⭐⭐⭐⭐⭐
Quick Sort은 분할정복(divide and conquer)을 통해 주어진 배열을 정렬한다.
※ 분할정복
문제를 2가지 작은 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략
주어진 배열을 피벗(pivot)이라는 기준 요소를 중심으로 두 부분으로 나누고, 각각의 부분배열을 재귀적으로 정렬하여 전체를 정렬하는 알고리즘이다.
GIF로 이해하는 Quick Sort
접근방법
1. 피벗 선택
배열 가운데서 하나의 원소(=피벗;pivot)를 고른다. 보통 첫번째 요소를 피벗으로 고른다.
2. 분할(Divide)
배열을 둘로 나눈다. 이때, 값이 피벗보다 작으면 왼쪽에, 피벗보다 크면 오른쪽에 둔다.
pivot보다 작은 값 | pivot | pivot보다 큰 값
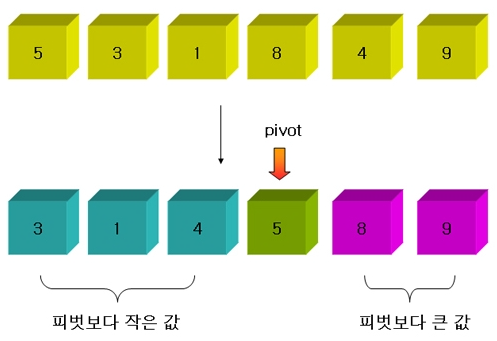
※ 분할을 마친 뒤 pivot은 더 이상 이동 X
3. 재귀적 정렬
분할된 부분배열을 각각 정렬한다. (반복)

- 부분배열의 첫 데이터를 pivot으로 둔다.
l은 왼→오 로 진행하며 피벗보다 크면 정지r은 왼←오 로 진행하며 피벗보다 작으면 정지l와r를 swap- 다시
l은 왼→오 로 진행,r은 왼←오 로 진행하며
4. 합병(Merge)
각 부분배열이 정렬되면, 피벗과 합쳐서 전체배열을 정렬한다.
Java Code
시간복잡도
비교횟수 = 재귀호출의 깊이 * 각 순환 호출 단계의 비교 연산
최선의 경우(Best cases) : T(n) = O(nlog₂n)
- 재귀호출의 깊이: 분할할 때마다 배열이 반으로 나뉘므로
(log₂n) - 각 재귀호출단계의 비교연산: 각 단계마다
(n)번 비교횟수 = n*log₂n이동횟수 = 비교횟수보다 적으므로 무시

평균의 경우(Average cases) : T(n) = O(nlog₂n)
최악의 경우(Worst cases) : T(n) = O(n²)
- 최악 = 이미 정렬된 경우, 매우 불균형하게 분할되는 경우
- 재귀호출의 깊이:
(n) - 각 재귀호출단계의 비교연산: 각 단계마다
(n)번 비교횟수 = n*n = n²이동횟수 = 비교횟수보다 적으므로 무시

공간복잡도
주어진 배열 안에서 교환(swap)을 통해, 정렬이 수행되므로 O(n)이다.
장점
- 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환할 뿐만 아니라, 한 번 결정된 피벗들이 추후 연산에서 제외되는 특성 때문에, 시간 복잡도가 O(nlog₂n)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
- 정렬하고자 하는 배열 안에서 교환하는 방식이므로, 다른 메모리 공간을 필요로 하지 않는다.
단점
- 불안정 정렬(Unstable Sort) 이다.
- 정렬된 배열에 대해서는 Quick Sort의 불균형 분할에 의해 오히려 수행시간이 더 많이 걸린다.
