
레디스 자료 구조
string
레디스에서 데이터를 저장할 수 있는 가장 간단한 구조이다.
-
최대 512MB의 문자열 데이터를 저장할 수 있다.
-
JPEG 이미지와 같은 바이트 값, HTTP 응답값 등의 다양한 데이터를 저장하는 것도 가능하다.
-
데이터가 1:1로 저장되는 유일한 자료구조이다.
-
이미 키 값에 저장된 데이터가 존재할 경우, 해당 키에 새로운 데이터를 SET 할 경우 데이터가 새로 입력된 값으로 대체된다.
-
INCR, INCRBY와 같은 커맨드를 이용하면 저장된 데이터를 원자적으로 조작할 수 있다.
커맨드가 원자적이라는 것은 같은 키에 접근하는 여러 클라이언트가 경쟁 상태(race condition)를 발생시킬 일이 없음을 의미한다.
-
INCR
저장된 데이터를 1씩 증가시킬 수 있으며, 증가된 값이 반환된다. -
INCRBY
입력한 값만큼 데이터를 증가시키며, 증가된 값이 반환된다. -
DECR
저장된 데이터를 1씩 감소시킬 수 있으며, 감소된 값이 반환된다. -
DECRBY
입력한 값만큼 데이터를 감소시키며, 감소된 값이 반환된다. -
MSET
"Multiple SET"의 줄임말로, 여러 키-값 쌍을 한 번에 설정하는 명령어이다. 여러 키-값 쌍을 설정하는 과정이 하나의 명령어로 처리되기 때문에, 중간에 다른 클라이언트가 개입하거나 키의 값이 변경되지 않는다. 즉, 모든 키-값이 한꺼번에 설정되며, 일부만 설정되는 일이 없다. -
MGET
"Multiple GET"의 줄임말로, 여러 키의 값을 동시에 읽어오는 명령어이다. 이를 실행하는 동안 다른 클라이언트가 데이터를 변경하더라도 읽기 시점의 값을 반환한다.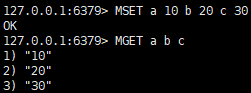
cf. 대규모 시스템에서는 MSET과 MGET과 같은 커맨드를 적절하게 사용해 네트워크 통신을 줄여 전반적으로 서비스의 응답 속도를 크게 향상시킬 수 있다.
-
list
 출처:
출처: -
순서를 가지는 문자열의 목록이다.
-
하나의 list에는 최대 42억여 개의 아이템을 저장할 수 있다.
-
서비스에서 스택과 큐로 활용된다.
기본 데이터 조작 커맨드
-
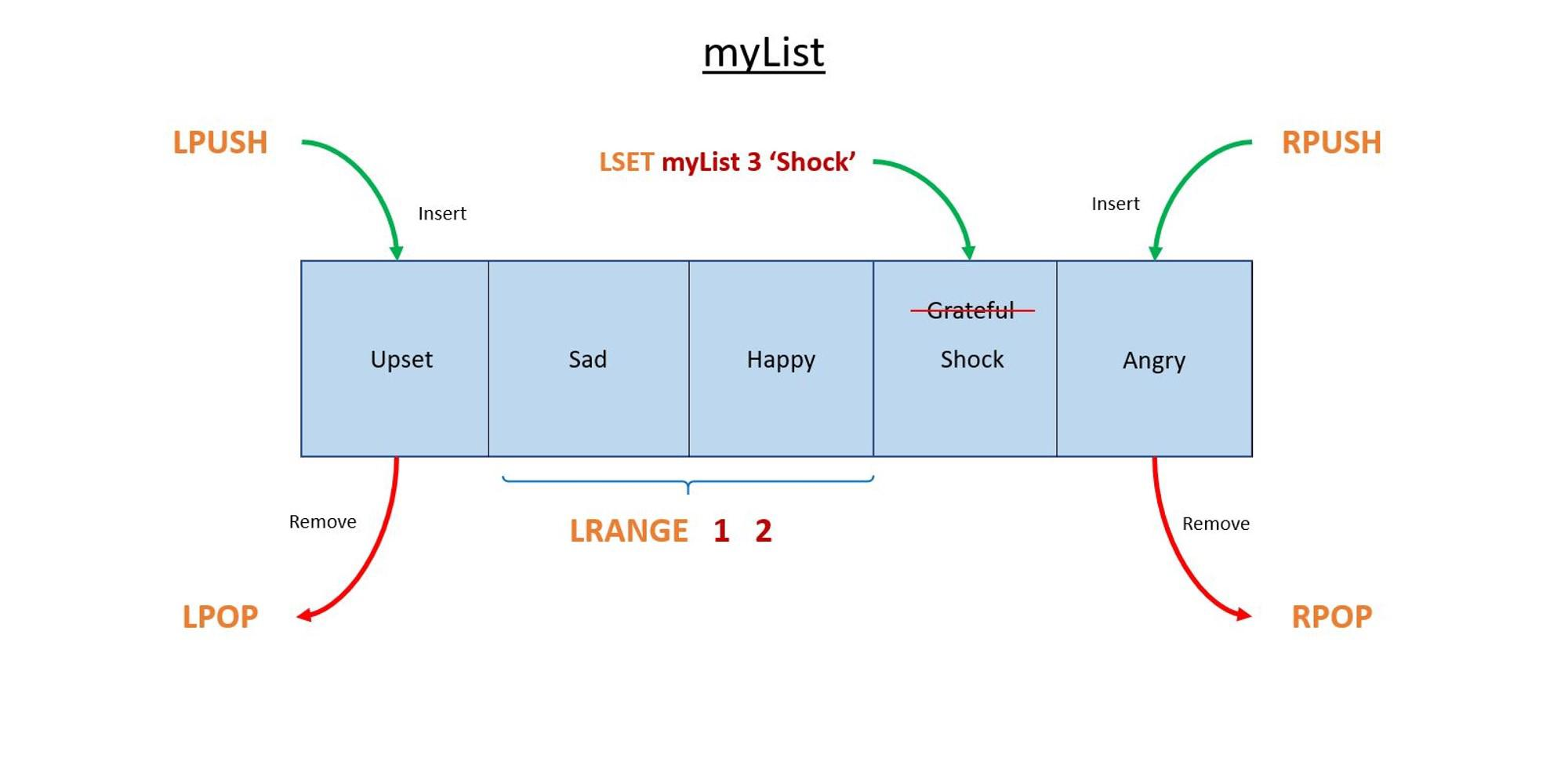
LPUSH key value [value ...]
리스트의 왼쪽(앞쪽)에 하나 이상의 값을 추가한다.LPUSH mylist "A" "B" "C"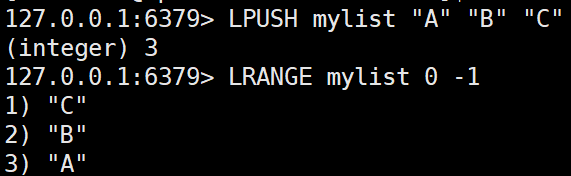
-
RPUSH key value [value ...]
리스트의 오른쪽(끝쪽)에 하나 이상의 값을 추가한다.RPUSH mylist "D" "E"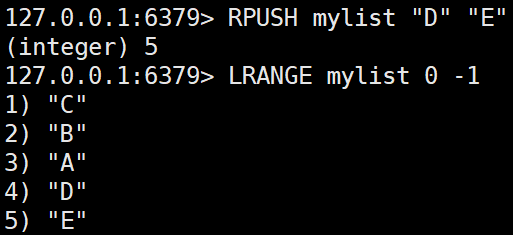
-
LPOP key
리스트의 왼쪽(앞쪽)에서 값을 꺼내고 제거한다.LPOP mylist LPOP mylist 2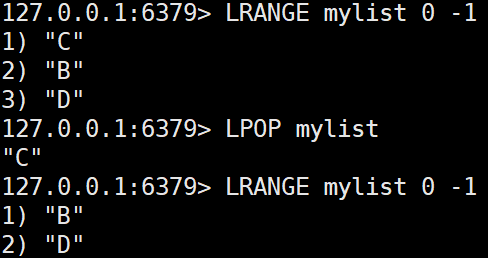
-
RPOP key
리스트의 오른쪽(끝쪽)에서 값을 꺼내고 제거한다.RPOP mylist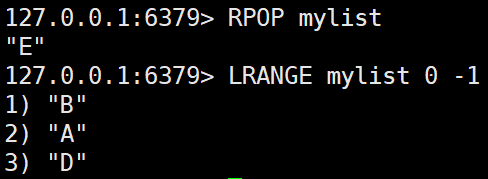
데이터 조회 관련 커맨드
-
LRANGE key start stop
리스트의 지정된 범위 내 값을 반환한다.LRANGE mylist 0 -1 # 전체 데이터 출력, 맨 오른쪽에 있는 아이템의 인덱스가 -1이다, 그 앞의 인덱스는 -2이다.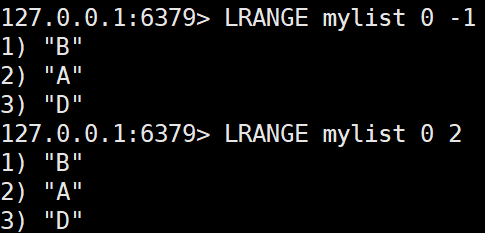
-
LLEN key
리스트의 길이(요소 개수)를 반환한다.LLEN mylist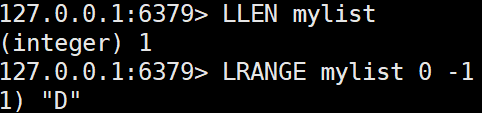
-
LINDEX key index
리스트에서 특정 인덱스의 값을 반환한다.LINDEX mylist 1
데이터 수정 관련 커맨드
-
LSET key index value
리스트의 특정 인덱스에 있는 값을 수정한다.LSET mylist 1 "Z"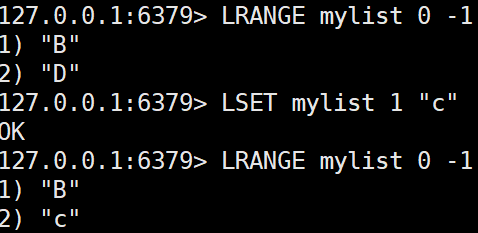
-
LINSERT key BEFORE|AFTER pivot value
지정된 값을 기준으로 앞(BEFORE) 또는 뒤(AFTER)에 새 값을 삽입한다.LINSERT mylist AFTER "B" "X"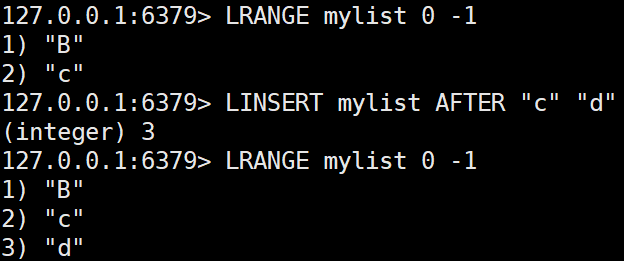
데이터 삭제 관련 커맨드
-
LREM key count value
리스트에서 특정 값을 찾아 count만큼 제거한다.-
count > 0: 왼쪽부터 검색해 제거.
-
count < 0: 오른쪽부터 검색해 제거.
-
count = 0: 모든 값을 제거.
LREM mylist 1 "c"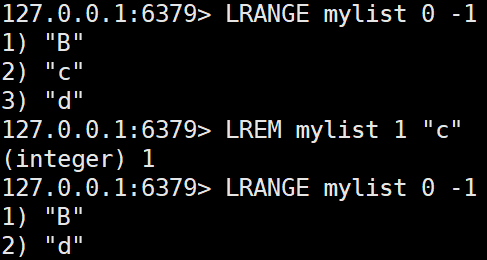
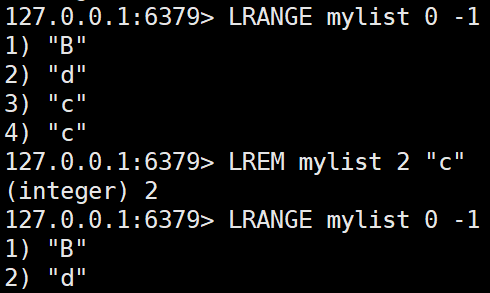
-
-
LTRIM key start stop
지정된 범위만 남기고 나머지 요소를 제거한다.LTRIM mylist 1 -1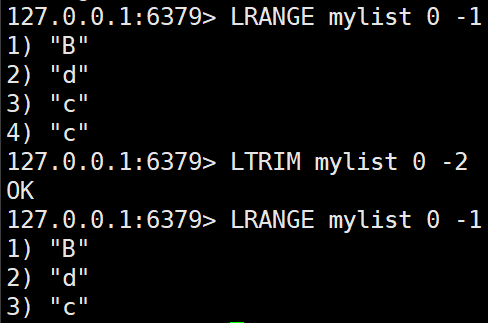
cf. 리스트의 양 끝에 데이터를 넣고 빼는 LPUSH, RPUSH, LPOP, RPOP 커맨드는 O(1)로 처리할 수 있어 매우 빠른 실행이 가능하지만, 인덱스나 데이털르 이용해 list의 중간 데이터에 접근할 때는 O(n)으로 처리되며, list에 저장된 데이터가 늘어남에 따라 성능이 저하된다.
hash
출처: https://medium.com/@danilosilva_37526/using-redis-hash-to-deal-with-collections-569449ac0384
-
하나의 키 아래에 여러 필드-값(Field-Value) 쌍을 저장할 수 있는 데이터 구조다.
-
필드는 하나의 해시 내에서 유일하며, 필드와 값 모두 문자열 데이터로 저장된다.
-
한 키 아래 여러 필드를 저장하므로, 개별 키를 사용하는 것보다 메모리 효율적이다.
-
필드의 값은 문자열로 저장되지만, 정수나 실수 연산도 가능하다.
-
O(1)의 시간 복잡도로 필드에 접근이 가능하다.
-
관계형 데이터베이스의 Row처럼 작고 구조화된 데이터를 관리할 수 있다.
-
객체를 표현하기 적절한 자료 구조이기 때문에 관계형 데이터베이스의 테이블 데이터로 변환하는 것도 간편하다.
-
각 아이템마다 다른 필드를 가질 수 있으며, 동적으로 다양한 필드를 추가할 수 있다는 특징이 존재한다.
cf. 같은 객체 데이터를 저장하더라도 서비스의 특성에 따라 최적의 데이터 저장소를 선택해야한다.
-
데이터 삽입 및 수정 커맨드
-
HSET key field value
필드에 값을 설정하거나 수정한다.HSET user:1 name "Alice" age "25"
데이터 조회
-
HGET key field
특정 필드 값을 조회한다.HGET user:1 name
-
HGETALL key
모든 필드와 값을 조회한다.HGETALL user:1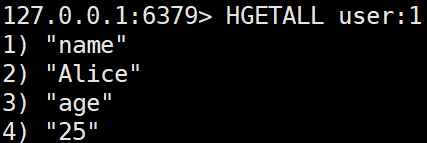
-
HMGET key field1 field2 ...
여러 필드의 값을 조회한다.HMGET user:1 name age
데이터 삭제 및 확인
- HDEL key field
특정 필드를 삭제한다.HDEL user:1 age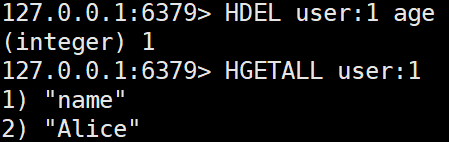
- HEXISTS key field
필드 존재 여부를 확인한다.(1: 존재, 0: 존재 x)HEXISTS user:1 city
필드 목록 및 값 조회
- HKEYS key
모든 필드 이름을 반환한다.HKEYS user:1
-
HVALS key
모든 값을 반환한다.HVALS user:1
기타
- HLEN key
해시 필드 개수를 반환한다.HLEN user:1
- HINCRBY key field increment
정수 필드 값을 증가시킨다. (기존 값이 정수가 아니면 오류 발생)HINCRBY user:1 age 5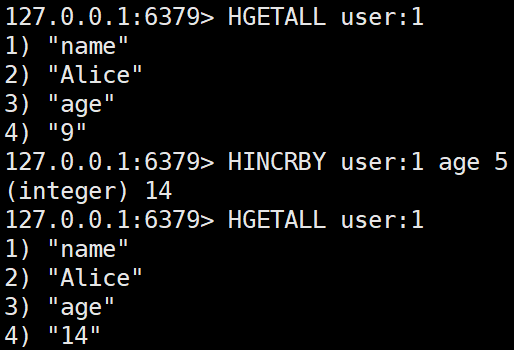
- HINCRBYFLOAT key field increment
실수 필드 값을 증가시킨다. (기존 값이 정수여도 오류 발생 x, 기존 값이 문자형이면 새로운 name 필드가 생성되고 값이 10.5로 설정된다.)HINCRBYFLOAT user:1 age 10.5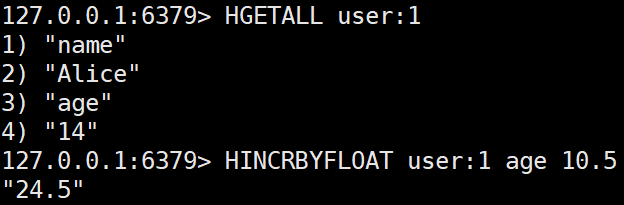
SET
 출처:
출처: -
정렬되지 않은 문자열의 모음이다.
-
저장되는 값들은 중복이 허용되지 않는다.
-
교집합, 합집합, 차집합 등의 집합 연산과 관련한 커맨드를 제공한다.
-
객체 간의 관계를 계산하거나 유일한 원소를 구해야 하는 경우 유용하다.
-
활용 예시
-
태그 관리
SADD tags "Redis" "Database" "NoSQL"
-
팔로우/팔로워 관리
SADD user:1001:followers 1002 1003 1004 SADD user:1002:following 1001
-
추천 시스템
사용자 간의 공통 관심사를 교집합으로 계산.
-
요소 추가 및 삭제 커맨드
- SADD key member [member ...]
집합에 하나이상의 요소를 추가한다.SADD myset A B C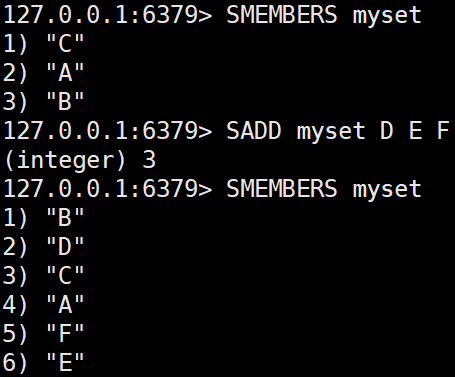
- SREM key member [member ...]
집합에서 하나 이상의 요소를 제거한다.SREM myset B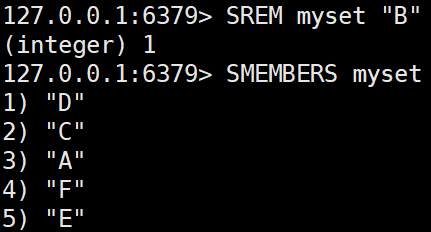
요소 조회
- SMEMBERS key
집합의 모든 요소를 반환한다.SMEMBERS myset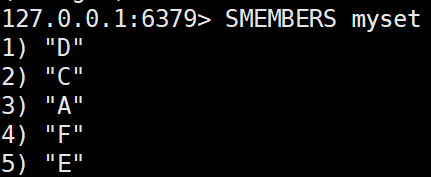
- SISMEMBER key member
특정 요소가 집합에 포함되어 있는지 확인한다.SISMEMBER myset A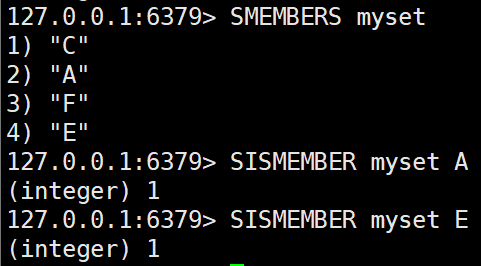
- SCARD key
집합의 요소 개수를 반환한다.SCARD myset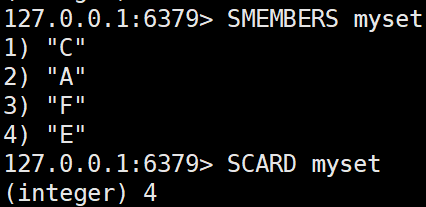
집합 연산
-
SUNION key [key ...]
여러 집합의 합집합을 반환한다.SADD set1 "A" "B" SADD set2 "B" "C" SUNION set1 set2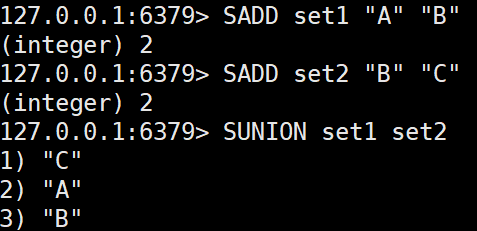
cf. SADD set1 A B와 같이 ""를 붙이지 않으면 에러가 발생한다.
- SINTER key [key ...]
여러 집합의 교집합을 반환한다.SINTER set1 set2
- SDIFF key [key ...]
첫 번째 집합에서 나머지 집합과의 차집합을 반환한다.SDIFF set1 set2
무작위 요소
- SRANDMEMBER key [count]
집합에서 무작위로 하나 또는 여러 요소를 반환한다.SRANDMEMBER myset
- SPOP key [count]
집합에서 무작위로 하나 또는 여러 요소를 꺼내고 제거한다.SPOP myset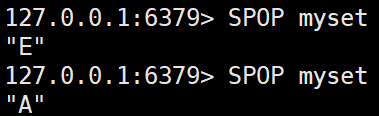
sorted Set
 출처:
출처: -
중복되지 않는 값에 대해 점수(Score)를 부여하여 값을 정렬할 수 있는 데이터 구조다.
-
일반 Set과 달리 값이 점수에 의해 정렬되며, 특정 순서대로 데이터를 저장하고 조회할 수 있다.
-
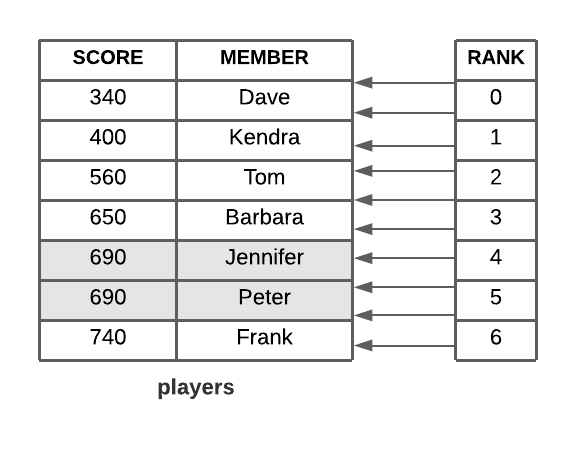
각 값은 점수(Score)에 따라 오름차순으로 자동 정렬된다.
-
같은 스코어를 가진 아이템은 데이터의 사전 순으로 정렬돼 저장된다.
-
점수 또는 인덱스 범위를 기반으로 효율적인 검색이 가능하다.
cf. 인덱스를 이용해 아이템에 접근할 일이 많다면 list가 아닌 sorted Set을 사용하는 것이 더 효율적이다.
cf. lsit -> O(n), sorted set -> O(log(n))
-
활용 예시
-
리더보드 관리
사용자 점수를 관리할 때 유용하다.ZADD leaderboard 100 "Alice" 200 "Bob" 150 "Charlie" ZRANGE leaderboard 0 -1 WITHSCORES
-
시간 기반 데이터 관리
타임스탬프를 점수로 사용하여 정렬된 데이터를 관리한다.ZADD events 1610000000 "Event1" 1610001000 "Event2"
-
우선순위 큐
작업의 우선순위를 점수로 설정한다.ZADD tasks 1 "Task1" 2 "Task2"
-
요소 추가 및 업데이트
-
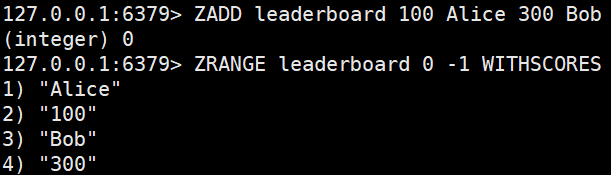
ZADD key [NX|XX][CH] [INCR] score member [score member ...]
집합에 값(멤버)과 점수를 추가하거나, 기존 멤버의 점수를 업데이트한다. 여러 아이템을 입력할 수 있으며 각 아이템은 sorted set에 저장되는 동시에 스코어 값으로 정렬된다.ZADD leaderboard 100 Alice 200 Bob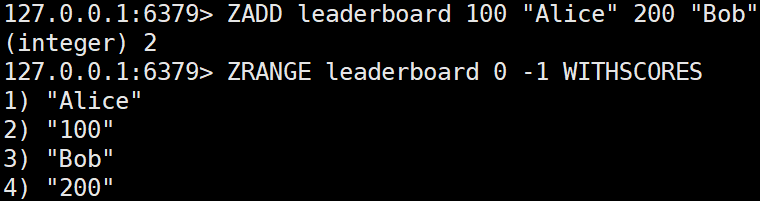
-
주요 옵션
-
NX: 멤버가 존재하지 않을 때만 추가한다.
-
XX: 멤버가 존재할 때만 업데이트한다.
-
LT: 업데이트 스코어가 기존 아이템의 스코어보다 작을 때에만 업데이트한다. 기존 아이템이 존재하지 않을 떄에는 새로운 데이터를 삽입한다.
-
GT: 업데이트 스코어가 기존 아이템의 스코어보다 클 때만 업데이트한다. 기존 아이템이 존재하지 않을 떄에는 새로운 데이터를 삽입한다.
-
-
요소 조회
-
ZRANGE key start stop [WITHSCORES] [REV]
인덱스 범위 내의 멤버를 오름차순으로 반환한다. WITHSCORES 옵션 사용 시 점수와 함께 표시된다. REV 옵션 사용 시 역순으로 데이터를 출력할 수 있다.ZRANGE leaderboard 0 -1 WITHSCORES
-
ZRANK key member
특정 멤버의 순위(인덱스)를 오름차순으로 반환한다.ZRANK leaderboard Alice
-
ZSCORE key member
특정 멤버의 점수를 반환한다.ZSCORE leaderboard Alice
범위 검색
-
ZRANGEBYSCORE key min max [WITHSCORES]
점수 범위 내 멤버를 오름차순으로 반환한다. WITHSCORES 옵션 사용 시 점수와 함께 표기 된다.ZRANGEBYSCORE leaderboard 50 150 WITHSCORES
-
ZCOUNT key min max
점수 범위 내 멤버 수를 반환한다.ZCOUNT leaderboard 50 200
-
ZRANGE key min max BYLEX
ZRANGE key min max BYLEX 명령어를 사용하면 점수 대신 사전적 순서를 기준으로 범위를 지정하여 데이터를 조회할 수 있다.-
min과 max는 사전적 범위를 지정하는 문자열이다.
-
[는 범위에 해당 값을 포함.
-
(는 범위에 해당 값을 포함하지 않음.
-
-는 가장 첫 번째 문자열.
-
+는 가장 마지막 문자열.
-
ZADD mySortedSet 0 apple 0 banana 0 candy 0 dream 0 egg 0 frog # 데이터 저장 ZRANGE mySortedSet [b (f BYLEX # 사전 순으로 데이터 조회.-
[b: b로 시작하거나 b 이후의 값 포함.
-
(f: f 이전의 값(단, f는 제외).
-
결과: banana, candy, dream, egg.
-
요소 삭제
-
ZREM key member [member ...]
특정 멤버를 삭제한다.ZREM leaderboard Alice
-
ZREMRANGEBYSCORE key min max
특정 점수 범위의 멤버를 삭제.ZREMRANGEBYSCORE leaderboard 0 150
점수 증가
-
ZINCRBY key increment member
특정 멤버의 점수를 증가.ZINCRBY leaderboard 50 Bob
비트맵
