1. 내장함수, NULL, 비교문
1-1. SQL 내장함수
- 상수나 속성 이름을 입력값으로 받아 단일 값을 결과로 반환
- 모든 내장함수는 사용 시 유효한 입력값을 받아야함
- SELECT절, WHERE절, UPDATE절에서 모두 사용 가능
(1) 숫자 함수
- SQL문에서 수학의 기본적인 사칙 연산자와 나머지 연산자 기호를 그대로 사용
- MySQL은 이러한 연산자 중 사용 빈도가 높은 것을 내장 함수 형태로 제공
- ABS(숫자): 숫자의 절댓값을 계산
- CEIL(숫자), FLOOR(숫자): 올림/내림
- ROUND(숫자, m): 숫자의 반올림. m은 기준수.
ABS 함수
- 절댓값 구하는 함수
SELECT ABS(-78), ABS(78);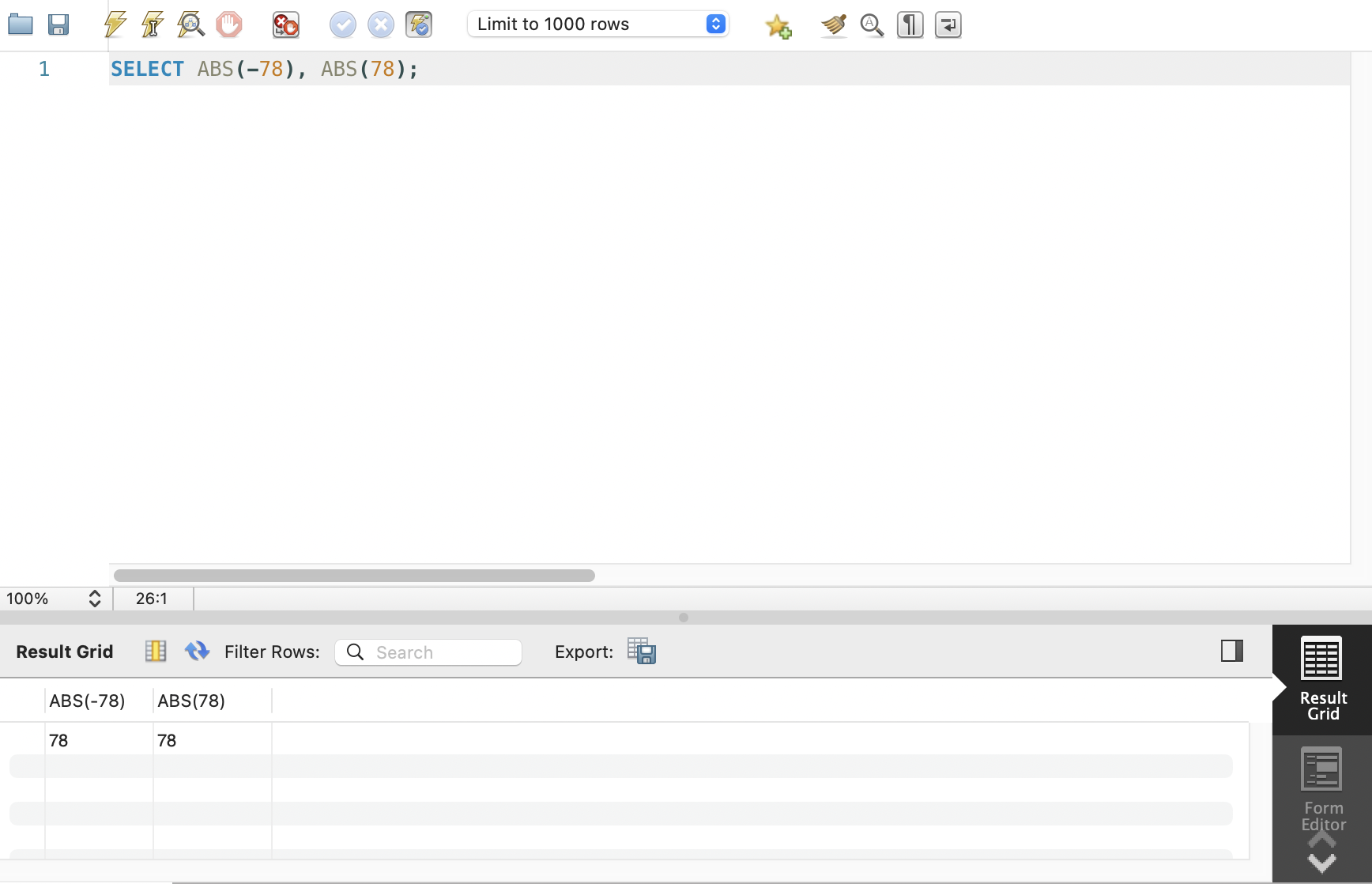
ROUND 함수
- 반올림한 값을 구하는 함수
SELECT ROUND(4.12345, 3);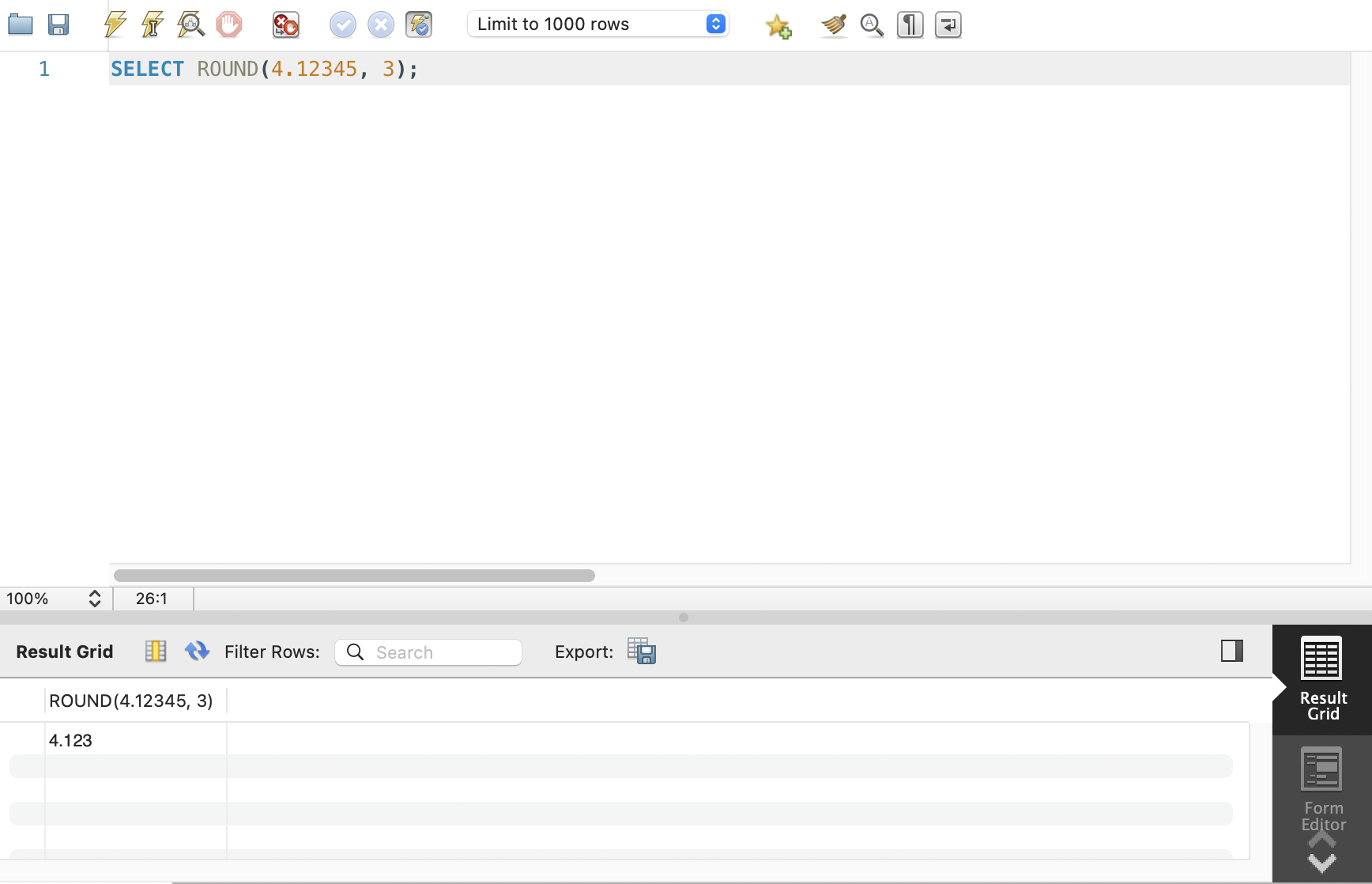
숫자함수의 연산
- 숫자함수에는 직접 숫자를 입력하거나 열 이름을 사용할 수 있음
- 여러 함수를 복합적으로 사용할 수도 있음
SELECT custid '고객번호', ROUND(SUM(saleprice)/COUNT(*), -2) '평균금액'
FROM orders
GROUP BY custid;
(2) 문자함수
문자값 반환 함수
- CONCAT(s1, s2): 두 문자열을 연결
- LOWER(s), UPPER(s): 대상 문자열을 모두 소문자로/대문자로 변환
- SUBSTR(s,n,k): 대상 문자열을 지정된 자리에서부터, 지정된 길이만큼 잘라서 반환
- TRIM(c FROM s): 대상 문자열의 양쪽에서 지정된 문자를 삭제. (문자열만 넣을 시 기본으로 공백 제거)
숫자값 반환 함수
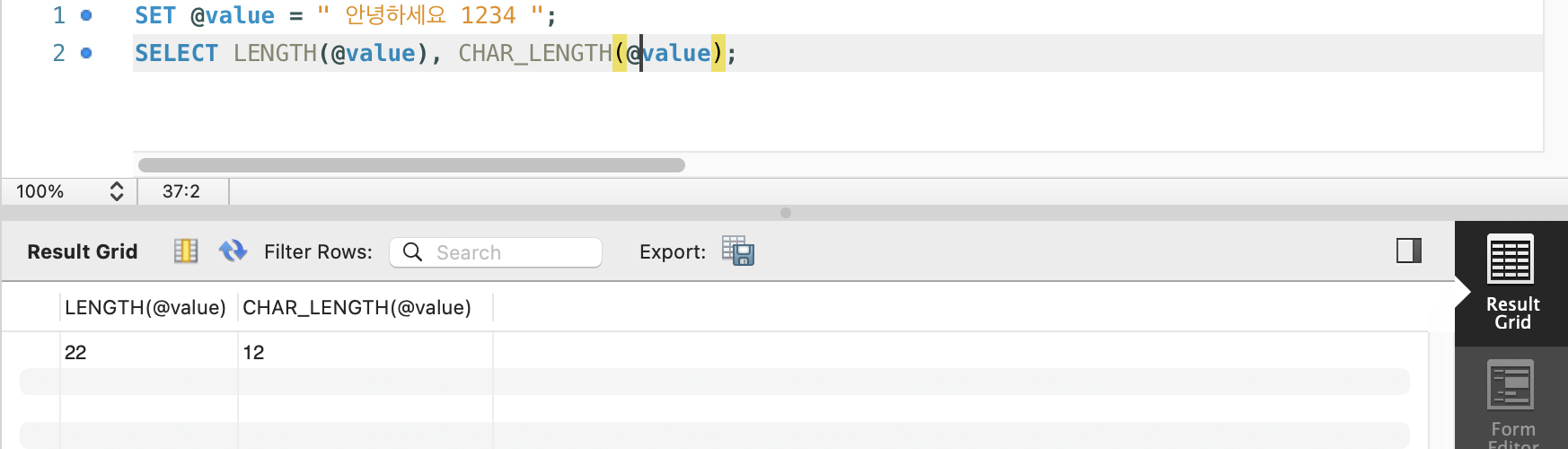
- LENGTH(s): 대상 문자열의 바이트를 반환 (알파벳은 1바이트, 한글은 3바이트)
- CHAR_LENGTH(s): 문자열의 문자 수를 반환
REPLACE 함수
- 문자열을 치환하는 함수
SELECT bookid, REPLACE(bookname, '야구', '농구') bookname, publisher, price
FROM book;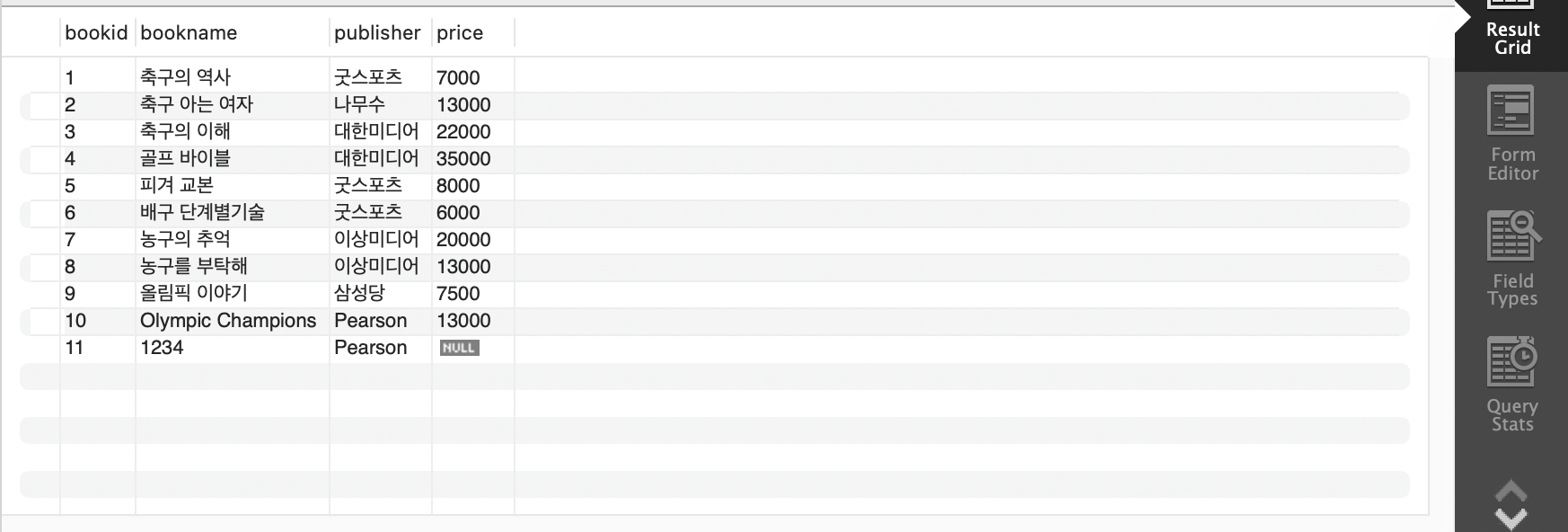
LENGTH, CHAR_LENGTH 함수
LENGTH(): 바이트 수를 가져오는 함수CHAR_LENGTH(): 문자의 수를 가져오는 함수
이름 가리기(masking) 실습
SELECT CONCAT(LEFT(name,1), '*',RIGHT(name,1)) AS marked_name
FROM customer;
SELECT
CASE
WHEN CHAR_LENGTH(name) = 2
THEN CONCAT(LEFT(name,1),'*')
WHEN CHAR_LENGTH(name) > 2
THEN CONCAT(LEFT(name,1), REPEAT('*',CHAR_LENGTH(name)-2), RIGHT(name,1))
ELSE name
END
FROM customer;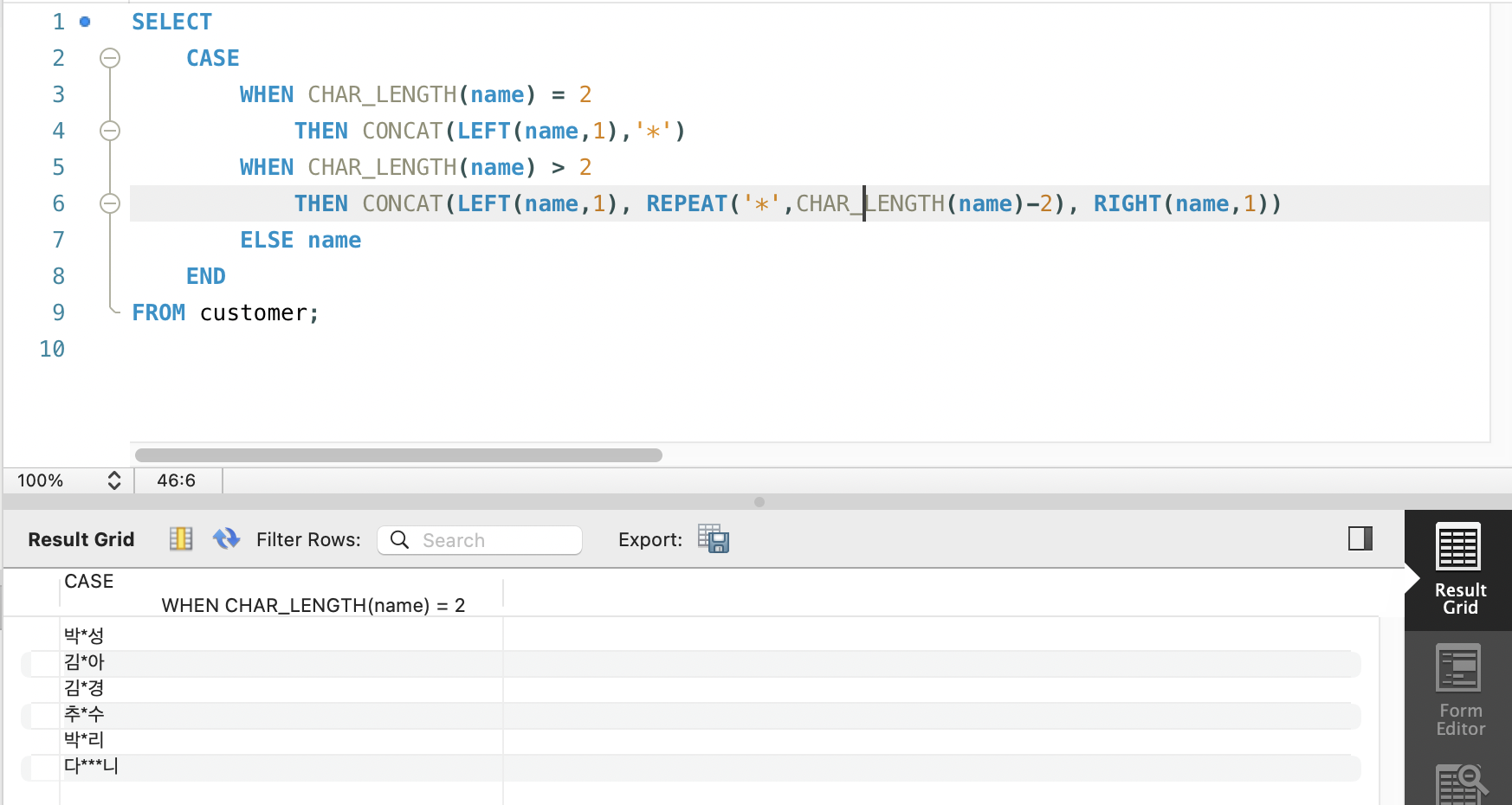
(3) 날짜/시간 함수
- 날짜와 시간 부분을 나타내는
format으로 표기 format은 날짜 형식 지정자로 날짜와 시간 부분을 표기하기 위해 특별한 규칙을 가짐.
STR_TO_DATE(string format): 문자열 데이터를 날짜형으로 반환DATE_FORMAT(date format): 날짜형 데이터를 문자열로 반환ADDDATE(date interval): DATE형의 날짜에서 INTERVAL 지정한 시간만큼 더함DATE(date): DATE형의 날짜 부분을 반환DATEDIFF(date1, date2): DATE형의 date1-date2 날짜 차이를 반환함SYSDATE: DBMS 상의 오늘 날짜를 반환.
- DBMS마다 함수 이름과 동작이 다름
- 날짜형 데이터는 '-'와 '+'를 사용하여 원하는 날짜로부터 이전(-)과 이후(+)를 계산할 수 있음
+ [ MariaDB에서 `NOW()`와 `SYSDATE()`]📌 날짜, 시간함수 사용 주의점
1. DBMS마다 이름과 동작, 의미가 다름
2. 타임존 문제
NOW()나CURRENT_TIMESTAMP는 DB 서버의 타임존을 기준으로 반환.- 서버와 사용자가 다른 지역에 있으면 시간이 어긋날 수 있으므로, 필요시 따로 맞춰줘야함.
- 날짜 포맷 출력:
DATE_FORMAT()(MySQL)TO_CHAR()(Oracle/Postgres) 포맷 지정- NULL 처리:
- 날짜 컬럼이 NULL이면 함수 적용 시 에러가 발생
- 기본값으로 설정해둬야함:
IFNULL(),COALESCE()사용해서 널 처리.
- 성능 고려: select에서 조회용으로 사용할 때
- 다른 부분에서 속성을 함수를 사용해 변환하면 인덱스에 저장된 값이 아니라 함수 결과를 새로 계산하여 테이블 풀 스캔을 할 가능성이 높음
- 테이블 풀스캔의 경우 성능이 떨어짐
WHEN DATE(order_date) = '2026-04-02'보다WHEN order_date >= '2026-03-24 00:00:00' AND order_date < '2026-03-39 00:00:00'가 좋음.
NOW(): 쿼리 실행 시작 시점의 시간을 반환. 같은 쿼리 내에서는 항상 동일한 값으로 유지 SYSDATE(): 함수 호출 순간의 시스템 시간을 반환. 같은 쿼리 내에서도 호출 시점마다 값이 달라짐.
(1) ADDDATE(date, interval)
ADDDATE('날짜', 'INTERVAL 수치단위')
- 지정한 날짜에 일(day) 또는 시간(interval)을 더해 새로운 날짜를 반환하는 함수
SET @value = '2024-04-01';
SELECT ADDDATE(@value, INTERVAL -10 DAY) "BEFORE", ADDDATE(@value, INTERVAL 10 DAY) "AFTER";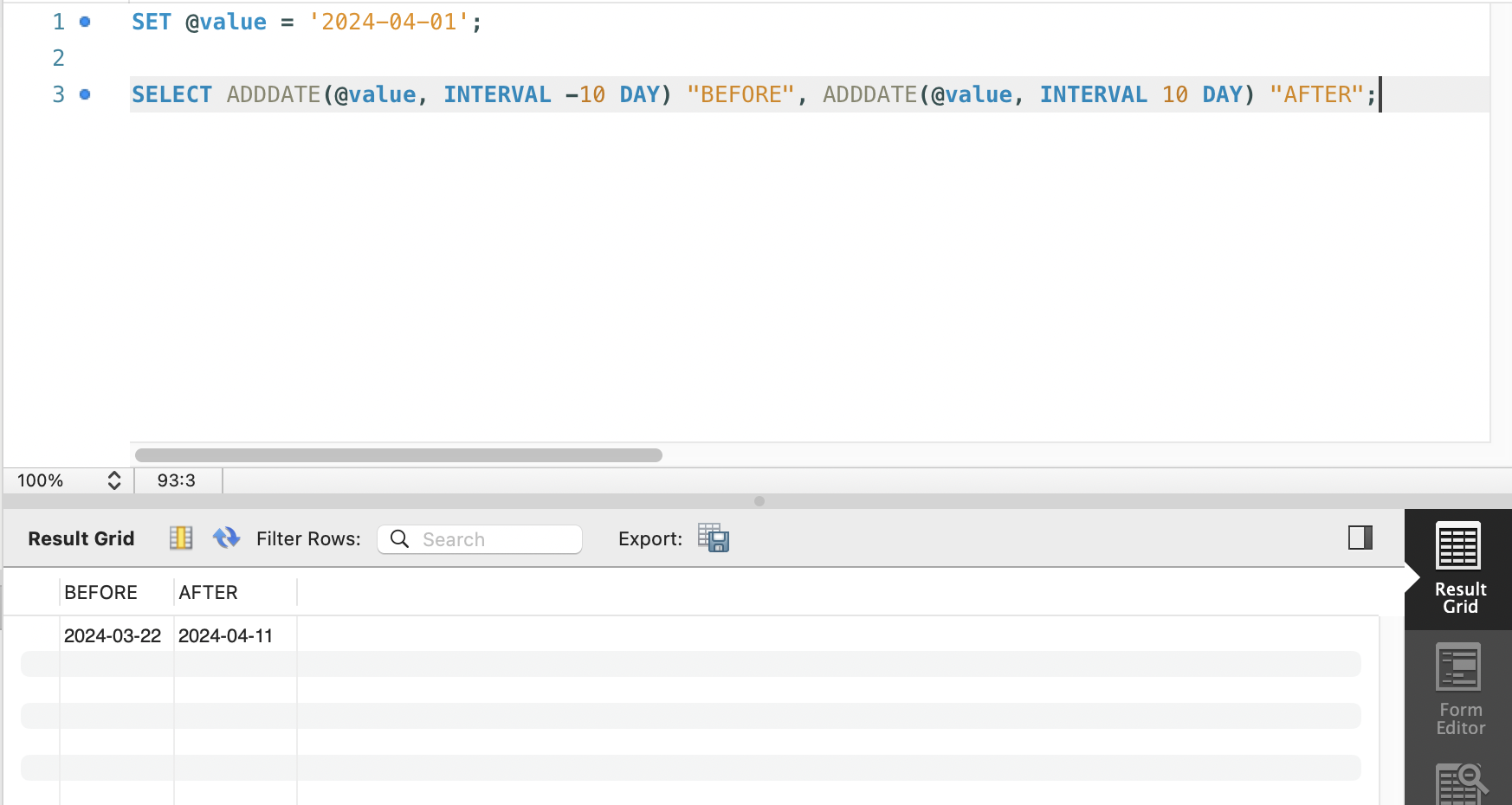
(2) format의 주요 지정자
1. 요일
%w: 요일 순서 (0~6, Sunday=0)%W: 요일 (Sunday~Saturday)%a: 요일의 약자(Sun~Sat)
2. 날짜
%d: 한 달 중 날짜 (00~31)%j: 1년 중 날짜 (001~366)
3. 시간
%h: 12시간 (0~12)%H: 24시간 (0~24)%i: 분 (0~59)%s: 초(0~59)
4. 월
%m: 월 순서 (01~12, January = 01)%M: 월 이름 (January ~ December)%b: 월 이름 약어(Jan~Dec)
5. 연도
%Y: 4자리 연도%y: 4자리 연도의 마지막 2자리
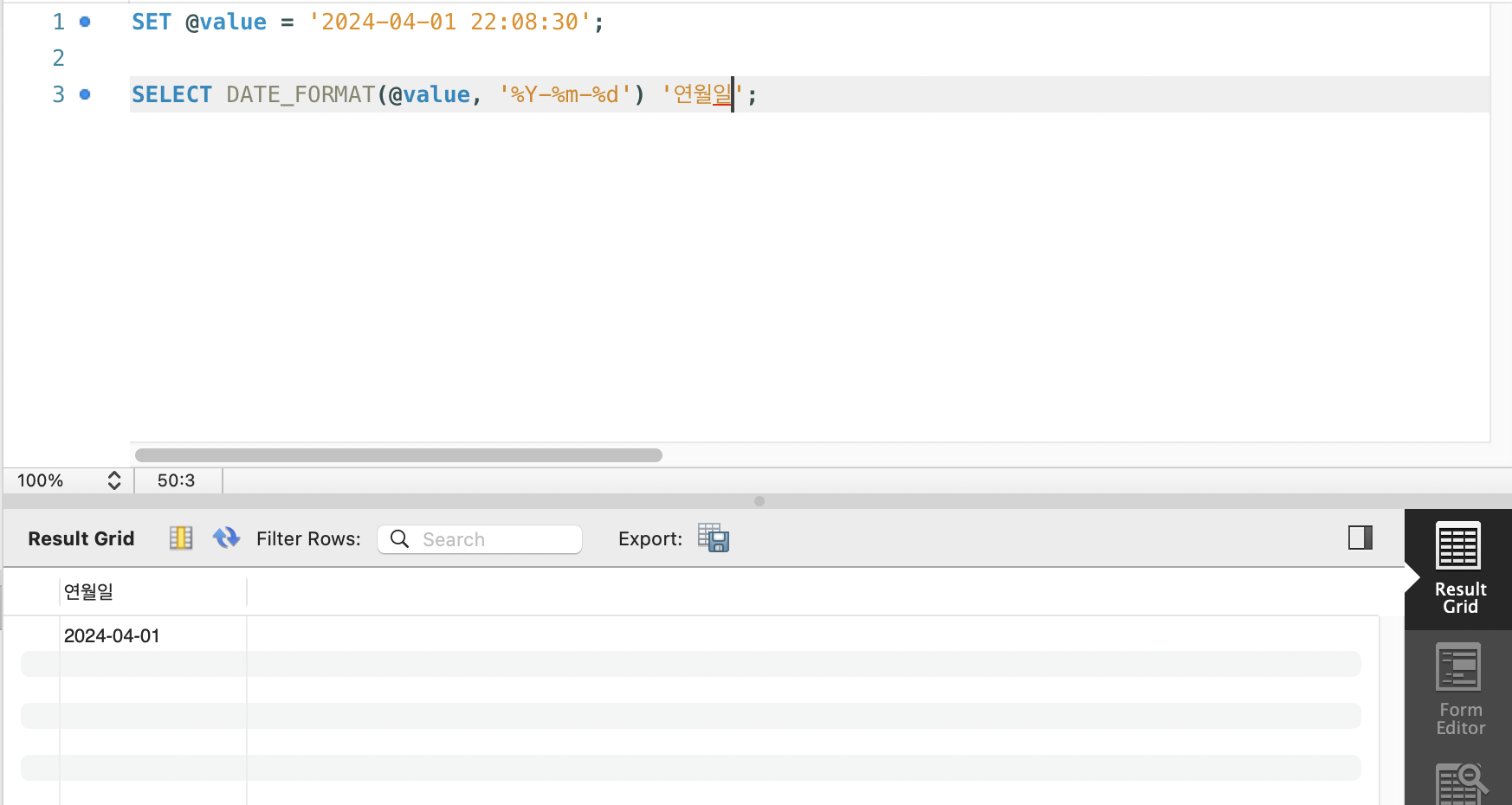
(3) STR_TO_DATE 함수, DATE_FORMAT 함수
STR_TO_DATE: CHAR 형(문자열)으로 저장된 날짜를 DATE형으로 변환DATE_FORMAT: 날짜형을 문자형으로 변환함
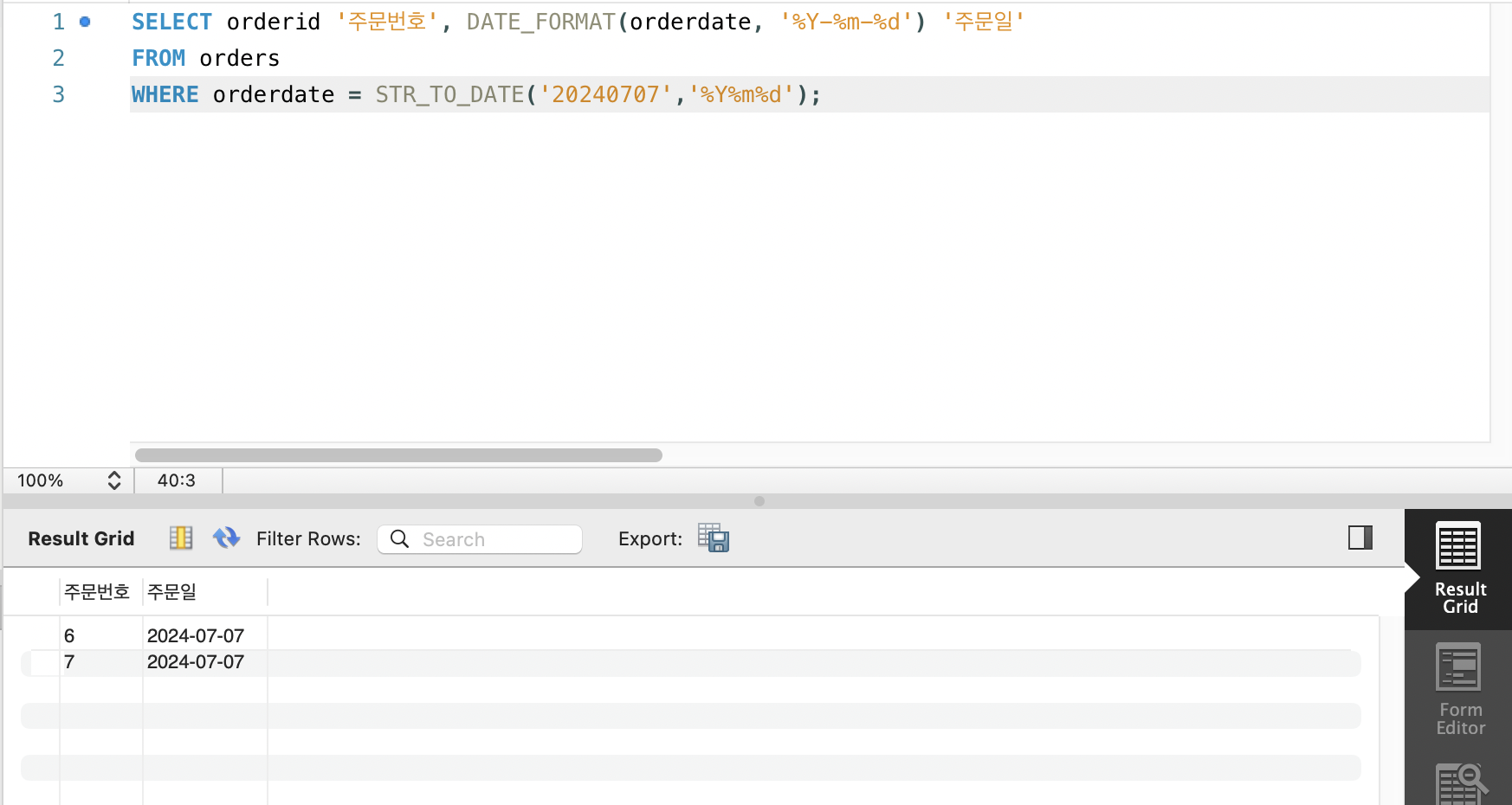
(4) SYSDATE 함수
- 데이터베이스에 설정된 현재 날짜와 시간을 반환하는 함수
1-2. NULL 값 처리
널(NULL) 값
-
아직 지정되지 않은 값, 즉 값을 알 수도 없고 적용할 수도 없음
-
'0'이나 빈 문자 또는 공백과는 다른 특별한 값으로 **비교연산자로 비교할 수도 없고, 연산 수행의 결과도 NULL로 반환됨.
-
NULL 값에 대한 연산 및 집계함수:
- NULL + 숫자의 연산 결과는 NULL
- 집계 함수를 사용할 때에 NULL이 포함된 행은 집계에서 제외 (해당 행이 하나도 없을 경우, SUM, AVG의 결과는 NULL, COUNT 함수의 결과는 0이됨)
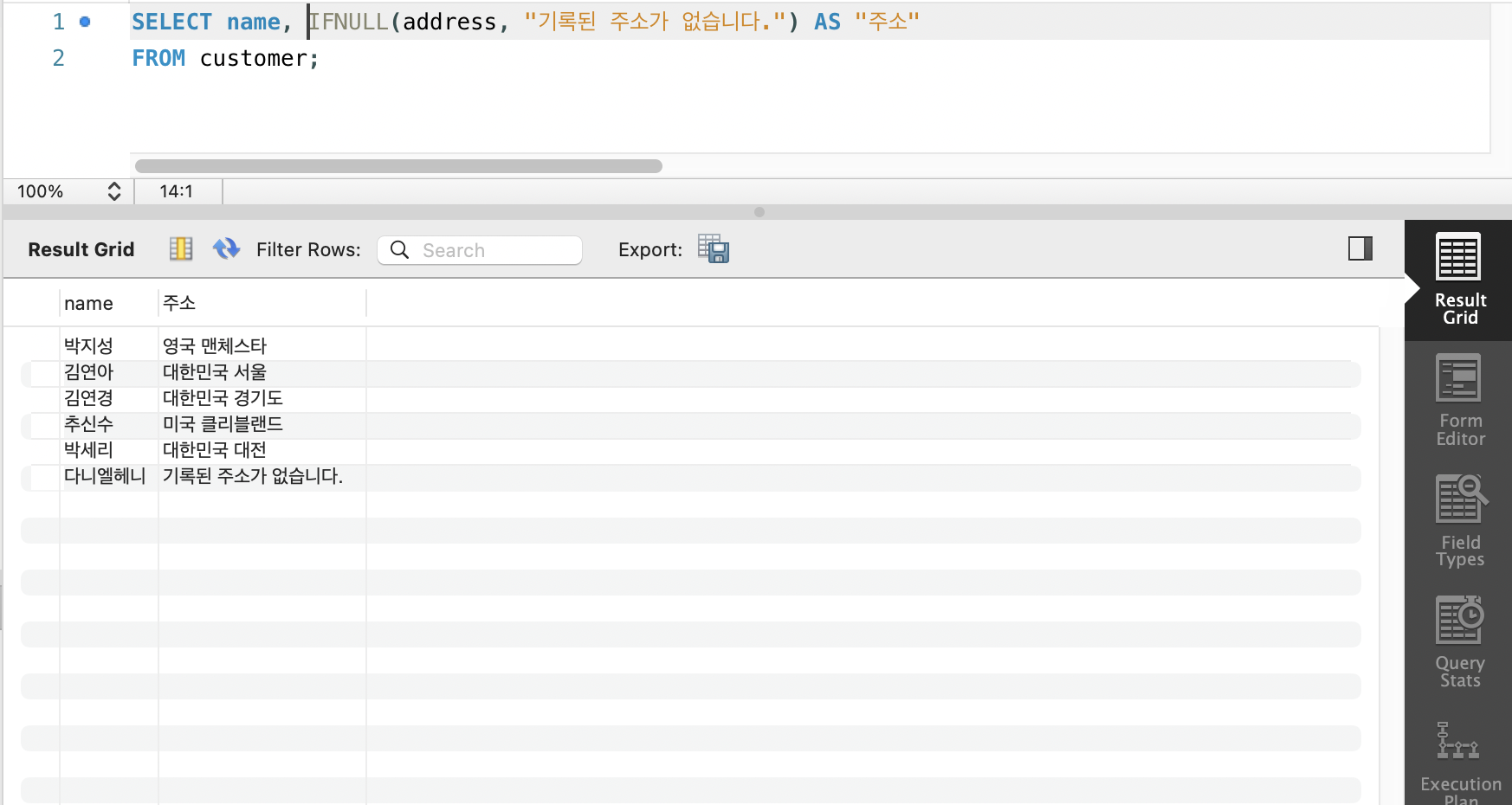
IFNULL 함수
-
NULL 값을 다른 값으로 대치하여 연산하거나 다른 값으로 출력
-
IFNULL(속성, 값)의 형태로 사용하며 속성값이 널일때 '값'으로 대치한다. -
MySQL, MariaDB에서 사용
COALESCE 함수
- 표준 SQL에서 지원
COALESCE(인자1, 인자2,...): 여러 개의 인자 중 널값이 아닌 첫 번째 값을 반환하며IFNULL과 마찬가지로COALESCE(속성, '값')으로 작성하면 널 값을 '값'으로 채워서 출력할 수 있음.
1-3. 행번호 출력
SET
- MySQL에서는 변수는 이름 앞에
@기호를 붙이며, 치환문에는 SET과:=기호를 사용한다.
SET @seq:=0;
SELECT (@seq := @seq+1) '순번', custid, name, phone
FROM customer
WHERE @seq < 2;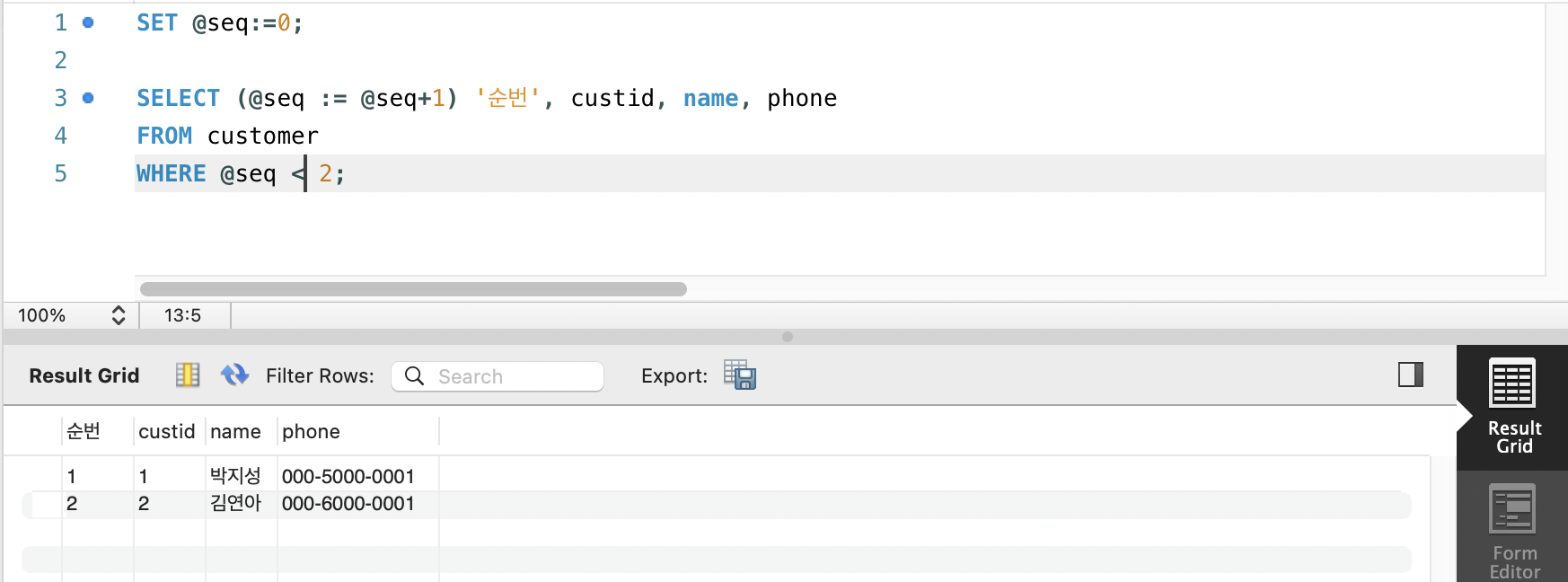
위처럼 적었을 때는 결과가 생각한 것처럼 잘 나오는데, 좀 다르게 @seq <2인 경우에만 출력하려고 하면, 예상과는 다르게 아래처럼 나온다.
SET @seq:=0;
SELECT (@seq := @seq+1) '순번', custid, name, phone
FROM customer
WHERE @seq > 2;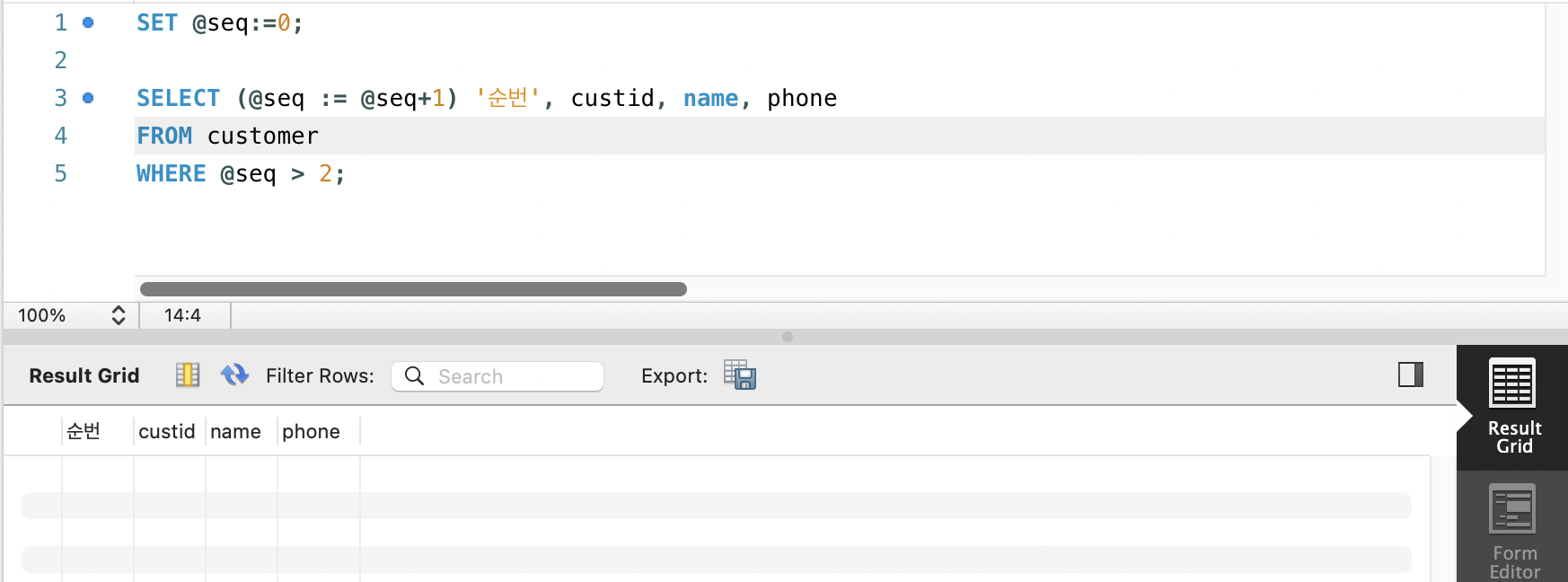
이유는 쿼리 실행 시 동작 순서와 관련이 있다.
@seq를 증가시켜주는 부분이 SELECT에 있어서 인데, WHERE절에서 조건을 체크하고 그 행이 조건에 맞으면 이제 SELECT로 가게되는데, 위의 경우에는 처음부터 @seq가 조건에 맞지 않아 SELECT절로 이동하지 않으면서 @seq가 그 뒤의 행들에서도 전혀 증가되지 않고 계속 0으로 남아있게 된다.
그래서 만약에 위에처럼 쿼리를 작성하고 싶으면 아래처럼 @seq 증가시켜주는 부분을 WHERE 절에서 하는 하도록 작성해주면 되었다.
이게 쿼리 실행했을 때 각 행 별로 이제 쿼리의 내용대로 돌아가면서? 실행? 조건 체크? 등이 이루어지는 식이고 그 행 별로 이제 적용이 되는? 느낌이었다.
SET @seq:=0;
SELECT (@seq) '순번', custid, name, phone
FROM customer
WHERE (@seq := @seq+1) > 2;1-4 CASE WHEN
- 조건에 따라 다른 값을 반환
- IF-THNE-ELSE와 비슷하게 동작하며 집계함수와 함께 쓰거나 출력 컬럼을 가공할 때 유용하다
CASE
WHEN 조건1 THEN 결과1 #WHEN: 조건 지정
WHEN 조건2 THEN 결과2 #THEN: 조건이 참이면 반환할 값
...
ELSE 기본값 #ELSE: 모든 조건이 거짓일 때 반환할 기본값
END AS 별칭 #END: CASE문 종료예) 국내 거주자/국외 거주자 출력
SELECT custid, name,
CASE
WHEN address LIKE '%대한민국%'
THEN "국내"
ELSE "국외"
END AS "국적", phone
FROM customer;
2. 부속질의
2-1. 부속질의 (=서브쿼리)
- 하나의 SQL문 안에 다른 SQL문이 중첩된 질의
- 주로 메인 쿼리의 조건에 따라 서브 쿼리의 결과를 가져와서 메인 쿼리에서 사용하는 용도로 활용
- 다른 테이블에서 가져온 데이터로 현재 테이블의 정보를 찾거나 가공하는 등의 작업 수행 가능
- 조인을 사용하는 방법도 있지만 서브 쿼리가 더 유리한 경우에 서브 쿼리를 사용
부속 질의가 유리할 때
- 필터링 대상이 매우 적을 때: 서브 쿼리의 결과값이 단 하나임이 보장되고, 메인 테이블의 양이 방대할 때
- 복잡한 집계가 포함될 때: 조인으로 풀면 중복 데이터가 너무 많이 발생해 계산이 꼬이는 경우.
+EXPLAIN을 사용하면 쿼리가 훑고간 행의 수, 실제 남은 데이터의 비율, 인덱스를 사용하는(using index) 아니면 풀테이블 스캔(using filesort)를 하는지 등을 확인해 볼 수 있음.
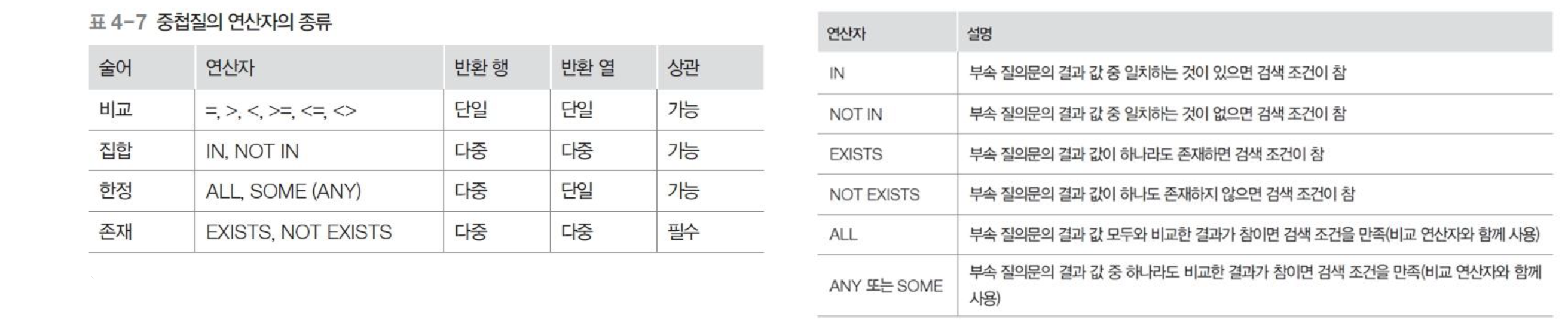
부속질의의 종류
| 부속질의 | 실무 용어 | 설명 |
|---|---|---|
| WHERE 부속질의 | 중첩질의 | WHERE 절에서 술어와 같이 사용되며 결과를 한정. 상관 또는 비상관 형태 |
| SELECT 부속질의 | 스칼라 부속질의 | SELECT 절에서 사용되며 단일값을 반환 |
| FROM 부속질의 | 인라인 뷰 | FROM 절에서 결과를 뷰 형태로 반환 |
WHERE 부속질의
- 중첩질의. 보통 데이터를 선택 하는 조건 혹은 술어와 같이 사용.
- 비교/집합/한정/존재 연산자와 사용.
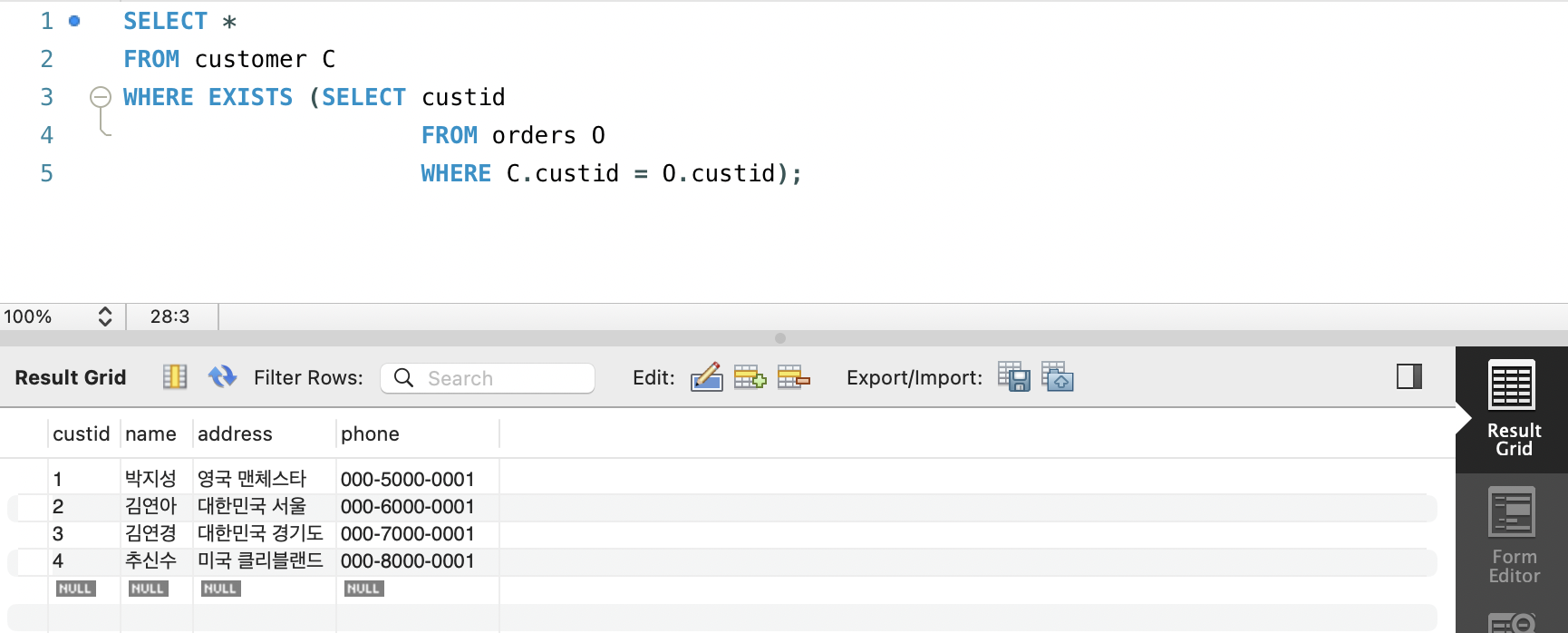
비교연산자
- 비교 연산자 사용 시 부속질의가 반드시 단일 행, 단일 열을 반환해야하며, 아닐 경우에는 질의를 처리할 수 없다.
- 주질의 대상 열 값과 결과 값을 비교 연산자에 적용하여, 참인 경우에만 주질의의 해당 열을 출력한다.
IN, NOT IN (집합 연산자)
- IN/NOT IN 연산자는 주질의의 속성값이 부속질의에서 제공한 결과 집합에 있는지/없는지 확인하는 역할
- 주질의는 WHERE절에 사용되는 속성값을 부속질의의 결과 집합과 비교해 하나라도 있으면 참이 됨
ALL, SOME/ANY(한정 연산자)
- 하나의 결과값이 아니라 여러 결과값과 비교할 수 있게 해줌
- ALL: 모든 결과값보다~ (크거나 작다 등 비교연산자 사용)
- SOME/ANY: 반환한 결과값 중 하나라도 조건 만족
#예시
SELECT 이름 FROM 학생
WHERE 키 > ALL (SELECT 키 FROM 학생 WHERE 학년 = 3);
SELECT 이름 FROM 학생
WHERE 키 > ANY (SELECT 키 FROM 학생 WHERE 학년 = 3);예)
#동작하지 않는 경우
SELECT *
FROM customer
WHERE custid = (SELECT custid
FROM orders);
#수정
SELECT *
FROM customer
WHERE custid IN (SELECT custid
FROM orders);부속질의 vs 상관질의
- 부속질의: 단순히 쿼리 안에 들어간 SELECT문으로 독립적으로 실행할 수 있음
- 상관질의: 부속질의 중 메인 쿼리의 컬럼을 참조하여 메인 쿼리의 각 행마다 실행되는 경우.
EXISTS, NOT EXISTS (존재 연산자)
- 데이터의 존재 여부를 확인
WHERE [NOT] EXISTS (부속질의)- 메인 쿼리와 서브 쿼리가 상관 부속질의의 관계일 때 둘 사이의 연결 관계를 잘 설정해줘야한다
SELECT *
FROM customer C
WHERE EXISTS (SELECT custid
FROM orders O
WHERE C.custid = O.custid);위에서는 `C.custid = O.custid`로 둘을 연결해주었다.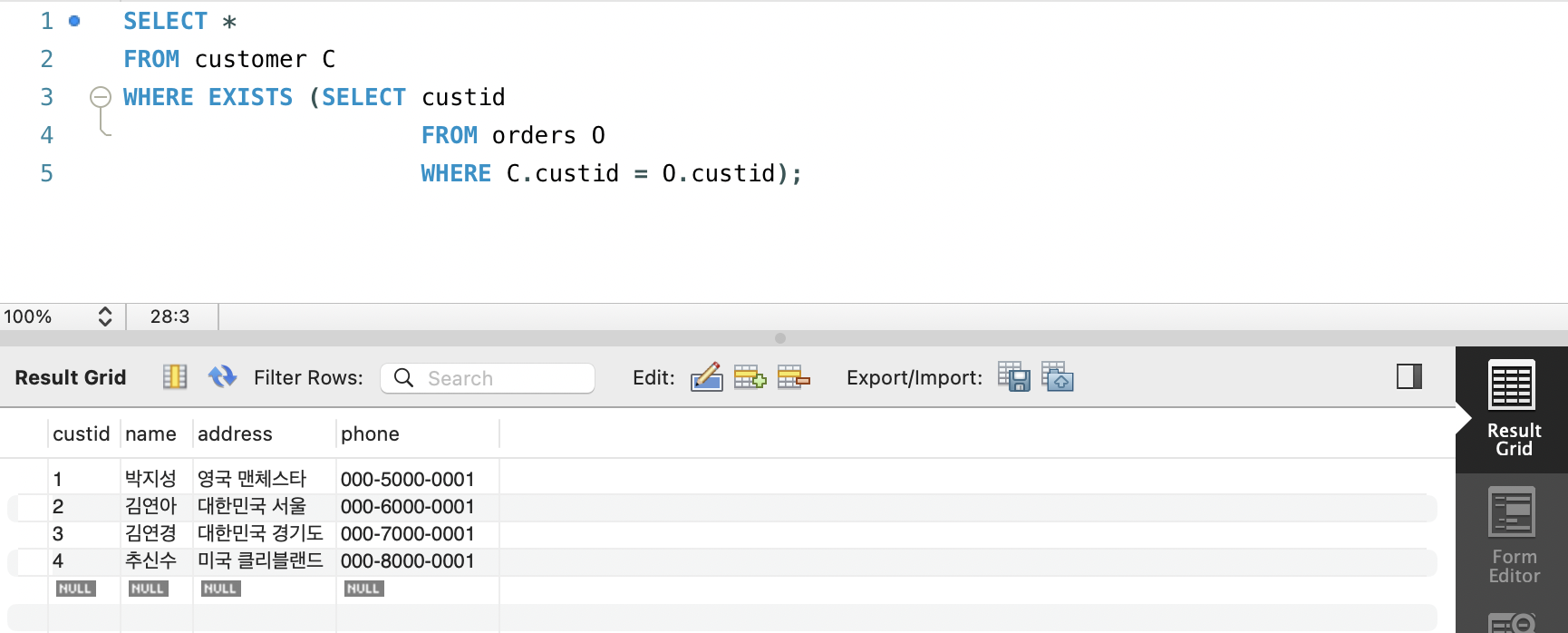
2-2. 스칼라 부속질의 (SELECT 부속질의)
- 부속질의의 결과 값을 단일 행, 단일 열의 스칼라 값으로 반환
- 만약 결과 값이 다중 행이거나 다중 열이면 DBMS는 어떤 행/열을 출력해야하는지 몰라 에러를 출력
- 결과값이 없는 경우에는 NULL 출력
- SELECT 절에서 사용하니 고객별 주문 총횟수/총액과 같은 부분을 출력할 때 사용, 이때 하나의 행에 출력되는 값이니 여러 개일 수 없는 느낌...?
예)
1. GROUP BY 없이
SELECT custid, (SELECT COUNT(*)
FROM orders O
WHERE C.custid = O.custid) AS "주문 횟수"
FROM customer C;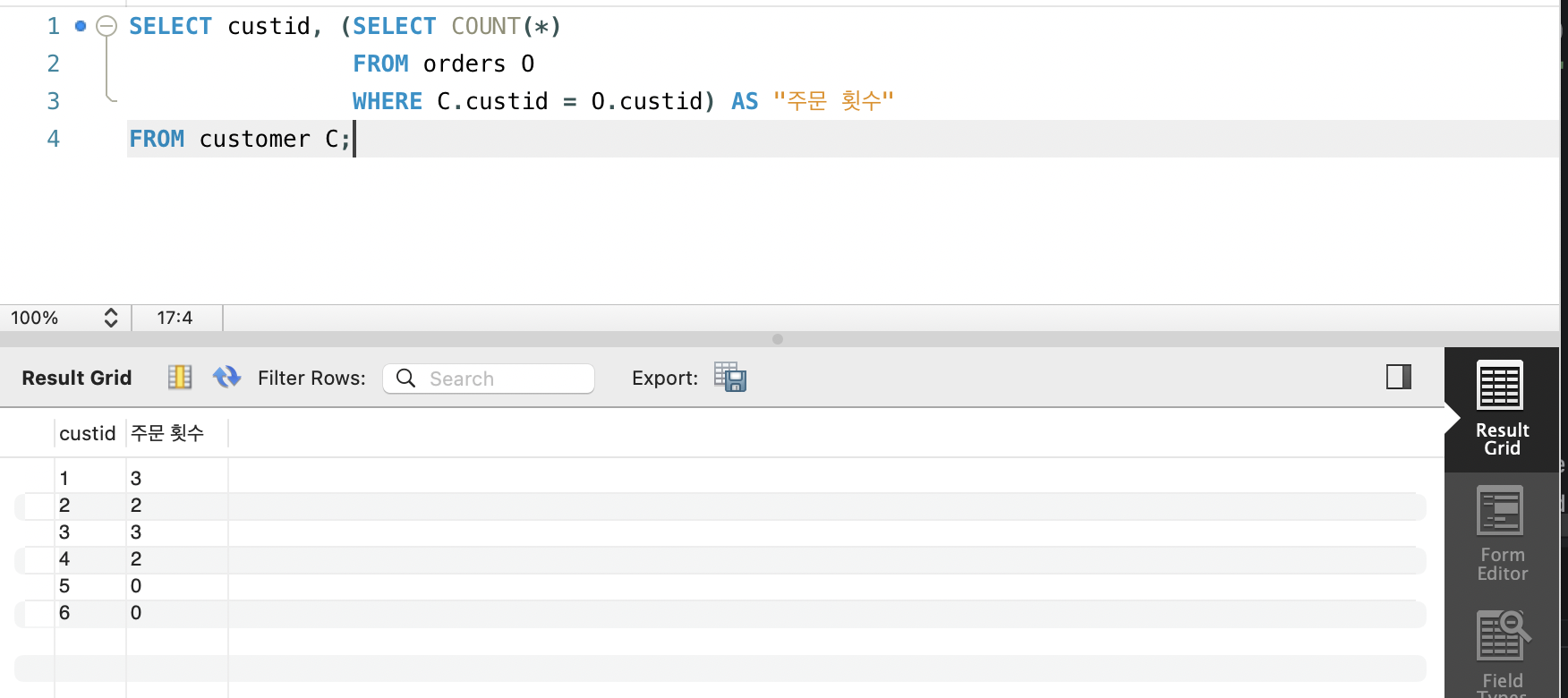
- WHERE 절에서 고객의 주문을 찾고, 주문이 없는 경우 결과가 0이 되는데 이때
GROUP BY가 없이COUNT()를 쓰기에 대상이 없더라도 무조건 0이 됨 - 결과: 주문 안 한 고객의 옆에는 0
2. GROUP BY 있는 상태
SELECT custid, (SELECT COUNT(*)
FROM orders O
WHERE C.custid = O.custid
GROUP BY custid) AS "주문 횟수"
FROM customer C;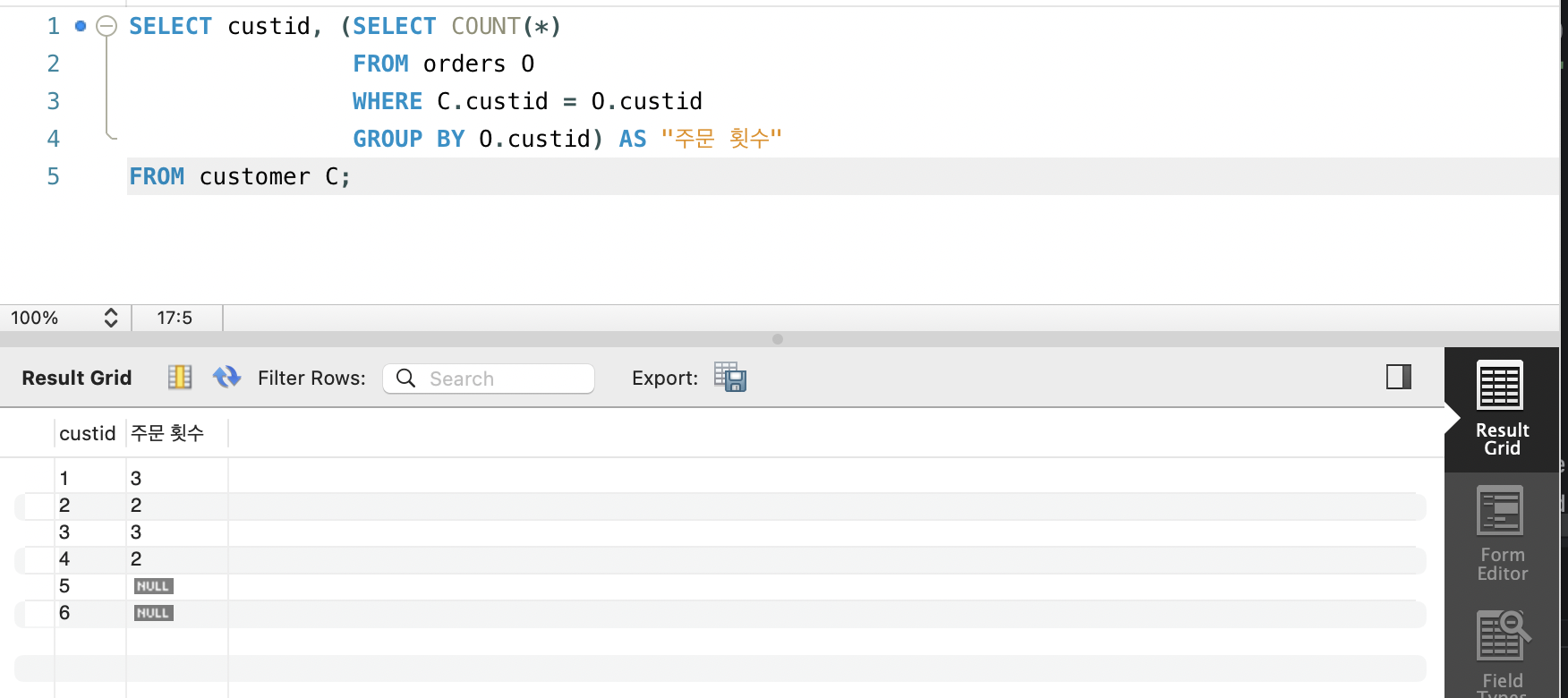
- WHERE절 이후 그룹별로 묶으려고하는데, 이때 주문이 없으면 WHERE절에서 남은 데이터가 하나도 없기에 그룹 자체가 만들어지지 않음
- 그룹이 없으면
COUNT()의 대상도 없기에 아무 행도 반환하지 않음.
UPDATE 문에서의 스칼라 부속질의(SELECT 부속질의)
- 스칼라 부속질의(SELECT 부속질의)는 UPDATE문에서도 사용할 수 있음
SET SQL_SAFE_UPDATES = 0;
UPDATE orders
SET bookname = (SELECT bookname
FROM book
WHERE book.bookid = orders.bookid);
SELECT *
FROM orders;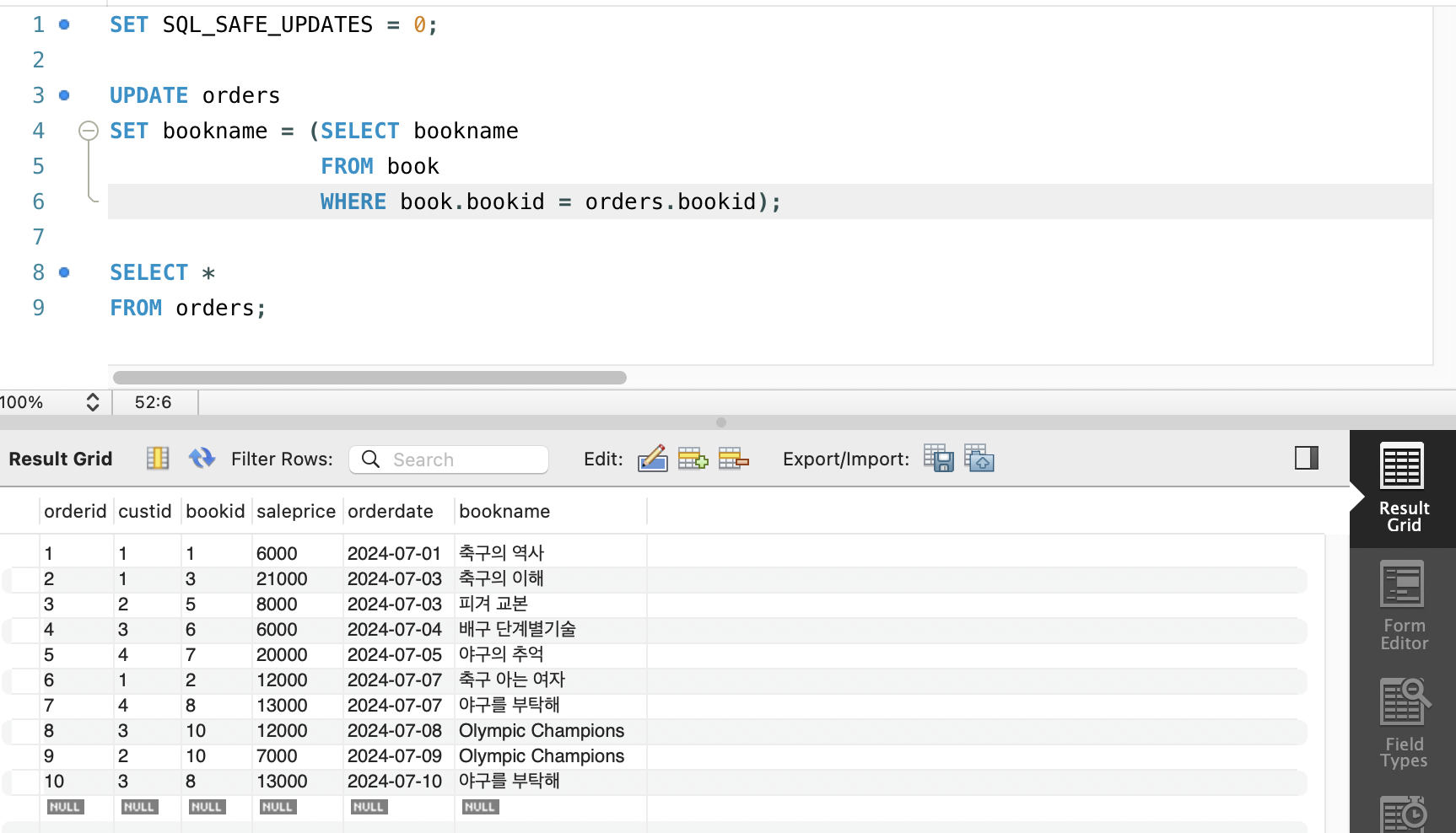
2-3. 인라인 뷰 (FROM 부속질의)
- FROM 절에서 사용되는 부속질의
- 뷰: 기존 테이블로부터 일시적으로 만들어지는 가상의 테이블
예)
SELECT C.name, SUM(o.saleprice) 'total'
FROM (SELECT custid, name
FROM customer
WHERE custid <= 2) C,
orders O
WHERE C.custid = O.custid
GROUP BY C.name;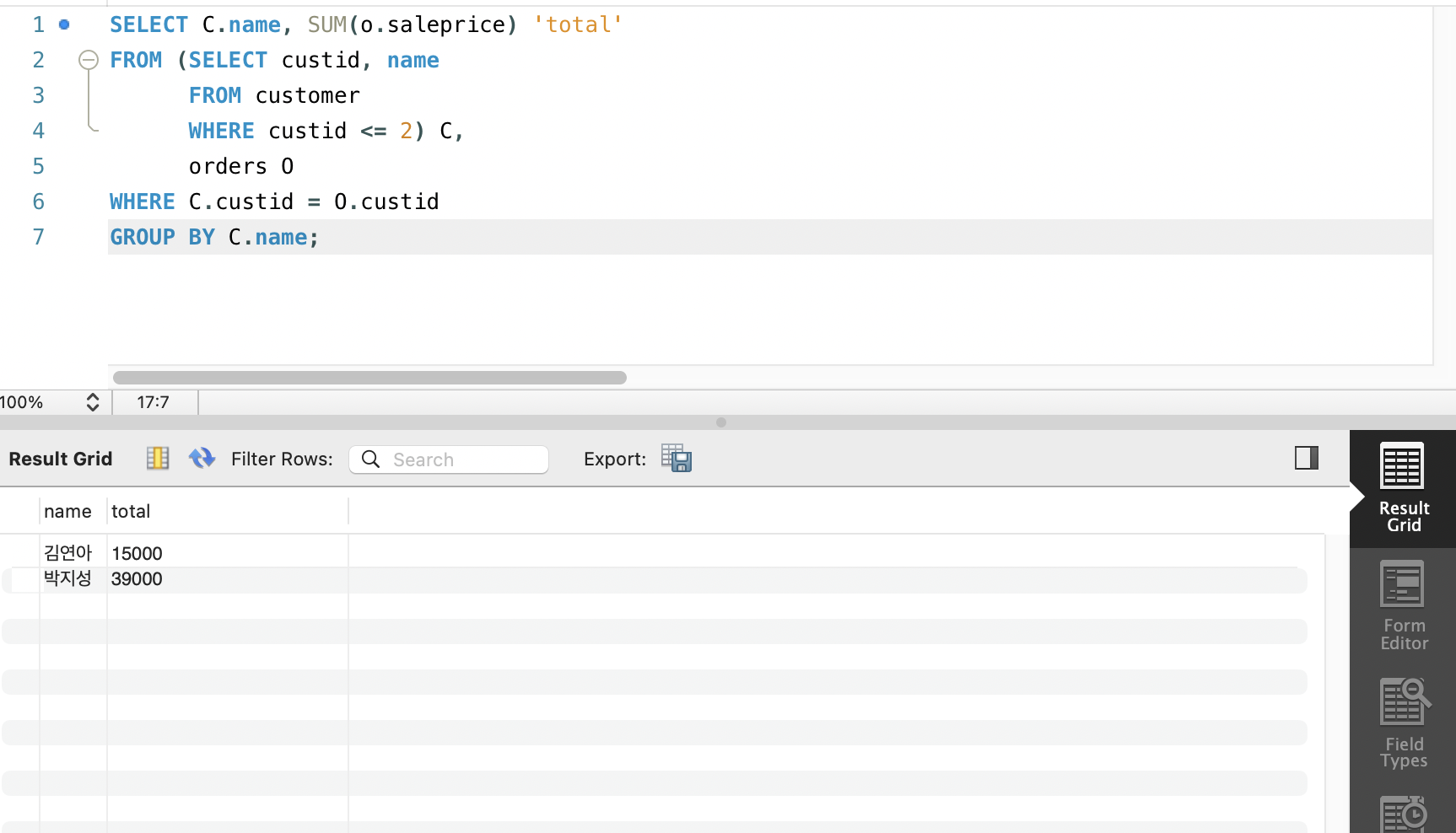
2-4. CTE (Common Table Expression, WITH)
WITH CTE명 AS (SELECT)
- 복잡한 SQL 쿼리 내에서 일시적인 결과 집합 (임시테이블)을 정의하여, 가독성을 높이고 쿼리를 구조화
- 메인 쿼리에서 일반 테이블처럼 재사용하거나, 재귀 쿼리 구현에 활용됨
- 쿼리 실행에만 존재하며 데이터베이스에 영구적으로 저장되지 않음.
WITH CTE이름 AS (
SELECT...
)
#,나 ; 적어주지 않고
#메인 쿼리는 이 아래
SELECT ...
FROM CTE이름;예)
WITH sales_summary AS (
SELECT o.custid, c.name, SUM(o.saleprice) AS total_sales
FROM orders o
JOIN customer c
ON o.custid = c.custid
GROUP BY o.custid
)
SELECT custid, name, total_sales
FROM sales_summary
ORDER BY total_sales DESC;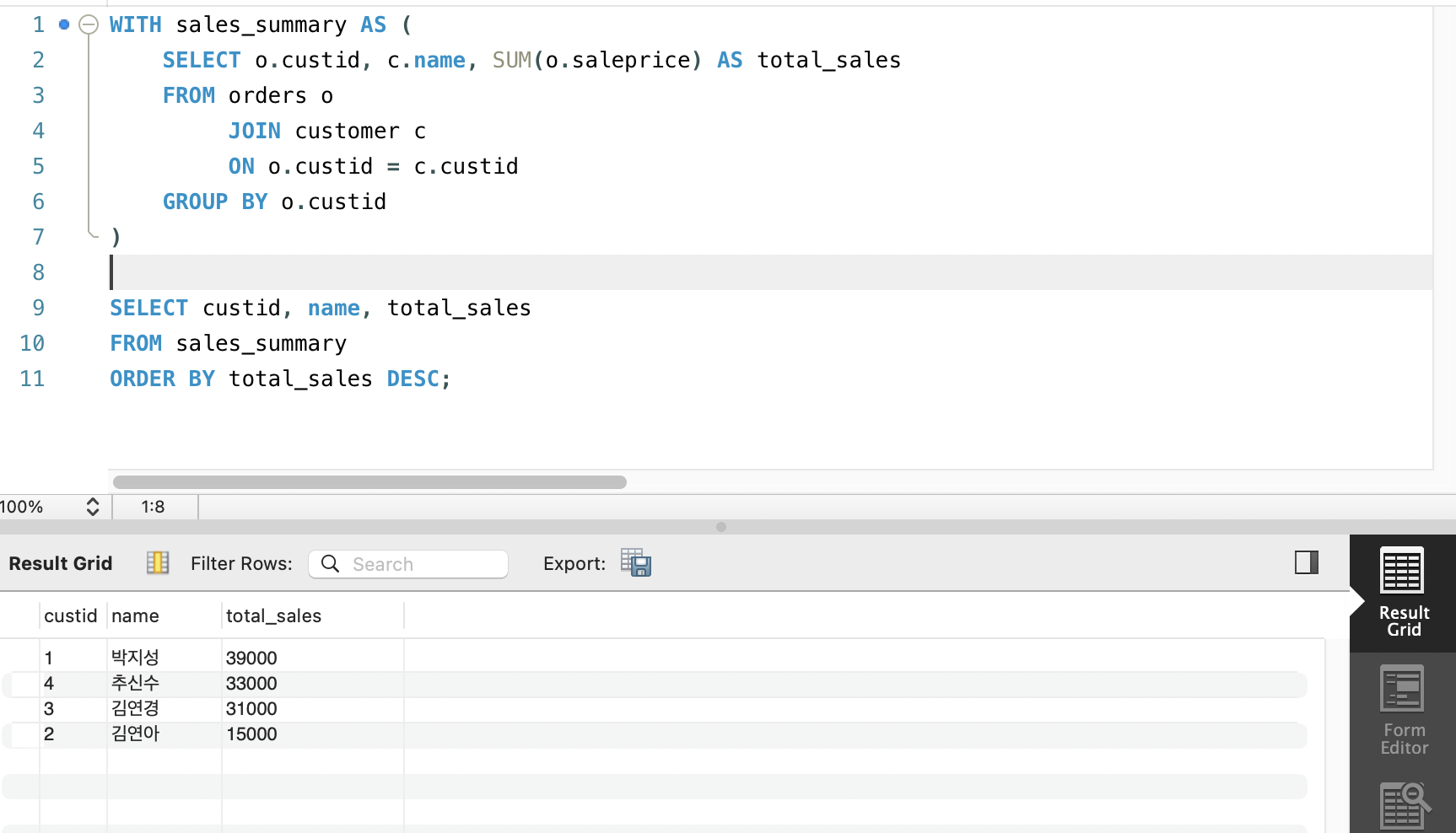
2-5. 윈도우 함수
SQL 윈도우 함수
: 테이블의 행과 행 간의 관계를 정의하여 데이터를 윈도우(틀)로 그룹화하여 사용하는 함수
- 각 행에 대한 집계나 순위 계산 결과를 추가하여 사용
- GROUP BY와 달리 행의 개수를 유지하면서 그룹 내 계산 결과를 각 행에 표시
- 복잡한 조인(JOIN) 없이 행 간 계산, 순위, 누적합계 등을 구할 때 유용
OVER()절과 함께 사용되어 PARTITION BY와 ORDER BY로 범위와 순서 지정
GROUP BY랑 비슷한데 행이 없어지지 않는다...
GROUP BY를 하는 경우에는 여러 개의 행이 그룹별로 묶여 사라지지만, 윈도우 함수를 쓰는 경우에는 행 옆에 계산 결과를 붙여주는 식.
SELECT 함수명() OVER (PARTITION BY 컬럼명 ORDER BY 컬럼명)
FROM 테이블명;
- PARTITION BY: 계산을 수행할 그룹을 나눔
- ORDER BY: 그 그룹 안에서 계산을 수행할 순서
주요 윈도우 함수 유형
1. 순위함수
ROW_NUMBER(): 줄 세우기 (1,2,3,4...)RANK(): 공동 순위만큼 건너뛰기 (1,2,2,3...)DENSE_RANK(): 공동순위가 있어도 촘촘하게 (1,2,2,3,...)
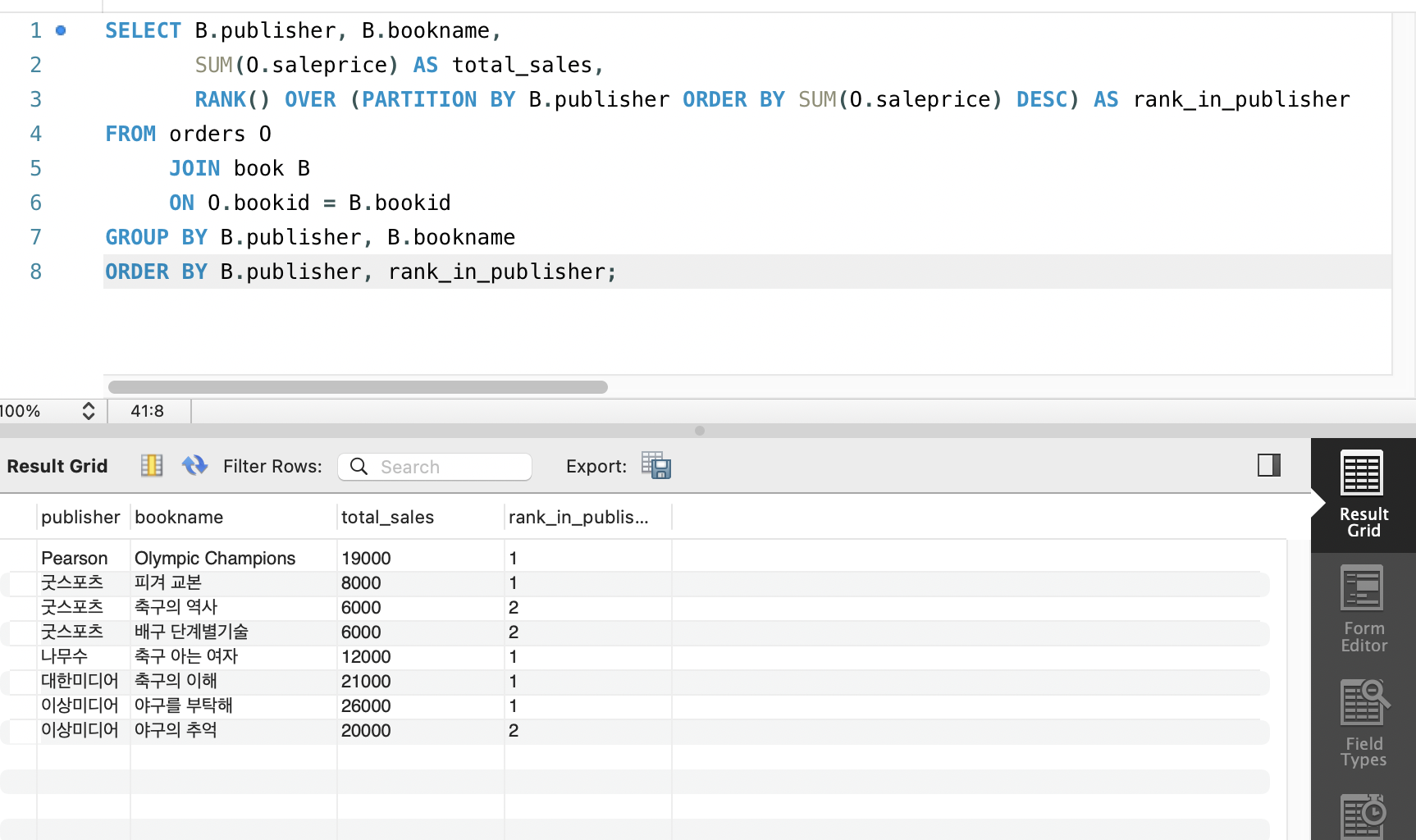
SELECT B.publisher, B.bookname,
SUM(O.saleprice) AS total_sales,
DENSE_RANK() OVER (PARTITION BY B.publisher ORDER BY SUM(O.saleprice) DESC) AS rank_in_publisher
FROM orders O
JOIN book B
ON O.bookid = B.bookid
GROUP BY B.publisher, B.bookname
ORDER BY B.publisher, rank_in_publisher;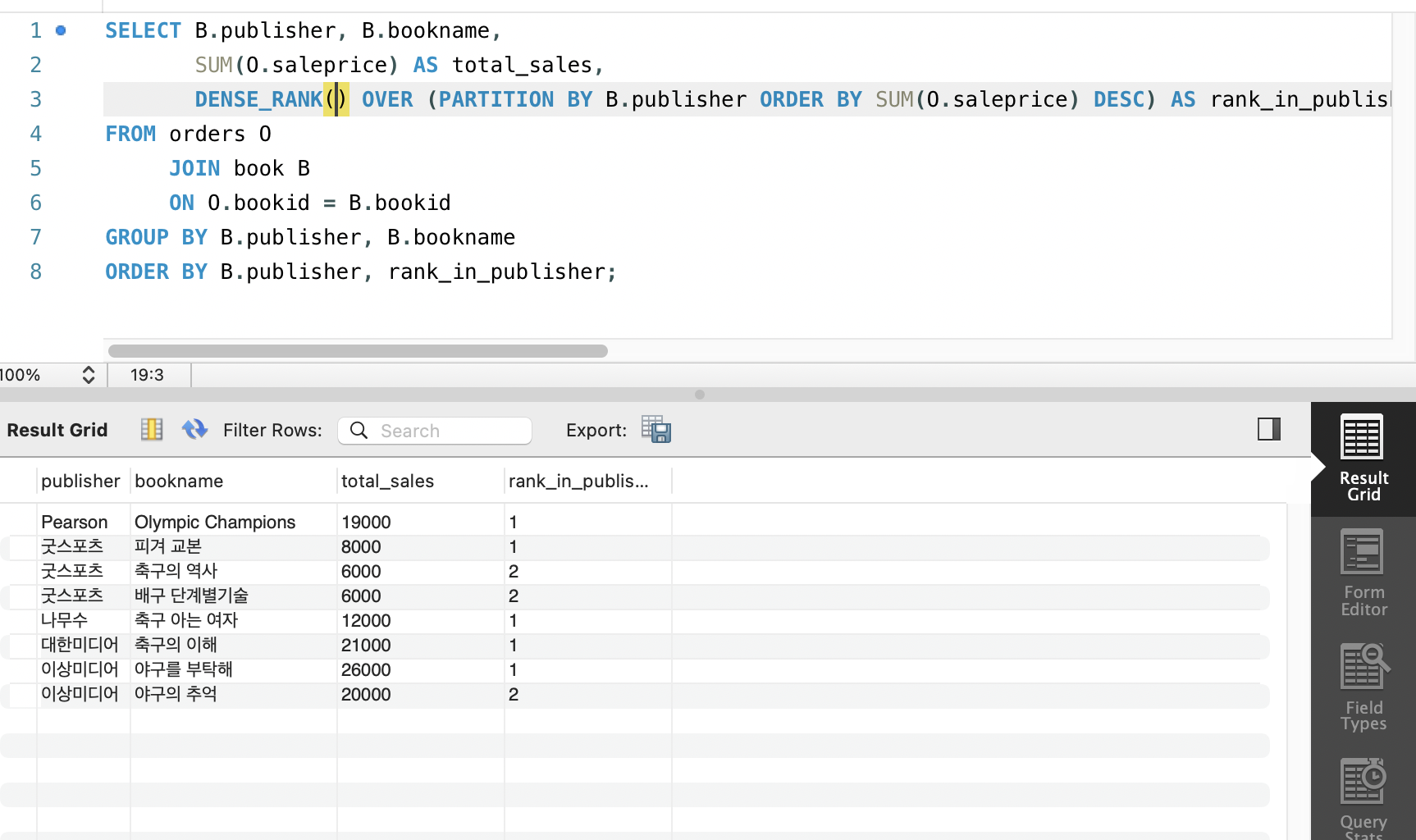
2. 집계함수
-
누적 합계를 구할 때 편함.
-
순위함수(Ranking): ROW_NUMBER(), RANK(), DENSE_RANK()
-
집계함수(Aggregate): SUM(), AVG(), COUNT(), MAX(), MIN()
-
분석/값 함수(Value): LEAD(), LAG(), FIRST_VALUE(), LAST_VALUE()...
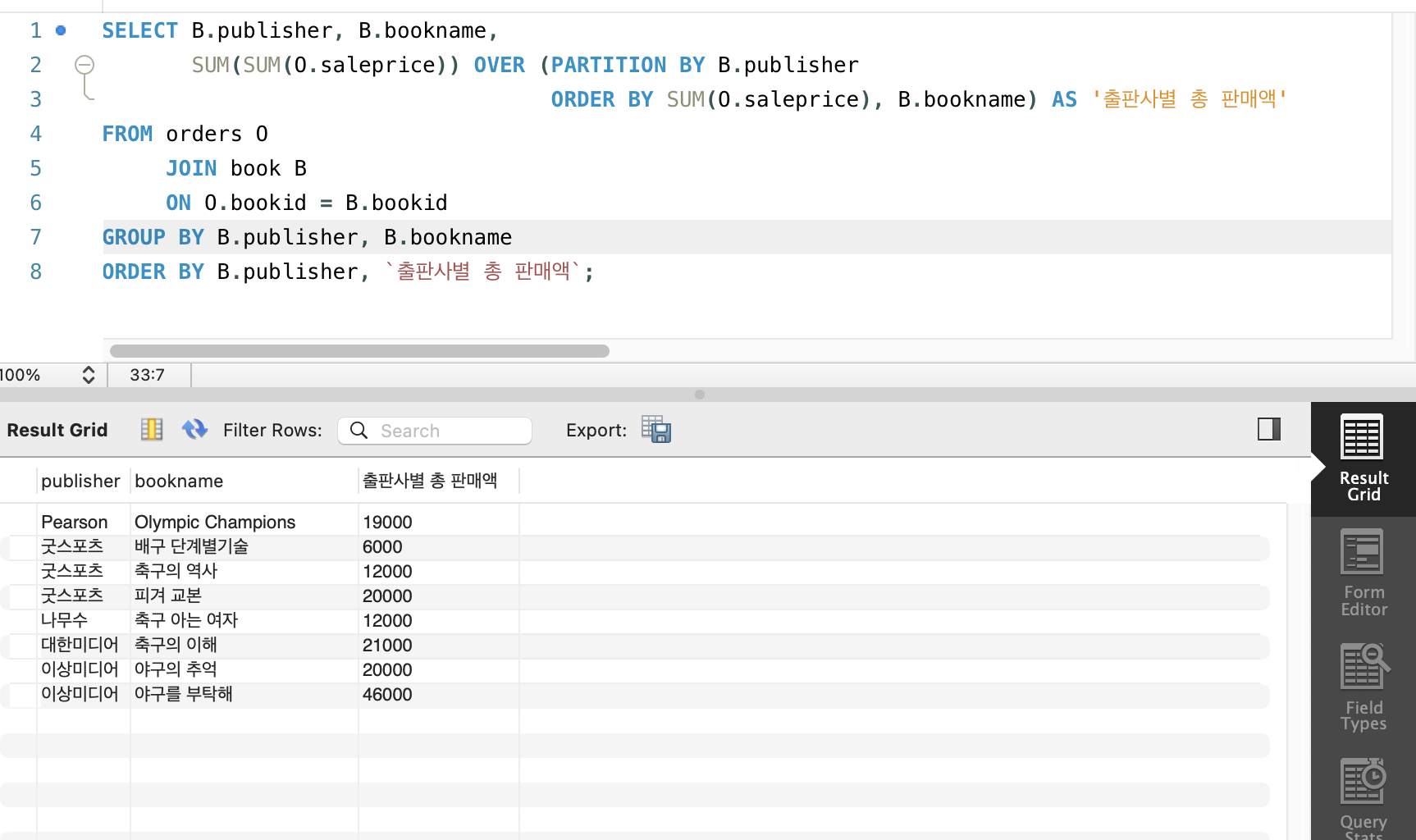
예) 출판사별로 saleprice 누적합 구하기
SELECT B.publisher, B.bookname,
SUM(SUM(O.saleprice)) OVER (PARTITION BY B.publisher
ORDER BY SUM(O.saleprice), B.bookname) AS '출판사별 총 판매액'
FROM orders O
JOIN book B
ON O.bookid = B.bookid
GROUP BY B.publisher, B.bookname
ORDER BY B.publisher, `출판사별 총 판매액`;orders와 book 조인 -> 출판사, 책 이름 별로 그루핑 출판사-책이름-그 책의 총판매액: SUM(O.saleprice) -> 윈도우 함수 안에서 PARTITION BY를 통해 출판사별로 분리, 출판사별 SUM(O.saleprice) 계산. -> ORDER BY 통해 책별 총판매액 & 책이름으로 정렬 (같은 가격이어도 분리되어서 나오게) -> 외부 ORDER BY에 윈도우 함수 결과 속성 추가해서 정렬결과대로 보기.
SUM(SUM(O.saleprice)
- 안쪽 SUM: GROUP BY 결과로 나온 책 한 권의 합계
- 바깥 SUM: 윈도우 함수가 만드는 출판사 내의 누적 합계
3. 분석/값 함수
- 이전 행이나 다음 행의 데이터를 가져올 때
- JOIN 없이도 어제와 오늘의 차이를 계산할 수 있음
LAG(컬럼): 현재 행보다 이전(뒤에있는) 행의 값을 가져옴 (과거)LEAD(컬럼): 현재 행보다 다음(앞에있는) 행의 값을 가져옴 (미래)