SQL
개념 정리
SQL(Structured Query Language)
:관계 데이터베이스(RDBMS)를 위한 표준 질의어이자 비절차적 데이터 언어이다.
비절차적인 언어: 데이터를 조회하거나 조작하는데 필요한 조건을 기술하긴 하지만, 어떻게 데이터를 찾고 처리하는지와 같은 실행 절차를 직접 명시하지 않음
분류
데이터 정의어(DDL): 테이블을 생성하고 변경/삭제하는 기능을 제공
예) CREATE, ALTER, DROP
데이터 조작어(DML): 테이블에 새 데이터를 삽입하거나 테이블에 저장된 데이터를 수정/삭제/검색하는 기능 제공
예) SELECT, INSERT, DELETE
데이터 제어어(DCL): 보안을 위해 데이터에 대한 접근 및 사용 권한을 사용자별로 부여하거나 취소하는 기능 제공.
예) GRANT, REVOKE
데이터 조작어 (DML)
1. SELECT 문
: 데이터를 검색하는 기본 문장으로, 결과를 테이블 형태로 출력함.
SELECT [ALL | DISTINCT] <속성이름(들)>
FROM <테이블이름(들>
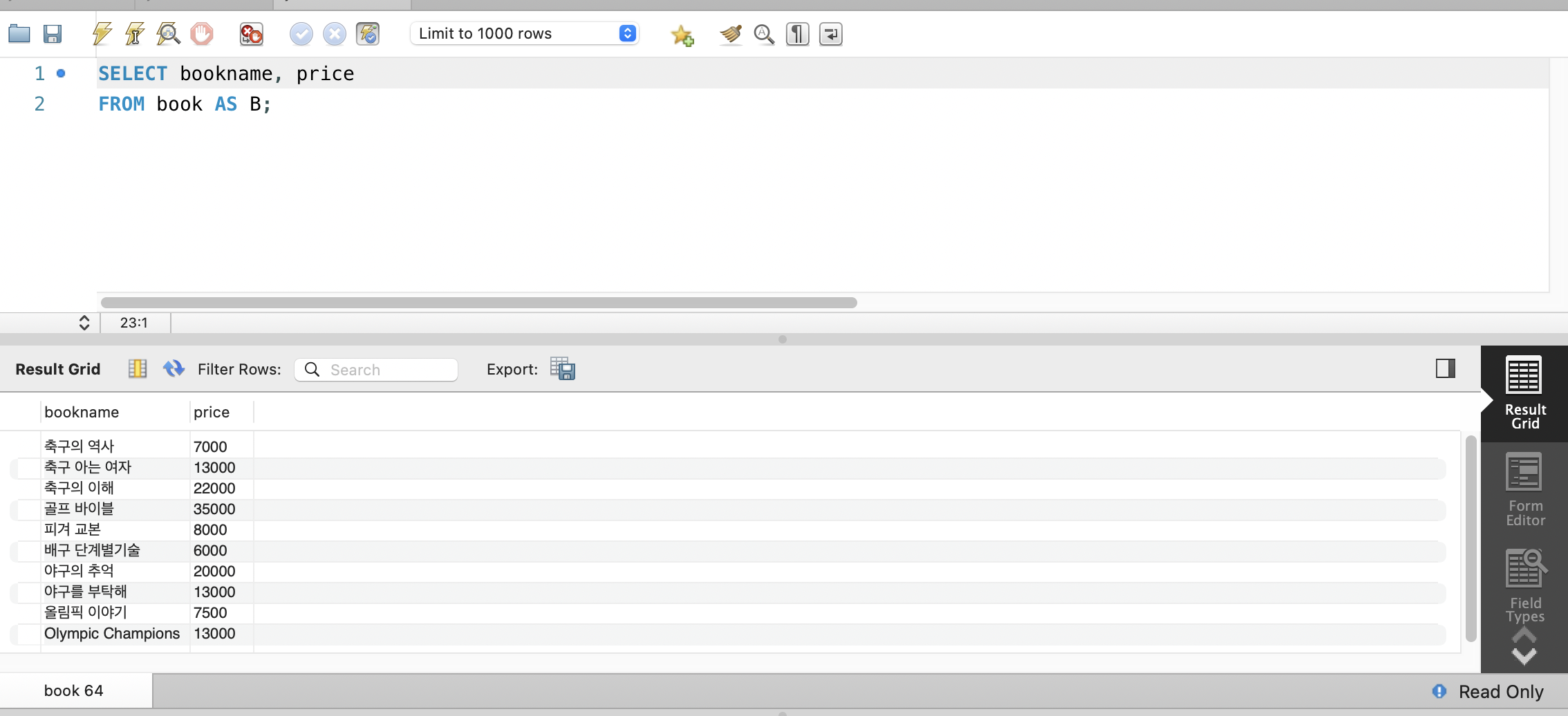
SELECT name, custid
FROM customer;- ALL: 결과 테이블의 튜플 중복 허용 (기본)_
- DISTINCT: 결과 테이블 튜플의 중복 허용하지 않도록 지정
SELECT [ALL | DISTINCT] <속성이름(들)>
FROM <테이블이름(들>
WHERE <검색조건(들): 단, 수식이나 함수 불가>
GROUP BY <속성 이름>
HAVING <검색조건(들): 수식이나 함수 포함된 것들
ORDER BY <속성 이름> [ASC | DESC]예) 모든 도서의 이름과 가격 검색하기
WHERE 조건
: 해당 조건에 부합하는 튜플만 출력 (수식이나 함수 작성 X)
1. WHERE 절에 사용할 수 있는 술어:
- 비교 기호(>, <, >=, =)
- 범위:
BETWEEN - 집합:
IN,NOT IN - 패턴:
LIKE - 이외:
NULL,AND,OR,NOT
SELECT *
FROM book
---BETWEEN 사용
WHERE price BETWEEN 10000 AND 20000;
---IN/ NOT IN 사용
WHERE publisher IN ('대한미디어', '굿스포츠');- 패턴/복합 조건 사용
- LIKE와 와일드 문자를 사용해 문자열 검색 가능
- 와일드 문자 사용 시,
=기호 보다LIKE사용. AND또는OR사용 가능- 와일드 문자:
%: 0개 이상의 문자열과 일치
예) '%축구%': 축구를 포함하는 문자열_: 특정 위치에 있는 1개의 문자와 일치
예) '_구%': 두 번째 위치에 '구'가 들어가는 문자열
SELECT bookname
FROM book
WHERE bookname LIKE '%축구%';
SELECT bookname
FROm book
WHERE bookname LIKE '_구%';ORDER BY
정렬검색: SQL문 실행 결과를 특정 순서대로 정렬
기본은 오름차순(ASC)이며, 내림차순으로 정렬할 때는 DESC 사용. 널 값은 오름차순에서는 맨 마지막, 내림차순에서는 맨 먼저 출력됨.
SELECT bookname
FROM book
ORDER BY bookname DESC;
---순서가 같은 결과가 있을 때, 두 번째 정렬기준으로 정렬하는 법
SELECT bookname
FROM book
ORDER BY bookname DESC, price ASC;2. 집계함수와 GROUP BY
집계함수
: 특정 속성 값을 통계적으로 계산하는 함수로 WHERE절에서는 사용불가하고 SELECT나 HAVING절에서만 사용 가능
예) SUM, AVG, COUNT 같은 합계, 평균, 갯수
집계함수 종류
| 집계함수 | 문법 | 예 |
|---|---|---|
SUM | SUM(<속성이름>) | SUM(price) |
AVG | AVG([<속성이름>) | AVG(price) |
COUNT | COUNT[<속성이름/*>] | COUNT(*) |
외에도 MAX, MIN 등의 집계함수가 존재하고, 속성을 택할 때 ALL/DISTINCT 선택 가능.
COUNT의 경우 책의 갯수나 튜플의 갯수를 세는데 사용 가능.
SELECT SUM(saleprice) AS 총매출
FROM orders;위처럼 집계함수를 사용해서 나오는 결과 열(컬럼)의 이름을 AS를 통해 지정해줄 수 있음
COUNT
: 행의 개수를 세며 괄호 안에는 * 또는 특정 속성의 이름을 사용.
COUNT(*)는 널(NULL)까지 포함해 전체 튜플의 개수를 세고, COUNT(<속성>)의 경우 널(NULL)을 제외한다.
GROUP BY
: 특정 속성의 값이 같은 튜플을 모아 그룹을 만든 후 검색
예) 고객별로 주문한 도서의 총수량과 총판매액 구하기
SELECT COUNT(*) AS 도서수량,
SUM(saleprice) AS 총액
FROM orders
GROUP BY custid
ORDER BY custid;위의 sql문 같은 경우 순서는 위처럼 작성하지만, 실제로 실행되는 순서는 FROM -> GROUP BY -> SELECT -> ORDER BY 순서대로 진행된다. SELECT가 나중에 실행되기 때문에 여기서 정하는 별칭 등은 아래에서 사용할 수 없다.
HAVING
: GROUP BY 절의 결과에 나타나는 그룹을 제한.
GROUP BY와 HAVING 사용 주의사항
GROUP BY <속성>: 튜플을 그룹으로 묶으면 SELECT 절에는 GROUP BY에서 사용한 속성과 집계함수만 나올 수 있음.
HAVING <검색조건>: WHERE절과 HAVING절이 같이 포함된 SQL문은 검색조건이 모호해 질 수 있기에 HAVING절은
1. 반드시 GROUP BY 절과 함께 작성해야함
2. WHERE 절보다 뒤에 나와야함
3. 검색조건에는 집계함수가 나와야함
예)
SELECT custid, COUNT(*) AS 도서수량
FROM orders
WHERE saleprice >= 8000
GROUP BY custid
HAVING COUNT(*) >= 2;
ORDER BY custid;위 sql문의 실행순서는 FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY 순이다.
3. 조인(JOIN)
조인검색: 여러 테이블을 연결해 데이터를 검색하는 것
카티션 프로덕트를 사용해도 연결할 수 있지만, 데이터가 많아질수록 방대한? 연산?이 필요해지는 식이므로 조인을 사용하는 것이 좋다..!
❗ 주의점
연결하려는 테이블 간에 조인 속성의 이름은 달라도 되지만 도메인은 같아야함
일반적으로 외래키를 조인속성으로 사용함
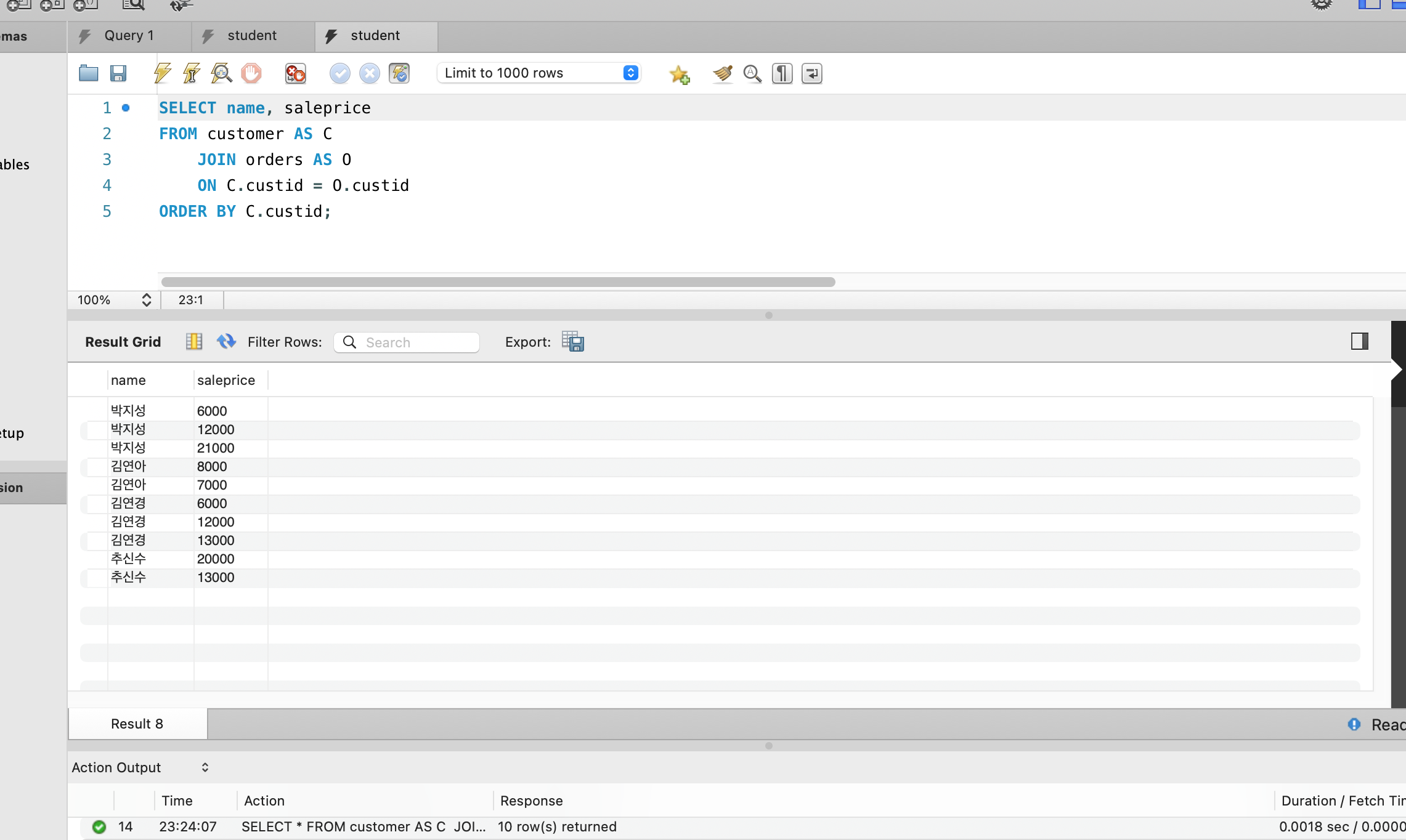
SELECT *
FROM customer AS C
JOIN orders AS O
ON C.custid = O.custid
WHERE custid BETWEEN 1 AND 4;위 예시처럼 테이블에 AS를 사용해 별칭을 지정해 줄 수 있다.
FROM절에서 지정한 별칭은 SELECT에서 사용해도 되지만, SELECT에서 지정한 별칭을 아래에서 사용하는것은 불가. 별칭인 C, O를 튜플 변수라고도 한다.
외부조인
: 조인 조건을 만족하지 않는 튜플에 대해서도 검색을 수행하는 조인.
완전/왼쪽/오른쪽이 존재한다. 각각 전부에서 만족하지 않는 튜플에 대해서도 가져올지, 왼쪽에서만 또는 오른쪽에서만 가져올지를 결정한다.
---제대로 안돌아가는 코드
SELECT C.name, C.saleprice
FROM customer AS C
LEFT OUTER JOIN orders AS O
ON C.custid = O.custid
WHERE custid = 1;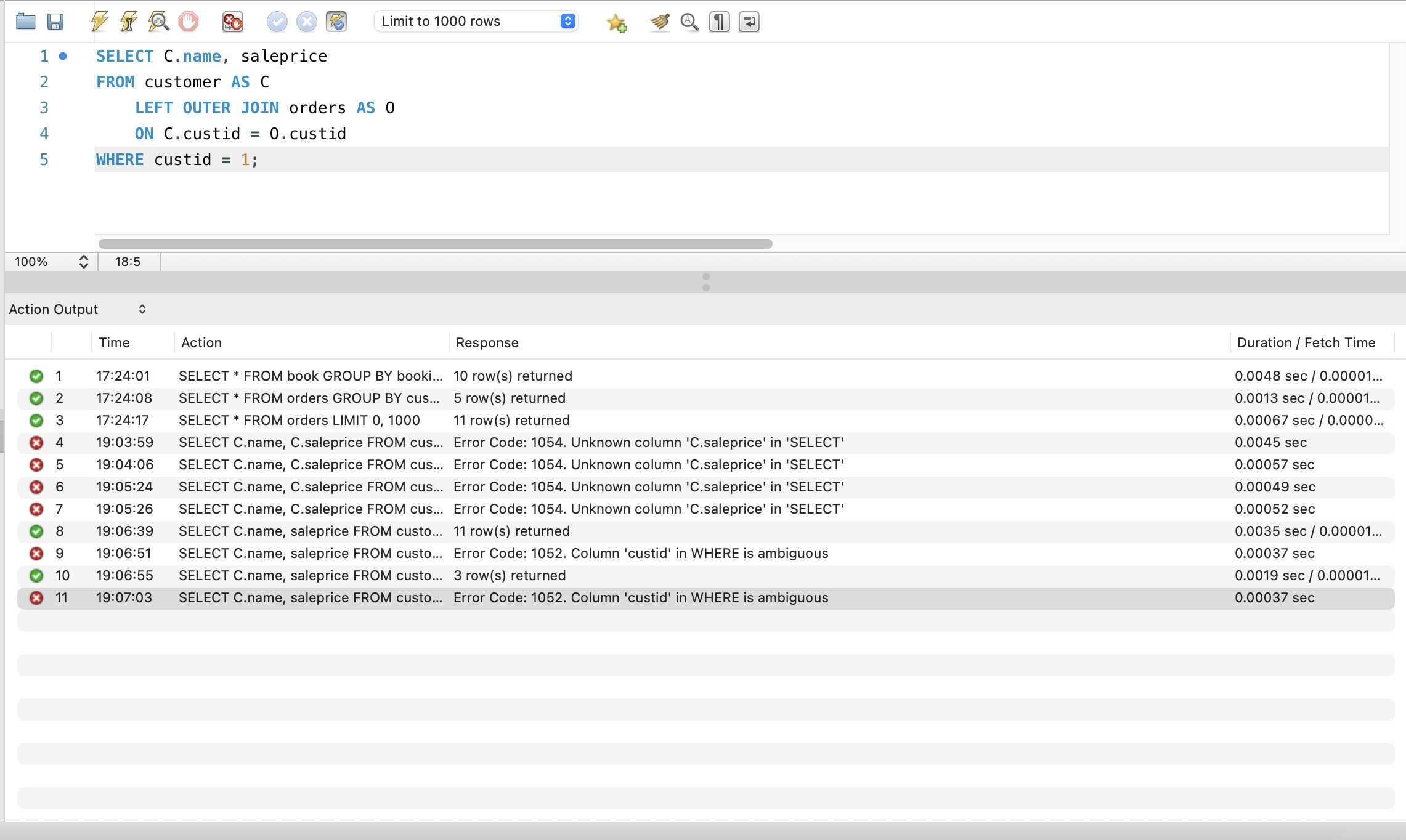
조인하고 나서 WHERE에서 속성 선택할 때 테이블명.속성 이렇게 지정해줘야할 것 같다. 공통 속성이면 둘 다 존재하니까. 그리고 SELECT할 때도 조인 후에도 잘 선택해줘야할 것 같다. (처음에 C.saleprice해서 오류)
예) 고객과 고객의 주문에 관한 데이터를 고객별로 정렬해 나타내기
SQL 클린 코드
코드 스타일
- 키워드 대문자:
SELECT - 식별자 소문자:
orders,customer_id - 별칭: 짧고 의미있는 이름
- 들여쓰기와 줄바꿈: 절마다 줄바꿈, 조건은 들여쓰기
- 주석:
-또는/**/를 통해 설명 추가
네이밍 규칙
- 일관성 유지: 같은 개념은 동일한 이름 사용
예)customer_id와cust_id혼용X - snake_case 권장
- 명확한 의미
