FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders (ICLR 2021)
개요
- 목적 : 사전 학습된 문장 인코더(pretrained sentence encoder)에 내재된 사회적 편항(social bias)제거
- 특징 : 기존 편향제거 방법들은 주로 단어 수준에서 이루어졌다는 점에 주목하여 문장 수준에서 편향제거 방법인 FairFil(Fair Filter)제안
주목할만한 점
- 문장 임베딩에 존재하는 편향 제거 위해 새로운 신경망 구조와 학습전략 제안
- 대조학습이라는 새로운 패러다임을 활용하여 편향 제거와 의미 보존 동시 달성
학습 과정
1) 데이터 증강(Data Augmentation)
원본 문장에 대해, 편향된 속성어 이를테면 (he, she) ⇢ (she, he) 처럼 다른 방향의 단어로 치환한 문장을 생성한다. 이로써 의미는 유지하되 편향 방향이 다른 문장 쌍을 만든다.

2) 대조학습(Contrastive Learning)
원본 문장 임베딩과 증강 문장 임베딩 간 상호정보량(mutual information)을 최대화하도록 FairFil을 학습시킨다. 이 작업은 InfoNCE 손실함수를 사용하여 두 임베딩이 공유하는 의미 정보를 보존하면서도 편향 정보는 제거하려는 목적으로 진행한다.
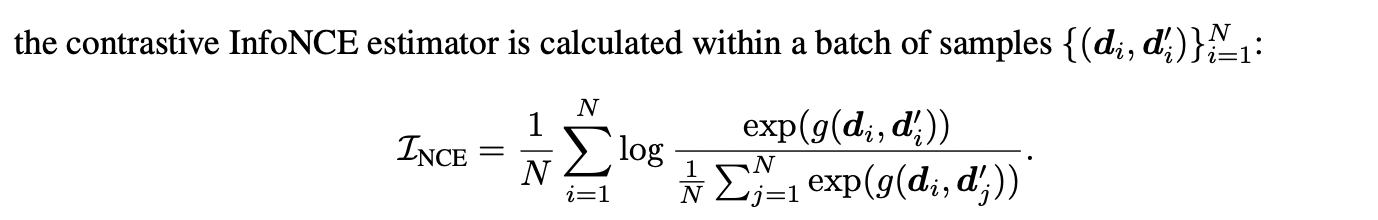
3) 편향 정보 제거(Debiasing Regularizer)
FairFil의 출력 임베딩과 편향 속성어 임베딩 간 상호정보량을 최소화하는 정규화 항을 추가한다. CLUB 손실 함수를 사용하여 출력 임베딩에서 편향 단어 정보를 최대환 제거하기 위해 진행한다.
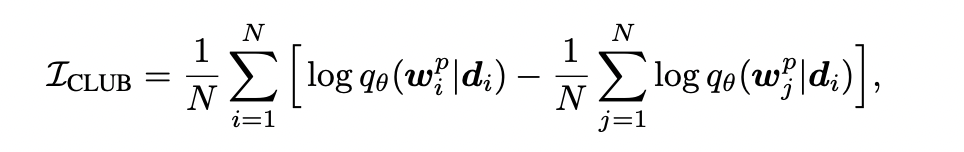
조건부 확률 p(w|d)에 대한 변분근사 qθ(w|d), θ: 모델 파라미터, qθ(w|d): 모델을 통해 학습되는 함수
이 모든 과정을 Multi-view contrastive learning framework 로 칭하며
-
기존 문장 x 의 의미는 보존하지만 다른 잠재적 편향 방향성을 갖는 새로운 문장 x'을 만든다.
-
InfoNCE를 손실 함수로 사용하여 기존 문장 임베딩 z=f(x)와 새로운 문장 임베딩 z'=f(x') 간 MI를 최대화한다.
-
편향 제거 정규화(Debiasing regularizer)를 이용하여 필터링된 임베딩 d와 문장 x 안의 민감한 속성을 지닌 단어 간의 MI를 최소화한다.
실험 결과 FairFil은 기존 방법(Sent-Debias)에 비해 편향 정도를 더 크게 감소시켰고, 하위작업(downstream task)에서 성능 하락폭도 더 작았다. 특히 적은 학습 데이터로도 우수한 결과를 보여, 데이터 효율성 측면에서 강점을 보였다.
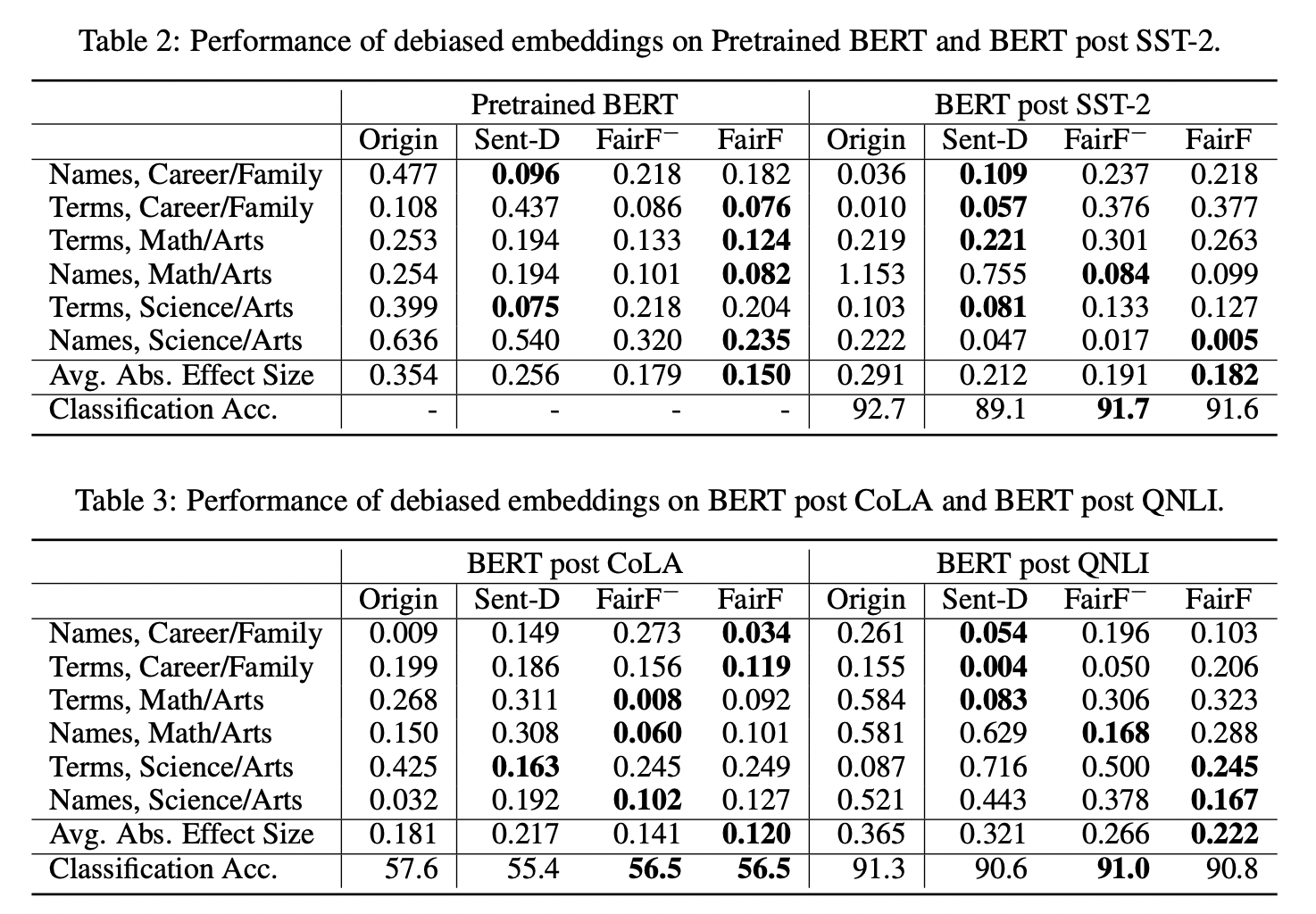
Table2. 하위과제(Downsteam Tasks)에서 성능
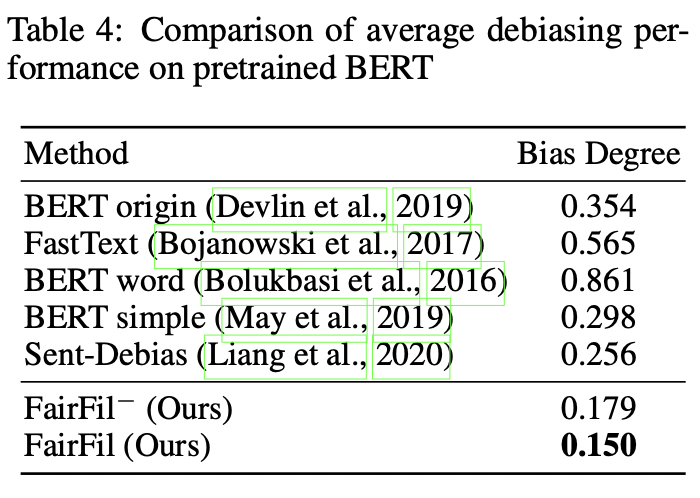
Table4. 문장 임베딩의 사회적 편향 측정
결론
- 사전학습 모델 재학습시킬 필요 없이 사후 적용 가능하여 실용성 높다(사후검정 방식, posthoc)
- 즉, 편향 속성어에 대한 정보만 있다면 원하는 사전학습 모델에 바로 적용 가능하다
