1. 파이썬에서 API 사용하여 데이터 가져오기
1-1. 가상 환경 설정
1-2. PIP로 가상 환경에 request 패키지 설치하기
PIP
패키지를 설치할 때는 PIP(Package Installer for Python)를 사용
여러 패키지를 설치할 수 있게 도와주는 프로그램
requests 패키지 .venv 가상환경에 설치하기
pip install requests
requests 라이브러리를 사용하면 지정된 URL의 HTML 콘텐츠를 요청할 수 있다.
1-3. requests 라이브러리 사용해 데이터 가져오기
import 패키지명
# requests 라이브러리 설치 후, import로 가져오기
import requests
# requests.get("api주소") 로 데이터 response 가져오기
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
# response를 json()형태로 가져오기
rjson = r.json()
# 터미널에 출력해보자
print(rjson)
# 터미널에 찍힌 걸 보니 이렇게 들어가면 될 듯
rowsList = rjson["RealtimeCityAir"]["row"]
# 로우list에 각 요소인 row를 순회하며 반복 실행하여 데이터 가져오기
for row in rowsList:
name = row["MSRSTE_NM"]
figure = row["IDEX_MVL"]
print(name, figure)2. 파이썬으로 웹 스크랩핑하기
2-1. 웹 스크랩핑이란?
파이썬 웹 스크래핑은 인터넷에서 정보를 가져오는 작업으로, 예를 들어 웹사이트에서 날씨 정보를 가져오는 프로그램을 만든다고 생각해보자.
1. 웹사이트에 접속하여 웹 페이지의 내용을 가져온다.
2. 가져온 내용에서 원하는 정보(예: 날씨)를 찾는다.
3. 찾아낸 정보를 사용하여 프로그램에서 활용한다.
파이썬을 사용하면 다양한 웹사이트에서 정보를 가져와 유용한 프로그램을 만들 수 있다.
즉, API가 없더라도 내가 원하는 페이지의 데이터를 가져올 수 있다.
2-2. (예제) 네이버 날씨 스크래핑 하기
2-2-1. VSC에서 터미널을 열어 가상환경을 활성화한다.
2-2-2. 데이터를 가져올 수 있는 도구 설치
pip install requests bs4웹 페이지 요청
requests 라이브러리를 사용하여 웹 페이지의 HTML 콘텐츠를 요청한다.HTML 파싱
BeautifulSoup(bs4)을 사용하여 HTML을 파싱하고, 원하는 데이터를 추출한다.
2-2-3. 웹 스크래핑 기본 세팅
import requests
from bs4 import BeautifulSoup
# ✅ 웹 페이지 요청
URL = "스크랩할 주소" # ✅ 스크래핑할 웹 페이지의 URL을 입력
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
response = requests.get(URL, headers=headers) // ✅ 응답 data 겟하기
# 요청이 성공적이었는지 확인
if response.status_code == 200:
# ✅ HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 🔥 수행할 로직 작성...
# 예시: 모든 <a> 태그의 텍스트 추출
for link in soup.find_all('a'):
print(link.text)
# 특정 클래스를 가진 요소 추출
specific_element = soup.find_all(class_='특정클래스이름') # 예시: 특정 클래스 이름을 가진 모든 요소 찾기
for element in specific_element:
print(element.text)
else:
print(f"Failed to retrieve the webpage, status code: {response.status_code}")2-2-4. 네이버 날씨 스크래핑하기
https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=날씨
import requests
from bs4 import BeautifulSoup
# 웹 페이지 요청
URL = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=날씨"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# ✅ requests 라이브러리 => 지정된 URL의 HTML 콘텐츠 요청
data = requests.get(URL, headers=headers)
# ✅ BeautifulSoup 라이브러리 => HTML 파싱
soup = BeautifulSoup(data.text, 'html.parser')
# 터미널에 HTML 파싱한 결과 찍어보기
print(soup)- 터미널에 HTML 파싱한 결과 찍어보기
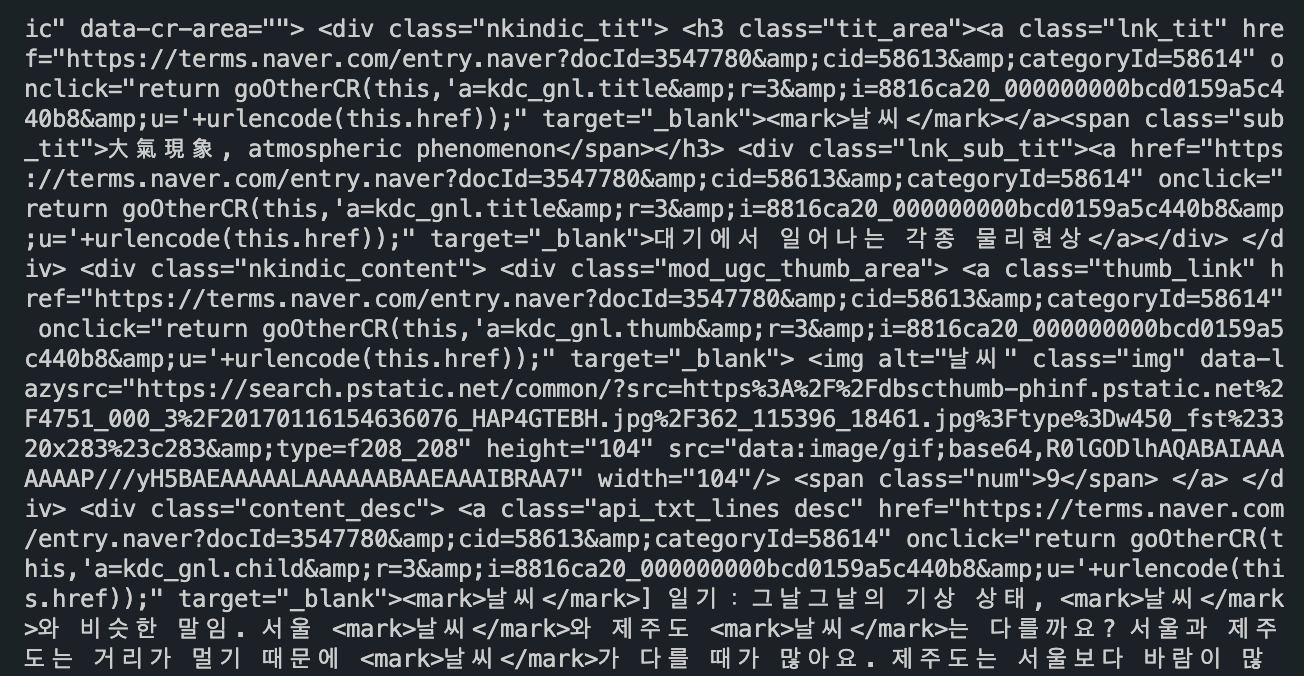
여기서 필요한 정보만 가져오는 걸
크롤링이라고 한다.
3. 스크래핑 후 필요한 정보만 크롤링하기
html 전체를 담은 soup 정보에서 하나씩 꺼내서 가져와 보자.
1. 스크래핑 한 웹 페이지를 열고 개발자 도구를 보면서 진행하면 된다.
2. 원하는 정보를 찾았다면, 해당 태그를 잘 살펴보자.
온도 데이터를 가져가고 싶다면 이 태그의 속성을 보자.
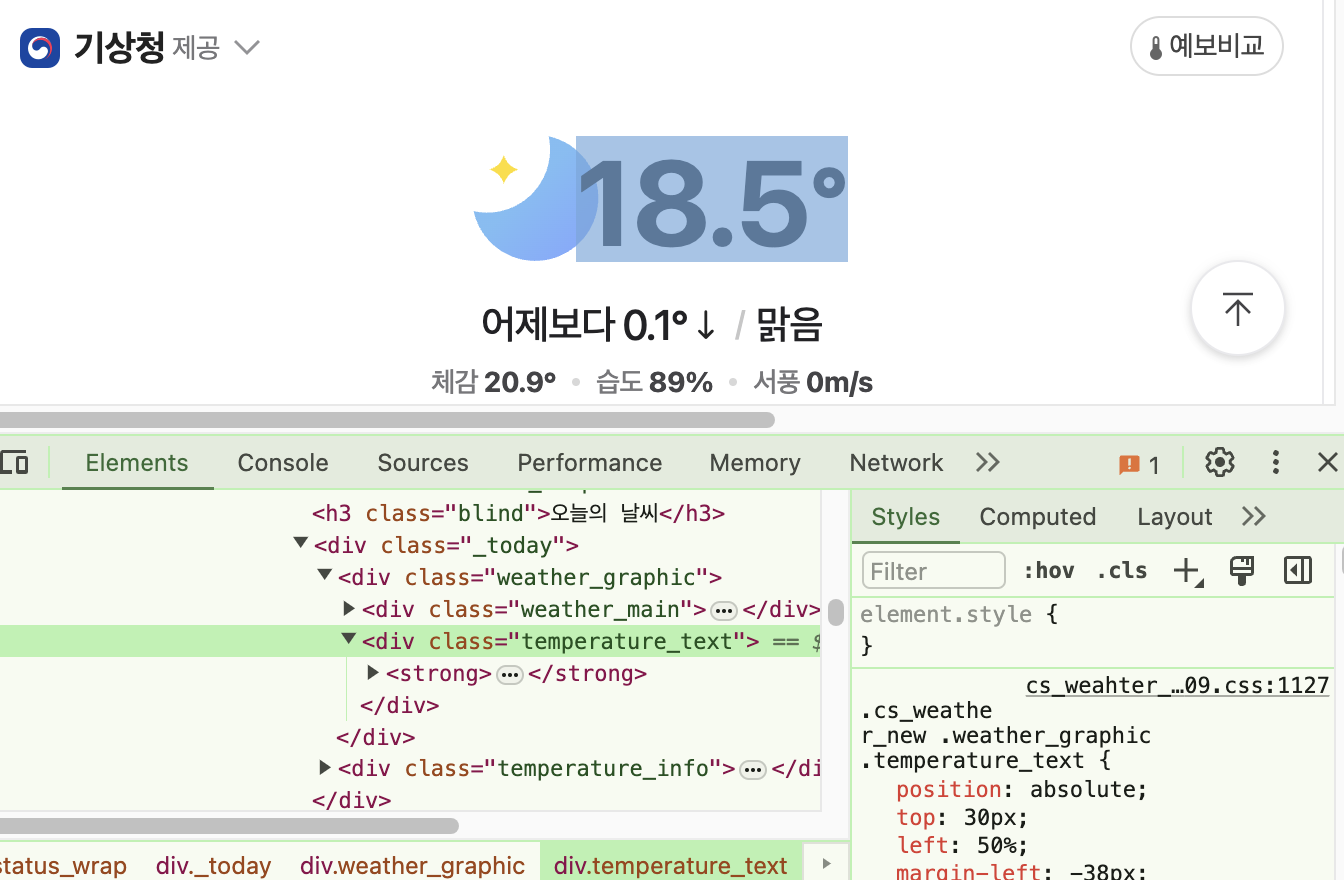
div태그- 클래스명
temperature_text
3. select_one(".클래스명")으로 온도에 해당하는 div 태그를 가져와 변수에 담는다.
temp = soup.select_one('.temperature_text')
# 잘 담겼는지 출력 해보기
print(temp)- 잘 담겼다.

4. .text를 사용하여 html 태그 안에 담긴 글자 내용 찍어보기
temp = soup.select_one('.temperature_text')
print(temp.text)
# ✅ `현재 온도18.5°`- 수치만 가져오고 싶어서 다시 태그를 보니
temperature_text 태그안에strong 태그가 있고,
그 안에 또span 태그,온도,span 태그, 총 3개가 들었다.
온도를 표시하는 부분은 두 번째에 있다.

5. 온도 수치만 가져오기
.클래스이름 > html태그
이렇게 쓰면, 클래스이름에 해당하는 html 태그 안의 html태그로 콕 지정할 수 있다. (html 태그, 아이디, 클래스 이름 어떤 것을 써도 된다.).contents로 내부의 데이터를 전부리스트(list)에 값으로 담을 수 있다.
# .temperature_text 클래스를 가진 태그 안에 있는
# strong 태그가 가진 태그를 모두 list에 담고,
# 리스트의 두 번째에 있는 요소에 접근해라
temp = soup.select_one('.temperature_text > strong').contents[1]
print(temp.text)
# ✅ 18.56. 이런 식으로 다른 정보도 가져올 수 있다.
temp = soup.select_one('.temperature_text > strong').contents[1]
cloud = soup.select_one('.weather').text
humid = soup.select_one('.summary_list > div:nth-child(2) > dd').text
wind = soup.select_one('.summary_list > div:nth-child(3) > dd').text
print(temp, cloud, humid, wind)
# ✅ 18.5 맑음 89% 0m/s📝 선택자 사용하여 원하는 html 정보만 가져오기
select()혹은select_one()`으로 원하는 html 정보만 가져올 수 있다.
1. 선택자를 사용하는 방법 (copy selector)
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')2. 태그와 속성값으로 찾는 방법
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')3. 한 개만 가져오고 싶은 경우
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')연습
멜론 탑백 차트 스크래핑하여 크롤링할 html 태그 확인
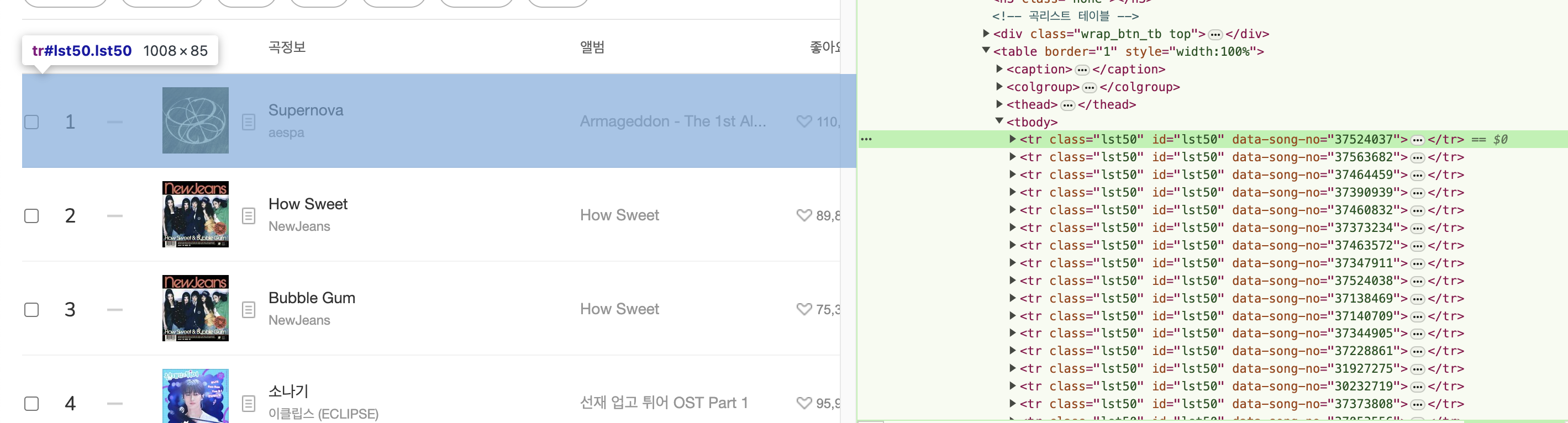
일단 1위 곡만 가져와 보자 (하나)
from bs4 import BeautifulSoup
import requests
# 멜론 100 차트 스크래핑
url = "https://www.melon.com/chart/index.htm"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# ✅ requests 라이브러리 => 지정된 URL의 HTML 콘텐츠 요청
data = requests.get(url, headers=headers)
# ✅ BeautifulSoup 라이브러리 => HTML 파싱
soup = BeautifulSoup(data.text, "html.parser")
# print(soup)
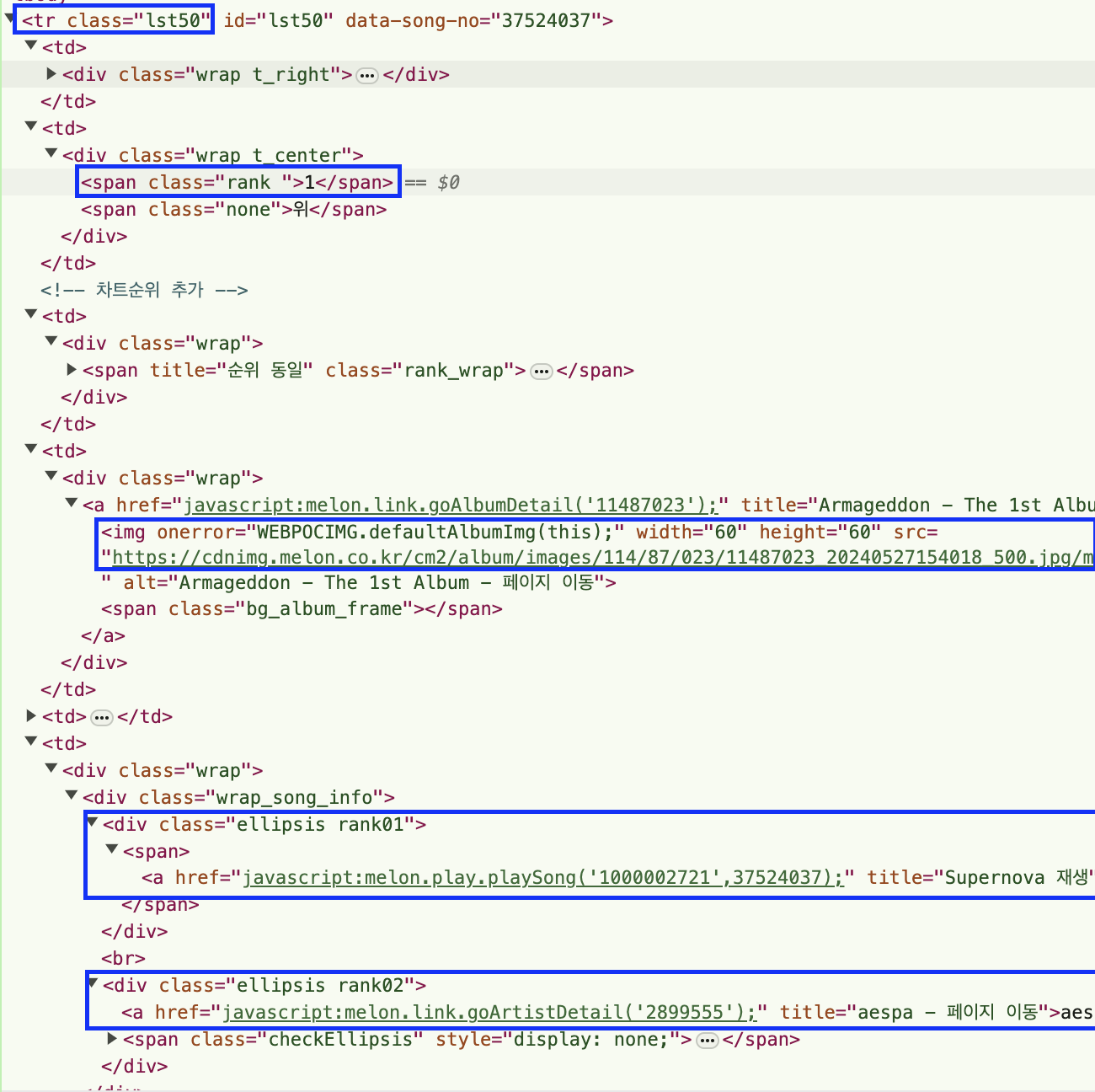
tr = soup.select_one(".lst50")
rank = tr.select_one(".rank").text
title = tr.select_one(".rank01 > span > a").text
artist = tr.select_one(".rank02 > a").text
image = tr.select_one("img")["src"]
print(rank, artist, "-", title, image)터미널에 크롤링한 데이터 찍어보기

전체 차트 크롤링하기 (여러개)
60위 부터는 클래스명이 다르다.
- 따라서 아에 1-100위를 아우르는 부모 태그를 가져와서 데이터를 뽑아내자.
# 차트 전체 가져오기
trs = soup.select("tbody > tr")
# 반복문 작성
for tr in trs:
rank = tr.select_one(".rank").text
title = tr.select_one(".rank01 > span > a").text
artist = tr.select_one(".rank02 > a").text
image = tr.select_one("img")["src"]
print(rank, artist, "-", title)
참고
웹 스크래핑을 할 때는 해당 웹사이트의 이용 약관을 준수하고, 데이터 수집의 목적에 따라 합법적인 범위 내에서 작업해야 한다.
또한, 너무 빈번한 요청은 서버에 부하를 줄 수 있으므로 적절한 간격을 두고 요청을 보내는 것이 좋다.
