데이터의 접근
데이터의 접근은 다음과 같은 순서로 일어난다.
1. 데이터가 저장되어 있는 공간에 접근한다.
2. 연산할 데이터를 가져온다.
3. 연산을 실행한다.
4. 연산 결과를 다시 저장한다.
ex) cpu-memory, 컴퓨터 내부-디스크, 프로세스-프로세스의 주소 공간
이 때 여러 프로그램이 하나의 저장 공간을 공유하는 경우 경쟁 상태(race condition)의 가능성이 존재한다. 경쟁 상태란 둘 이상의 입력 또는 조작의 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태를 말한다. 예시로는 멀티프로세서 시스템, 공유 메모리를 사용하는 프로세스들, 커널 내부 데이터를 접근하는 루틴들이 있다.
OS에서 경쟁 상태는 여러 프로세서들이 동시에 공유데이터를 접근하는 상황을 의미하며 또 데이터의 최종 연산 결과가 마지막에 그 데이터를 다룬 프로세서에 따라 달라지게 된다.
OS에서의 경쟁 상태는 언제 생기는가?
1. 커널 수행 중 인터럽트 발생 시
커널에서 count++의 작업중 인터럽트가 발생하고, 인터럽트 핸들러가 count--를 실행한 다음 다시 돌아오면 커널에서는 인터럽트 핸들러가 count--를 수행하기 전의 값을 갖고 있으므로 인터럽트 핸들러가 수행한 count--는 무시될 수 있다.
-> 커널이 작업을 수행중이면 인터럽트가 발생하더라도 먼저 하던 작업을 먼저 다 끝낸 뒤 인터럽트 처리 루틴을 실행하면 해결할 수 있다.
2. 프로세스가 시스템 콜을 하여 커널 모드로 수행중인데 문맥 교환이 일어나는 경우
프로세스1이 커널에서 count++ 작업중 cpu 할당 시간이 끝나서 다른 프로세스2로 cpu가 넘어가고, 커널에서 count++ 작업을 마친 뒤 cpu 할당 시간이 끝나서 다시 본래의 프로세스1로 돌아온다면, 프로세스1에서는 프로세스2 이전의 count 값을 갖고 있으므로 프로세스2의 작업이 무시될 수 있다.
-> 커널 모드에서 수행중일 때는 cpu를 선점당하지 않게 하고, 사용자 모드로 돌아갈 때 선점하게 한다.
3. 멀티 프로세서에서 공유 메모리 내의 커널 데이터
cpu1과 cpu2가 공유 메모리내의 데이터를 각각 가져가서 연산을 하고 다시 저장할 때, 누가 마지막으로 데이터를 저장했는가에 따라 어느 한 값이 무시된다.
방법 1) 커널 전체의 Lock를 걸어 한번에 하나의 cpu만이 커널에 들어갈 수 있게 한다. (비효율적)
방법 2) 커널 내부에 있는 각 공유 데이터에 접근할 때마다 그 데이터에 대한 Lock/Unlock을 한다.
방법2가 효율적이라 채택된다.
프로세스 동기화(synchronization) 문제
공유 데이터의 동시접근은 데이터의 불일치 문제를 발생시킬 수 있다. 따라서 일관성 유지를 위해서는 협력 프로세스간의 실행 순서를 정해주는 메커니즘이 필요하다.
즉 경쟁 상태를 막기 위해서는, 프로세스들은 서로 동기화되어야 한다.
임계영역(Critical-Section)
각 프로세스의 공유 데이터를 접근하는 코드가 존재한다. 이를 임계영역(Critical-Section)이라고 부른다.
프로세스 동기화를 위해선 하나의 프로세스가 임계영역에 있을 때 다른 모든 프로세스는 임계영역에 들어갈 수 없어야한다. 그리고 이를 해결하기 위한 프로그램적 해결법의 조건이 세 가지 존재한다.
mutual exclusion(상호 배제)
- 프로세스가 임계영역을 수행중이면 다른 모든 프로세스들은 그들의 임계영역에 들어가면 안된다.
progress(진행)
- 아무도 임계영역에 있지 않은 상태에서 들어가고자 하는 프로세스가 있으면 들어가게 해줘야한다.
bounded waiting(유한 대기)
- 프로세스가 임계영역에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 임계영역에 들어가는 횟수에는 한계가 있어야 한다.
알고리즘들
알고리즘 1

자신의 turn이 되면 임계영역을 실행하고 turn을 다른 수로 바뀌어서 다른 차례로 넘긴다.
progress를 만족하지 못한다.
알고리즘 2

flag을 이용하여 임계영역에 들어갈 때 나의 flag를 true로 설정한다음, 만약 다른 flag들이 true라면 대기했다가 false가 되는 순간 임계영역을 수행하고 나와서 나의 flag를 다시 false로 설정한다.
역시 progress를 만족하지 못하며, 만약 두 프로세스가 동시에 true가 됐을 경우 둘다 끊임 없이 양보하는 상황이 발생 가능하다.
알고리즘 3(peterson's algorithm)

위에서 설명했던 flag과 turn을 전부 사용하여 모든 조건을 만족시킨다.
busy waiting 문제가 존재한다.
세마포어(Semaphore)
세마포어는 앞의 방식들을 추상화시킨 방법이다. 세마포어는 두 개의 연산을 가진다.
Semaphore S에서(S는 정수)
P(S) -> 자원이 있으면 하나 가져가고 없으면 while문을 돌며 기다린다.
V(S) -> 자원을 다 사용하고 반납하는 과정이다.
세마포어의 종류는 두 가지가 존재한다.
counting semaphore
- 세마포어의 S가 범위가 0 이상인 임의의 정수 값이다. 자원의 숫자를 세는 데에 사용한다.
binery semaphore(mutex)
- 세마포어의 S가 0 또는 1의 값만 가질 수 있는 세마포어로 주로 Lock/Unlock에 사용한다. 뮤텍스라고도 한다.

위 코드는 뮤텍스의 구현 방식으로, P연산을 통해 만약 뮤텍스가 0이면 기다리고, 1이면 뮤텍스에서 1을 빼고 임계영역에 들어가게 된다. 임계영역이 끝나면 V연산을 통해 뮤텍스를 다시 1로 만들어 준다.
counting semaphore도 마찬가지로, 단지 자원의 숫자가 늘어나서 임계영역에 들어갈 수 있는 프로세스가 자원의 숫자만큼 늘어나는 것뿐이다.
여기서 뮤텍스를 기다릴 때 busy-waiting을 하게 되는데, 이것이 비효율적이라서 block/wakeup 방식의 구현이 존재한다.
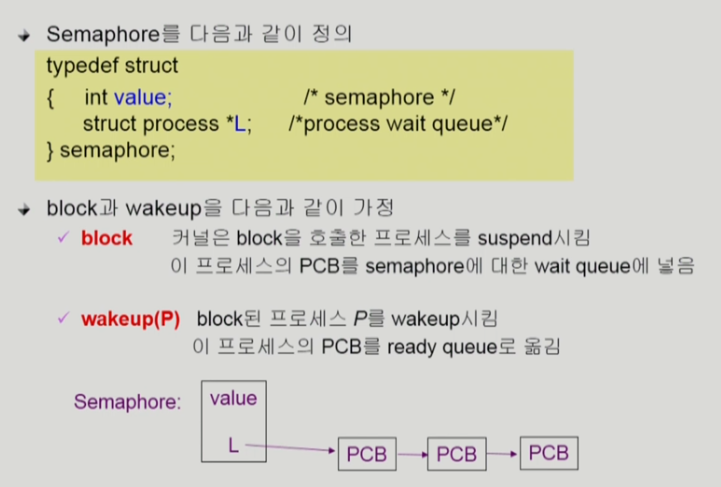
block/wakeup 방식은 위에서 기다릴 때 while문을 돌면서 기다리는 대신에 해당 프로세스를 block시킨다.
그렇다면 어느 방식을 사용하는 것이 좋을까? 일반적으로는 block/wakeup방식이 더 좋지만 임계영역의 길이가 긴 경우에는 block/wakeup 방식이 필요하고, 임계영역의 길이가 매우 짧은 경우에는 block 방식의 오버헤드가 busy-wating 오버헤드보다 커질 수 있어 busy-wating을 써도 적당하다.
모니터(Monitor)
세마포어는 다음과 같은 문제점을 가진다.
1. 코딩하기 힘들다.
2. 정확성의 입증이 어렵다.
3. 자발적 협력이 필요하다.
4. 한번의 실수가 모든 시스템에 치명적인 영향을 미친다.
따라서 프로그래밍 언어차원에서 공유 데이터 접근 문제를 해결해주는 프로그램인 모니터를 사용할 수 있다. 프로그래머는 모니터안에 공유 데이터 접근 관련 코드를 정의해서 프로세스가 모니터안의 코드만을 이용해서 공유 데이터에 접근할 수 있게 할 수 있다. 또한 모니터는 프로세스 하나만이 모니터안의 코드를 실행할 수 있게 제어해준다. 다른 프로세스가 모니터 안의 코드를 실행하려고 할 때 이미 다른 프로세스가 코드를 실행중이라면, 바깥의 큐에서 줄을 서게 된다.
모니터에서는 프로그래머가 동기화 제약 조건을 명시적을 코딩하지 않아도된다. 즉 Lock를 직접 걸지 않아도 된다. 모니터에서 프로세스는 코드를 수행할 때 특정 조건을 위해 중지될 수 있다. 이런 프로세스가 모니터 안에서 기다릴 수 있도록 하기 위해서 condition 변수를 사용한다. 그리고 이 변수에는 wait과 signal 연산이 존재한다.
condition x가 존재할 때, x.wait()을 호출한 프로세스는 다른 프로세스가 x.signal()을 호출하기 전까지 중지된다. x.signal()은 정확하게 하나의 중지된 프로세스를 재개시킨다. 만약 중지된 프로세스가 없으면 아무 일도 일어나지 않는다.
Bounded-Buffer Problem(producer-consumer problem)
생산자-소비자 문제라고도 한다. 어떤 유한한 개수의 버퍼에 여러 명의 생산자와 소비자들이 접근한다. 여기서 생산자는 데이터를 버퍼에 쓰고, 소비자는 데이터가 쓰여진 버퍼를 비운다.
생산자는 데이터가 하나 만들어지면 이것을 버퍼에 저장한다. 이 때 버퍼들이 전부 꽉차있어서 저장할 버퍼가 없는 문제가 발생할 수 있다. 또, 소비자는 데이터가 필요하면 데이터가 쓰여진 버퍼들 중 하나를 가져온다. 이 때 내용이 꽉차있는 버퍼가 없어서 가져올 버퍼가 없는 문제가 발생할 수 있다.
여기다가 여러 명의 생산자 또는 여러 명의 소비자가 하나의 버퍼에 접근을 할 수 있는 공유 데이터에 대한 접근에 관한 문제도 생길 수 있다.
첫 번째 문제를 해결하기 위해 생산자는 빈 버퍼가 없다면 빈 버퍼가 생길 때까지 기다렸다가, 빈 버퍼가 생기면 작업을 시작한다. 소비자도 마찬가지로 꽉 찬 버퍼가 없다면, 꽉 찬 버퍼가 생길 때까지 기다린다. 두 번째 문제를 해결하기 위해서는 생산자와 소비자는 버퍼를 사용할 때 Lock을 걸어줄 수 있다. 버퍼에 작업을 끝내면 Lock을 풀어준다.
이런 작업을 위해서 세마포어를 사용할 수 있다. 꽉 찬 버퍼와 빈 버퍼를 표시하는데 counting semaphore를 사용할 수 있고, Lock을 걸기 위해 binary semaphore를 사용할 수 있다.
Readers-Writers Problem
reader는 데이터를 읽기만 하는 프로세스고, writer는 데이터를 쓰기만 하는 프로세스다. 이 둘의 차이점은 데이터를 쓸 수 있냐 없냐다. 이 문제는 여러 명의 reader와 writer들이 하나의 공유 저장소를 접근할 때 생길 수 있는 문제에 관한 것이다.
이 문제에서 한 프로세스가 저장소에 데이터를 쓰고 있을 때는 다른 reader나 writer들은 저장소에 접근하면 안된다. 또 읽기를 할 때는 여러 명의 reader들이 동시 접근이 가능하다. 데이터를 쓰지 않기 때문이다.
이것을 해결하기 위한 방법은 다음과 같다.
1. writer가 DB에 접근 허가를 얻지 못한 상태에서는 모든 reader들이 접근 가능하다.
2. writer는 대기 중인 reader가 하나도 없을 경우 공유 저장소에 접근 가능하다.
3. writer가 공유 저장소에 접근 중이면 reader들은 접근이 금지된다.
4. writer가 공유 저장소에서 빠져나가야지만 reader들의 접근이 허용된다.
다만, 이 때 reader들이 계속 쉬지않고 들어온다면 writer는 접근 허가를 계속 얻지 못해 기아 상태에 빠질 수 있다. 이는 어느 정도 reader들이 들어오면 다음 들어오는 reader들은 잠시 멈추고 writer에게 기회를 한번씩 주는 형태로 해결할 수 있다.
식사하는 철학자 문제
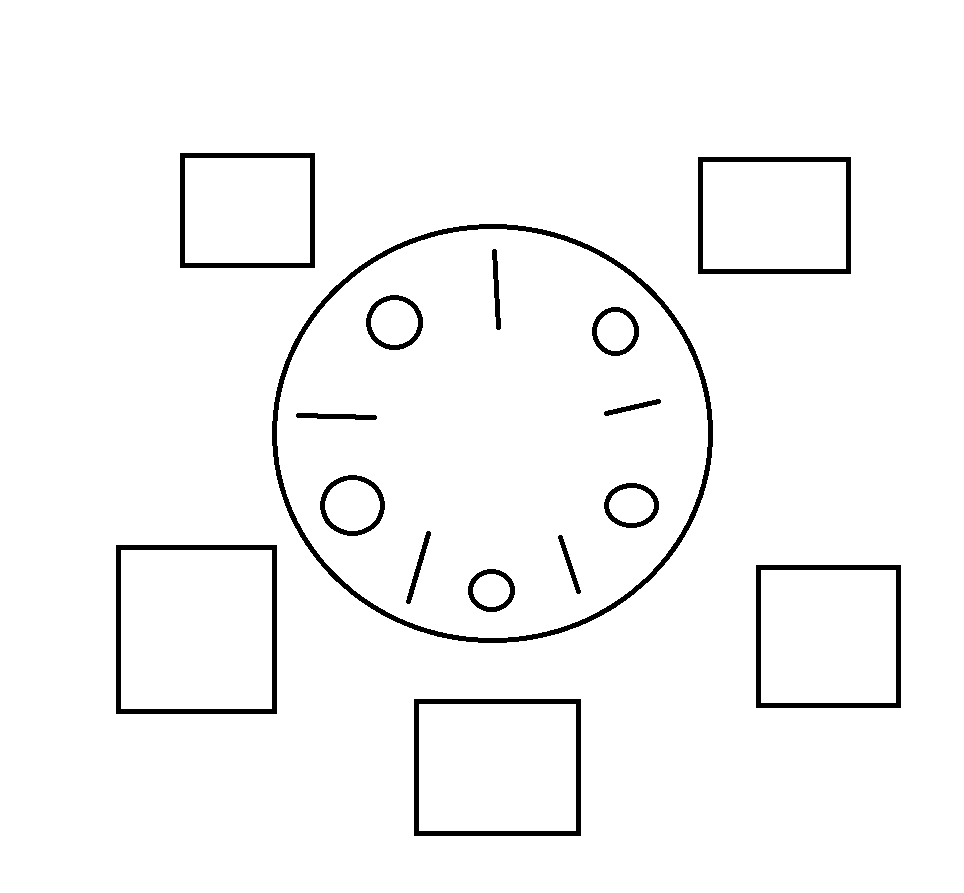
위와 같은 테이블에서 철학자 5명이 식사를 한다. 철학자 자신의 왼쪽과 오른쪽에 있는 포크를 하나씩 모두 집어야 식사를 할 수 있다.
여기서 여러 문제가 발생하는데 먼저 한 철학자의 왼쪽, 오른쪽 철학가가 계속 양쪽 포크를 집고 식사를 한다면 이 철학자는 기아 상태에 빠질 것이다. 또 모든 철학자가 동시에 왼쪽/오른쪽 포크를 집은 경우에는 deadlock 상태에 빠지게 될 것이다.
이를 위한 해결방안은 다음과 같다.
1. 4명의 철학자만이 테이블에 동시에 앉을 수 있도록 한다.
2. 포크를 두 개 모두 집을 수 있을 때만 집을 수 있게 한다.
3. 짝수 철학자는 왼쪽 포크부터, 홀수 철학자는 오른쪽 포크부터 집도록 한다.
4. 포크의 갯수를 늘린다.
이 외에도 더 많은 해결방법이 있을 수 있다.
반효경 교수님의 운영체제 강의를 바탕으로 작성했습니다
