이론 정리 및 실습을 하나의 파일에 정리하였습니다.
3. 뷰
3-1. 뷰(View)의 생성
뷰(view): 하나 이상의 테이블을 합해 만드는 가상의 테이블
- 실제 데이터는 저장하지 않고, SELECT 쿼리의 결과에 이름을 붙여 재사용하는 객체
CREATE VIEW <뷰의 이름> [열이름...]
AS <SELECT문...>특징
- 데이터 보안- 특정 컬럼만 노출하도록 설정 가능
- 재사용성: 복잡한 쿼리를 뷰를 통해 재사용하며 단순화 가능
- 독립성: 기본 테이블의 구조를 변경해도 뷰를 통해 동일한 인터페이스를 제공
- 읽기 전용이 기본이지만, 일부의 경우에는 테이블 업데이트 역시 가능
예) 뷰의 생성
CREATE VIEW view_book
AS SELECT *
FROM book
WHERE bookname LIKE '%축구%';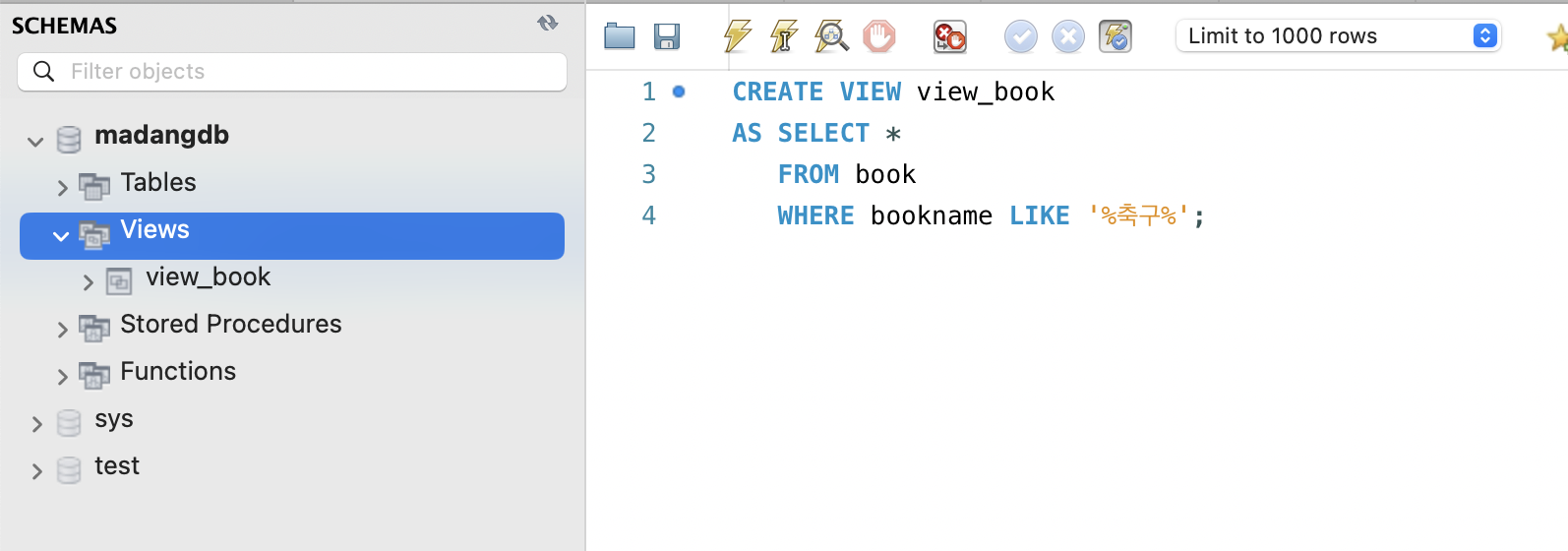
schemas 아래에 있는 view에서 생성된 뷰를 확인할 수 있다.
뷰의 생성 후에는 아래처럼 설정한 뷰의 이름을 통해 해당 뷰를 사용할 수 있음
CREATE VIEW order_books
AS SELECT B.bookid, B.bookname, B.price, B.publisher
FROM book B JOIN
orders O ON B.bookid =O.bookid;
SELECT publisher, SUM(price) AS '출판사별 수익'
FROM order_books
GROUP BY publisher;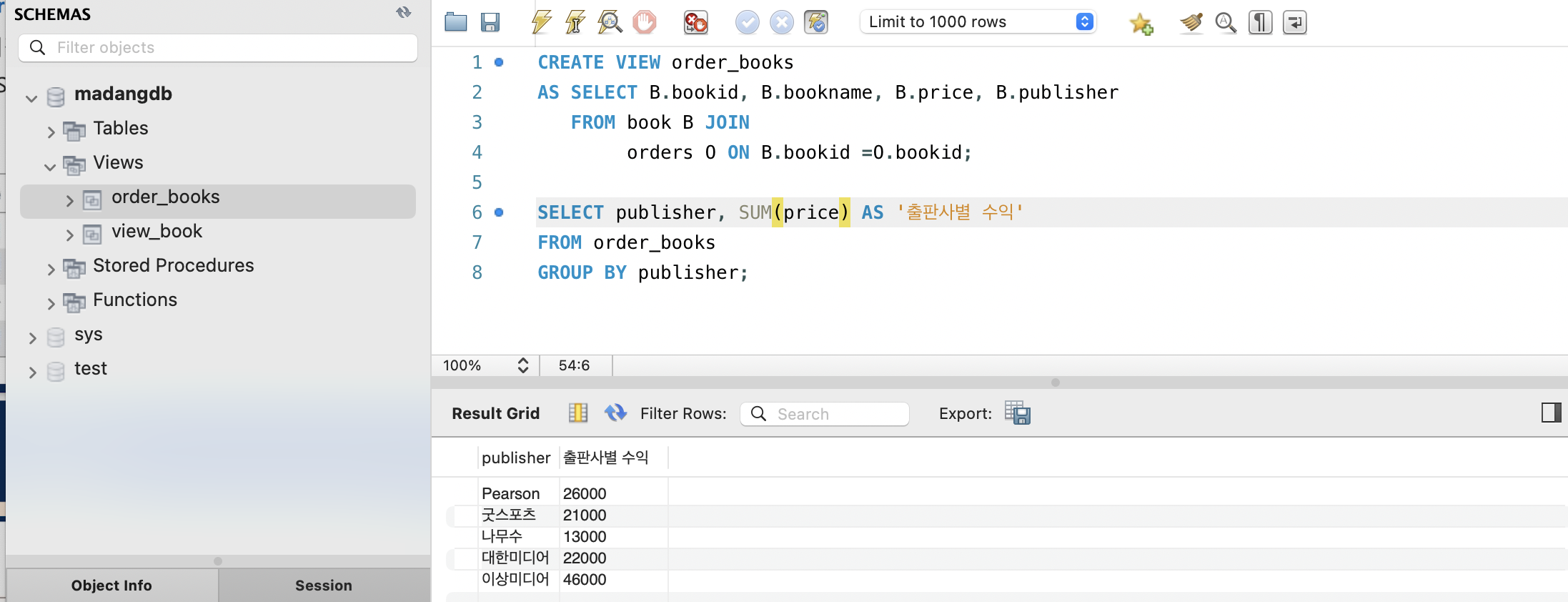
뷰의 장점 및 특징
장점
- 편리성 및 재사용성: 자주 사용되는 복잡한 질의를 뷰로 미리 정의해두고 사용할 수 있음
- 보안성: 사용자별로 필요한 데이터만 선별하여 보여줄 수 있고, 중요한 질의의 경우, 질의 내용을 암호화하는 것도 가능
예) 개인정보(주민번호)나 급여, 건강 같은 민감 정보를 제외한 뷰를 생성해 사용 - 독립성: 원본 테이블의 구조가 변해도 응용(사용)에 영향을 주지 않도록함
-> 논리적 데이터 독립성 제공 방법
특징
- 원본 데이터 값에 따라 같이 뷰의 값이 변함
- 독립적인 인덱스 생성이 어려움
- 삽입/삭제/갱신 연산에 많은 제약 존재 (읽기 전용이 대다수)
3-2. 뷰의 수정
REPLACE
뷰의 수정을 위해서는 CREATE VIEW 문에 REPLACE 명령을 추가.
CREATE OR REPLACE VIEW <뷰 이름>
AS <SELECT 문>생성하거나 수정한다는 의미.
예) 앞에서 사용한 뷰에서 주문고객 정보까지 뷰에 포함하도록 수정
CREATE OR REPLACE VIEW order_books
AS SELECT B.bookid, B.bookname, B.price, B.publisher, C.custid
FROM book B JOIN
orders O ON B.bookid = O.bookid JOIN
customer C ON C.custid = O.custid;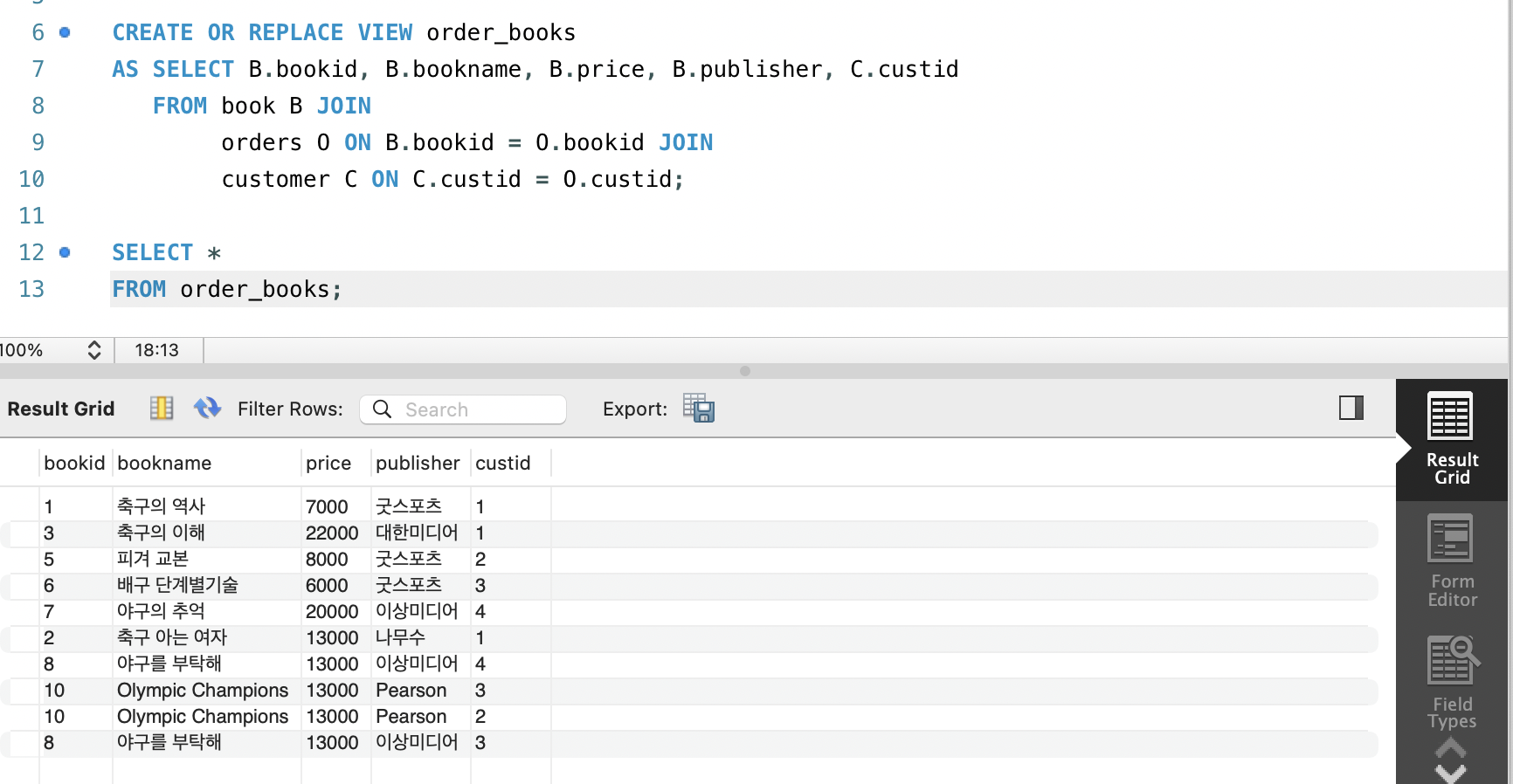
DROP
뷰를 삭제하기 위해서는 DROP 명령어를 사용함
DROP VIEW <뷰 이름> 예)
DROP VIEW order_books;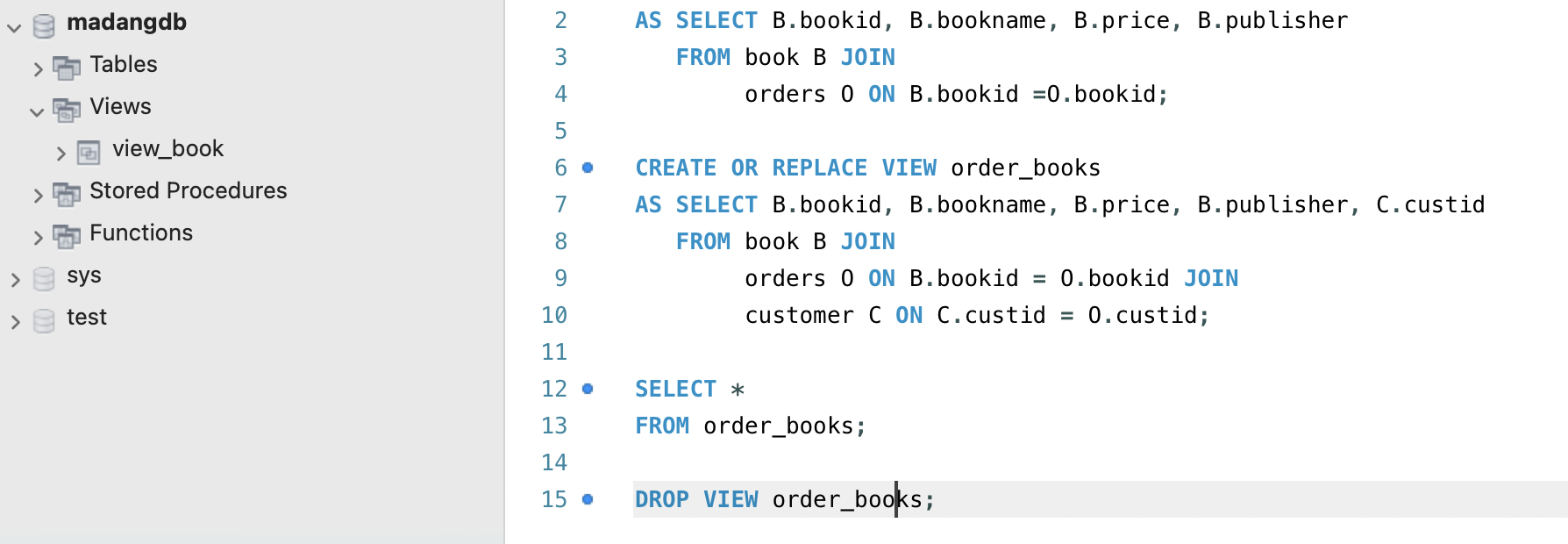
왼쪽의 Views에서 order_books가 사라진 것을 볼 수 있다.
3-3. 뷰의 활용
일반적으로 뷰는 읽기 전용이지만,. DISTINCT, GROUP BY 등의 제약이 없다면 변경이 가능하다
뷰의 활용: INSERT, UPDATE, DELETE 문
- 뷰에 대한 삽입/수정/삭제 연산은 제한적으로 수행된다.
- 실제로 기본 테이블에 연산이 수행되니, 결과적으로 기본 테이블이 변경되는 것- 변경 가능한 뷰와 불가능한 뷰가 존재한다
변경이 불가능한 뷰의 특징
- 기본 테이블의 기본키를 구성하는 속성이 포함되어 있지 않은 뷰
- 기본 테이블에서 NOT NULL로 지정된 속성이 포함되어있지 않은 뷰
- 기존 테이블에 있던 내용이 아닌 집계함수로 새로 계산된 내용을 포함하는 뷰
- DISTINCT 키워드를 포함해 정의한 뷰
- GROUP BY 절을 포함해 정의한 뷰
- 여러 개의 테이블을 조인해 정의한 뷰는 변경이 불가능한 경우가 많음.
예) 변경이 불가능한 뷰의 예
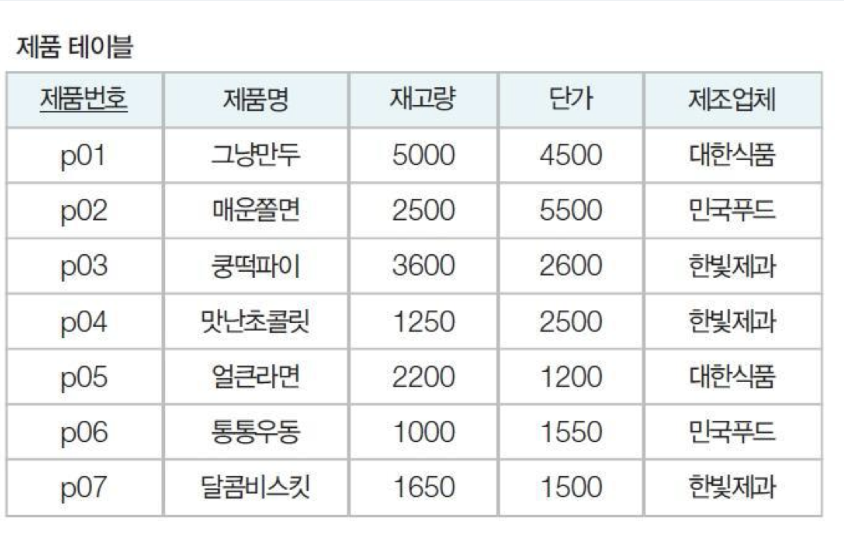
View1
CREATE VIEW view1
AS SELECT 제품번호, 재고량, 제조업체
FROM 제품;
기본 테이블의 기본키인 제품번호를 포함하고 있기에 변경 가능.
(기본키 속성은 NOT NULL)
View2
CREATE VIEW view2
AS SELECT 제품명, 재고량, 제조업체
FROM 제품;기본 테이블의 기본 키를 구성하는 속성이 포함되어 있지 않아 변경이 불가능함.
만약, 변경을 허용하는 경우 기본 키 속성의 값이 NULL이 되기에 안됨.
뷰에 데이터 삽입하기
INSERT INTO view1 VALUES ('p08', 1000, '신선식품');INSERT문은 기존 테이블에 작성하듯이 작성한다.
이 연산은 실제로는 기본 테이블(제품 테이블)에 수행 되기에 새로운 제품에 대한 튜플이 제품 테이블에 삽입된다.
슬라이드 60p. 실습12
(1) 판매가격이 20,000원 이상인 도서의 도서번호, 도서이름, 고객이름, 출판사, 판매가격을 보여주는 highorders 뷰 생성하기
CREATE VIEW highorders
AS SELECT B.bookid, B.bookname, C.name, B.publisher, B.price
FROM book B JOIN
orders O ON B.bookid = O.bookid JOIN
customer C ON C.custid = O.custid
WHERE B.price >= 20000;(2) 생성한 뷰를 이용하여 판매된 도서의 이름과 고객의 이름을 출력하는 SQL문 작성하기
SELECT bookname, name
FROM highorders;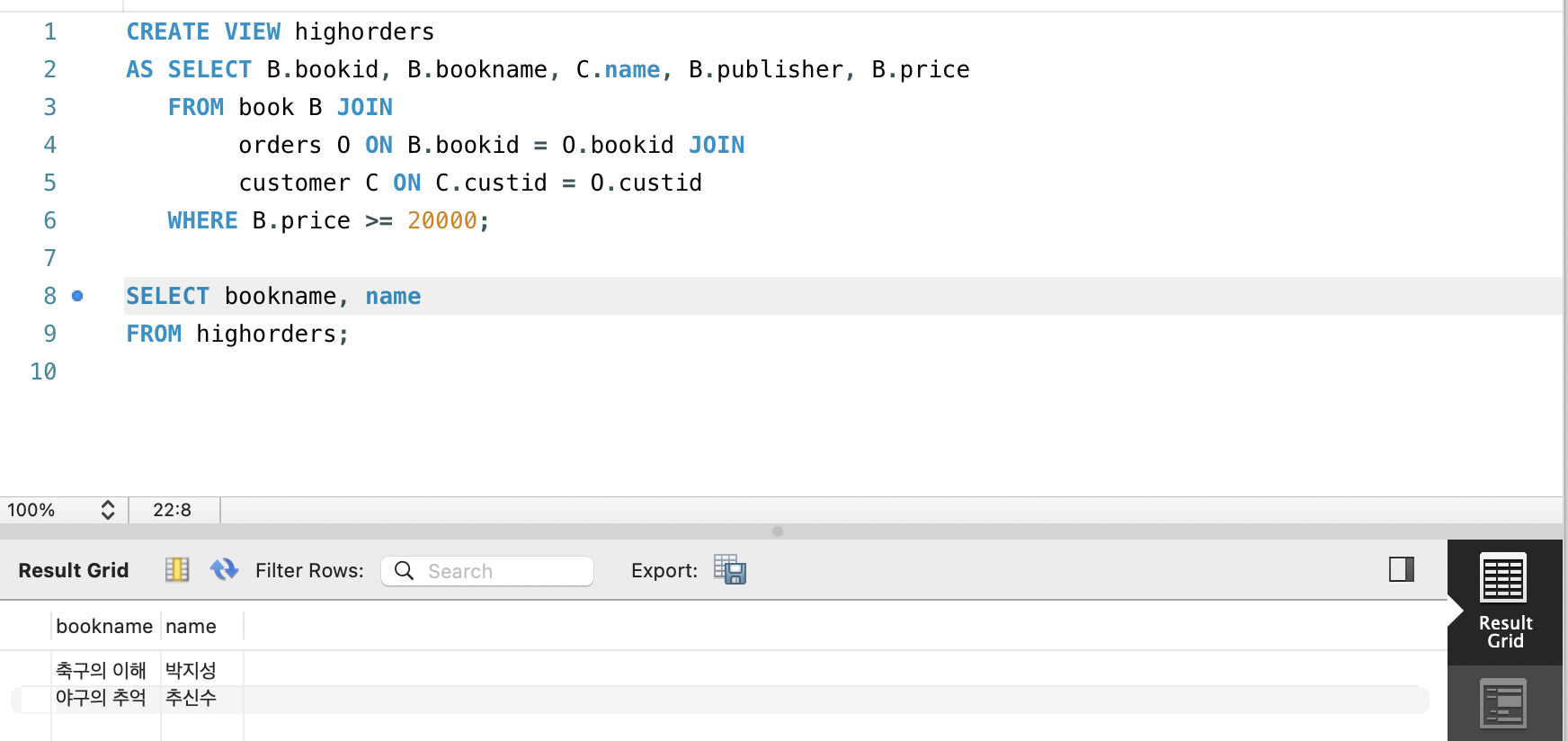
(3) highorders 뷰를 변경하고자한다. 판매가격 속성을 삭제하는 명령을 수행하시오. 삭제 후 (2)번 SQL문 재수행.
CREATE OR REPLACE VIEW highorders
AS SELECT B.bookid, B.bookname, C.name, B.publisher
FROM book B JOIN
orders O ON B.bookid = O.bookid JOIN
customer C ON C.custid = O.custid
WHERE B.price >= 20000;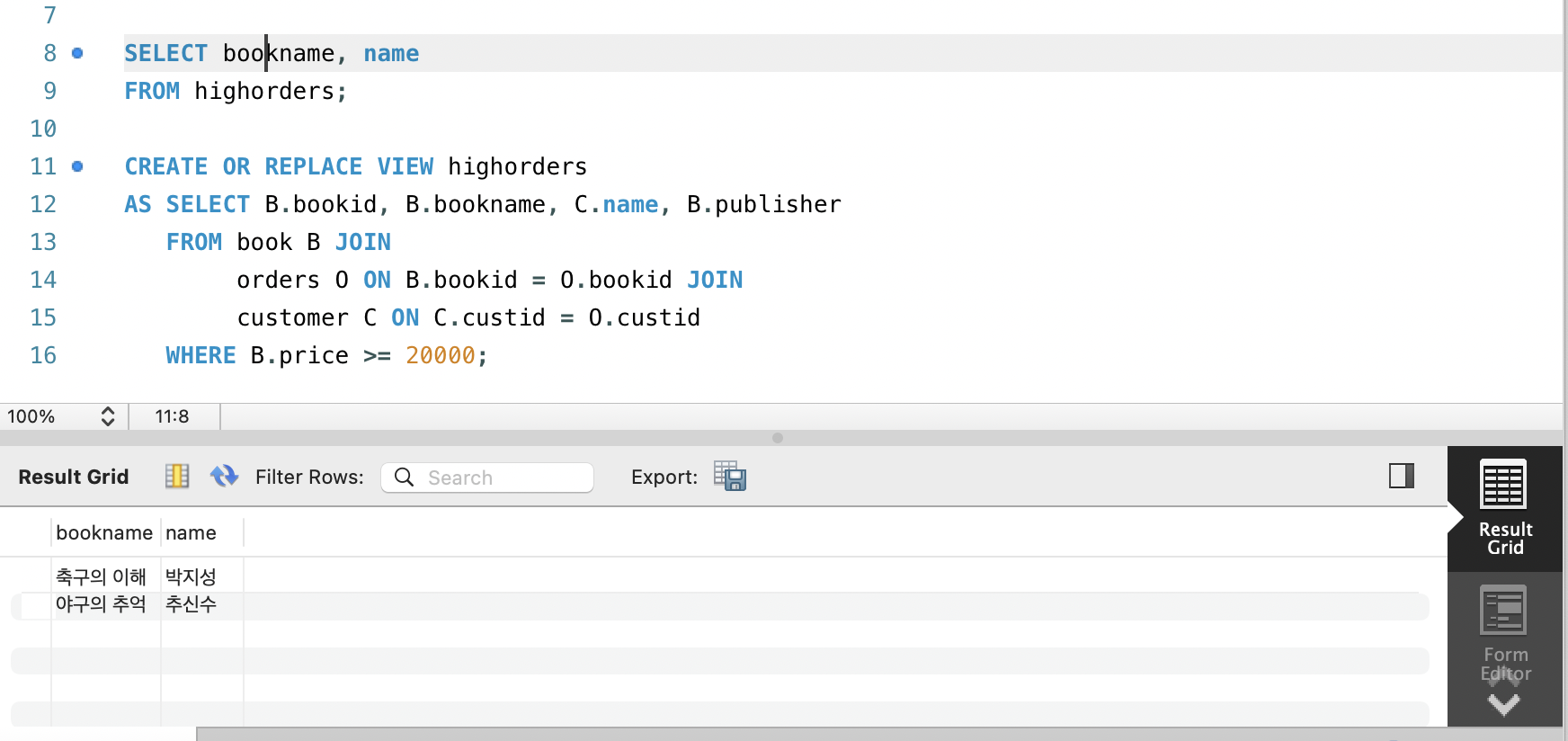
4. 인덱스
4-1. 데이터베이스의 물리적 저장
데이터베이스의 경우 각 DBMS 만의 고유한 방식으로 테이블에 저장되는 데이터를 저장함.
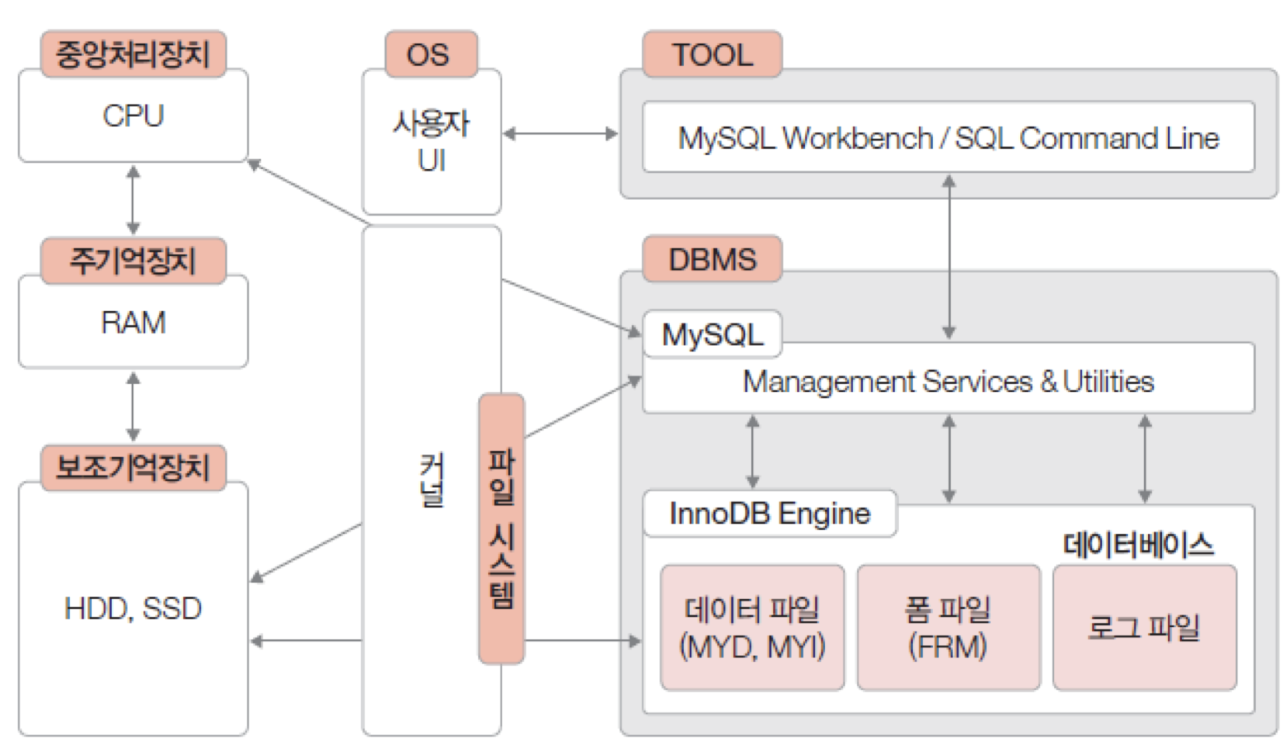
DBMS가 하드디스크에 데이터를 저장하고 읽어오면 속도가 느리기에, 주기억장치에 사용하는 공간 중 일부를 버퍼 풀로 만들어 사용함. 데이터 검색 시 이 버퍼 풀에 저장된 데이터를 우선 읽어들여 작업을 진행함.
SHOW VARIABLES LIKE 'datadir'를 통해 데이터베이스가 저장된 위치를 알아볼 수 있음
4-2. 인덱스와 B-tree
인덱스
데이터를 쉽고 빠르게 찾을 수 있도록 만든 데이터 구조로, 일반적인 RDBMS의 인덱스는 대부분 B-tree(B+Tree) 구조로 이루어져 있음.
B-tree
- 데이터 검색 시간을 단축하기 위한 자료구조
- B-tree의 각 노드는 키값과 포인터를 가짐
- 루트노드, 내부노드, 리프노드로 구성
- 리프노드가 같은 레벨에 존재하는 균형 트리
- 리프노드에는 해당 데이터의 저장 위치에 대응하는 정보가 있어 빠르게 검색할 수 있음.
- B Treed와 B-Tree는 balanced tree.
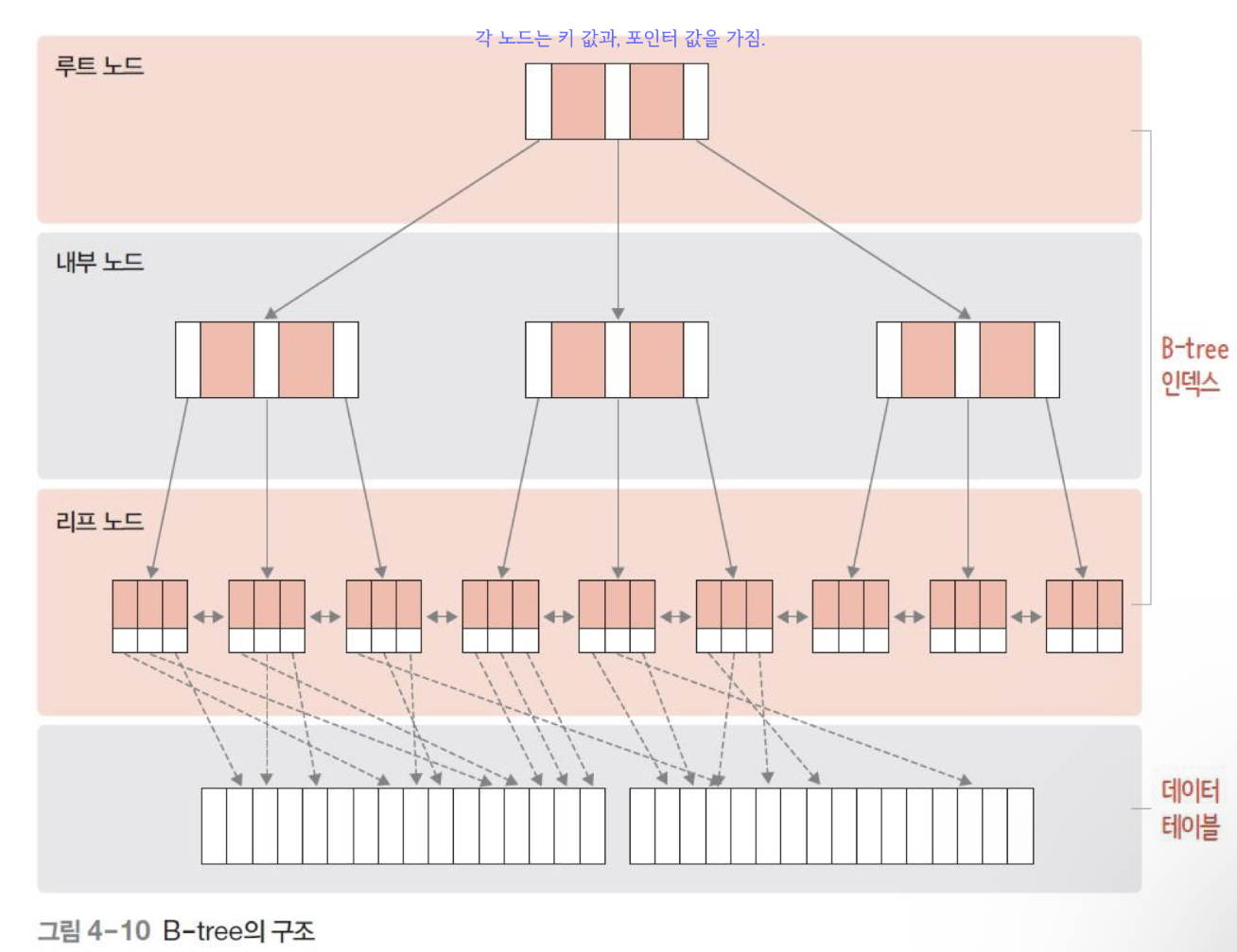
- B-tree에서의 검색: 루트 노드에서부터 값을 비교 -> 중간 단계(내부 노드)에서 해당 노드를 찾음 -> 최종적으로 마지막 레벨인 리프 노드에 도달
인덱스의 특징
- 인덱스는 테이블에서 한 개 이상의 속성을 이용해 생성
- 빠른 검색과 효율적인 레코드 접근이 가능
- 순서대로 정렬된 속성과 데이터의 위치만 보유하기에 테이블보다 작은 공간 차지
- 저장된 값들은 테이블의 부분집합이 됨
- 데이터에서 수정, 삭제 등의 변경이 발생하면 인덱스를 재구성해야함.
4-3. MySQL의 인덱스
MySQL의 인덱스는 클러스터 인덱스와 보조 인덱스로 나뉨
클러스터 인덱스
- 테이블 자체가 인덱스 구조로 되어있어, 데이터가 인덱스 키 순서대로 물리적 저장됨
- 기본키 생성 시 자동으로 생성
특징
- 테이블 당 하나만 존재
- 키 값이 정렬되어 특정값, 범위 검색에 유리
- 기본키 기반 검색이 매우 빠름
- 검색 성능은 뛰어나지만, 키 변경/삽입 시 성능 부담
보조 인덱스
- 클러스터 인덱스가 아닌 모든 인덱스
- InnoDB에서는 PK(기본키)가 클러스터 인덱스이고, 나머지는 모두 보조 인덱스임.
특징
- 데이터 자체를 정렬하지 않고, 테이블 당 여러 개를 만들 수 있음
- 인덱스 키와 해당 레코드의 기본키값을 저장해 검색될 수 있게 함
- 즉, 인덱스의 리프 노드 = 테이블 상 데이터 위치를 지정하는 row id
MySQL 인덱스
클러스터 인덱스와 보조 인덱스를 동시에 사용하는 검색.
예) 기본키인 bookid는 클러스터 인덱스, 외에 추가적으로 bookname을 보조 인덱스로 설정
비교 정리
| 인덱스 명칭 | 설명/생성 예 |
|---|---|
| 클러스터 인덱스 | - 기본적인 인덱스. 테이블 생성 시 기본 키 지정하면, 기본 키에 대해 클러스터 인덱스를 생성. - 기본키 지정하지 않을 시에는 먼저 나오는 UNIQUE 속성에 대해 생성 - 기본키/UNIQUE 모두 없을 시에는 MySQL 자체 생성 행번호로 생성 - 테이블 당 1개만 생성 |
| 보조 인덱스 | - 클러스터 인덱스 외 모든 인덱스. 각 레코도는 보조 인덱스의 속성과 기본키 속성값을 가짐 - 보조 인덱스 검색 -> 기본 키 속성을 찾음 -> 이후 클러스터 인덱스로 가서 해당 레코드를 찾는 방식. -테이블 당 여러 개를 생성할 수 있음 |
4-4. 인덱스의 생성
의미없이 인덱스를 생성할 경우에는 오히려 검색속도가 더 느려지고 공간이 낭비됨
인덱스 생성 전 고려사항
- 인덱스는 WHERE절에서 자주 사용되는 속성이어야함
- 인덱스는 JOIN에 자주 사용되는 속성이어야함
- 단일 테이블에 인덱스가 많으면 속도가 느려질 수 있음 (테이블 당 4-5개 권장)
- 속성이 가공되는 경우에는 사용X
예) YEAR(birth) = 2026- 속성의 선택도가 낮을 때 유리 ( 즉, 속성의 모든 값이 다른 경우)
예) 주민번호 - 선택도가 낮음 (고유한 값, 중복 없음),
성별 - 선택도 높음 (중복 많음)
인덱스 생성 방법
CREATE [UNIQUE] INDEX [인덱스 이름]
ON <테이브 이름> (컬럼 [ASC|DESC], ...)- UNIQUE: 테이블 속성값에 대해 중복이 없는 유일한 인덱스를 생성하는 것
- ASC |DESC: 컬럼 값의 정렬 방식 의미.
예)
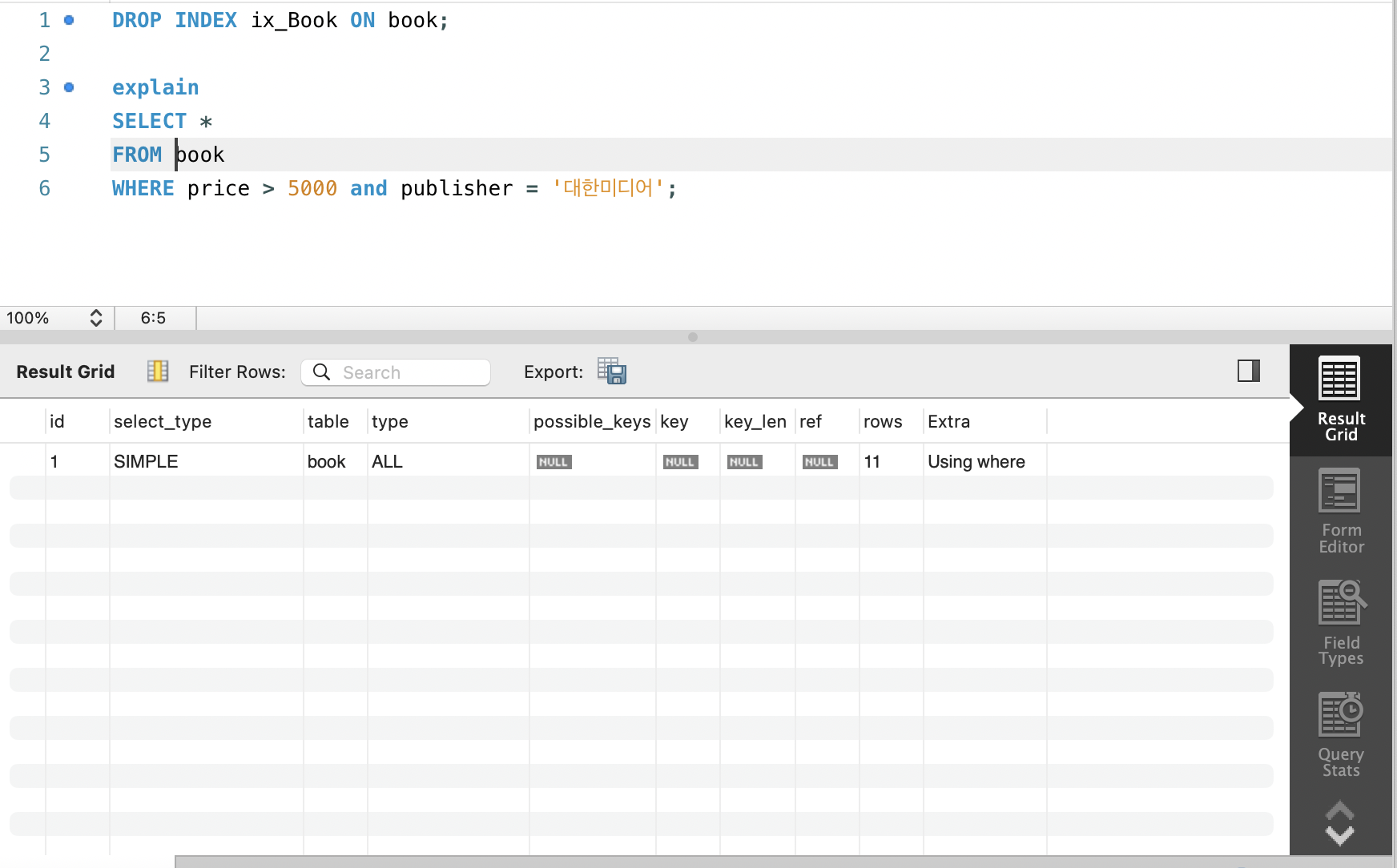
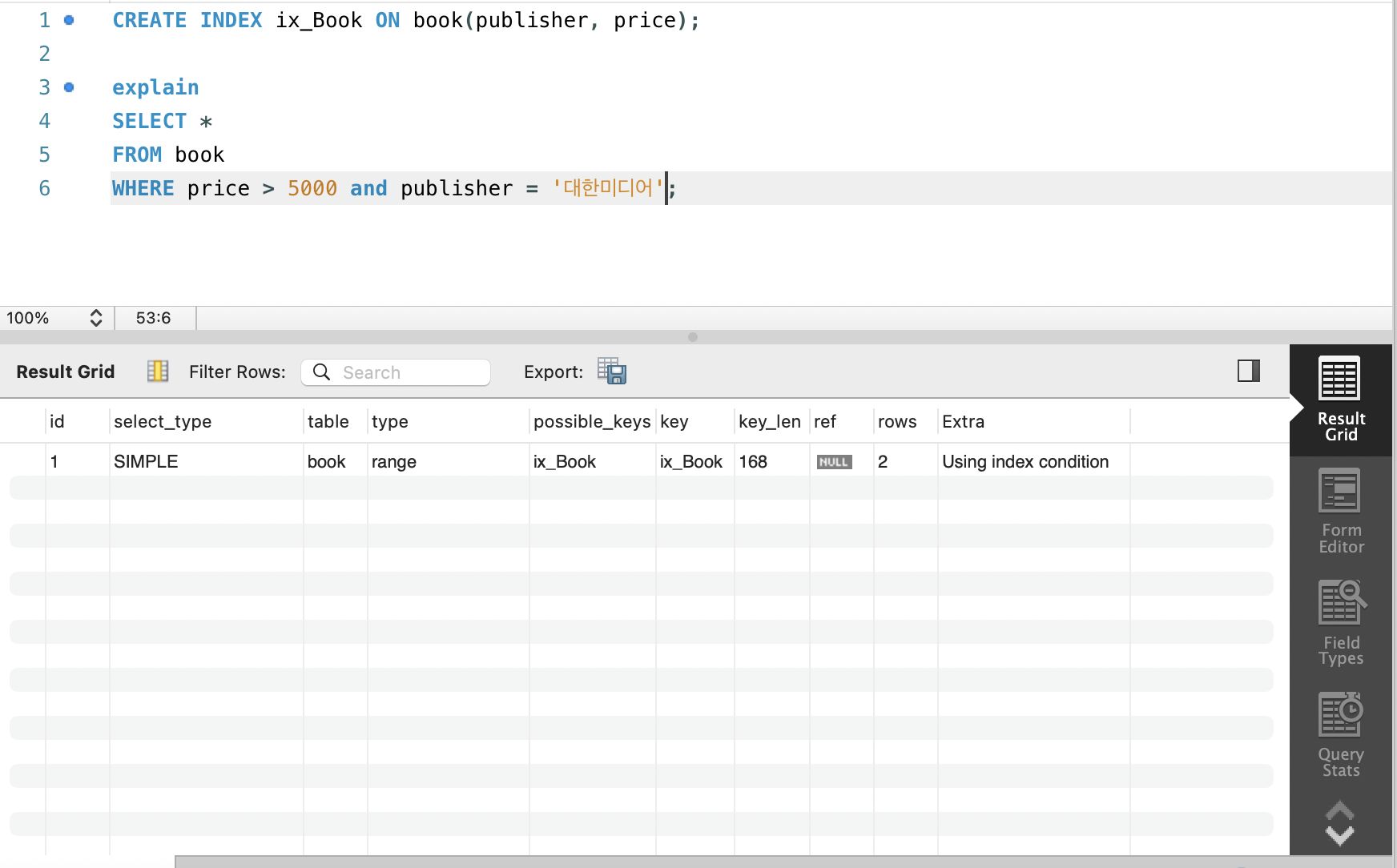
CREATE INDEX ix_Book ON book(publisher, price);인덱스 미사용
인덱스 사용
4-5. 인덱스 재구성과 삭제
인덱스 재구성
-
B-tree 인덱스의 경우 데이터 수정/삭제/삽입이 잦으면 노드의 갱신이 주기적으로 일어나 단편화 현상이 일어남
+)단편화(Fragmentation): 데이터가 저장된 공간이 효율적으로 채워지지 않고 군데군데 빈틈(구멍)이 생겨 성능이 떨어지는 현상 -
이 경우, ANALYZE 문법을 통해 인덱스를 다시 생성해줌
ANALYZE TALBE book;인덱스 삭제
DROP INDEX ix_Book ON book;1. 데이터베이스 프로그래밍의 개념
데이터베이스 프로그래밍
- DBMS에 데이터를 정의하고 저장된 데이터를 읽어와 데이터를 변경하는 프로그램을 작성하는 과정
- 데이터베이스 언어인 SQL을 포함하는 점이 일반 프로그래밍과의 차이점.
방법
- SQL 전용 언어 사용
- 일반 프로그래밍 언어에 SQL 삽입해 사용하기
- 웹 프로그래밍 언어에 SQL 삽입해 사용하기
- 4GL: 데이터베이스 관리 가능 비주얼 프로그래밍 기능을 갖춘 GUI 기반 소프트웨어 개발 도구 사용
데이터베이스 응용 시스템 -> '하드웨어 - 운영체제 - DBMS -프로그램 환경'으로 계층화
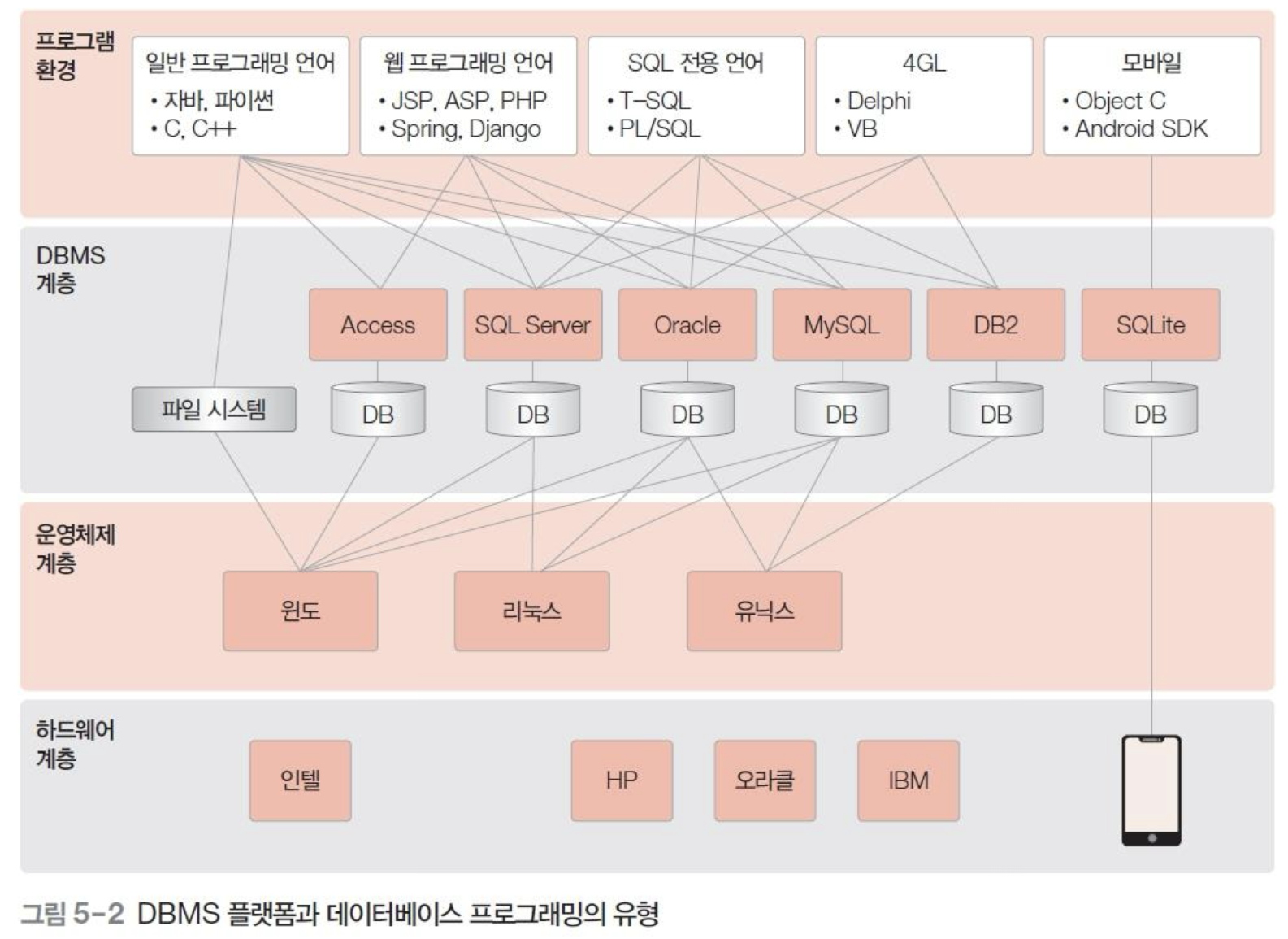
2. 저장 프로그램
2-1. 저장 프로그램
저장 프로그램
프로그램 로직을 프로시저로 구현해 객체 형태로 사용
- 프로시저가 정의된 후 MySQL(DBMS)에 저장되기에 저장 프로그램이라 함
- MySQL에서 저장프로그램을 정의하는과정:
프로그램 정의 -> 실행 -> 실행 결과 -> 개체확인
CREATE PROCEDURE
- 프로시저는 선언부와 실행부(BEGIN-END)로 구성
- 선언부: 변수와 매개변수 선언, 실행부: 프로그램 로직 구현
- 매개변수: 저장 프로시저가 호출될 때 해당 프로시저에 전달되는 값
- 변수: 저장 프로시저/트리거 내에서 사용되는 값
- 제어문 사용 가능.
저장프로그램의 제어문
DELIMITER: 구문 종료 기호를 설정BEGIN-END: 프로그램문을 블록화. 중첩 가능IF-ELSE: 조건의 검삭 결과에 따라 문장 실행RETURN: 프로시저 종료 및 상태값 반환.LOOP: LEAVE 문을 만나기 전까지 LOOP 반복WHILE: 조건이 참일 경우 WHILE문읠 블록 실행REPEAT: 조건이 참일 경우 REPEAT 문의 블록 실행
프로시저(PROCEDURE) 실습
- DELIMITER 뒤에 오는 기호는 자유롭게 지정 가능
예: $$, //, ### 등
프로시저 생성
DELIMITER $$
CREATE PROCEDURE getAge(
-- 선언부
IN p_id INt,
OUT p_name VARCHAR(50),
OUT p_age INT
)
-- 실행부
BEGIN
SELECT 이름, 나이 INTO p_name, p_age -- SELECT 후, 해당 값 전달 위치 지정해줘야함
FROM person
WHERE id = p_id; -- 쿼리의 마지막이니 ;(세미콜론) 필요
END $$
DELIMITER ;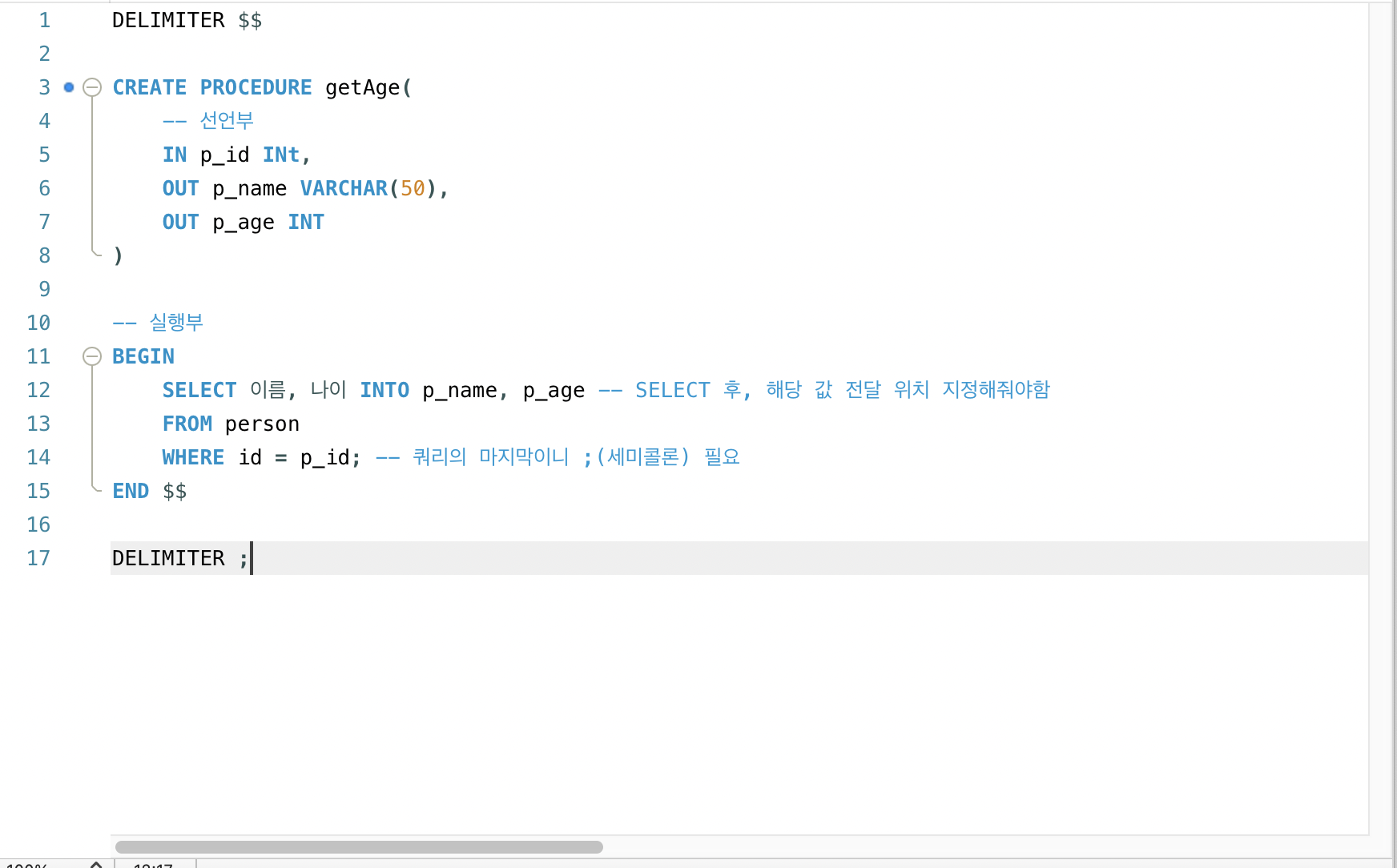
생성한 프로시저 사용
CALL getAge(2, @NAME, @age);
SELECT @NAME, @age;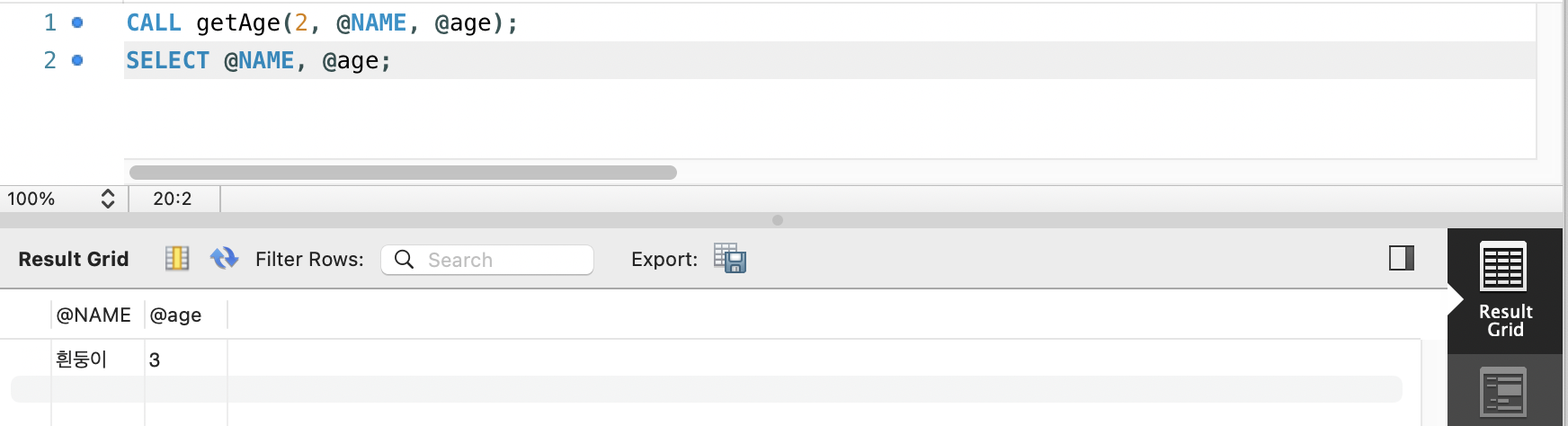
2-2. 트리거
트리거
테이블에 대한 특정 동작(INSERT, UPDATE, DELETE)이 수행될 때 자동으로 실행되는 저장된 프로그램
사용목적
- 데이터 무결성 유지: 잘못된 값 입력 방지, 자동 검증
- 자동 처리: 로그 기록, 변경 이력 관리
- 비즈니스 규칙 적용: 특정 조건 만족 시 자동 계산, 알림 처리
- 연관 테이블 동기화: 다른 테이블에 자동 반영
주의사항
- 트리거는 자동 실행되기에 디버깅이 어렵고, 잘못 작성 시 성능 저하 우려
- 너무 많은 로직을 트리거에 넣으면 관리가 어려워짐
- 트리거는 트랜잭션과 밀접한 관련이 있기에 롤백 시 함께 취소됨.
트리거 실습
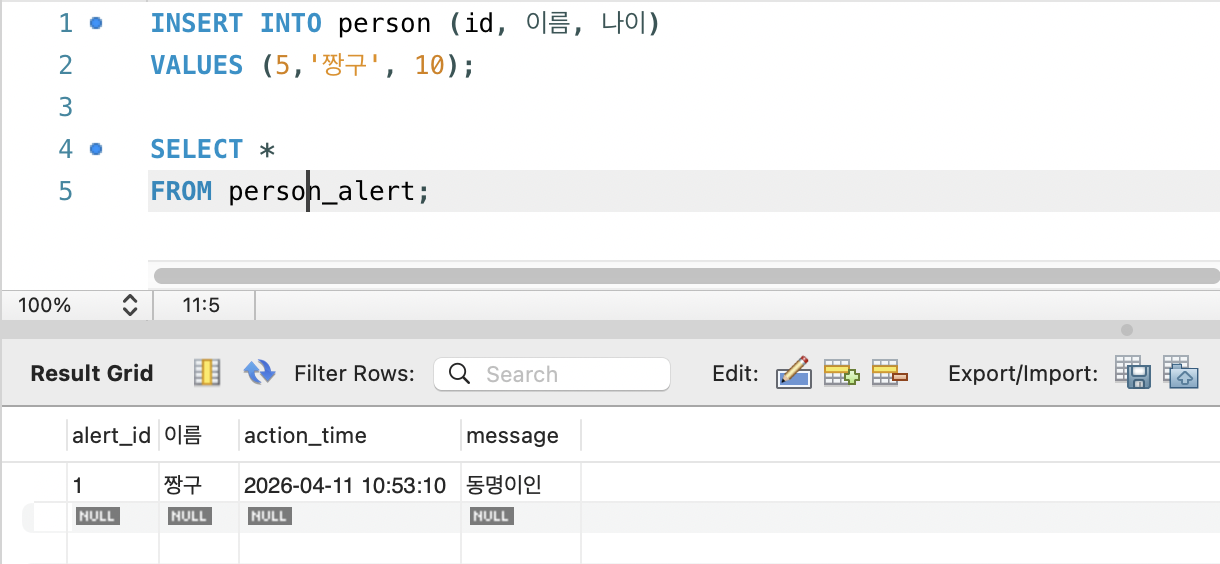
예) person 테이블에 새로운 행이 삽입될 때, 같은 이름이 이미 존재하면 로그 테이블에 기록하는 트리거 생성
DELIMITER $$
CREATE TRIGGER check_duplicate_name
BEFORE INSERT ON person -- person 테이블에 삽입하기 전에
FOR EACH ROW
BEGIN
DECLARE cnt INT;
SELECT COUNT(*) INTO cnt
FROM person
WHERE 이름 = NEW.이름;
IF cnt > 0 THEN
INSERT INTO person_alert (이름, action_time, message)
VALUES (NEW.이름, NOW(), '동명이인');
END IF;
END $$
DELIMITER ;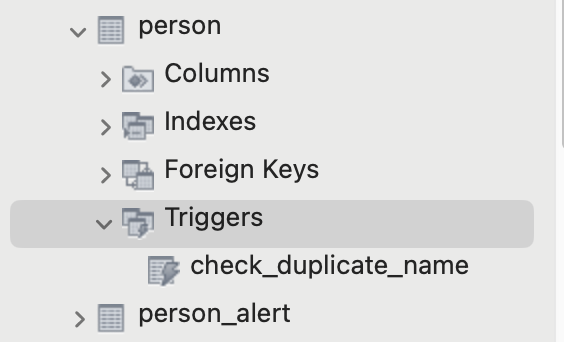
MySQLWorkbench의 경우 트리거를 생성한 테이블 아래에 생성된 트리거가 보인다.
테스트: 이름이 중복인 튜플 넣기
2-3. 사용자 정의 함수
사용자 정의 함수
개발자가 직접 작성하여 SQL 내에서 호출할 수 있는 함수.
- 기본 제공 함수로 해결하기 어려운 로직을 캡슐화할 때 유용
- SQL에서 자주 쓰는 계산이나 로직을 자신이 만든 함수로 등록해두고 필요할 때 호출
종류
- 스칼라 함수: MySQL에서 일반적
- 테이블 반환 함수
- 인라인 함수
장점
- SQL 코드 간결화
- 유지보수에 용이
- 재사용성 증가
단점
- 잘못 사용 시 성능 저하 가능
사용자 정의 함수 실습
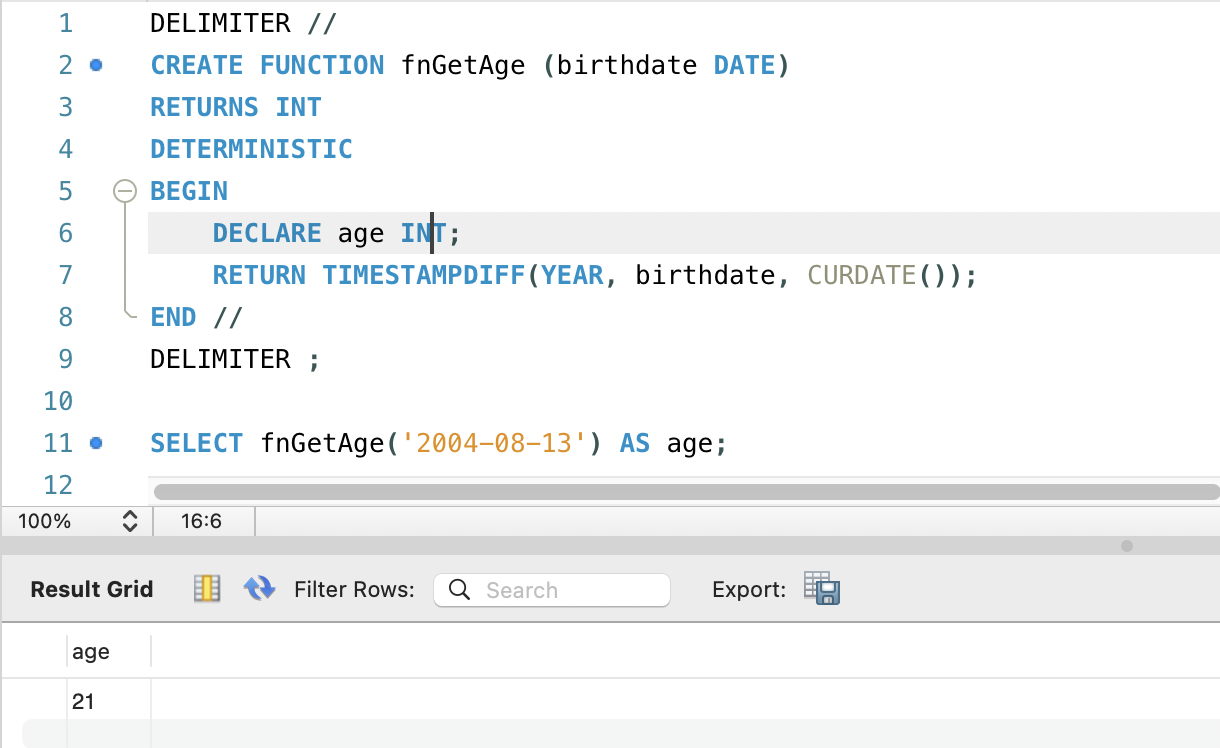
DELIMITER //
CREATE FUNCTION fnGetAge (birthdate DATE)
RETURNS INT
DETERMINISTIC
BEGIN
DECLARE age INT;
RETURN TIMESTAMPDIFF(YEAR, birthdate, CURDATE());
END //
DELIMITER ;
SELECT fnGetAge('2004-08-13') AS age;2-4. 저장 프로그램의 특징
프로시저
여러 SQL문의 묶음으로 단순 반복 업무에 권장. 복잡한 로직을 DB에 몰아넣으면 안됨.
트리거
특정 이벤트가 발생할 때 자동으로 실행. 디버깅, 예측 불가능한 성능 저하 문제 존재.
사용자 정의 함수
입력을 받아 단일값 또는 테이블 반환. 복잡한 연산을 함수로 감싸면 쿼리 최적화를 방해할 수 있음.
비교
| 구분 | 프로시저 | 트리거 | 사용자 정의 함수 |
|---|---|---|---|
| 정의 방법 | CREATE PROCEDURE | CREATE TRIGGER | CREATE FUNCTION |
| 호출 방법 | CALL 문으로 직접 호출 | INSERT, DELETE, UPDATE 문 실행 시 자동 실행 | SELECT 문에 포함됨 |
| 기능 차이 | SQL문으로 할 수 없는 복잡한 로직 수행 | 기본값 제공, 데이터 제약 준수, SQL 뷰의 수정, 참조무결성 작업 수행 | 속성값을 가공해 반환, SQL문 내에서 직접 사용 |
실제 사용 예시
트리거
- 히스토리(감사) 로그 기록: 고객 등급/결제 상태 변경 시 로그 테이블에 기록
- 통계 데이터 실시간 갱신: 게시글 증가 시, 총 게시글 수 증가
프로시저
- 복잡한 주문/결제 처리: 주문 내역 생성 -> 재고 차감 -> 포인트 적립 -> 쿠폰 사용 처리'
- 배치 데이터 처리: 매일 새벽 2시, 유효기간 지난 미사용 쿠폰 일괄 만료 상태 변경
함수
- 비즈니스 로직 계산: 상품 가격&고객 등급 -> 최종 할인 가격 반환
- 데이터 포맷팅/마스킹: 01012345678 입력시 010-1234-5678로 변환 또는 이름 홍*동으로 마스킹
3. 데이터베이스 연동 프로그래밍
Java 주요 클래스
-
DriverManager:getConnection()- DBMS 드라이버를 로드하고 연결 객체 생성
-
Connection:createStatement(),prepareStatement(),close()- 특정 데이터베이스와 연결 세션을 관리. SQL 실행 객체 생성
-
Statement:executeQuery(),executeUpdate()- SQL문을 DB에 전달. 캐싱되지 않기에 정적 SQL 실행 시 주로 사용.
-
PreparedStatement:set...(),executeQuery(),executeUpdate()- SQL을 미리 컴파일해 성능을 높이고, 매개변수를 사용해 보안 강화(SQL Injection 방지)
-
ResultSetnext(),get...(),close()- SELECT 쿼리 실행 결과를 테이블 형태로 저장, 커서를 이동시켜 데이터를 한 줄씩 조회
-
SQLExceptiongetMessage(),getErrorCode()- DB 연동 과정에서 발생하는 예외상황에 대한 정보 제공
연동
연동 순서
드라이버 로드 -> Connection 생성 -> Statement 생성 및 실행 -> ResultSet 처리 -> 자원 반납.
PreparedStatment 권장
보안, 가독성, 성능의 이유로 권장됨
자원 반납(Try-with-resources)
close()를 일일이 호출하지 않아도 자동으로 자원을 닫아주는 구문.
SOLID 원칙
SOLID란?
SOLID 원칙이란 변화에 강하고 재사용에 유리한 클래스 구조를 만드는 법칙이자 원칙이라고한다. 앞에서 정리한 클린코드를 위해서 지켜야하는 법칙과도 같다. 이 원칙을 지키면서 코딩하면, 유지보수 및 확장이 편리하며 재사용성이 높고 테스트가 쉬운 코드를 작성할 수 있다.
| S | Single Responsibility | 단일 책임 원칙 |
| O | Open/Closed | 개방-폐쇄 원칙 |
| L | Liskov Substitution | 리스코프 치환 원칙 |
| I | Interface Segregation | 인터페이스 분리 원칙 |
| D | Dependency Inversion | 의존성 역전 원칙 |
JDBC에서의 SOLID
SRP(단일 책임 원칙)
하나의 클래스는 하나의 책임만을 가져야함.
DAO, DTO, View, Controller로 분리해야함
OCP (개방-폐쇄 원칙)
확장에는 열려있고, 변경에는 닫혀있어야함
인터페이스 기반 DAO
LSP (리스코프 치환 원칙)
자식 클래스는 부모 클래스를 대체할 수 있어야함.
다형성 활용.
ISP (인터페이스 분리 원칙)
불필요한 인터페이스 의존은 피해야함.
역할별 인터페이스, DAO 인터페이스 정의
DIP (의존성 역전 원칙)
고수준 모듈은 저수준 모듈에 의존하면 안됨.
Service -> DAO 인터페이스 주입.
DAO와 DTO
View(입출력), Controller(흐름 제어), Service(비즈니스 로직 처리)와 함께 사용됨.
DAO에서 DB와 관련된 작업이 처리되거나 테이블의 데이터와 매핑되며, DTO는 이런 데이터를 전달하거나 받을 때 사용함.
DAO(Model)
DB 접근 전담 CRUD 처리 클래스(JDBC를 사용하여 SQL 실행)로 DAO 인터페이스를 도입할수도 있음.
DB와 직접 통신한다.
예) 학생 정보 객체
DTO(Data Transter Object)
데이터를 담아 다른계층으로 전달. 가볍고 단순해야 함.
JDBC 실습
JDBC
: 자바 애플리케이션이 데이터베이스에 연결하고 SQL문을 실행할 수 있도록 제공됟는 표준 API
과거 DB마다 접속 방법이 달랐으나, JDBC라는 통일된 인터페이스와 각 DB 제조사의 JDBC 드라이버 제공으로 JDBC 드라이버만 교체하면 자바 코드의 변경 없이 다양한 종류의 데이터베이스와 통신이 가능해짐.
1. Driver 라이브러리 추가
2. 데이터 베이스 연결
String url = "jdbc:mysql://127.0.0.1:3307/madangdb";
String username = "";
String password = "";
try (Connection connection = DriverManager.getConnection(url, username, password)) {
...
} catch (SQLException e) {
System.out.println("DB연결 실패");
}
3. SQL문 실행
- Statement/PreparedStatement
- Connection 객체로부터 SQL을 실행할 수 있는
Statement또는PreparedStatement객체를 생성. statement: 정적인 SQL문 실행에 사용preparedStatement: 성능과 보안 때문에 사용 권장.
4. 결과처리 (ResultSet)
- SELECT문을 실행한 후 반환되는
ResultSet객체는 조회된 데이터의 집합 next()메소드를 호출해 한 행씩 이동하며 데이터를 읽어옴.
JDBC 실습 결과
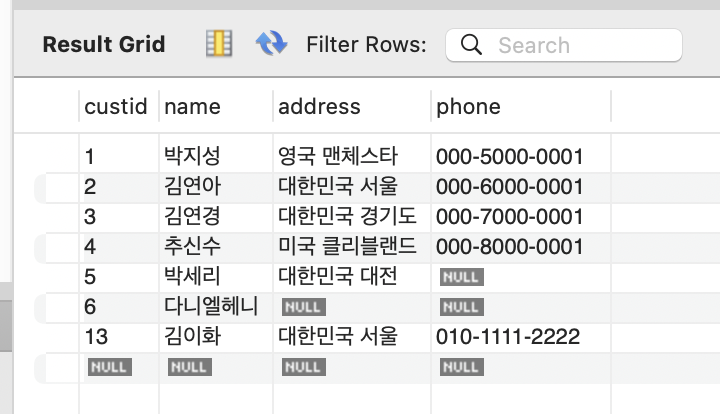
madangdb에서 만든 book, customer 데이터베이스에서 select 및 insert 쿼리 실행.
import java.sql.*;
public class Main {
public static void main(String[] args) {
String url = "jdbc:mysql://127.0.0.1:3307/madangdb";
String username = "";
String password = "";
try (Connection connection = DriverManager.getConnection(url, username, password)) {
String selectSql = "SELECT * FROM book";
try (Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery(selectSql)) {
while (rs.next()) {
int bookid = rs.getInt("bookid");
String bookname = rs.getString("bookname");
String publisher = rs.getString("publisher");
int price = rs.getInt("price");
String result = "bookid: "+ bookid;
result += " bookname: "+ bookname;
result += " publisher: "+ publisher;
result += " price: "+price;
System.out.println(result);
}
}
String insertSql = "INSERT INTO customer (custid, name, address, phone) VALUES(?,?,?,?)";
try (PreparedStatement pstmt = connection.prepareStatement(insertSql)) {
pstmt.setInt(1,13);
pstmt.setString(2, "김이화");
pstmt.setString(3, "대한민국 서울");
pstmt.setString(4,"010-1111-2222");
pstmt.executeUpdate();
}
} catch (SQLException e){
System.out.println("연결 오류");
}
}
}실습코드 사진
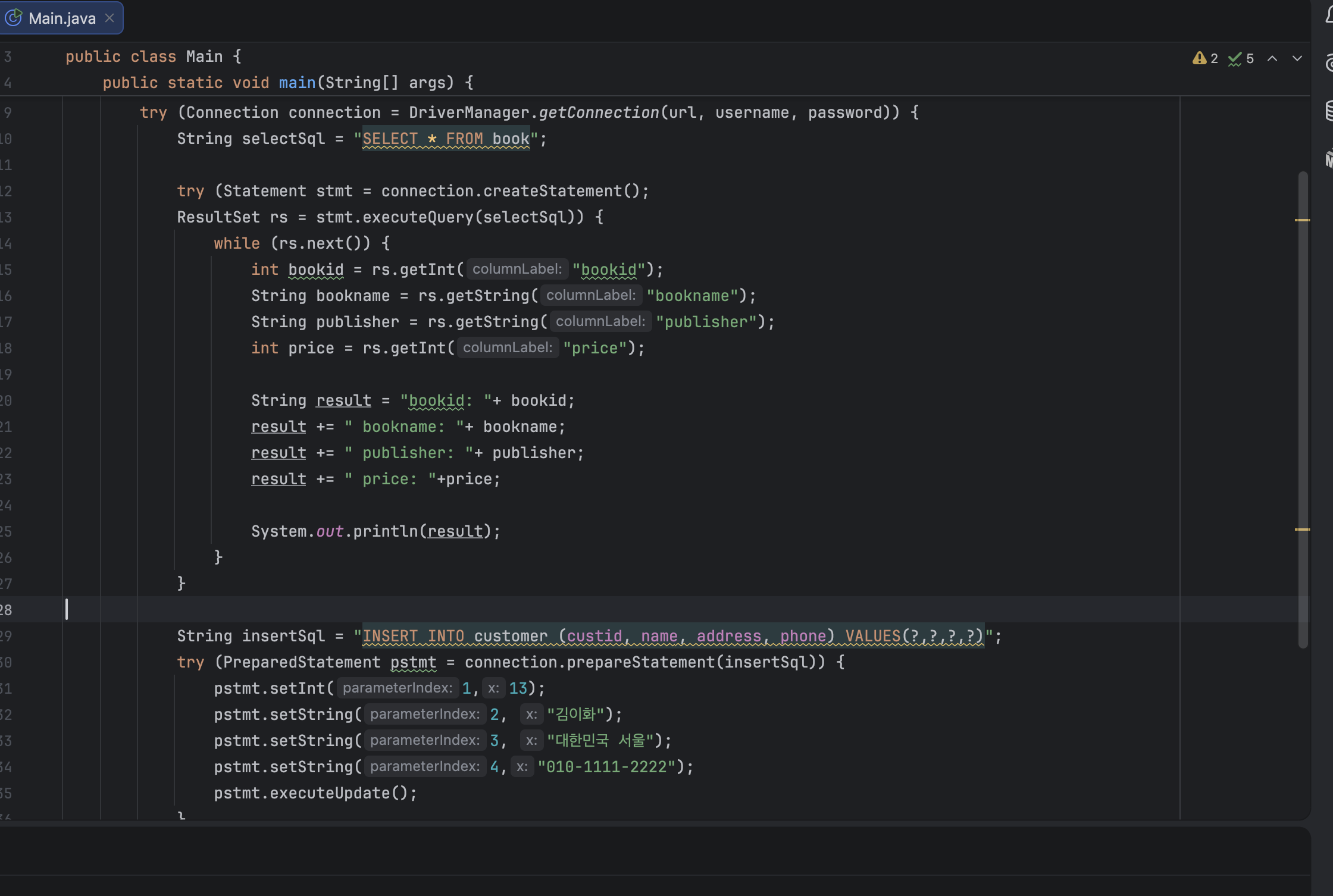
실습 결과
select 쿼리

insert 쿼리
pstmt.setInt(1,13);
pstmt.setString(2, "김이화");
pstmt.setString(3, "대한민국 서울");
pstmt.setString(4,"010-1111-2222");
pstmt.executeUpdate();