파일
파일은 관련된 정보들을 이름을 통해서 묶어 놓은 것이다. 파일은 이름을 통해서 구분되고 접근한다. 일반적으로 비휘발성 보조기억장치에 저장한다. 파일은 생성, 삭제, 읽기, 쓰기 등의 작업을 할 수 있다.
운영체제에서는 저장 장치도 파일로 인식하여 볼 수 있게 해준다.
파일에는 파일 metadata(혹은 file attribute)가 존재한다. 메타데이터는 파일 자체의 내용이 아니라 파일을 관리하기 위한 각종 정보들이 포함된 데이터로 파일 이름, 유형, 저장된 위치, 파일 사이즈, 접근 권한, 시간, 소유자 등이 존재한다.
운영체제에서 이런 파일들을 관리하는 부분을 파일 시스템이라고 하며, 파일 및 파일의 메타데이터와 디렉토리 정보등을 관리한다.
디렉터리
디렉터리는 폴더와 같은 뜻으로, 파일의 메타데이터중 일부를 보관하고 있는 일종의 특별한 파일이다. 디렉터리에는 그 디렉터리에 속한 파일 이름 및 파일의 메타데이터들이 존재한다.
파티션(Logical disk)
하나의 디스크에 여러 개의 방을 만드는 것을 파티션이라고 한다. 보통 하나의 디스크안에 여러 파티션을 두는게 일반적이다. 또한 여러 개의 디스크를 하나의 파티션으로 구성하기도 한다.
디스크를 파티션으로 구성한 뒤 각각의 파티션에 파일 시스템을 깔거나 메모리 swapping 용도로 사용할 수 있다.
open(), read() 시스템 콜
open()은 파일의 메타데이터를 메모리에 올려놓는다.
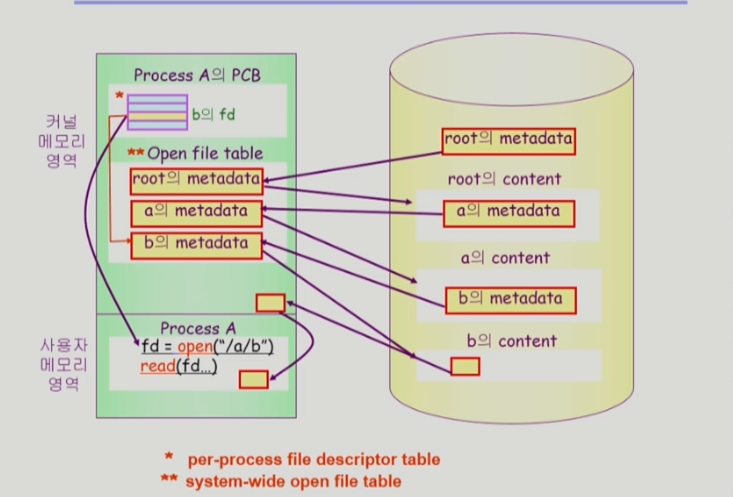
만약 프로세스 A가 open("a/b")를 한다고 하자. 그럼 다음 순서로 파일 열기가 이루어진다.
- 보통 root의 메타데이터는 알려져있기 때문에 root로부터 순서대로 찾기 시작한다.
- root의 메타데이터를 파일 테이블 위에 올려놓는다.
- root의 content안에 파일 a를 찾아 메타데이터를 파일 테이블 위에 올려놓는다.
- 파일 a의 content안에 파일 b를 찾아 메타데이터를 파일 테이블 위에 올려놓는다.
- 프로세스 A의 PCB에는 b의 파일 디스크립터가 저장된다.
- 프로세스 A가 파일 b의 read() 시스템 콜을 호출한다.
- b의 메타데이터를 파일 테이블에 올려놨으므로 b의 content안의 b의 데이터를 찾아서 운영체제의 버퍼 캐시 위에 올려놓는다.
- 프로세스 A에게 파일 b의 내용을 복사하여 전달한다.
- 만약 파일 b의 read() 요청이 다시 들어오면 버퍼 캐시를 이용하여 전달한다.
파일 protection
각 파일에 대해 누구에게 어떤 유형의 접근(read/write/execution)을 허락할 것인지 설정할 수 있다. 다음 세 가지 방법이 있다.
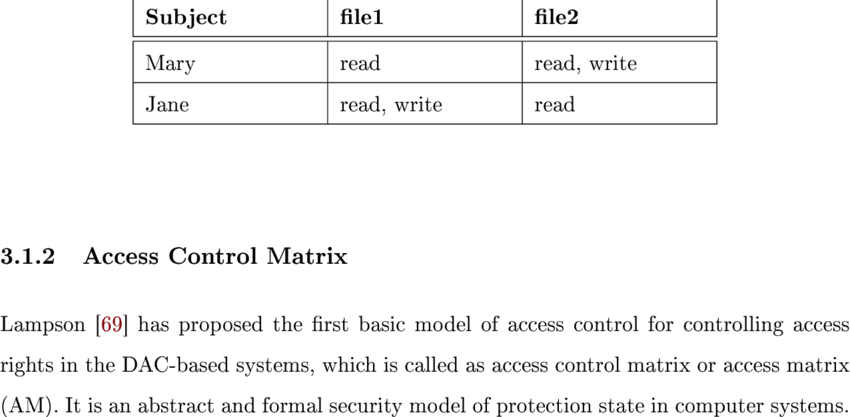
Access control matrix
- 파일과 파일에 대한 유저의 접근 권한을 행렬 표로 배치하는 방법
- 방법1 access control list : 파일별로 누구에게 어떤 접근 권한이 있는지 표시
- 방법2 capabillity : 사용자별로 자신이 접근 권한을 가진 파일 및 해당 권한 표시
- 하지만 오버헤드가 크다는 단점이 존재한다.
Grouping
- 전체 user를 owner, group, public 세 그룹으로 구분
- 각 파일에 대해 세 그룹의 접근 권한을 rwx를 3비트씩표시
- ex) rwxrwxrwx(owner, group, other)
Password
- 파일마다 password를 두는 방법
- 접근 권한별 password의 관리에 대한 문제가 존재한다.
Mounting
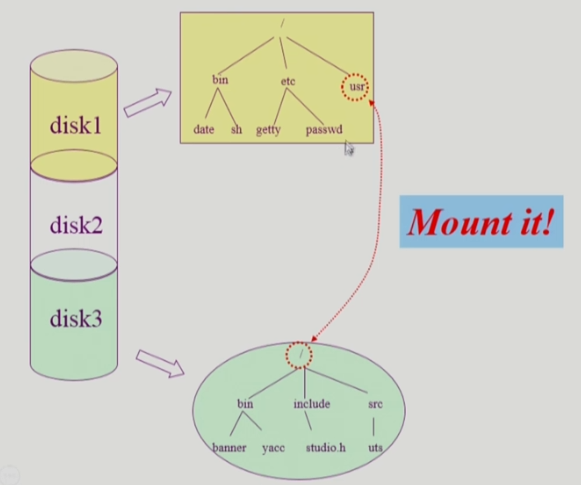
mounting은 어떤 한 디스크의 하위 디렉터리에 다른 디스크의 root를 연결하여 사용가능하게 해주는 것이다.
파일 정보의 접근 방식
순차접근(sequential access)
- 카세트 테이프를 사용하는 방식처럼 접근
- 읽거나 쓰면 offset(현재 디스크가 가리키고 있는 곳)은 자동적으로 증가
직접 접근(direct access, random access)
- LP 레코드 판과 같이 접근하도록 함
- 파일을 구성하는 레코드를 임의의 순서를 접근할 수 있다.
디스크 파일 저장 방법
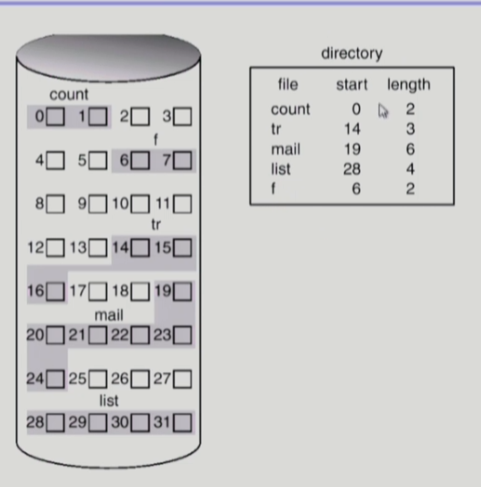
연속 할당(contiguous allocation)
하나의 파일이 디스크상에 연속적으로 저장되게 하는 것을 연속 할당이라고 한다. 파일의 메타데이터에 파일의 시작 위치와 길이를 저장해놓고 사용한다.
장점
- 빠른 I/O
- 한번의 seek/rotation으로 많은 데이터를 가져올 수 있음
- 프로세스의 swapping용으로 사용 가능
- direct access 가능
단점
- 외부 단편화 발생 가능
- 파일 크기를 키우는 것이 어려움 -> 이에 대비해 미리 할당하는 방법이 존재하나 결국엔 그만큼밖에 파일 크기를 키우지 못함. 또한 미리 할당한다면 내부 단편화가 발생할 수 있음.
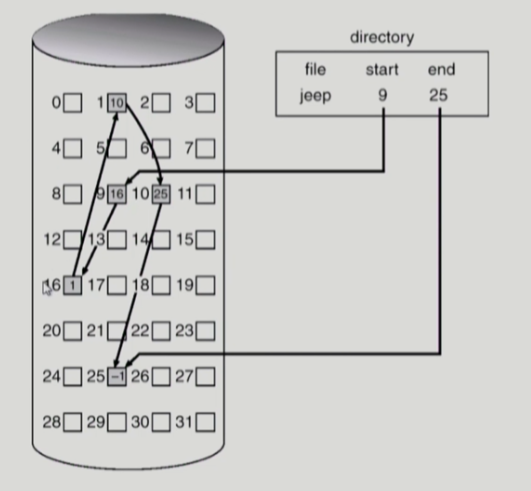
연결 할당(linked allocation)
파일을 연속된 공간에 저장하지 않고 아무 곳에나 저장한다음 linked list처럼 다음 데이터가 있는 블럭의 주소를 연결한다. 파일의 메타데이터에는 파일 데이터의 시작 주소와 끝 주소를 저장하여 파일의 시작과 끝을 파악한다.
장점
- 외부 단편화가 발생하지 않음
단점
- direct access 불가능
- reliabiliy 문제 존재: 한 섹터가 고장나 다음 블럭에 대한 포인터가 유실되면 많은 부분을 잃을 수 있음
- pointer를 위한 공간이 block의 일부가 되어 공간 효율성을 떨어뜨림
위 단점을 해결하기 위해 변형한 시스템인 File-allocation table(FAT)이 존재한다. FAT는 포인터를 별도의 위치에 보관하여 reliability와 공간효율성 문제를 해결한다.
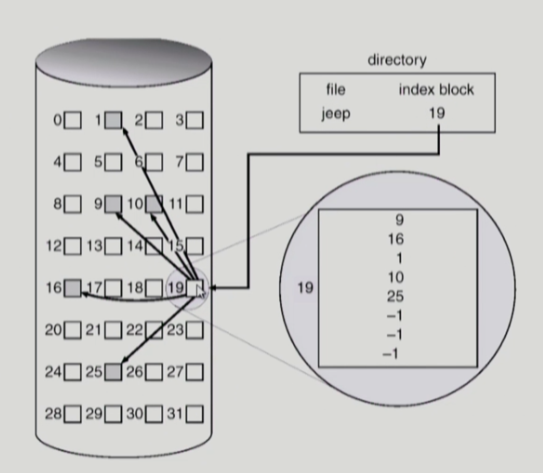
색인 할당(indexed allocation)
인덱스 블럭이라 불리는 블럭들을 사용하는 방법이다. 인덱스 블럭 하나에 파일의 데이터가 저장되어 있는 디스크 상의 주소가 순차적으로 적혀져 있다. 파일의 메타데이터에는 파일에 해당하는 인덱스 블럭의 인덱스가 존재한다.
장점
- 외부 단편화가 발생하지 않음
단점
- 작은 파일의 경우 공간 낭비 (실제로 많은 파일들이 작음)
- 매우 큰 파일의 경우 하나의 블럭으로 index를 저장하기에 부족
- direct access 불가능
위 단점을 해결하기 위해 linked sheme, multi-level index 등의 구조를 적용할 수 있다.
유닉스 파일 시스템
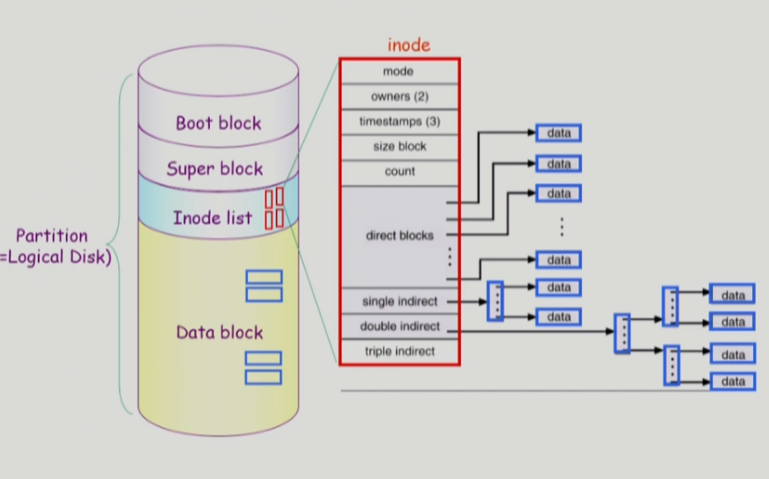
유닉스에서 파일 시스템은 한 파티션을 다음과 같이 나눈다.
Boot block
부팅에 필요한 정보를 저장해두는 공간이다. 이곳을 참조하여 운영체제를 부팅한다.
Super block
파일 시스템에 관한 총체적인 정보를 담고 있다. 정보중엔 어느 공간이 빈 블록이고, 파일이 저장된 블록인지같은 것이 있다.
Inode list
유닉스 파일 시스템에서 inode는 파일의 메타데이터를 뜻한다. 파일 하나당 하나의 inode를 가지고 있다. inode list는 그런모든 inode를 저장해두는 공간이다.
Data block
파일의 실제 내용을 보관하는 공간이다.
유닉스 파일 시스템은 색인 할당을 베이스로 한 시스템이다. 이 시스템에서 디렉터리 파일은 파일의 메타데이터를 바로 가지고 있지 않다. 대신 파일의 이름과 inode 번호를 가지고 있다. 파일을 읽을 땐 파일에 연결된 inode의 direct blocks 항목을 사용한다. 이 항목엔 위에서 설명한 색인 할당처럼 해당하는 파일의 디스크상 주소가 순차적으로 적혀있다.
만약, 파일의 크기가 커서 direct blocks의 인덱스만으로는 부족한 경우 single indirect, double indirect, triple indirect를 사용한다. 이것들은 똑같이 파일의 디스크상 주소가 순차적으로 적혀있지만 페이징에서의 n단계 페이지처럼 단계적으로 블럭을 구성하여 저장한다. 그럼 더 많은 인덱스를 사용하여 파일을 저장할 수 있다.
FAT 파일 시스템
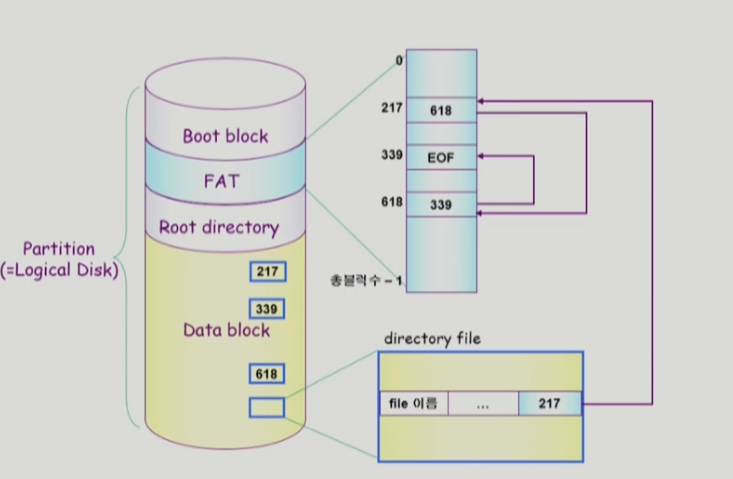
FAT 파일 시스템은 파일의 메타데이터중 위치정보를 FAT라는 공간에 저장하는 방식이다. 그 외에 나머지 메타데이터는 전부 디렉터리가 가지고 있다.
디렉터리의 메타데이터에는 파일의 시작 주소가 담겨있다. FAT에는 해당 시작 주소로부터 파일의 데이터가 저장되어 있는 주소가 링크 형태로 연결되어 있다. 따라서 FAT의 정보를 따라가면 파일의 전체 데이터를 알 수 있다.
연결 할당에서 한 섹터가 고장나 다음 포인터를 참조하지 못하는 문제를 포인터와 저장공간(FAT)을 따로 분리하여 해결했다. 또한 FAT상 링크만 따라가면 한 파일의 원하는 순서의 블럭을 참조할 수 있으므로 direct access도 가능하다.
FAT는 이렇게 중요한 정보를 저장하는 공간이므로 보통 여러 개의 복사본을 가지고 있다.
free space management
디스크의 비어있는 공간을 관리하는 방법이다.
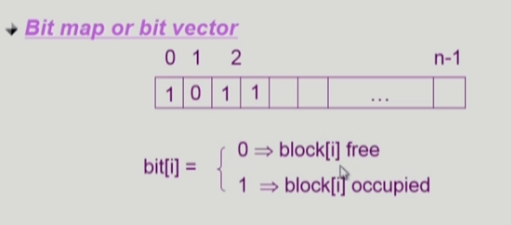
bit map or bit vector
비트맵을 이용하여 해당 위치의 0이나 1의 플래그를 통해 사용중과 비어있음을 나타내는 방법이다. 부가적인 공간을 필요로 하며 연속적인 n개의 free block을 찾는데 효과적이다.
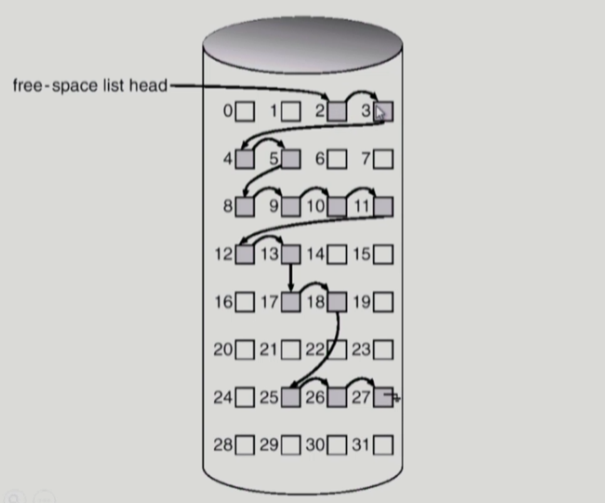
linked list
모든 free block를 링크로 연결하고 시작 부분의 포인터(head)를 따로 저장하는 방법이다. 공간의 낭비가 없다는 장점이 있지만 연속적인 가용 공간을 찾는 것이 쉽지 않다.
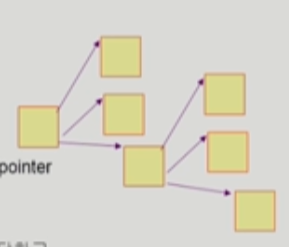
grouping
linked list의 변형으로 첫 번째 free block이 n개의 포인터를 가지게 한다. 이 때 포인터는 각각 새로운 free block을 가리킨다. 그리고 첫 번째 free block의 n-1번째 포인터가 가리키는 블럭이 다시 새로운 free block를 가리킨다. 이 블럭은 또 다시 n개의 포인터를 가진다.
counting
프로그램들이 종종 여러 개의 연속적인 블럭을 할당하고 반납한다는 성질에 착안하여, grouping에서 포인터를 가지고 있는 블럭이 빈 블럭뿐만아니라 빈 블럭의 갯수까지 저장하는 방식이다. 이러면 연속적인 가용공간을 찾기 쉬워진다.
디렉터리
디렉터리는 다음 두 가지 방법으로 구현이 가능하다.

linear list
- 파일 이름, 파일의 메타데이터를 매핑한 리스트
- 구현이 간단함
- 디렉터리 내에 파일이 있는지 찾기 위해서는 선형 시간의 검색이 필요함
hash table
- linear list에 해싱을 적용한 방법
- 해시 테이블은 file 이름을 이 파일의 linear list의 위치로 바꾸어줌
- 검색 시간을 없앰
- 해시 충돌이 발생 가능함
디렉터리에서의 파일 메타데이터 보관 방법은 다음과 같다.
- 디렉터리 내에 직접 보관
- 디렉터리에는 포인터를 두고 다른 곳에 보관(inode, FAT)
디렉터리에서 각 엔트리는 일반적으로 고정 크기를 가진다. 만약 파일 이름이 고정 크기의 엔트리보다 길어지는 경우에는 길어진 파일 이름을 잘라서 뒷부분을 디렉터리 파일의 일부 공간에 따로 저장하고, 엔트리 마지막 부분에 이름의 뒷부분이 위치한 곳의 포인터를 둔다.
VFS, NFS
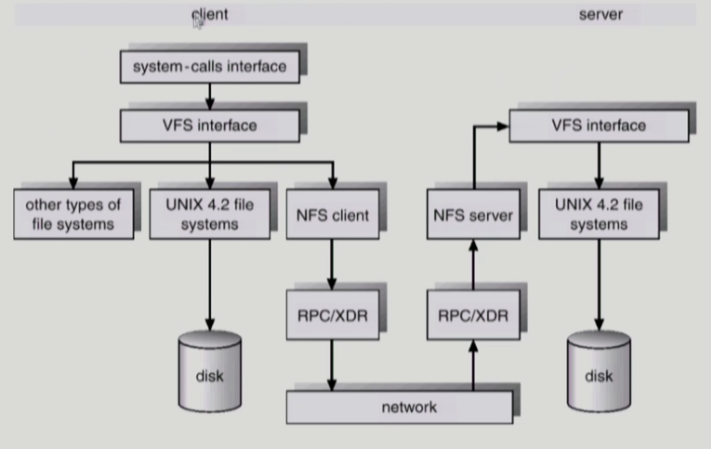
VFS
virtual file system으로 운영체제에 존재하는 서로 다른 다양한 파일 시스템에 대해 동일한 시스템 콜 인터페이스(API)를 통해 접근할 수 있게 해주는 OS의 layer다.
NFS
분산 시스템에서는 네트워크를 통해 파일이 공유될 수 있다. NFS는 분산 환경에서의 대표적인 파일 공유 방법이다. 분산 시스템에서 파일을 공유하기 위해 NFS 클라이언트와 서버가 이용된다.
Page cache & Buffer cache
page cache
가상 메모리의 페이지 프레임을 캐싱의 관점에서 설명하는 용어다. 즉 페이지 프레임 == 페이지 캐시.
buffer cache
파일 시스템을 통한 I/O연산은 메모리의 특정 영역인 버퍼 캐시를 사용한다. OS가 한 번 읽어온 블럭에 대해서 후속 요청을 받으면 다시 블럭을 읽으러 가는 것이 아니라 버퍼 캐시에서 즉시 전달한다. 버퍼 캐시는 모든 프로세스가 공용으로 사용하고, 캐시에 대한 replacement algorithm이 필요(LRU, LFU 등)하다. 하지만 페이징과 달리 OS가 파일 시스템에 대해 모두 총괄하므로 replacement algorithm을 그대로 적용할 수 있다.
memroy-mapped io
파일의 일부를 가상 메모리에 매핑시키는 방법이다. 매핑시킨 영역에 대한 메모리 접근 연산은 파일의 입출력을 수행하게 한다.
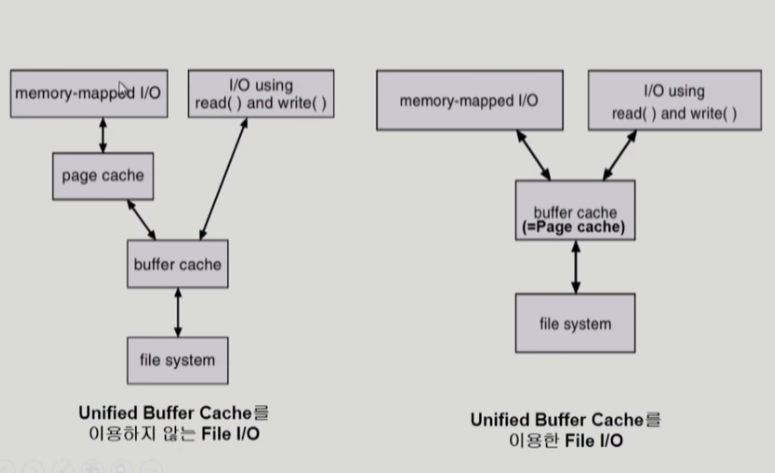
unified buffer cache
최근의 os에서는 기존의 버퍼 캐시가 페이지 캐시에 통합되어 사용되고 있다. 이를 이용하면 페이지 프레임에 파일 블럭의 주소가 올라갈 수 있게 되어 그곳을 접근하면 파일의 입출력을 수행하게 된다.
이 구조에서는 unified buffer cache를 사용한다. 사용자 프로그램이 파일을 접근하는 방식은 두 가지가 존재한다. read() / write() 시스템 콜과 위에서 설명한 memory-mapped I/O가 바로 그것이다.
read(), write()
사용자 프로그램이 read(), write() 시스템 콜을 요청하면 페이지 캐시에 있는 내용을 카피해서 주소 공간에 전달한다. 만약 페이지 캐시에 존재하지 않으면 OS가 해당 파일 내용을 가져와 페이지 캐시에 올린다. 시스템 콜을 요청하게 되므로 파일을 요청할 때마다 오버헤드가 생길 수 있다.
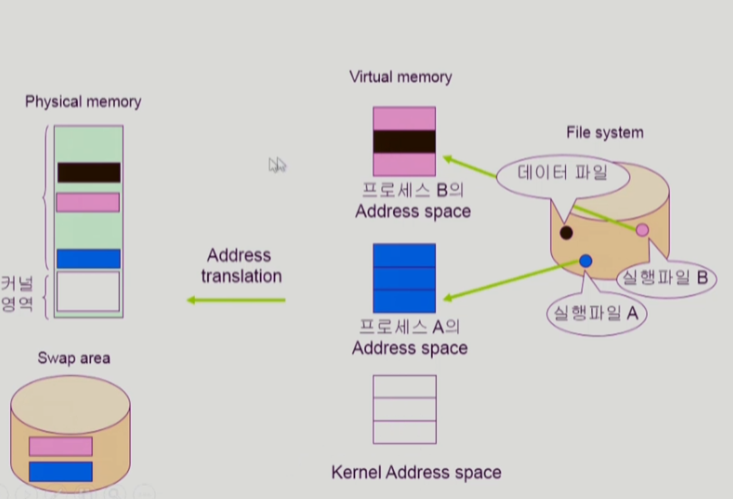
memory-mapped I/O
사용자 프로그램이 OS에게 파일의 일부와 자신의 주소 공간의 일부를 매핑해달라는 요청을 한다. 그러고나서 사용자 프로그램이 자신의 주소 공간에서 해당 메모리(방금 매핑한 파일)를 접근했을 때, 물리적 메모리에 프레임이 존재하지 않는다면 page fault가 일어난다. 그러면 OS가 page fault에 해당하는 페이지를 물리적 메모리에 올려놓는다.
그럼 이때부터는 가상 메모리상의 페이지가 물리적 메모리상의 프레임으로 매핑된다. 따라서 파일을 읽어오는데 OS의 도움을 받지 않고 바로 자신의 주소 공간에서 물리적 메모리의 프레임으로 접근하여 데이터를 읽고 쓸 수 있다.
물리적 메모리에서 쫓겨날 때는 swap area로 가지 않고 파일에 변경된 내용을 쓰고 쫓아낸다.
반효경 교수님의 운영체제 강의를 바탕으로 작성했습니다
