제너릭(Generic)
제너릭(generic) 사용의 목표는 일반적인 코드를 작성하고 해당 코드를 다양한 타입의 객체에 대해 재사용하기 위해서라고 할 수 있다.
이때 타입 파라미터를 사용해 클래스와 인터페이스를 정의하게되는데,
타입 파라미터는 주로 대문자 알파벳 한 문자로 표현한다. 클래스 혹은 인터페이스의 이름 뒤에 "<>"의 기호와 내부에 타입 파라미터를 명시하여 사용한다.
예) <E,V>: element, value
public class Box<T> {
private T t;
public T get() {return t};
public void set(T t) {this.t = t;}
}위와 같은 코드를 작성한 후, Box<String> box= new Box<String>();와 같은 식으로 타입 파라미터를 String으로 지정한 뒤에 사용하게 되는데, 간단하게 생각하면 타입 파라미터 T의 자리에 String이 들어간다고 생각하면된다.
위와 같이 작성했을 때의 장점은, Box라는 객체에 담을 정보가 String이 아닌 int 타입일 경우 Box의 전체 코드를 다시 작성할 필요가 없이, Box<Integer> box2 = new Box<>();와 같이 타입 파라미터를 다르게 지정하여 사용할 수 있기 때문이다.
(이때, 주의할 점은 int형을 그대로 사용하지 않고 Wrapper 클래스를 활용해 Integer와 같이 사용한다는 점이다. 또한, 앞에 타입을 명시한다면, 뒤에서는 생략해도 된다.)
PECS 원칙
PECS: Producer Extends, Consumer Super
| 키워드 | 역할 | 사용목적 | 설명 |
|---|---|---|---|
? extends T | Producer | 읽기전용 | 생산된 걸 꺼내어 쓰는 입장, 안전하게 꺼낼 수 있음 |
? super T | Consumer | 쓰기전용 | 소비자에게 값을 제공하는 입장. 안전하게 넣을 수 있음 |
실습 코드 일부
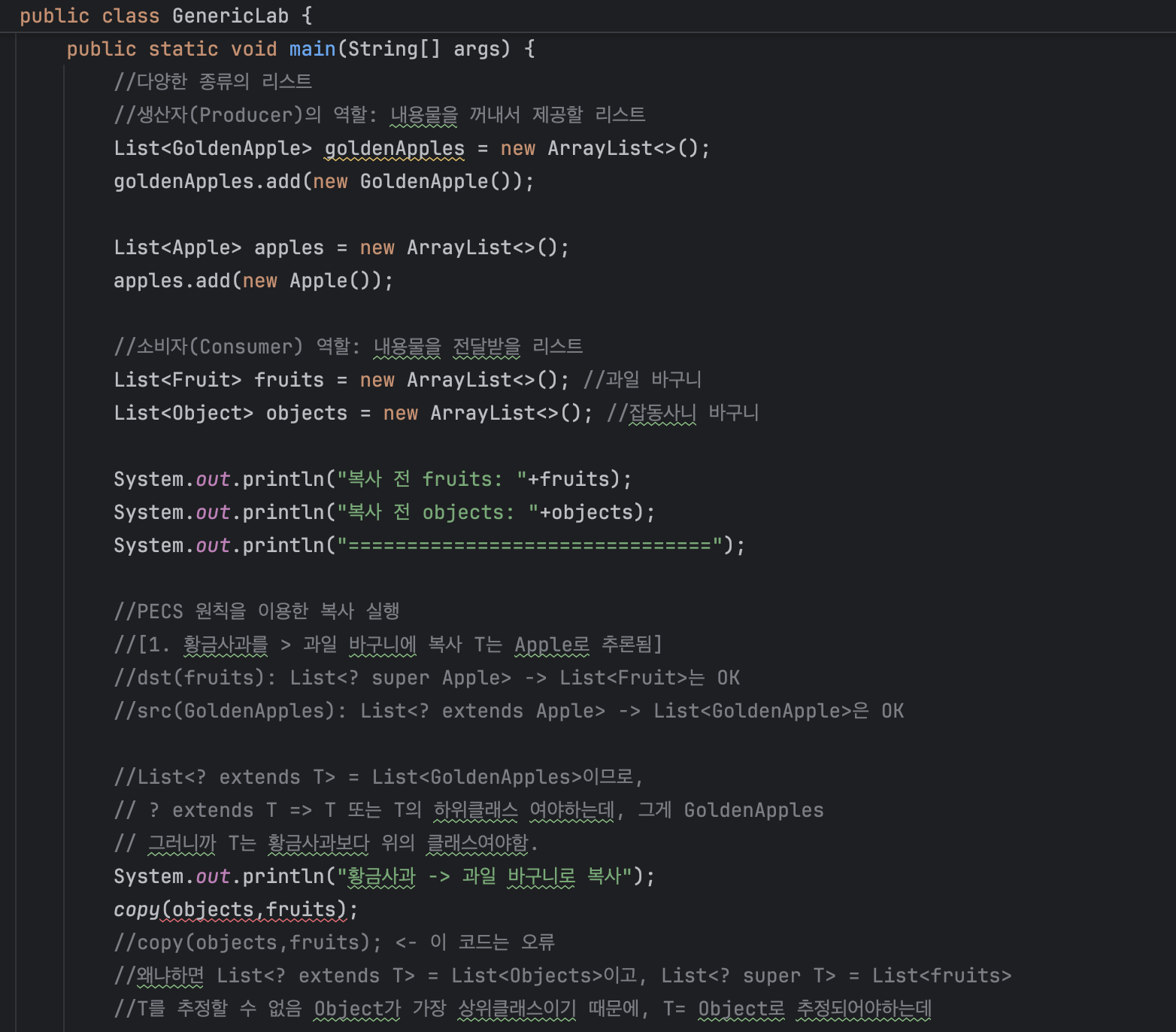
실습 요약
-
실습을 위한 클래스 계층 구조: Object <- Fruit <- Apple <- GoldenApple
(Object가 최상위 클래스) -
copy()메소드 설명``` public static <T> void copy(List<? extends T> src, List<? super T> dst) { for (T item: src) {dst.add(item);} } ```- src 리스트에서는 T타입(또는 그 자식)의 데이터를 안전하게 꺼낼 수 있다.
- dst 리스트에서는 T타입의 데이터를 안전하게 추가할 수 있다.
-
copy()메소드의 인자로 어떤 값이 들어오는냐에 따라 컴파일러가 T를 추론하게되고, 이에 따라 안전하게 데이터를 꺼내고 추가 가능하다.경우1:
copy(goldenApples,apples);List<? extends T>=List<GoldenApple>, 이를 위해서는 T가 GoldenApple 혹은 그보다 상위 클래스(Apple/Fruit/Object)여야함.List<? super T>=List<Apple>, 이를 위해서는 T가 Apple 혹은 그보다 하위 클래스(GoldenApple)이어야함.결론적으로, T=Apple로 추론되어 코드가 실행됨. (이부분은 조금 헷갈리지만, 컴파일러가 두 조건을 만족하는 공통적인 클래스 중 가장 일반적인(?)(=상위의 클래스)로 추론하는 느낌으로 이해했다.
경우2:
copy(objects, fruits);간단히 생각하면 Fruit보다 상위의 클래스인 Object 클래스 리스트를 Fruit 리스트로 옮기면 안되겠구나 정도로 생각할 수 있을 것 같다.
위의 케이스처럼 분석해보면?
List<? extends T>=List<Object>, 이를 만족시키기 위한 T는 Object 뿐이다. Object는 모든 클래스들의 상위 클래스인, 최상위 클래스이기 때문이다.List<? super T>=List<Fruit>, 이를 만족시키기 위한 T는 Fruit 혹은 이보다 더 하위 클래스인데, 이미 위의 조건에서 T로 추론가능한 후보는 Object 뿐이었다.결론적으로 두 조건을 모두 만족하는 T를 추론하지 못하기 때문에(=애초에 그런 T가 없으니..?), 코드에서 바로 오류 표기가 된다.
컬렉션 (Collection)
컬렉션(Collection)은 객체들을 효율적으로 추가, 삭제, 검색할 수 있도록 자바에서 제공되는 라이브러리로 리스트(list), 스택(stack), 큐(queue), 집합(set) 등이 있다.
여기서는 집합(set)과 맵(map)과 관련된 실습 및 정리를 진행하였다.
리스트 (List)
배열과 여러모로 비슷하지만, 우선 크기가 유동적(=가변배열)이라는 큰 장점이 존재한다. 이외에도 객체를 삽입/추가/삭제할 때 훨씬 간단하기에 유용하다.
배열이 요소가 삭제되어도 null 형태로 남아있는데에 반해, 리스트는 자동으로 공백을 뒤의 요소가 채우고, 사이에 요소를 삽입할 수도 있다는 장점이 존재한다.
List 인터페이스를 구현하는 컬렉션으로는 Vector, ArrayList, LinkedList가 존재한다.
집합(Set)
집합(Set)은 정말 수학에 존재하는 집합의 개념과 같다. 요소들을 저장하는 순서가 유지되지 않으며, 요소의 중복을 허용하지 않는다.
앞의 리스트와 다르게 순서가 존재하지 않기에 get(int index)와 같이 인덱스로 객체를 가져오는 메소드가 존재하지 않는다는 특징이 있다.
Set 인터페이스를 구현하는 클래스로는 HashSet, LinkedHashSet, TreeSet, EnumSet가 있다.
public static <E> void show(Set <E> s) {
//람다식 활용해 컬렉션 방문 + 출력하기
s.forEach(i -> System.out.print(i+","));
System.out.println();
System.out.println("=========================");
}
public static void main(String[] args) {
Set<Integer> set1 = new HashSet<>(Arrays.asList(1,2,3,4,5));
Set<Integer> set2 = new HashSet<>(Arrays.asList(3,4,5,6,7));
Set<Integer> set3 = new HashSet<>(Arrays.asList(5,6,7,8,9));
Set<Integer> set4 = new HashSet<>(Arrays.asList(8,9,10,11,12));
Set<Integer> set5 = new HashSet<>(Arrays.asList(1,2,3,4,5,6,7,8,9,10,11,12));
set1.addAll(set2); //합집합: set1에 set1&set2의 합집합이 저장됨
set2.retainAll(set3); //교집합
set3.removeAll(set4); //set3-set4 => set3 = {5,6,7}
set4.removeAll(set3); //set4-set3 => set4 = {그대로}
System.out.println(set5.containsAll(set4));
show(set1);
show(set2);
show(set3);
show(set4);
show(set5);
}HashSet을 사용하는 방법을 익히기 위한 실습을 진행하였으며, 결과값은 아래와 같이 출력된다. 사용된 메소드들을 정리하면 아래 표와 같다.
| 메소드 | 설명 |
|---|---|
set5.containsAll(set4) | set4가 set5의 부분집합이면 참 |
set1.addAll(set2) | set1에 set1과 set2의 합집합을 저장 |
set2.retainAll(set3) | set2에 set2와 set3의 교집합을 저장 |
set3.removeAll(set4) | set3에 set3-set4(차집합)을 저장 |
맵 (Map)
맵(Map)은 키(key)와 대응되는 값(value)로 구성된 Map.Entry 객체를 저장하는 구조의 컬렉션이다. 파이썬의 딕셔너리(dictionary)와 흡사하다.
집합(Set)과 마찬가지로 요소들의 저장순서를 유지하지 않으며, 키는 중복을 불허한다. 값(value)의 중복은 가능하다. 만약, 중복된 키와 값을 저장하면 가장 마지막에 저장한 값으로 변경되어 최종적으로 저장된다.
Map <K,V> map = new HashMap<K,V>();
public static <K,V> void show (Map<K,V> map) {
System.out.println("=====================");
//키만 가져옴
Set<K> keys = map.keySet();
System.out.println("Key: "+keys);
//값(value)만 가져옴
Collection<V> values = map.values();
System.out.println("Values: "+values);
//Entry: 키와 값을 같이 가져옴
//Entry<K,V>라는 객체들을 Set으로 관리
//Map은 키를 통해 값을 가지고 올 수도 있고, (map.get(key) -> value)
//Entry는 키와 값을 각각 가지고 올 수도 있다. (entry.getKey(), entry.getValue())
Set <Entry<K,V>>entrySet = map.entrySet();
System.out.println("Key : Values");
System.out.println("=====================");
for (Entry<K,V> entry : entrySet) {
System.out.println(entry.getKey() + ":" +entry.getValue());
}
entrySet.forEach(i -> System.out.println(i.getKey()+":"+i.getValue()));
}
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
for (int i=1; i<=10; i++) {
map.put(i,"data#"+i);
}
System.out.println(map); //map의 키와 값을 한꺼번에 출력함
System.out.println(map.get(111)); //키가 111인 값은 없음
map.put(111,"data#111");
map.remove(1);
map.remove(2);
map.put(3,"new_data#3");
System.out.println(map);
show(map);
}최종 실습: PrettyPrinter 인터페이스와 구현클래스
최종 실습으로 제너릭(Generic)과 컬렉션(Collection)을 활용해, 어떤 컬렉션이든 내부 요소에 구애받지 않고, 안전하게 출력하는 유틸리티 클래스를 만드는 실습을 수업에서 진행하였다.
요구사항:
- 요소가 Integer, String, Double, 사용자 정의 클래스여도 문제가 없어야함
- Null-Safe
- List, Set, Map 범위 내에서 진행
- PrettyPrinter 인터페이스
public interface PrettyPrinter {
public <E> void show(Set<E> set);
public <K,V> void show(Map<K,V> map);
public <E> void show(List<E> list);
}인터페이스이기 때문에 show() 메소드를 선언하기만 하고 구현하지는 않고, 오버라이딩(overriding)해 사용할 수 있도록한다. 컬렉션에 따라 코드를 다르게 작성할 것이기에, 파라미터에 따라 다른 메소드가 실행되도록 오버로딩(overloading)한다.
- CollectionPrinter 클래스
PrettyPrinter인터페이스를 구체적으로 구현하고 있는 실체 클래스이다.
public class CollectionPrettyPrinter implements PrettyPrinter{
@Override
public <K, V> void show(Map<K, V> map) {
System.out.println("[Map 출력]");
map.entrySet().forEach(i -> System.out.println(i.getKey()+" => "+i.getValue()));
System.out.println();
}
@Override
public <E> void show(Set<E> set) {
System.out.println("[Set 출력]");
set.forEach(i -> System.out.println(i+" "));
System.out.println();
}
@Override
public <E> void show(List<E> list) {
System.out.println("[List 출력]");
list.forEach(i -> System.out.println(i+" "));
System.out.println();
}
}PrettyPrinter 인터페이스의 메소드들을 오버라이딩하였다. Iterator를 사용하여 작성할 수도 있지만, 람다식을 수업에서 간단히 다뤄 람다식으로 작성하는 것을 시도했다.
맵(Map)은 키와 값의 쌍인 엔트리(entry)가 집합(set)의 구조로 저장되어있기 때문에, 맵에서 entrySet을 가져와 forEach+람다식을 통해 키와 값을 가져와 출력하도록? 코드를 작성했다.
- main 메소드
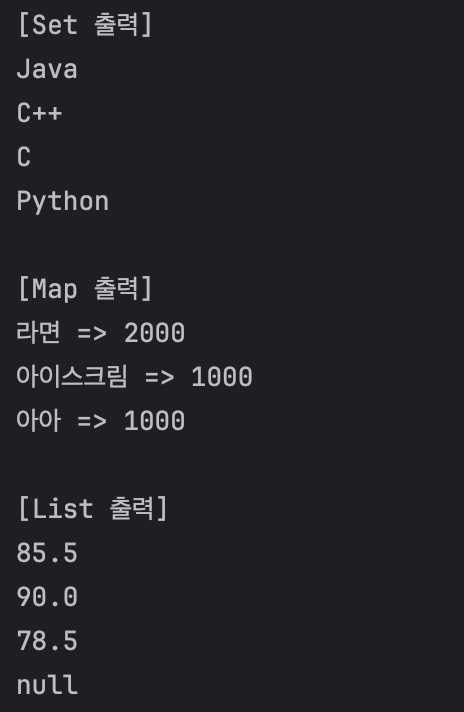
public static void main(String[] args) {
Set<String> languages = new HashSet<>(Arrays.asList("Java","Java","C","C++","Python"));
Map<String, Integer> menuMap = Map.of("라면", 2000, "아아",1000,"아이스크림",1000);
ArrayList<Double> scores = new ArrayList<>(Arrays.asList(85.5,90.0,78.5,null));
PrettyPrinter printer = new CollectionPrettyPrinter();
printer.show(languages);
printer.show(menuMap);
printer.show(scores);
}main() 메소드는 잘 돌아가는지 확인을 위한 코드..정도인 것 같다. 주어진 코드가 있어서 해당 코드를 그대로 사용해 돌아가는지 결과값을 확인하였다. 결과값은 아래와 같다.
소감
뭔가 많은 내용이 있었던 것 같은데, 사실 아직 조금 헷갈리는 개념들도 존재한다고...? 생각한다. 특히 용어가..하하. 컬렉션마다의 메소드들이 공통인 것도 있고, 조금씩 다른 부분도 있어서 그런 사용도 미숙하다. 특히Arrays.asList()나Map.of()이런..?
