-
[과제] 스타벅스의 음료에 대한 정보를 팀별로 모델링하기
https://www.starbucks.co.kr/menu/drink_list.do -
[Tool] Aquerytool 사용
https://aquerytool.com/
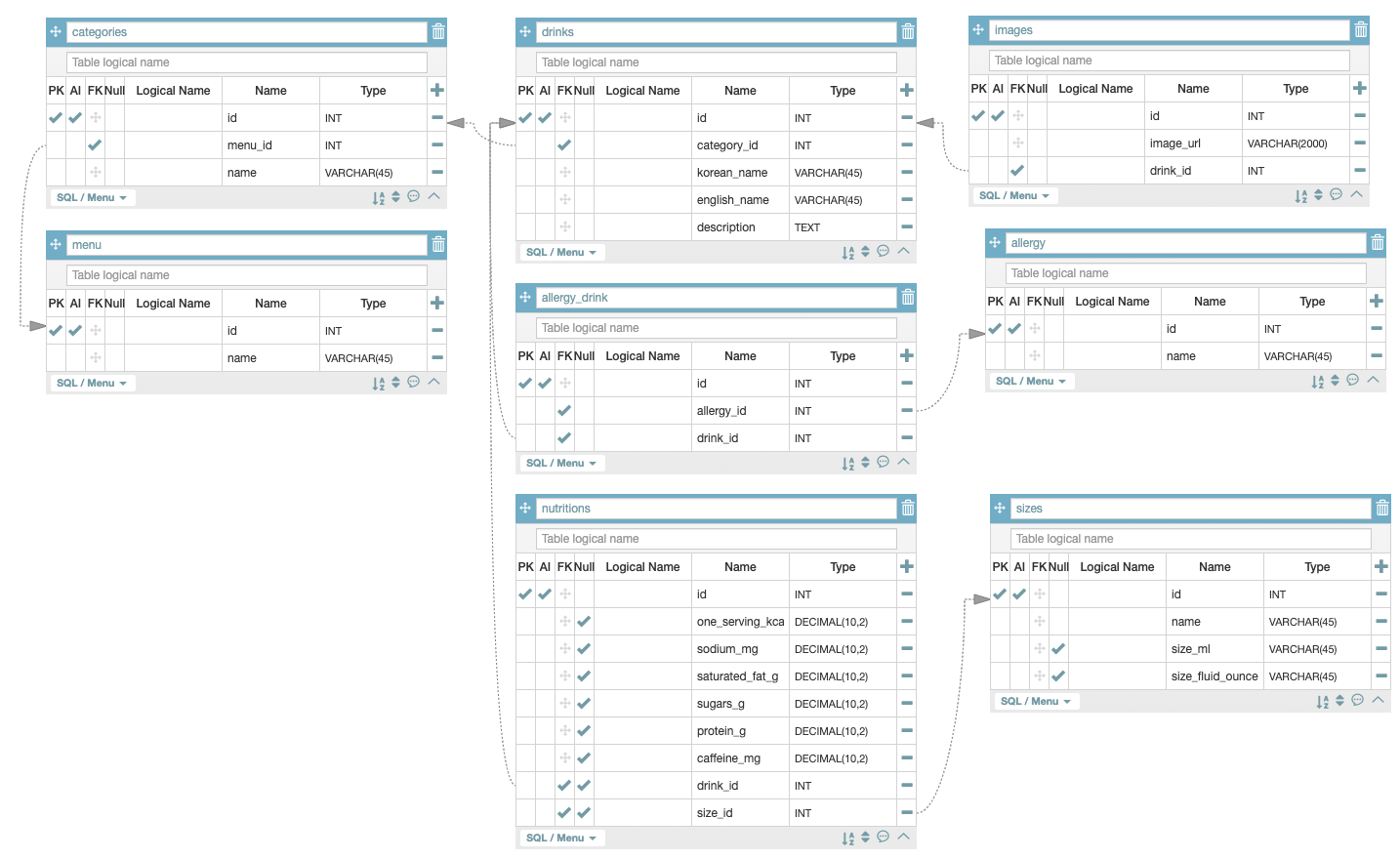
👀 카테고리 아이디는 어떤 걸 보고 붙이나요?
A. 카테고리 네임들이 있는데 drinks 테이블에서 참조해서 id넘버를 알 수 있게 함.
카테고리 테이블에는 콜드브루, 에스프레소 같은 데이터 값이 들어갈 수 있음.
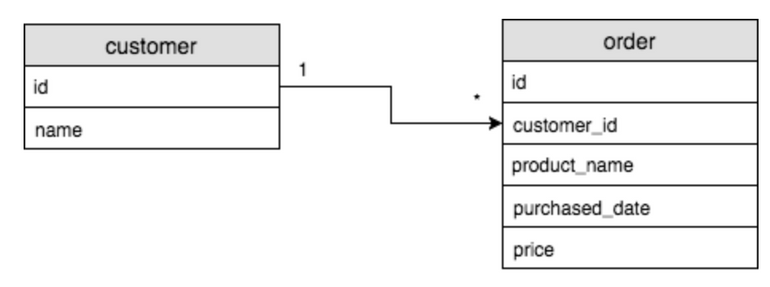
☕ drinks랑 카테고리는 무슨 관계?
A. categories : drinks = 1 : N (one to many)
ex.
drinks 테이블 : 쿨라임 피지오, 슈크림 라떼, 소이 라떼, [...]
categories 테이블 : 콜드브루커피, 브루드 커피, [...]
테이블이 있을 때 그 테이블의 행 하나가 다른 테이블의 행 여러개와 연결될 가능성이 있다면, 1:1관계가 될 수 없음.
테이블 하나에 다른 행이 몇 개가 포함될 수 있는지 체크!
-
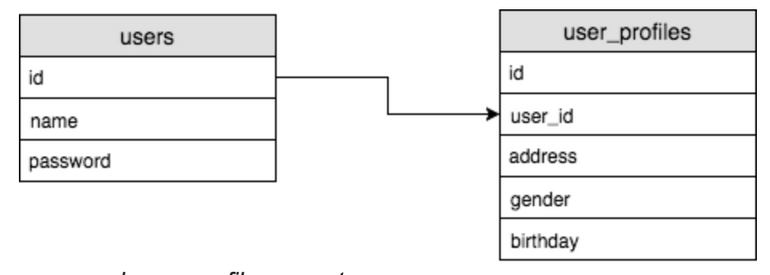
one to one (1:1) 관계: 테이블 A의 로우와 테이블 B의 로우가 정확히 일대일 매칭이 되는 관계
-
one to many(1:N) 관계 : 테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계
테이블 데이터 타입
음료 설명(description)
VARCHAR: 최대 길이가 3천자TEXT: 3천자 이상 (DB에서 메모리를 엄청 크게 잡음)
음료 가격(price)
- 데이터타입
INT로 관리하지 않음 - 달러나 유로 , 비트코인 등 소수점 나옴. 통상적으로 통화는
decimal으로 관리함
- 테이블명은 동사X 명사로
explain(X)description(O)infomation(O)
🖼 drinks 테이블에 이미지를 넣기? 빼기?
- 대부분 제품에 사진이 1개임 -> 서비스 기획에 따라. 나눌지 말지를 회사에서 정함
- 간혹 2-3개 있는 제품도 있음
- 이미지가 여러장이라면 테이블 나누는 게 좋음.
=> drinks : image_url =1 : N(one to many)
🎆 신상품(new) 여부
yes or no 인 경우는 테이블을 따로 두지는 않고 Y/N로 불리언타입으로 관리를 함
mySQL에서는 TINYINT type
Name은 has_new 또는 is_new 라는 이름으로 사용함.
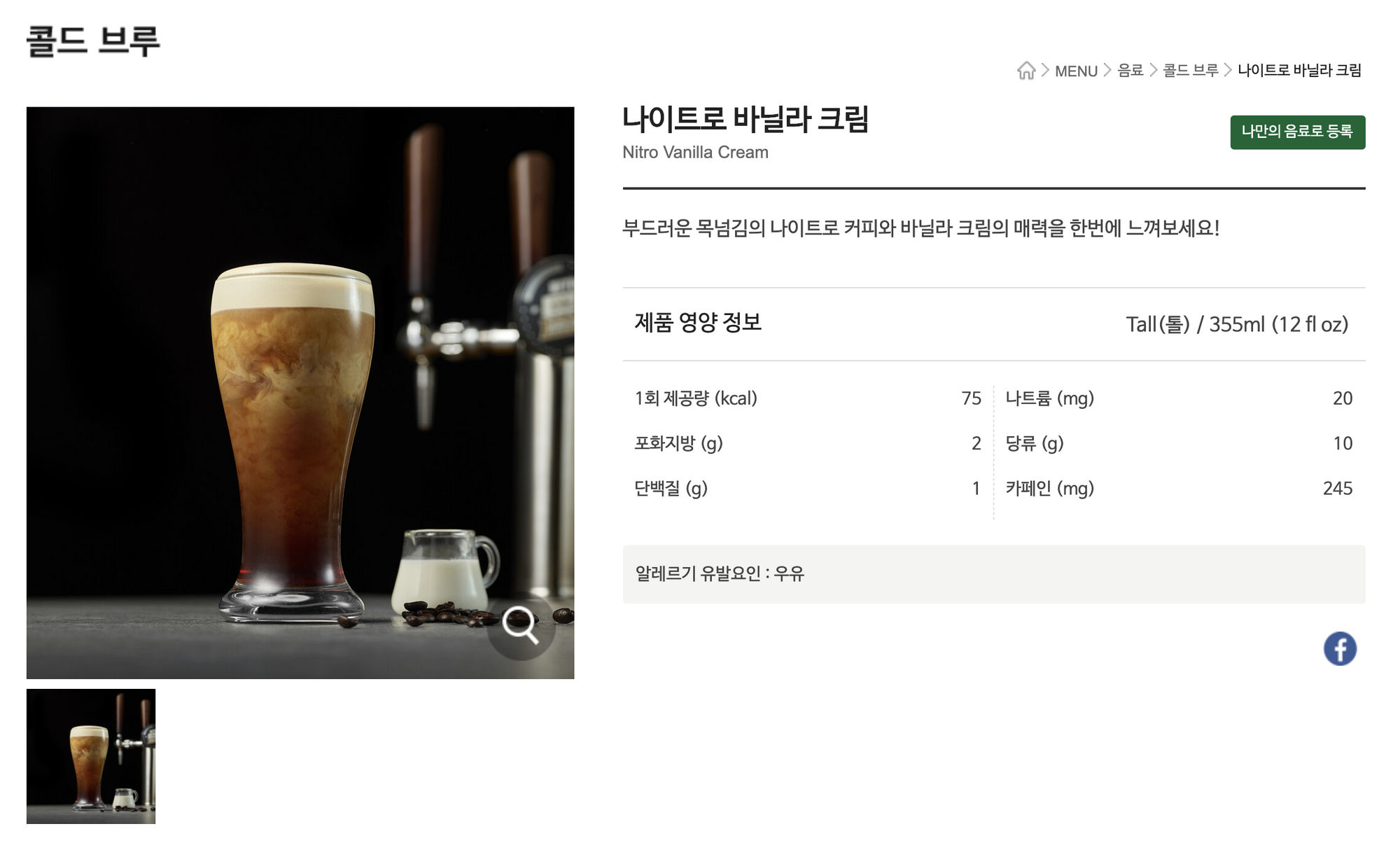
🥗 영양정보
drinks : nutritions = 1:1
1개 메뉴당 6개 정보가 1개가 됨
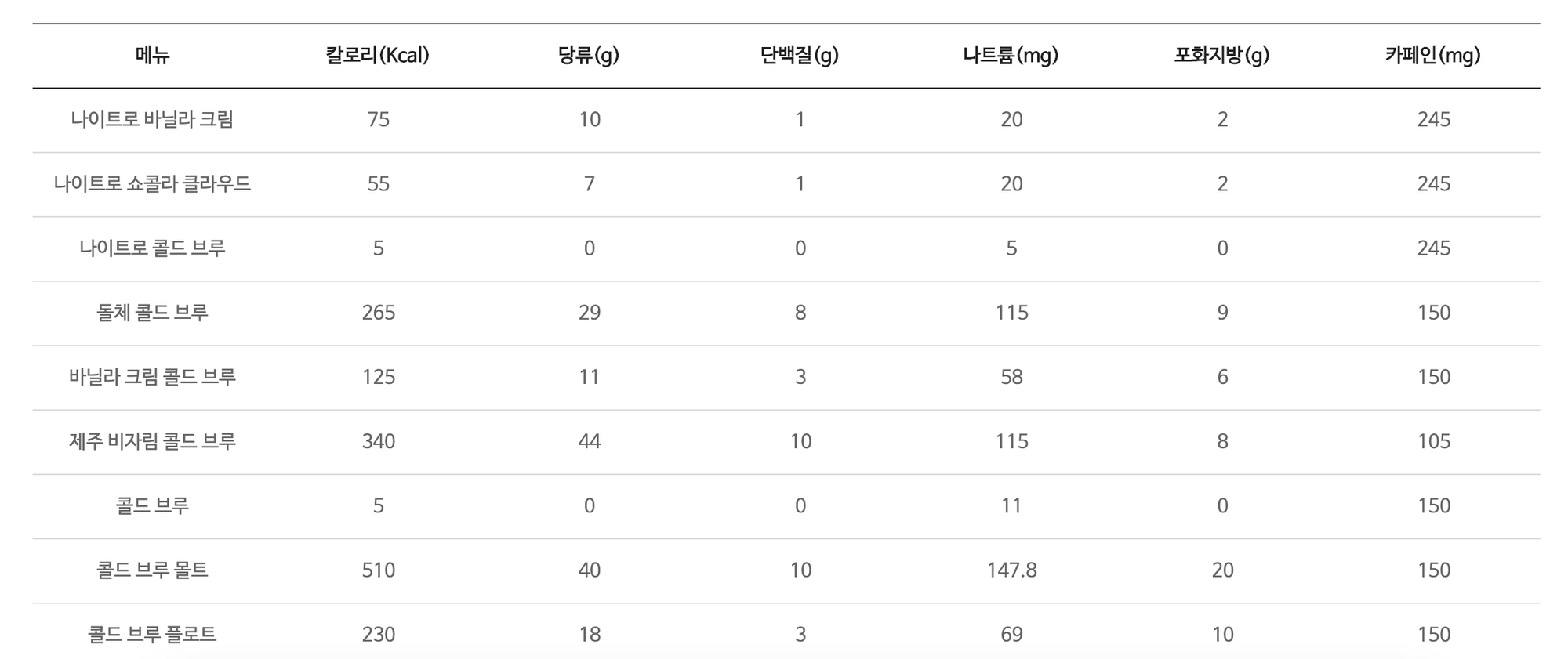
🥚 알러지
drinks : allergies = N : N
- 음료 하나에 알러지가 있는 요소가 여러개 있을 수 있음
- 알러지 하나에 해당되는 음료 여러개 있을 수 있음
drink : allergy_drink = 1 : N
allergy : allergy_drink = 1 : N
PK랑 FK를 동시에 하지는 않음
N에서 1을 참조하기 때문에 N관계에 있는 테이블에 FK를 물려서 1관계에 있는 테이블의 id를 참조함
many to many (N:N) 관계: 테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결이 되는 관계

만약, 알러지 테이블 컬럼에 알러지 종류를 해두고 T/F로 한다면?
음료 하나에 알러지가 있어봤자 1-2개.
단점1) 불리언타입으로 하면, 모든 컬럼에 데이터를 다 채워놓아야 함
단점2) 신제품을 개발해 전에없던 알러지를 추가하려면 컬럼을 추가해야 함. 그럼 이제까지 있던 모든 메뉴에 정보값을 새로 다 추가해야 함.
알러지 유무 : 우유, 대두/우유, 대두/우유/밀(제주 쑥떡 크림 프라푸치노, 제주 쑥쑥 라떼, 자바칩 프라푸치노초콜릿 크림칩 프라푸치노), 땅콩 / 대두 / 우유 / 난류 / 밀 / 오징어(제주 까망 크림 프라푸치노, 아이스 제주 까망 라떼, 제주 까망 라떼), 우유/토마토(화이트 딸기 크림 프라푸치노, 딸기 요거트 블렌디드), 복숭아(피치 & 레몬 블렌디드, 피치 젤리 티, 피치 젤리 아이스티)
🌗 테이블 구분 여부 기준?
테이블을 늘리면 시간과 돈이 든다. 꼭 분리해야 하는 경우가 아니면 하나로 합치는 게 좋음.
🚥 어떻게 테이블과 테이블을 연결하는가?
- Foreign key(외부키)라는 개념을 사용하여 주로 연결합니다
- 앞서 본 one to one 예에서 user_profiles 테이블의 user_id 컬럼은 users 테이블에 걸려있는 외부 키라고 지정합니다.
- 즉 데이터베이스에게 user_id의 값은 users 테이블의 id 값이며 그러므로 users 테이블의 id 컬럼에 존재하는 값만 생성될 수 있습니다.
- 만일 users 테이블에 없는 id 값이 user_id 에 지정되면 에러가 발생합니다.
🚦 왜 테이블들을 연결하는가?
- 왜 정보를 여러 테이블에 나누어서 저장하는가?
- 앞서 본 one to many의 예에 경우 그냥 하나의 테이블에 고객 정보와 구입한 제품 정보 모두를 저장 하면 안되는가?
- 하나의 테이블에 모든 정보를 다 넣으면 동일한 정보들이 불필요하게 중복되어 저장됩니다.
- 더 많은 디스크를 사용하게 되고, 잘못된 데이터가 저장 될 가능성이 높아집니다.
- 예를 들어, 고객의 아이디는 동일한데 이름이 서로 다른 로우들이 있다면 어떻게 해야 할까요? 어떤 이름이 정확할까요?
- 여러 테이블에 나누어서 저장한후 필요한 테이블 끼리 연결 시키면 위의 두 문제가 사라집니다.
- 중복된 데이터를 저장하지 않음으로 디스크를 더 효율적으로 쓰고,
- 또한 서로 같은 데이터이지만 부분적으로만 내용이 다른 데이터가 생기는 문제가 없어집니다.
- 이것을
**normalization**(정규화) 이라고 합니다.
💥 마무리
데이터 베이스 모델링에는 단 하나의 정답이 있는 것은 아닙니다. 현재 서비스에 가장 최적화된 구조를 찾아가는 과정입니다. Best practice를 자주 찾아보고, 여러 서비스들의 서비스 구조를 파악해보는 연습을 하는 것이 데이터 모델링 실력을 키우는 가장 좋은 방법입니다.
(멘토님say) 스타벅스는 상대적으로 무척 단순한 편이에요!
Q. 마켓컬리나 넷플릭스를 모델링한다고 하면.....? (와 꿀잼 A ㅏ....)