
- 아래의 자료는 웹 크롤링에 대해 단순히 파이썬 코드로만 데이터 가져오는 내용이 많아서 정해보았습니다.
- 간단하게 설명한다면, 실제 크롤링은 웹상의 다양한 페이지를 방문하고 정보를 가져오는 시스템이라고 볼 수 있습니다.
웹 크롤링이란
- 웹 크롤링이란 웹의 정보를 자동으로 수집하는 것을 의미하여 이런 목적으로 만든 프로그램을 웹 크롤러라고 말한다. 이는 검색엔진의 아주 원시적인 형태라고 할 수 있다.
- 다른 한편으로 어두운 해커들의 세계와 연결되어 있기도 하다. 웹의 정보를 모우는데 웹 크롤링은 아주 매력적인 방법이지만, 한편으로는 위험하다.(참고 링크)
크롤링의 목적
- 새로운 정보가 끊임없이 생기고 있으며, 구글 같은 회사가 하는 일 중 하나가 새로 생기는 정보를 구글 검색에 바로 걸리게 하는 것이다. 이때 전세계에서 끊임없이 생산되는 정보를 모우기 위해 필요한 일이 바로 웹 크롤링이다.
- 여기서 중요한 부분이 단순히 웹 크롤링이 필요한 데이터 수집이 아닙니다. 위에서 언급한 부분처럼 정보 검색(Information Retreival)과 연관이 있다. (간단하게 보면 검색이라고 볼 수 표현 가능)
참고) 구글이 설명하는 검색의 원리(출처)
구글은 ‘구글봇’이라고 하는 일련의 컴퓨터 프로그램이 있습니다. 구글봇은 매일 끊임없이 웹상에 존재하는 수십만 개의 페이지를 ‘방문’합니다. 이 과정을 ‘크롤링(crawling)’이라고 하는데 모두 정교한 알고리듬으로 짜여 있습니다. 다시 말해 어떤 사이트를 크롤할 지, 얼마나 자주 할지 또 각 사이트에서 얼마나 많은 페이지를 방문할 것인가에 대한 프로그램이 짜여 있습니다.
웹 크롤러 아키텍쳐 및 원리
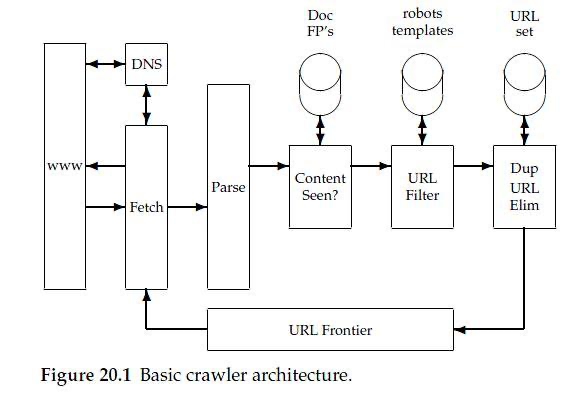
- Frontier: 탐색할 URL을 Fetcher 에게 전송
- Fetcher: URL의 HTML 내용을 Parser에게 전달
- Parser: HTML에서 a, url 태그의 다른 하이퍼링크를 탐색
- Content Seen: 방문한 페이지의 내용을 이전 내용으로 판단
- URL Filter: 해당 HTML 페이지에서 a, url 태그 등의 URL을 분류
- Dup URL Elim: 방문한 페이지를 다시 방문하지 않도록, 중복된 URL을 제거하여 Frontier 전달
위와 같은 과정들을 반복하며 웹 페이지를 방문
대부분 블로그의 웹 크롤링
- 아마 블로그에 존재하는 파이썬으로 된 코드들은 크롤링이 아닌 스크래핑이라고 볼 수 있다.
- 이미 크롤링이라는 단어가 책이나 블로그에 데이터를 수집하는 용어로 굳혀진 것처럼 보인다.

데이터 분석하고 있습니다