변수 튜닝을 자동화하여 시간과 리소스를 절약하는 방법을 제공합니다.
Azure Machine Learning 스튜디오에서 자동화된 기계 학습 작업을 만들 수 있습니다. 
Azure Machine Learning에서 실행할 수 있는 조작을 작업이라고 합니다. 자동화된 기계 학습 실행을 시작하기 전에 작업에 대한 여러 설정을 구성할 수 있습니다. 실행 구성은 학습 스크립트, 컴퓨팅 대상 및 Azure ML 환경을 지정하고 학습 작업을 실행하는 데 필요한 정보를 제공합니다. 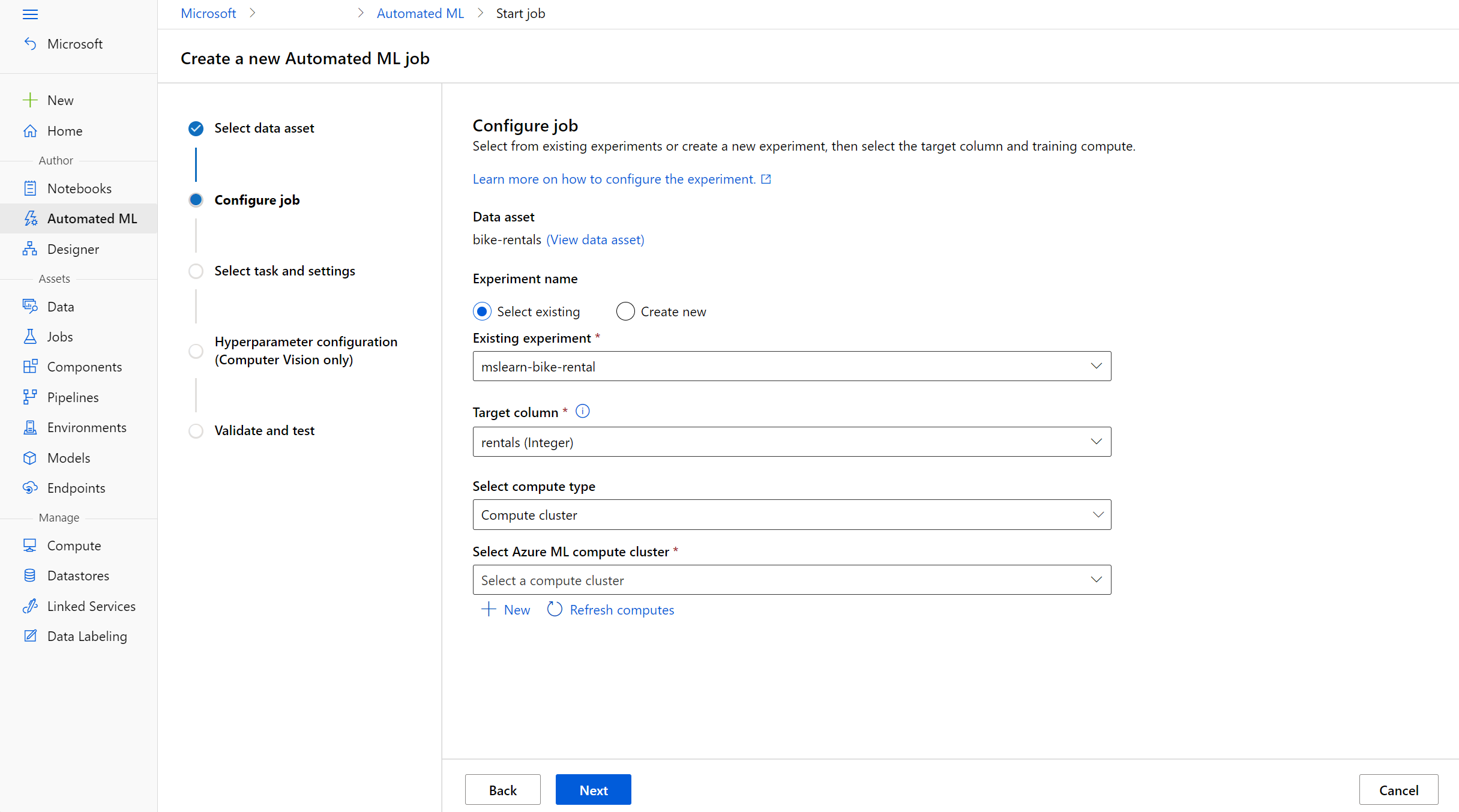
AutoML 프로세스 이해
- 데이터 준비: 데이터 집합의 기능 및 레이블을 식별합니다. 필요에 따라 데이터를 사전 처리 또는 정리 및 변환합니다.
- 모델 학습: 데이터를 학습 및 유효성 검사 집합이라는 두 그룹으로 분할합니다. 학습 데이터 집합을 사용하여 기계 학습 모델을 학습시킵니다. 유효성 검사 데이터 집합을 사용하여 기계 학습 모델에서 성능을 테스트합니다.
- 성능 평가: 모델의 예측이 알려진 레이블과 얼마나 가까운지 비교합니다.
- 예측 서비스 배포: 기계 학습 모델을 학습시킨 후 다른 사용자가 사용할 수 있도록 서버 또는 디바이스에 애플리케이션으로 모델을 배포할 수 있습니다.
이는 Azure Machine Learning을 사용한 자동화된 기계 학습 프로세스와 동일한 단계입니다.
데이터 준비
기계 학습 모델은 기존 데이터로 학습시켜야 합니다. 데이터 전문가들 데이터를 탐색 및 전처리하고, 다양한 유형의 모델 학습 알고리즘을 사용하여 정확한 모델을 생성하는 데 많은 노력을 기울입니다. 이러한 작업은 시간이 많이 걸리며 비용이 많이 드는 컴퓨팅 하드웨어가 비효율적으로 사용되는 경우도 많습니다.
Azure Machine Learning에서 모델 학습 및 기타 작업의 데이터는 주로 데이터 세트라는 개체에 캡슐화됩니다. Azure Machine Learning 스튜디오에서 사용자 고유의 데이터 세트를 만들 수 있습니다. 
모델 학습
Azure Machine Learning의 자동화된 Machine Learning 기능은 지도학습 모델, 즉 학습 데이터가 알려진 레이블 값을 포함하는 모델을 지원합니다.
자동화된 Machine Learning을 사용하여 다음에 대한 모델을 학습시킬 수 있습니다.
- 분류(범주 또는 클래스 예측)
- 회귀(숫자 값 예측)
- 시계열 예측(미래 시점의 숫자 값 예측)
자동화된 Machine Learning에서는 여러 작업 유형 중에서 선택할 수 있습니다. 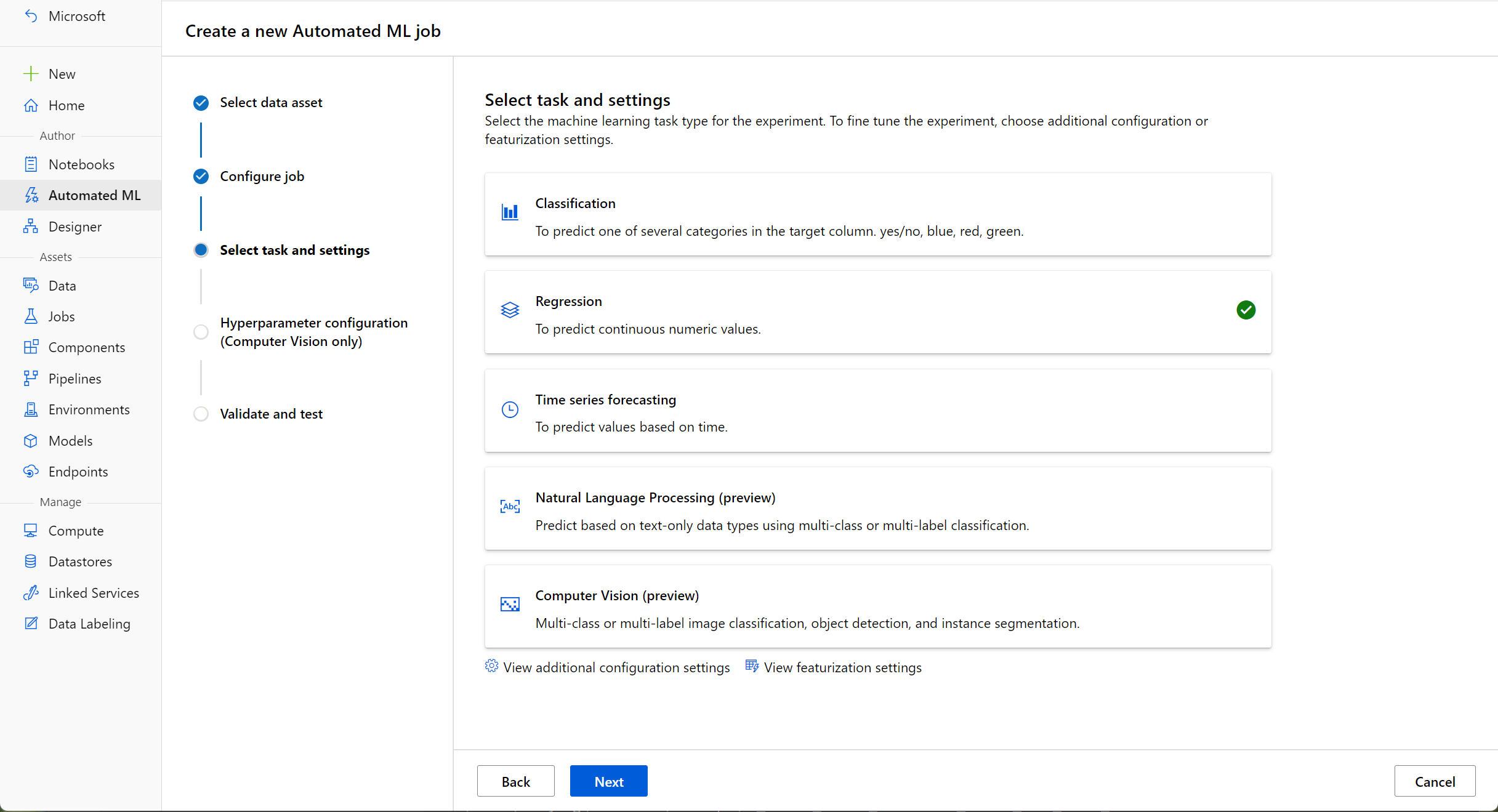
자동화된 Machine Learning에서 기본 메트릭에 대한 구성, 학습에 사용되는 모델 유형, 종료 기준 및 동시성 한도를 선택할 수 있습니다. 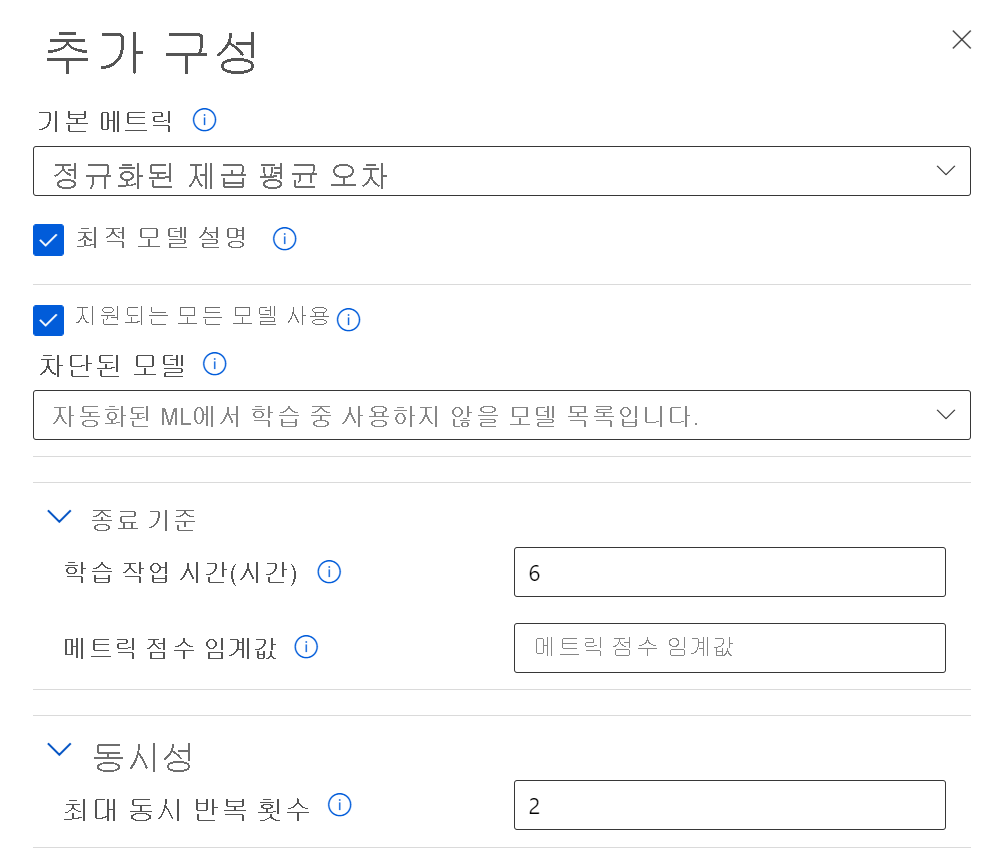
중요한 것은 AutoML이 데이터를 학습 집합 및 유효성 검사 집합으로 분할한다는 점입니다. 작업을 실행하기 전에 설정에서 세부 정보를 구성할 수 있습니다. 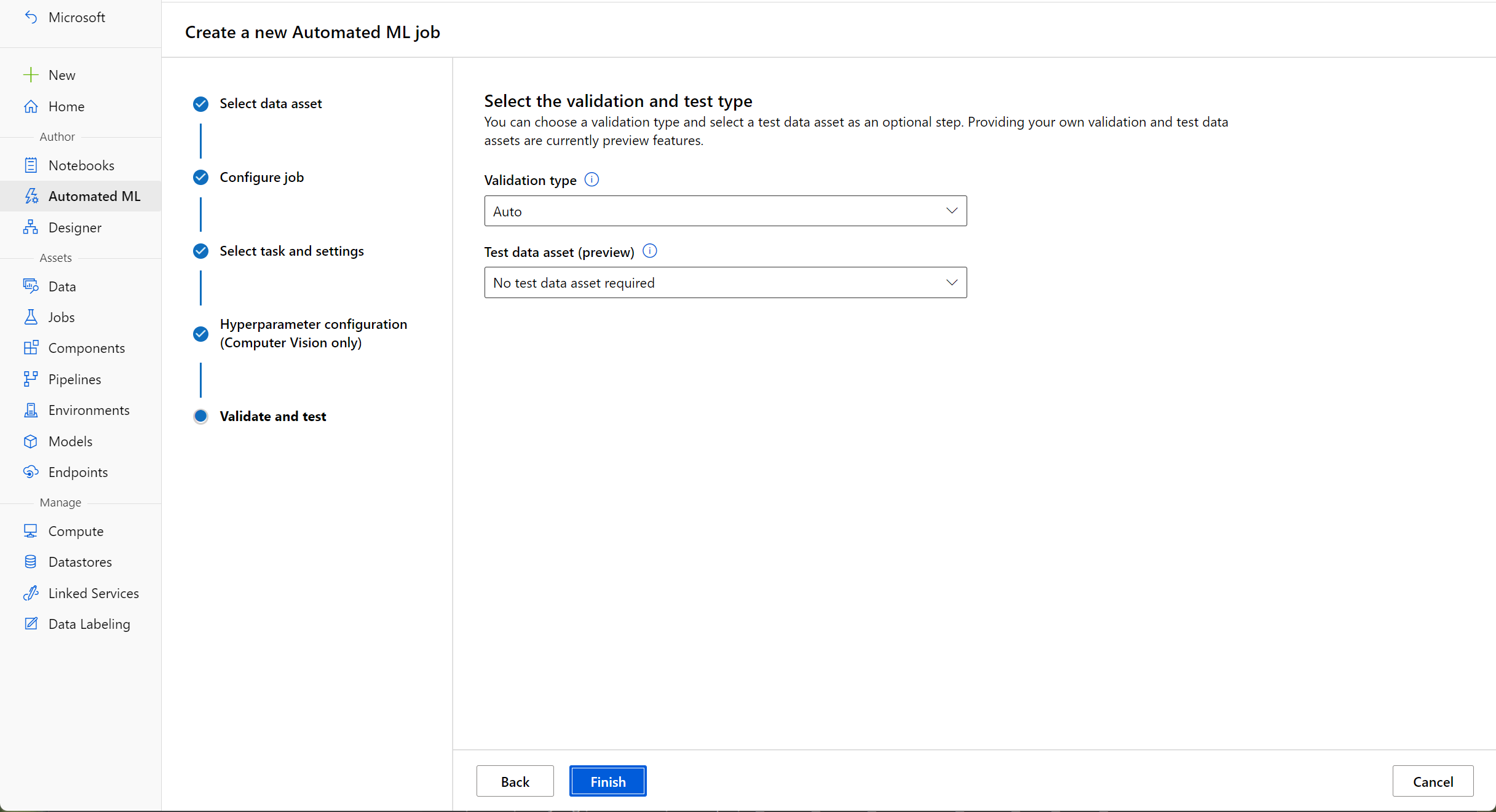
성능 평가
작업이 완료된 후 최고 성능의 모델을 검토할 수 있습니다. 예제에서는 종료 기준을 사용하여 작업을 중지했습니다. 따라서 작업에서 생성된 “최적” 모델은 가능한 최적 모델이 아니라 이 연습에 허용된 시간 내에서 발견된 최적 모델일 수 있습니다.
최적 모델은 지정한 평가 메트릭인 ‘정규화된 평균 제곱 오차’를 기준으로 확인됩니다.
교차 유효성 검사라는 기술이 평가 메트릭을 계산하는 데 사용됩니다. 일부 데이터를 사용하여 모델을 학습시킨 후 나머지 부분을 사용하여 학습된 모델에 대한 반복 테스트 또는 교차 유효성 검사를 수행합니다. 테스트의 예측 값을 알려진 실제 값 또는 레이블과 비교하여 메트릭을 계산합니다.
예측 값과 실제 값의 차이를 ‘오차’ 라고 하며, 모델의 ‘오류’ 양을 나타냅니다. 성능 메트릭 RMSE(정규화된 평균제곱 오차)는 모든 테스트 사례의 오류를 제곱하고 이러한 제곱의 평균을 찾은 다음, 제곱근을 구하여 계산됩니다. 따라서 이 값이 작을수록 모델이 더 정확하게 예측하는 것입니다.
NRMSE(정규화된 평균제곱 오차) 는 RMSE 메트릭을 표준화하므로 척도가 서로 다른 변수가 있는 모델 간 비교에 사용할 수 있습니다.
잔차 히스토그램은 잔차 값 범위의 빈도를 보여 줍니다. 오차는 모델에서 설명할 수 없는 예측 값과 실제 값의 차이, 즉 오류를 나타냅니다. 가장 자주 발생하는 오차 값이 0 주위에 클러스터링되어야 합니다. 오류가 적고, 특히 양 극단의 오류는 거의 없는 것이 좋습니다. 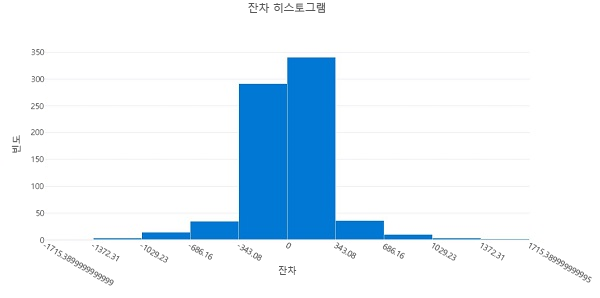
예측 값 및 참 값 차트는 예측 값이 참 값과 밀접하게 상호 연관되는 대각선 추세를 표시합니다. 점선은 완벽한 모델의 성능을 보여 줍니다. 모델의 평균 예측 값 선이 점선에 가까울수록 성능이 더 높은 것입니다. 꺾은선형 차트 아래의 히스토그램은 참 값의 분포를 보여 줍니다. 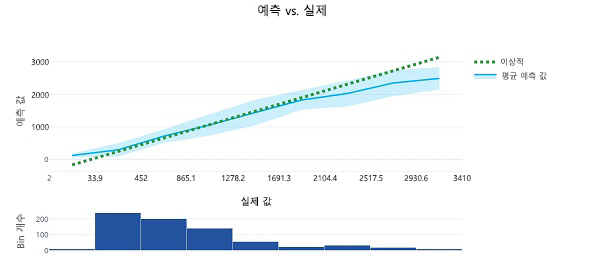
자동화된 기계 학습을 사용하여 일부 모델을 학습시킨 후에는 클라이언트 애플리케이션에서 사용할 수 있는 최상의 모델을 서비스로 배포할 수 있습니다.
예측 서비스 배포
Azure Machine Learning에서 서비스를 ACI(Azure Container Instances) 또는 AKS(Azure Kubernetes Service) 클러스터로 배포할 수 있습니다. 프로덕션 시나리오의 경우 AKS를 배포하는 것이 좋습니다 .이 경우 유추 클러스터 컴퓨팅 대상을 만들어야 합니다. 이 연습에서는 테스트에 적합한 배포 대상인 ACI 서비스를 사용하며, 유추 클러스터를 만들 필요가 없습니다.
