시작하기 전
GopherCon 2021: Madhav Jivrajani - Queues, Fairness, and The Go Scheduler와 구글링을 통해 정리했다.
Goroutine runtime
go 코드를 작성 후 컴파일하면 바이너리 파일에 go runtime이 같이 컴파일된다. 바이너리를 실행할 때 해당 runtime이 go의 gc와, goroutine의 스케줄링을 실시한다.
다음과 같은 코드가 있다고 생각해보자.
func main() {
go doSomething()
doAnotherThing()
}위 코드를 컴파일하면 아래와 같이 바뀐다.
func main() {
runtime.newProc(...)
doAnotherThing()
}runtime.newProc()은 우리가 작성한 함수를 실행하는 새로운 G 구조체를 만든다.
https://go.dev/src/runtime/proc.go

G 구조체는 고루틴이다. 우리가 방금 작성한 함수에 대한 레퍼런스, stack등 고루틴을 실행하는 데에 필요한 여러 context들을 포함하고 있다.
이렇게 runtime은 우리가 작성한 함수를 호출하고 system call을 하여 OS 쓰레드와 매핑하거나, 메모리를 관리하는 역할을 한다.
N:M
G 는 실행되려면 OS의 쓰레드에 매핑되어야 한다.
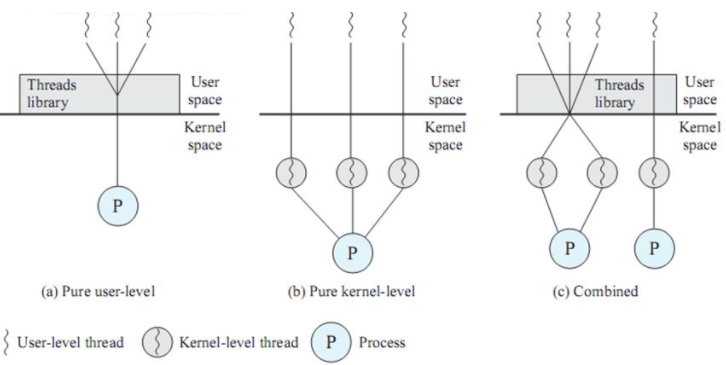
고루틴은 세 개의 구현 방법중 (c)인 N:M 스케줄링을 한다.
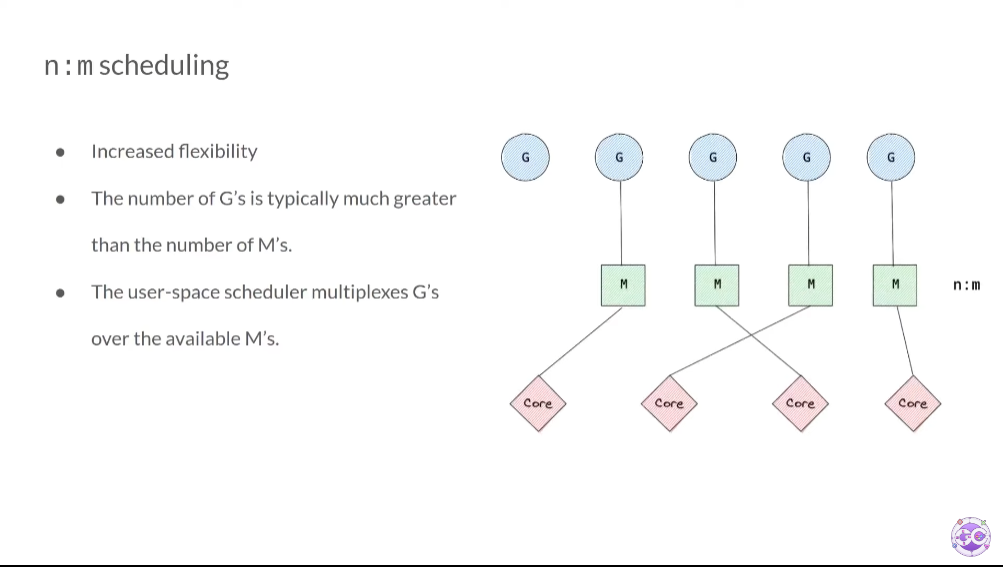
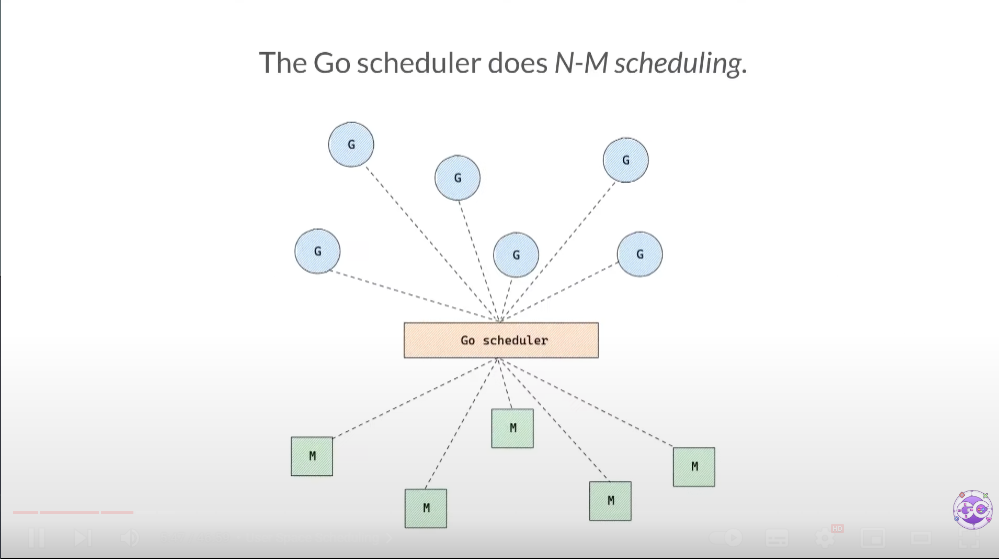
M은 OS 쓰레드를 의미한다. 이 쓰레드에 G 가 매핑되어 실행된다. 주의해야할 점은, N:M이라는 것이다. 하나의 M에 G가 종속되지 않는다. 다른 M에서도 실행될 수 있다.
G의 개수는 M의 개수보다 일반적으로 많다.
Global runqueue
그렇다면 아직 실행되지 않은 G는 어디다가 저장해두는 것일까?
바로 global runqueue에 저장한다. global runqueue는 FIFO 구조를 가진다.
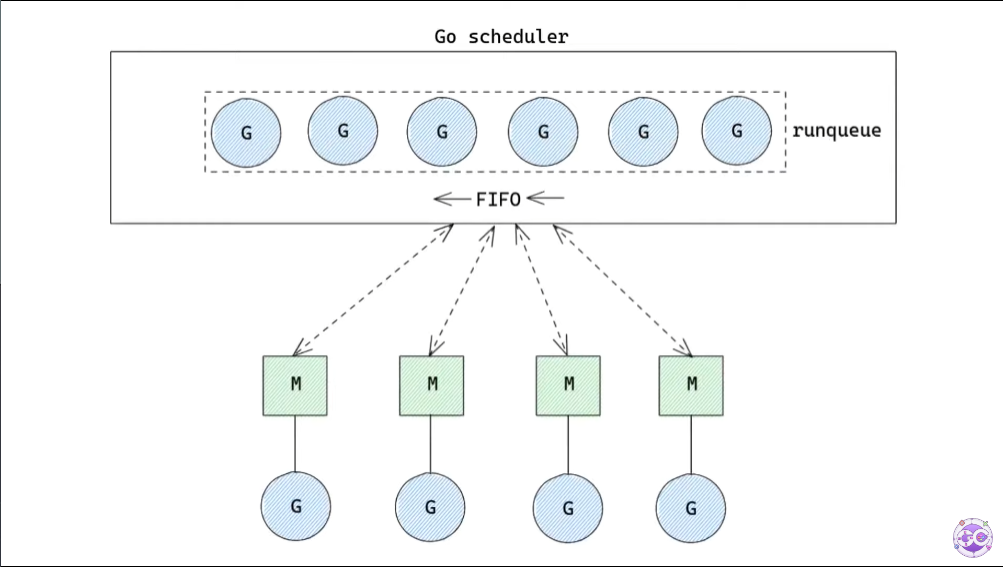
이 구조에서 M은 global runqueue에서 G를 하나씩 가져다가 실행한다.
이 때 고려해야 될 것이 몇 가지 있다.
첫 번째로, global runqueue는 하나의 자료 구조이므로 여러 개의 M이 동시에 사용하면 race condition이 발생할 것이다.
이를 해결하기 위해 Lock을 사용한다.
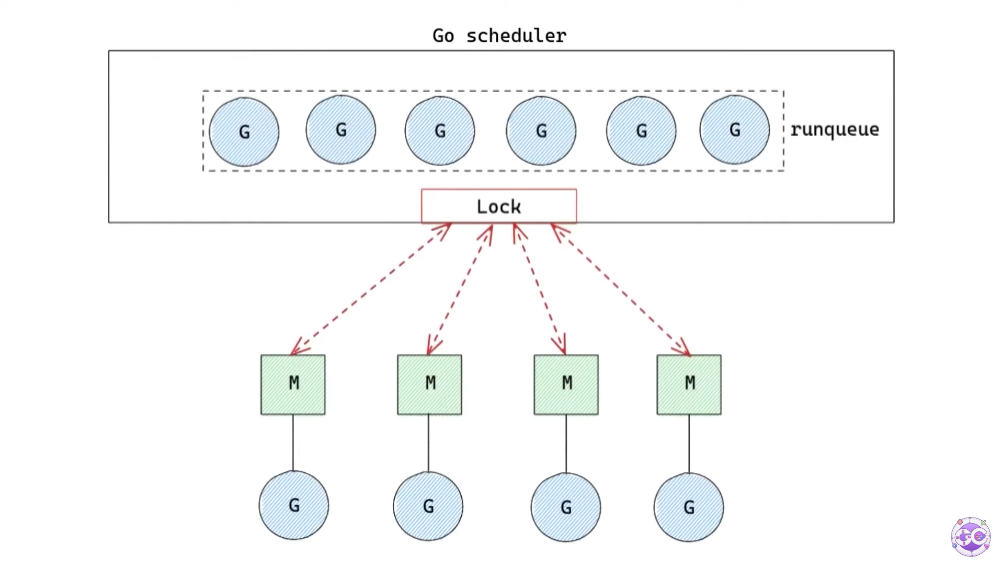
하지만 M이 G를 갖기 위해 Lock을 기다려야 하고, 이는 당연히 엄청난 성능저하로 이어진다.
또, 만약 하나의 고루틴이 엄청 긴 실행 시간을 갖고 있다면 어떨까? 다른 실행되지 않은 고루틴은 기아 상태에 빠질 수 있을 것이다.
이를 해결하기 위해 시분할 시스템을 사용할 수 있다. 각 고루틴마다 실행 시간을 정해주는 것이다.
하지만 만약 각 고루틴에 짧은 실행 시간을 정해준다면, 하나의 global runqueue로는 빈번한 context switching으로 인한 오버헤드와, poor locality가 발생할 것이다.
이 문제들을 해결하기 위해 runqueue를 여러 개로 분산하는 방법이 도입됐다.
local runqueue
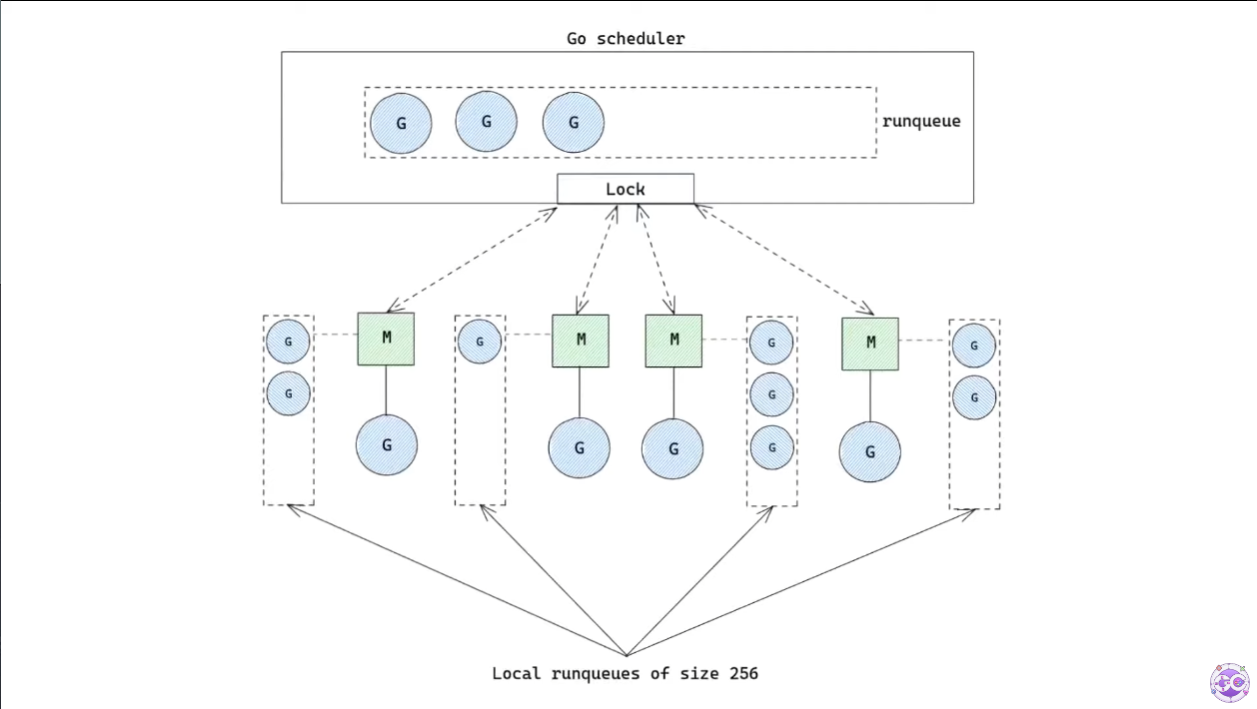
이제, 각 M은 local runqueue를 하나씩 가지게 된다. M은 이제 local runqueue에 저장된 G를 하나씩 가져와 실행하게 된다.
M은 local runqueue에 G가 없다면 여전히 global runqueue에서 가져오게 되지만, global runqueue를 접근하는 것보다 local runqueue를 더 자주 접근하게 되기 때문에 lock에 의한 성능 저하 문제도 해결된다.
go 1.17.2 버전 기준으로 local runqueue는 256개의 G를 저장할 수 있다.
GOMAXPROCS
The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit.
GOMAXPROCS 변수는 코드를 동시에 실행하는 OS 쓰레드의 갯수를 제한한다.
GOMAXPROCS가 6이라면, 코드를 실행하는 OS 쓰레드의 갯수는 6개가 최대다.
하지만 system call로 block 당한 쓰레드는 GOMAXPROCS에 해당하지 않는다.
즉, 6개의 실행중인 쓰레드를 제외하고 block된 많은 쓰레드를 가지고 있을 수 있다.
각 M은 local runqueue의 정보를 갖고 있어야 한다. 하지만 block된 쓰레드가 local runqueue를 갖고 있을 필요는 없다. block되지 않은 다른 쓰레드가 해당 local runqueue의 정보를 받아 G를 실행하면 된다.
또 Go Scheduler는 M에게 남은 G가 없다면, work stealing을 통해 다른 M의 local runqueue에 있는 G들을 뺏어와 작업한다.
코드를 실행하는 OS 쓰레드의 갯수는 GOMAXPROCS로 제한되지만, GOMAXPROCS에 해당하지 않는 block당한 쓰레드가 있을 수도 있으므로 work stealing을 구현하기 위해선 block당한 쓰레드들의 local runqueue도 살펴보아야 한다.
하지만 block된 쓰레드의 갯수는 제한이 없다. 즉 체크 해봐야할 쓰레드의 갯수가 무한하다는 것이다.
이를 해결하기 위해 P 구조체를 사용한다.
P 구조체
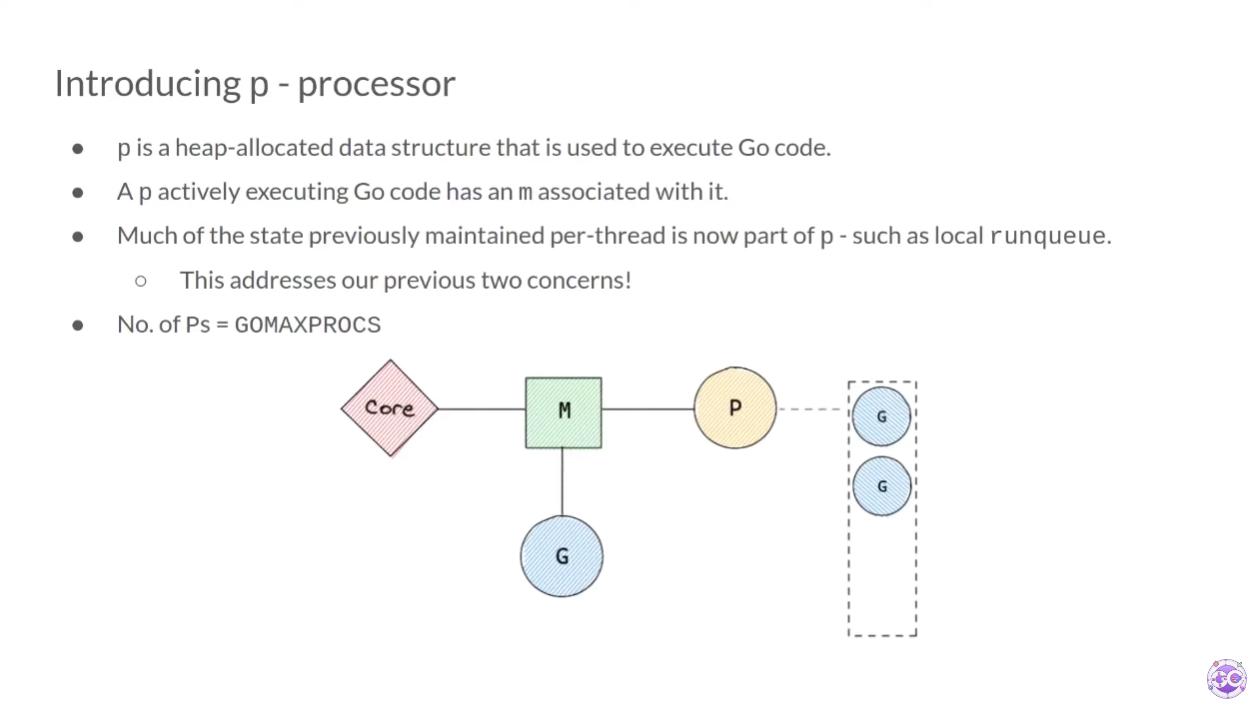
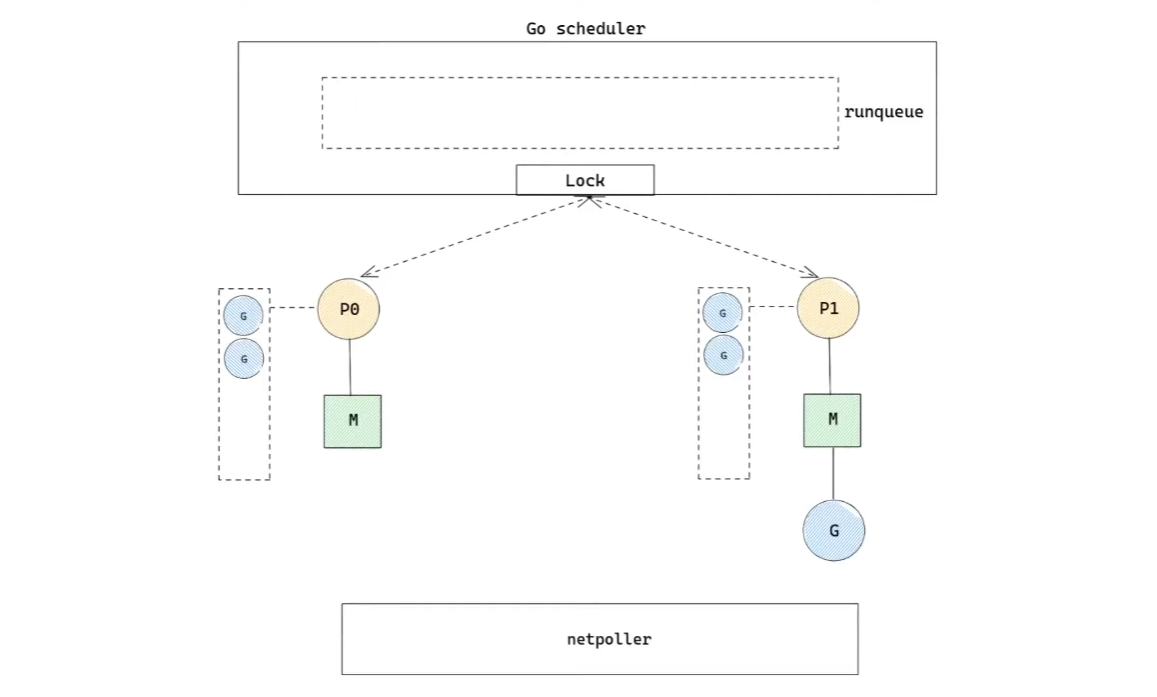
P 구조체는 heap에 할당되는 자료 구조다. P는 하나의 M에 할당된다. 따라서 P는 GOMAXPROCS의 갯수와 같다. 이제 M은 G를 실행하기 위해 P를 참조하게 된다.
위에까지는 각 M이 local runqueue를 갖고 있었지만, 이제부터는 각 P가 local runqueue를 갖게 된다.
또, local runqueue뿐만 아니라 코드를 실행하기 위해 M이 유지하고 있던 context도 전부 P에 저장한다.
자, 이제 우리가 가지고 있던 문제들을 살펴보자.
block된 쓰레드가 local runqueue를 갖고 있던 문제는 block된 M이 P를 다른 M에게 넘겨주면 해결된다.
work stealing을 위해 체크해봐야 할 쓰레드의 갯수가 무한하다는 문제는 P가 local runqueue를 갖게 됐고, P의 갯수는 GOMAXPROCS로 유한하게 되었으므로 해결됐다. P들만 체크해보면 된다.
Go scheduling
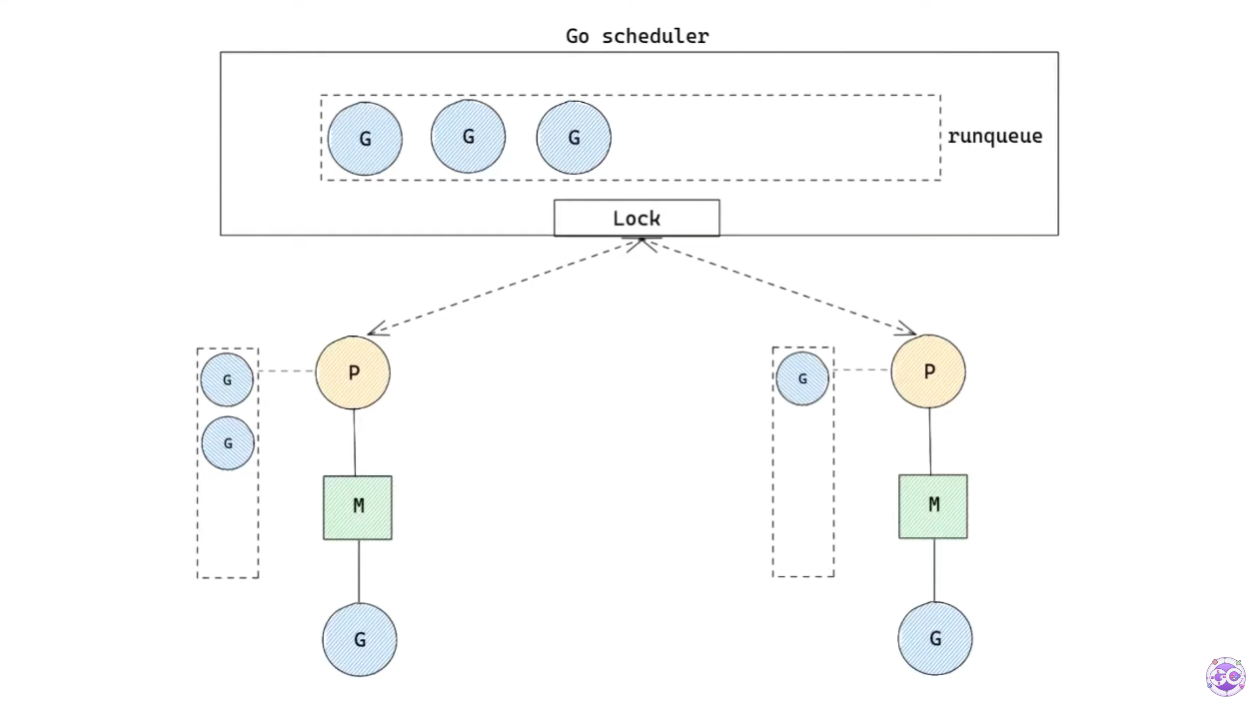
이제 Go scheduler는 위와 같은 형태를 갖추게 된다. 그렇다면 스케줄링은 정확히 어떻게 일어나는지 알아보자.
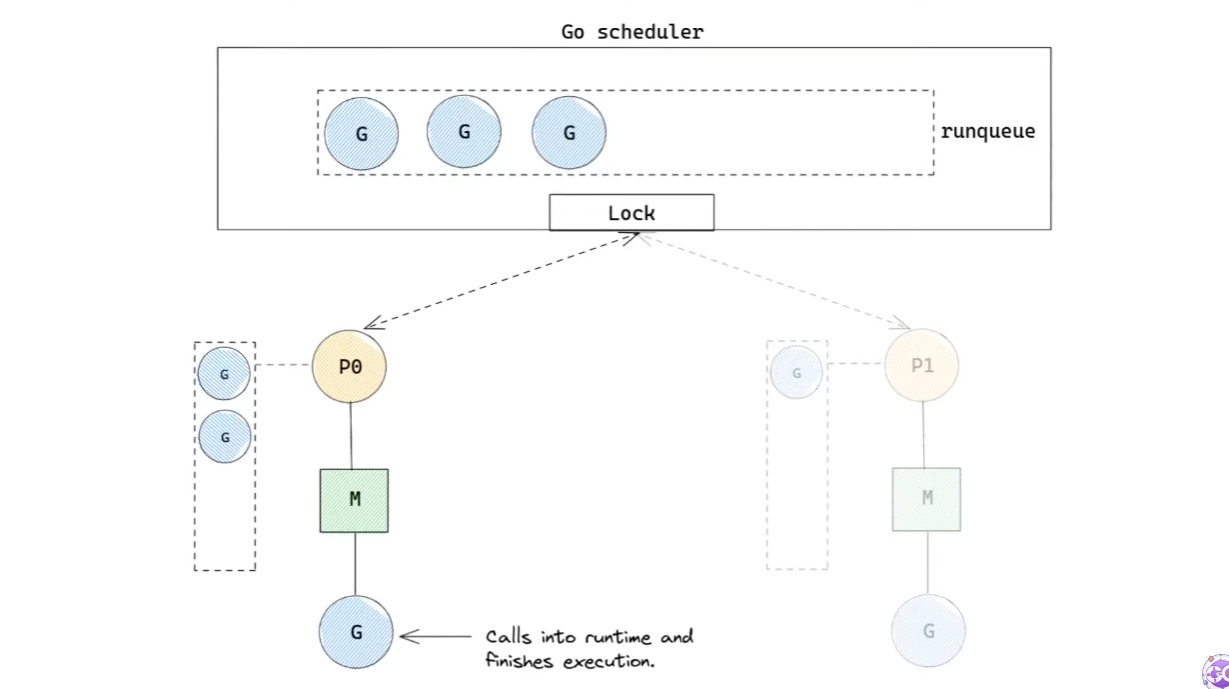
M은P0의 local runqueue에서G를 가져와 실행한다.G의 실행이 종료되면,M은P0의 local runqueue에 실행할G가 있는지 확인한다.- 만약 존재한다면, 가져와서 실행한다.
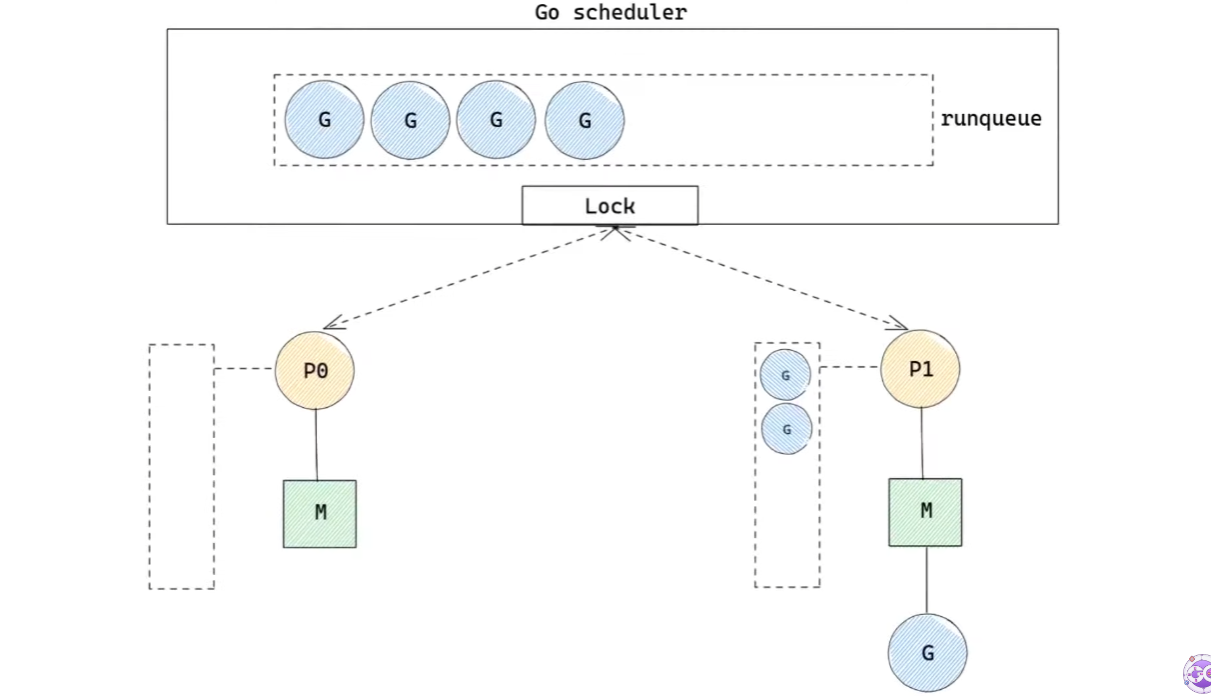
- 이제 모든
G를 실행하여 local runqueue가 비었다.- 그렇다면, global runqueue에 실행할
G가 있는지 확인한다.- 만약 존재한다면,
global runqueue의 현재 길이/GOMAXPROCS + 1만큼G를 가져온다.
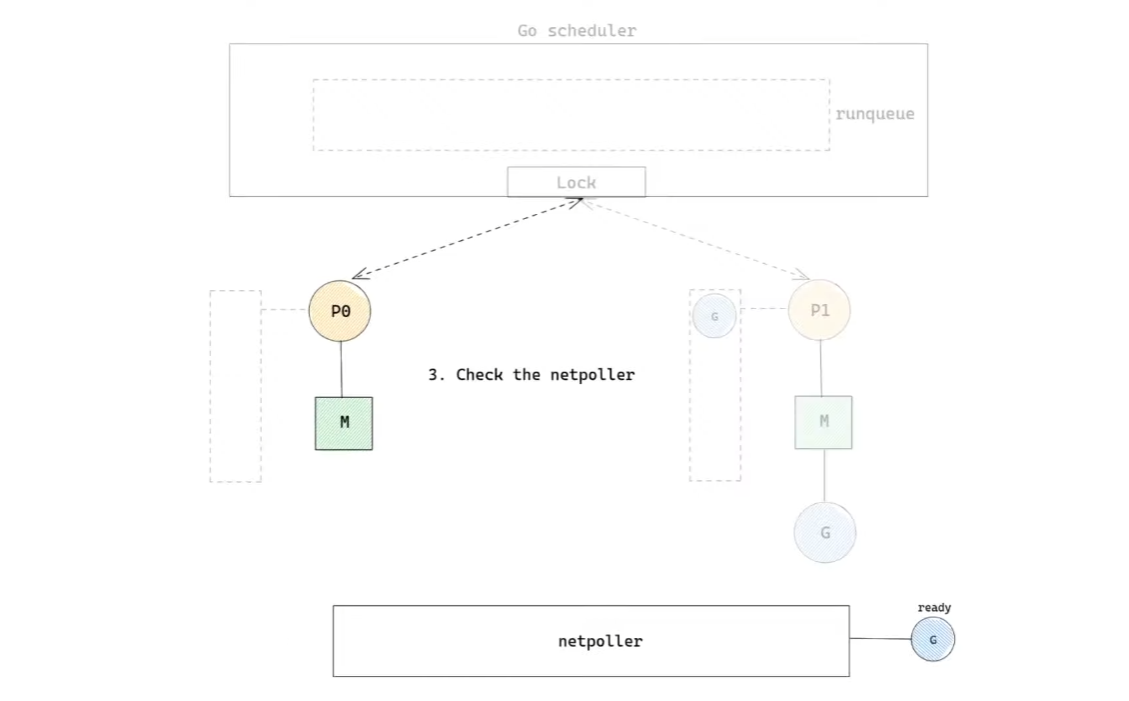
- 이제 global queue가 비었다.
- 그렇다면, netpoller에 준비된
G가 있는지 확인한다.- 만약 존재한다면, 가져와서 실행한다.
netpoller는 Go runtime에서 비동기 네트워크 I/O system call을 담당하는 component다.
만약 G가 네트워크 I/O를 하게 되면, G를 실행하던 M은 blocking되는 대신, 해당 G를 netpoller에서 기다리게 한다. 그리고 M은 blocking되지 않고 다른 G를 실행한다.
그리고 만약 I/O가 완료되면 G는 자신이 준비됐다고 알린다. 이렇게 M을 blocking되지 않게 만들어 성능을 향상시킨다.
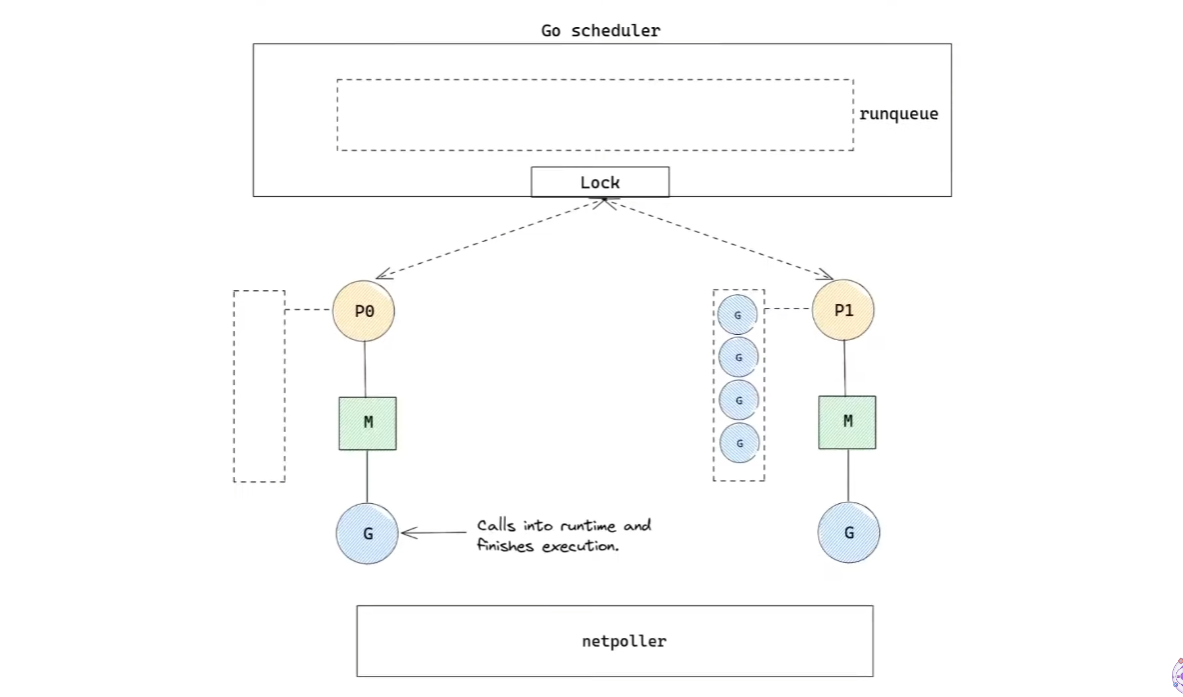
- 이제 netpoller도 비었다.
- 그렇다면, 이제부터는 랜덤하게
P를 하나를 선택한다.- 그리고 선택한
P의 local runqueue의 반을 가져온다. (work stealing)- 가져온
G를 실행한다.
공정성
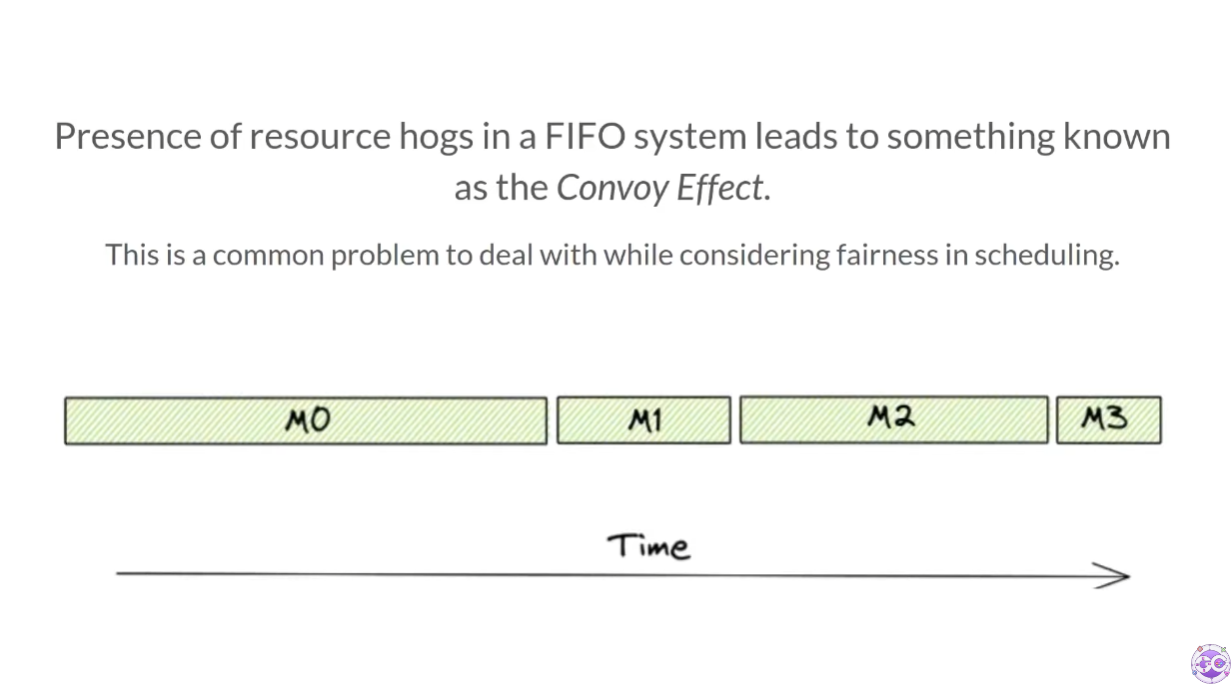
지금까지 go scheduler는 FIFO 시스템으로 G를 처리하고 있었다. 만약 어떤 G의 실행 시간이 매우 길다면 다른 G들은 실행 시간을 할당 받지 못하고 기아 상태에 빠지거나 convoy effect가 발생할 것이다.
이를 해결하는 방법 중 하나는 간단하게 실행 시간이 짧은 G를 먼저 실행하는 것이다. 하지만 각 G의 실행 시간을 미리 파악해야 하는 문제점이 있다. 사실 거의 불가능하다고 말할 수 있다.
다른 방법은 Preemptive Scheduling과 Cooperative Scheduling를 사용할 수 있다.
Cooperative Scheduling는 작업이 완료될 때까지 또는 태스크에서 스스로 자원을 내려놓을 때까지 모든 자원을 독점하는 스케줄링 방식이다.
Preemptive Scheduling는 우리가 익히 아는 선점형 방식으로, 시분할 시스템을 이용하여 일정 시간이 지나면 태스크로부터 자원을 빼앗아 다른 태스크에게 넘겨주는 방식이다.
Go는 Cooperative Scheduling을 사용했으나, 1.14버전부터는 Preemptive Scheduling을 사용한다.

각 G는 10ms 시간을 할당받는다. 10ms가 지난다면, SIGURG signal이 발생해 선점당한다. 우리가 흔히 아는 커널 영역에서의 인터럽트와 비슷하지만, signal이 userspace에서 일어난다는 점에서 다르다.
signal은 선점 당할 G가 실행되고 있는 M에 전달된다.
그렇다면 이 signal는 누가 보내줄까? 바로 sysmon이라는 쓰레드가 한다.
sysmon
go runtime에는 sysmon이라고 하는 Daemon thread가 존재한다.
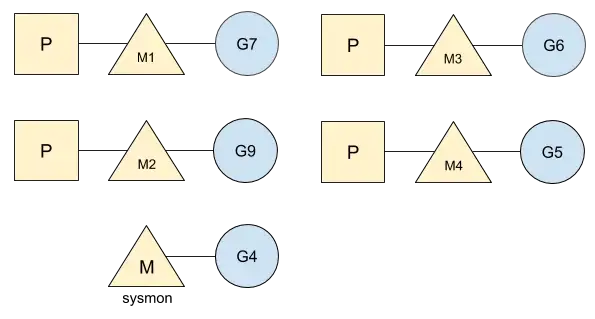
sysmon은 P 없이 G를 실행하며, 고루틴들을 모니터링하는 역할을 한다.
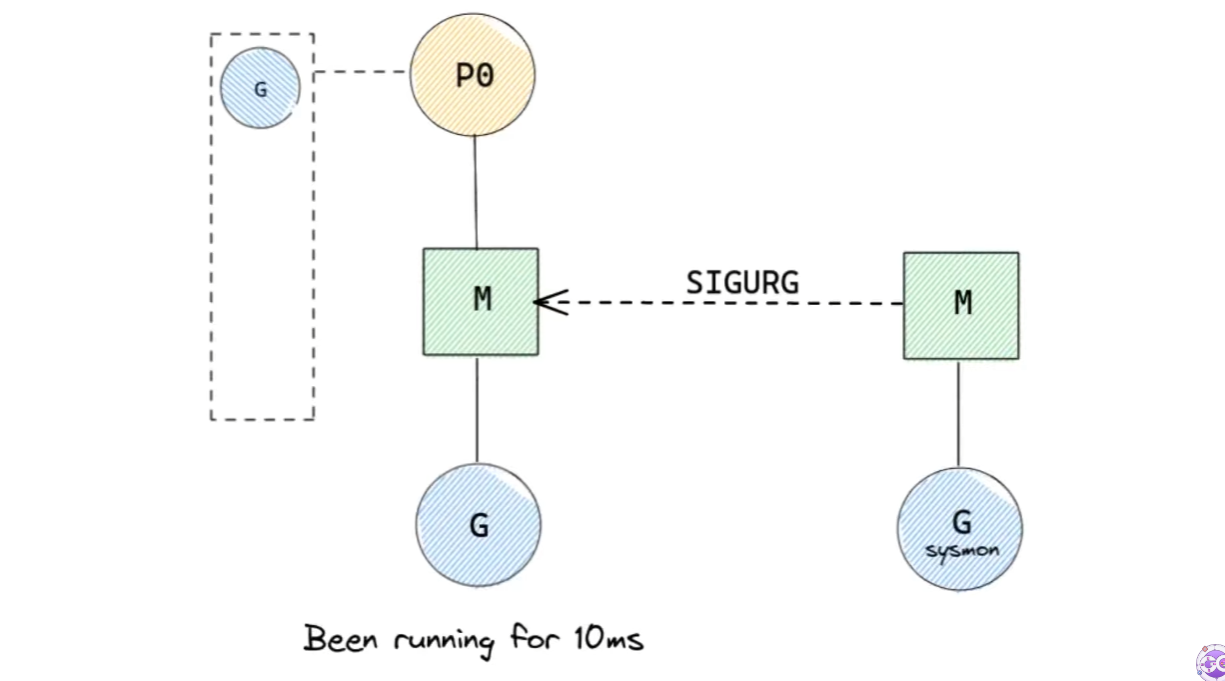
어떤 G의 실행 시간이 10ms가 넘으면, 해당 G를 실행하고 있는 M에게 선점 signal을 보낸다. 선점 signal을 받은 M은 G를 global runqueue에 보내게 된다.
Goroutine locality
G는 또 다른 G를 생성할 수 있다.
func main() {
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
doSomething()
}()
}
wg.Wait()
}
위 코드를 실행 시키면 main G가 10개의 새로운 G를 만들게 될 것이다. 생성된 G는 FIFO 방식을 따라 local runqueue의 tail로 들어가게 된다.
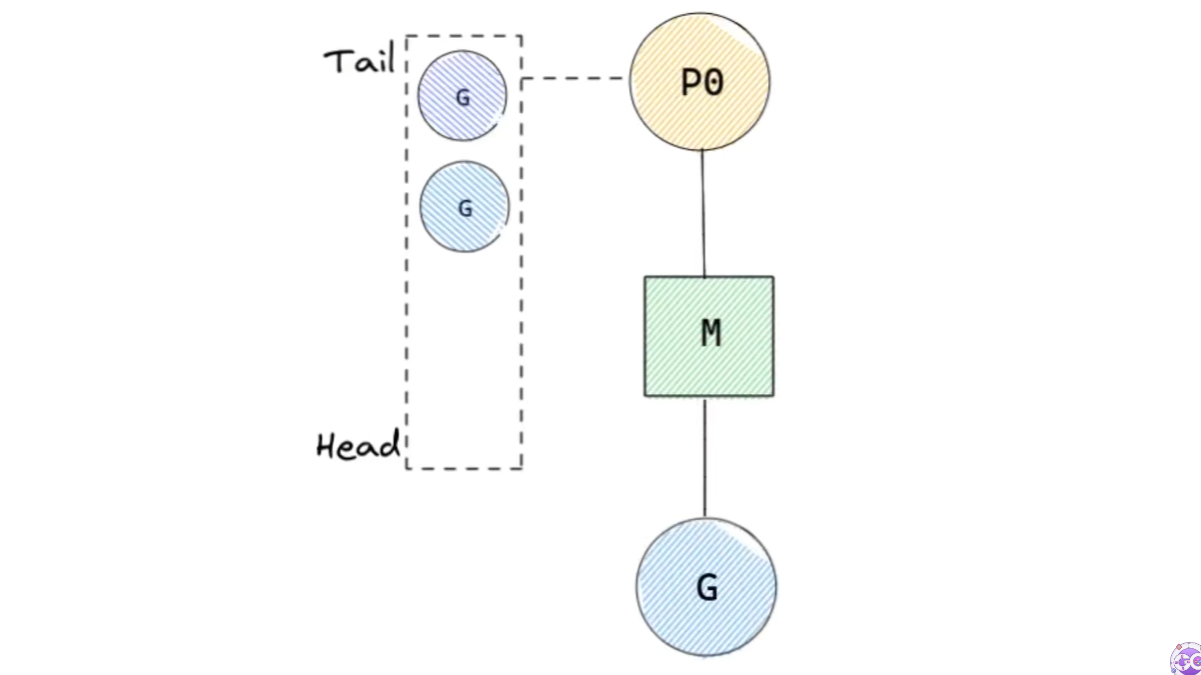
이렇게 FIFO를 사용하면 각 G가 동등하게 실행될 수 있으므로 공정하다. 하지만 locality 면에서는 좋지 않다. 방금 생성한 G를 다른 G를 전부 처리하고 나서 참조하게 되기 때문에 프로세서의 캐시, 스택을 사용하지 못하기 때문이다.
그렇다고 stack처럼 LIFO를 사용하면 locality를 극복할 수 있겠지만, 공정하지 않다.
또 다른 예시를 하나 보자. 이번에는 sender와 reciever가 존재한다.
func sender(ch chan int) {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}
func reciever(ch chan int) {
for {
msg, ok := <- ch
if !ok {
break
}
process(msg)
}
}
func process(msg int) {
fmt.Println("Reciedved:", msg)
}
func main() {
ch := make(chan int)
go sender(ch)
reciever(ch)
}위 코드를 실행할 때 go scheduler에서 발생하는 일을 살펴보자.
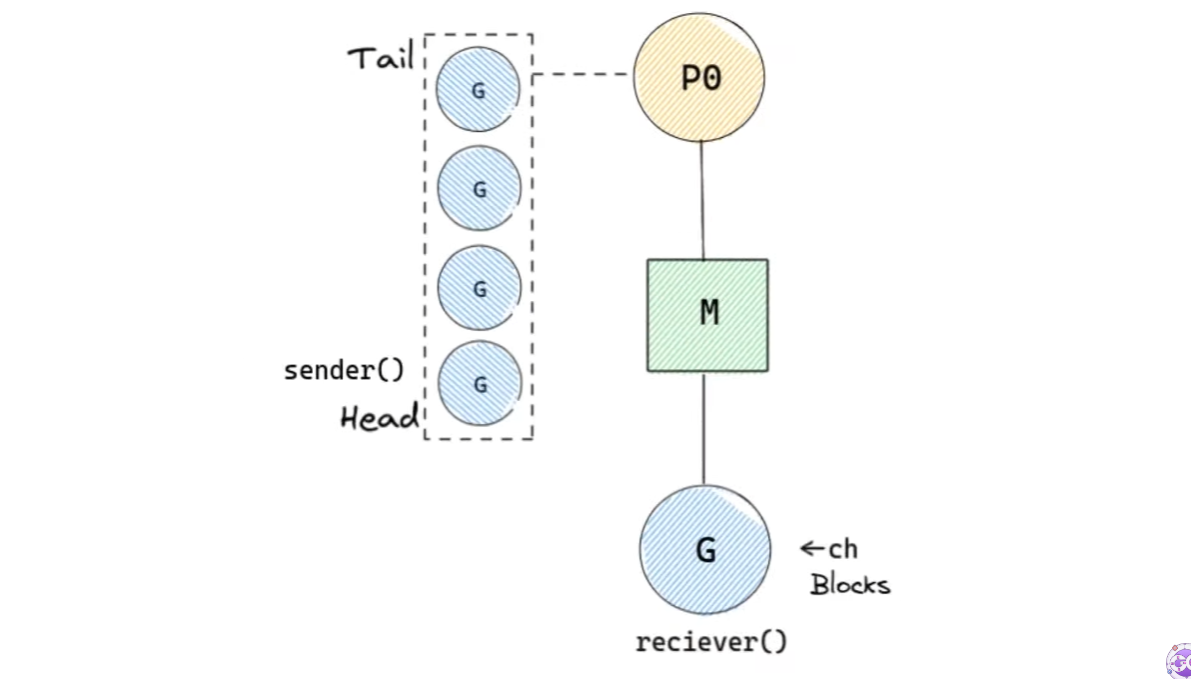
먼저, receiver()는 실행되다가 채널을 기다려야 하기 때문에 block된다. 이어서 sender()가 실행된다.
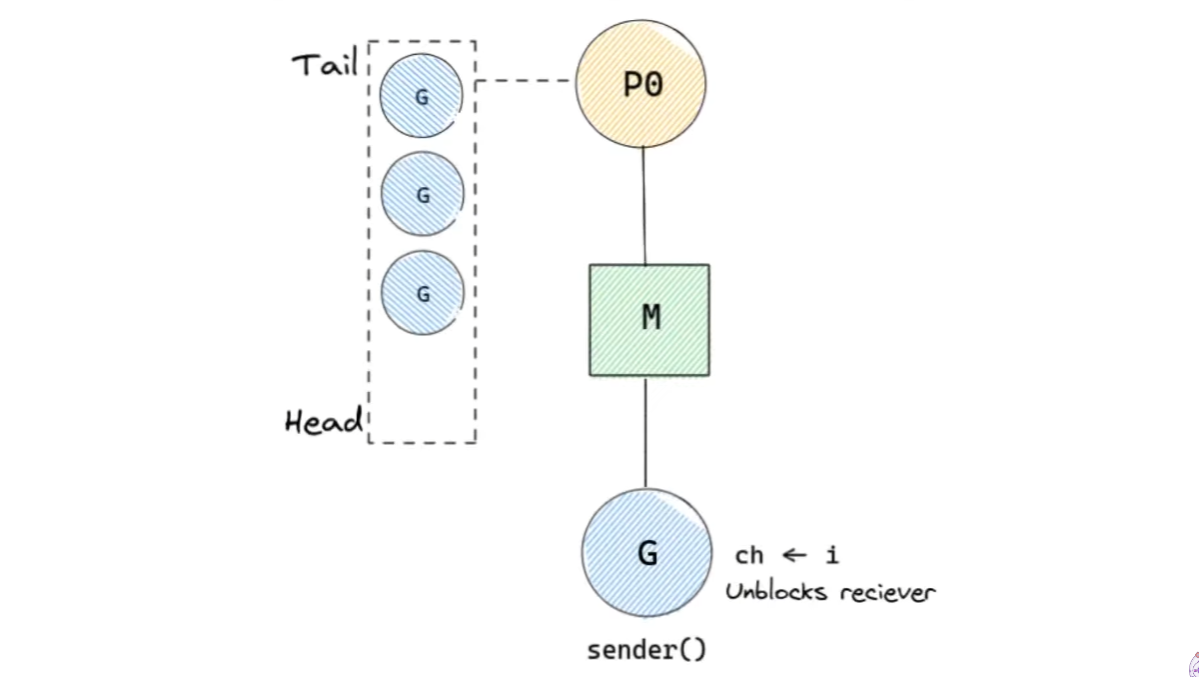
sender()는 채널에 메시지를 보낸다. 따라서 reciever()는 unblock된다. 이어서 local runqueue에 삽입된다.
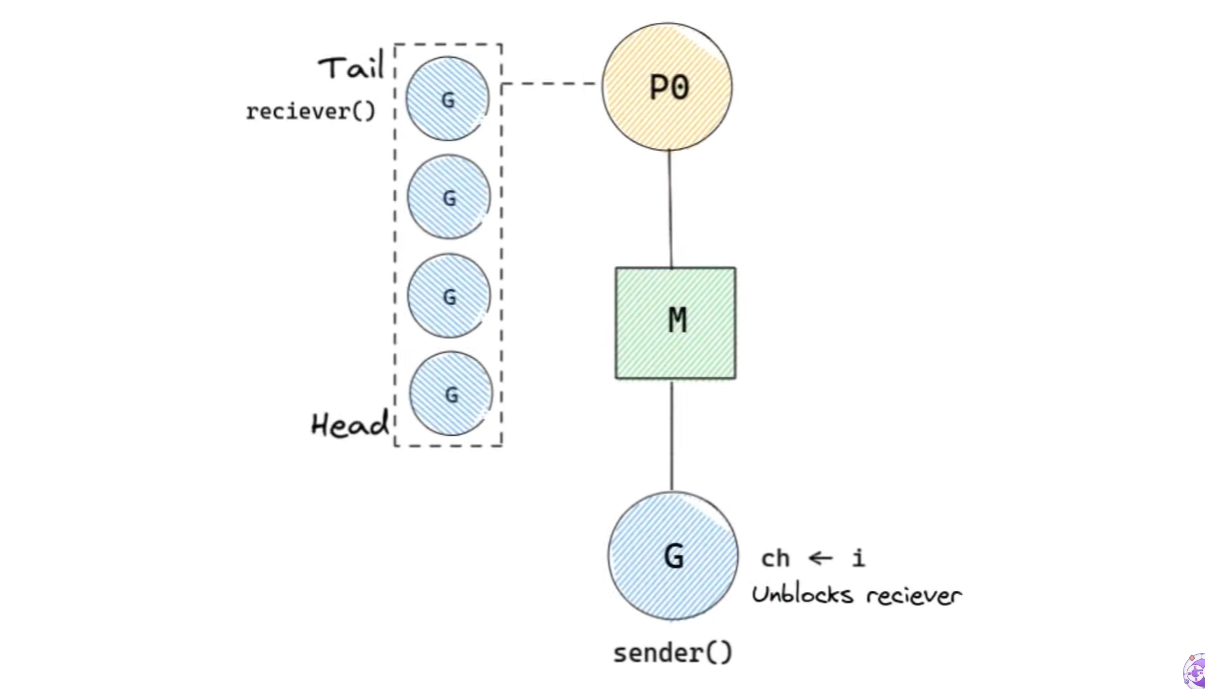
하지만 FIFO에 의해 reciever()는 tail에 삽입되었기 때문에, 채널의 메시지를 해결하려면 다른 G의 실행이 끝나기를 기다려야 한다.
sending과 receiving은 짧게 끝나는 과정이 아니라 긴 과정이다. 만약 sending과 receiving이 반복되어 일어난다면, FIFO에서는 위 예제처럼 reciever가 다른 고루틴의 작업이 끝나거나 선점당하기를 기다려야한다.
local runqueue의 길이는 256이므로 최악의 경우에는 자신을 제외한 나머지의 고루틴을 기다려야 한다. 따라서 255 * 10ms의 시간이 걸릴 수 있다.
따라서 이 역시 poor locality의 문제가 발생한다.
그렇다면 LIFO와 FIFO를 합쳐서 locality 문제를 해결할 수 없을까?
Time slice inheritance
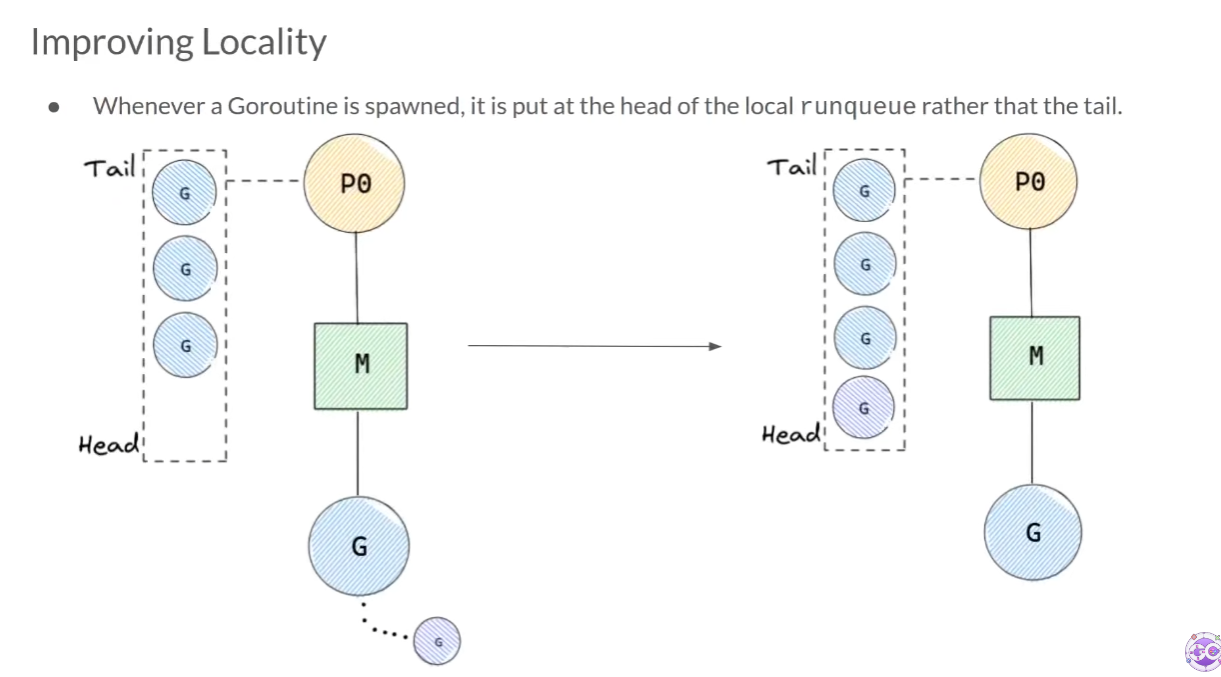
locality 문제를 해결하기 위해 Go scheduler는 G가 만들어지면, local runqueue의 tail 대신에 head에 넣는다.
이렇게 하면 locality를 해결할 수 있다. 하지만 당연히 문제점을 가져온다. 만약 G가 끊임없이 생성되는 경우, local runqueue의 나머지 G들은 기아 상태에 빠지게 된다. 게다가 local runqueue가 비질 않으니 global runqueue의 G들 또한 기아 상태에 빠지게 된다.
이를 해결하기 위해 Go scheduler는 Time Slice Inheritance를 사용한다.
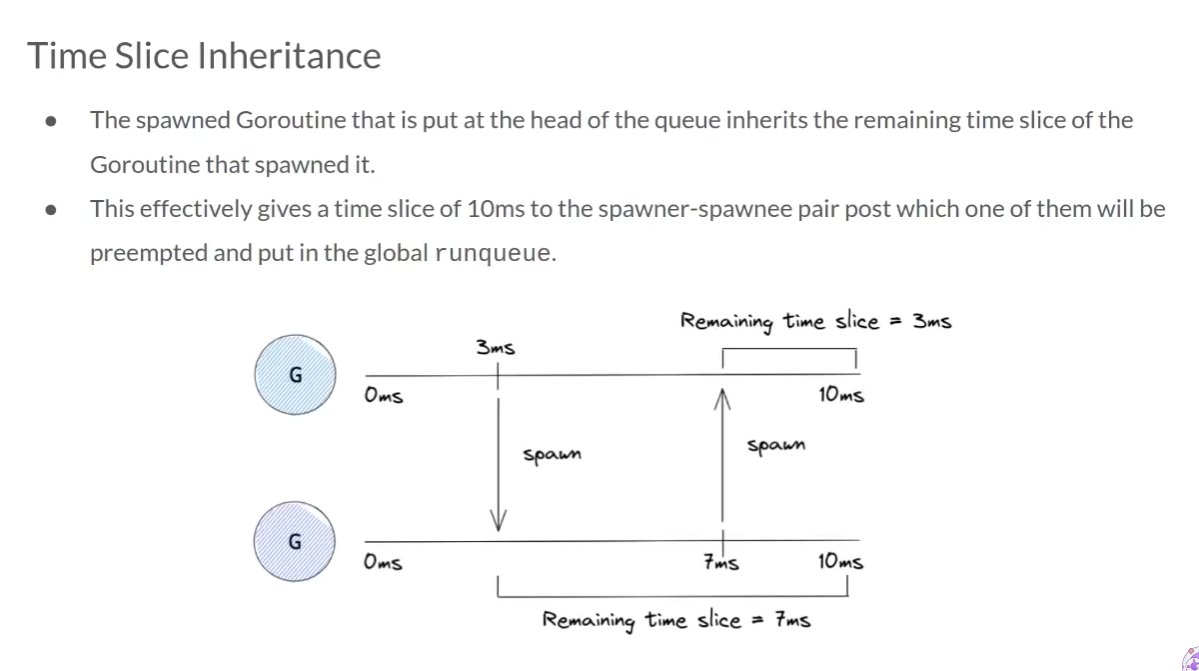
풀이하자면 시분할 상속이다.ParentGoroutine은 10ms의 실행 시간을 가지고, 3ms 시점에 ChildGoroutine1을 생성했다고 생각해보자.
그렇다면 ChildGoroutine1은 10ms - 3ms = 7ms의 실행 시간을 갖게 된다. 이어서 ChildGoroutine1이 4ms 시점에 새로운 ChildGoroutine2를 생성했다고 생각해보자.
그렇다면 ChildGoroutine2은 7ms - 4ms = 3ms의 실행 시간을 갖게 된다.
이렇게 부모와 자식 G들을 합쳐서 무조건 총 10ms의 실행 시간을 부여해 다른 G의 기아 상태를 방지한다.
여기까지 이 방법으로 local runqueue의 기아 상태는 해결하겠지만, global runqueue의 기아 상태는 해결하지 못한다. M이 global runqueue의 G를 가져올 때는 local runqueue가 비었을 때다. 즉, local runqueue에 항상 G가 존재한다면, global runqueue의 G를 절대 가져오지 않는다.
이를 해결하기 위해 Go scheduler는 어떤 조건을 만족하면 global runqueue에서 G를 가져오게 된다.
schedtick
go runtime에는 schedtick이라는 변수가 존재하며, 이 변수는 local runqueue의 polling이 한 번 일어날 때마다 증가한다.
polling은 어떤 장치나 프로그램의 상태를 주기적으로 살핀다는 의미이며, 여기서는 G 하나를 수행하고 나서 다음으로 실행할 G를 찾기 위해 runqueue를 살피는 것을 뜻한다.
global runqueue를 반드시 polling하게 되는 조건은 다음과 같다.
if schedtick % 61 == 0 {
getFromGlobalRunqueue()
} else {
doThingsAsBefore()
}즉, schedtick 변수가 61이 되면 global runqueue를 반드시 polling해서 G를 가져온다.
61이라는 숫자는 성능적으로 테스트한 범위에서 제일 결과가 좋았던 소수를 가져온 것이다. 이보다 너무 크면 기아 상태를 해결하지 못하고, 너무 작으면 global runqueue에 polling을 자주 하게 되어 lock때문에 성능 저하를 일으킨다.
그렇다면 왜 소수일까?
go scheduler는 실행할 새로운 application을 불러들이거나, 실행할 새 goroutine을 찾는 주기를 갖고 있는데, 이는 2나 16, 32같은 2의 거듭제곱으로 나타낼 수 있다. 물론 다른 숫자가 불가능하지는 않지만 가능성이 낮다.
만약 이 주기들이 겹치게 되면 go scheduler는 동시에 실행되면 안되므로 lock을 걸어야 한다. 따라서 scheduler에 lock이 걸린 동안 scheduler가 필요한 다른 작업들은 멈추게 되어 성능 저하가 일어난다.
즉, 새 application을 불러들이는 작업과 global runqueue를 polling하는 작업이 겹친다면, 둘 중 하나가 기다려야 하므로 성능 저하가 발생한다는 것이다.
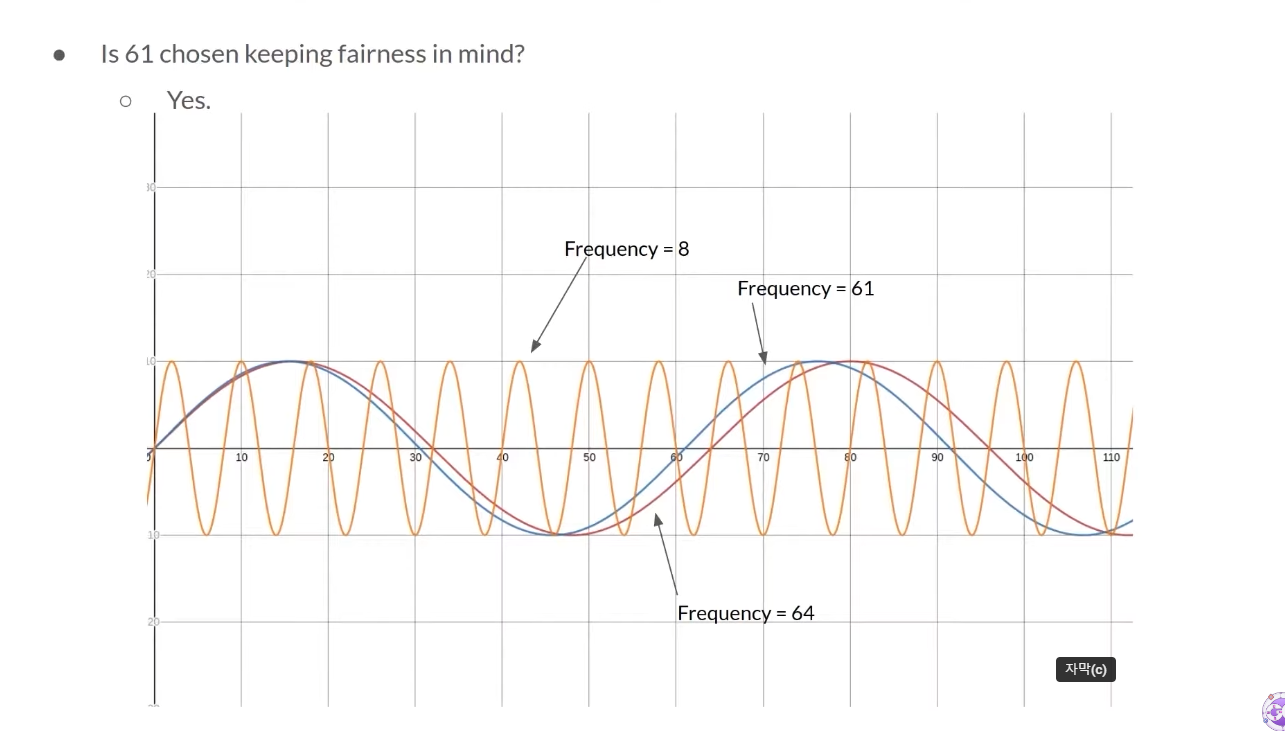
위 그래프에서 주황색 선은 scheduler가 새 application을 불러들이는 주기고 8이다.
파란색 선은 61의 주기이고 빨간색 선은 64의 주기다.
빨간색 선이 0이 될 때마다 주황색 선도 같이 0이 된다. 충돌이 일어난다는 뜻이다.
그러나 파란색 선은 그것을 비껴간다. 따라서 소수를 사용한다.
(이해한대로 적은 것이라 혹시 잘못 되었으면 지적 부탁드립니다)
syscall block
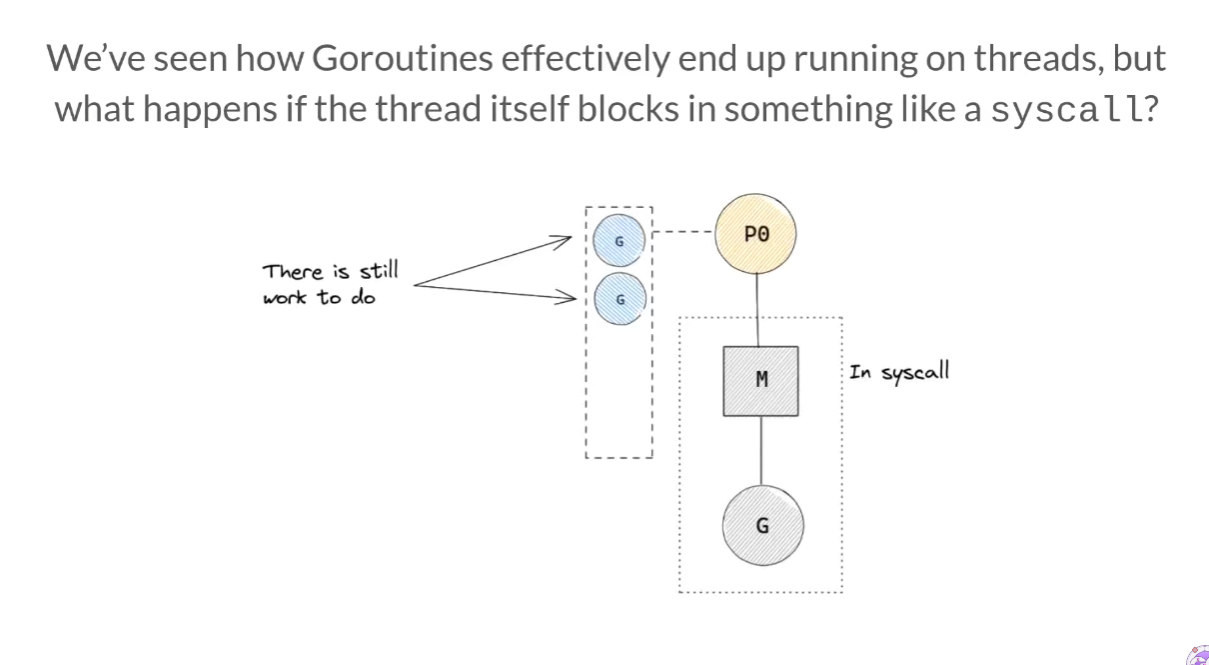
만약 G의 system call로 인해 M이 block됐다면 어떡할까? 아직 P의 local runqueue에는 실행되야 할 G들이 많은데 말이다.
Go scheduler는 P를 다른 M에게 건내주어(hand off) 이를 해결한다.
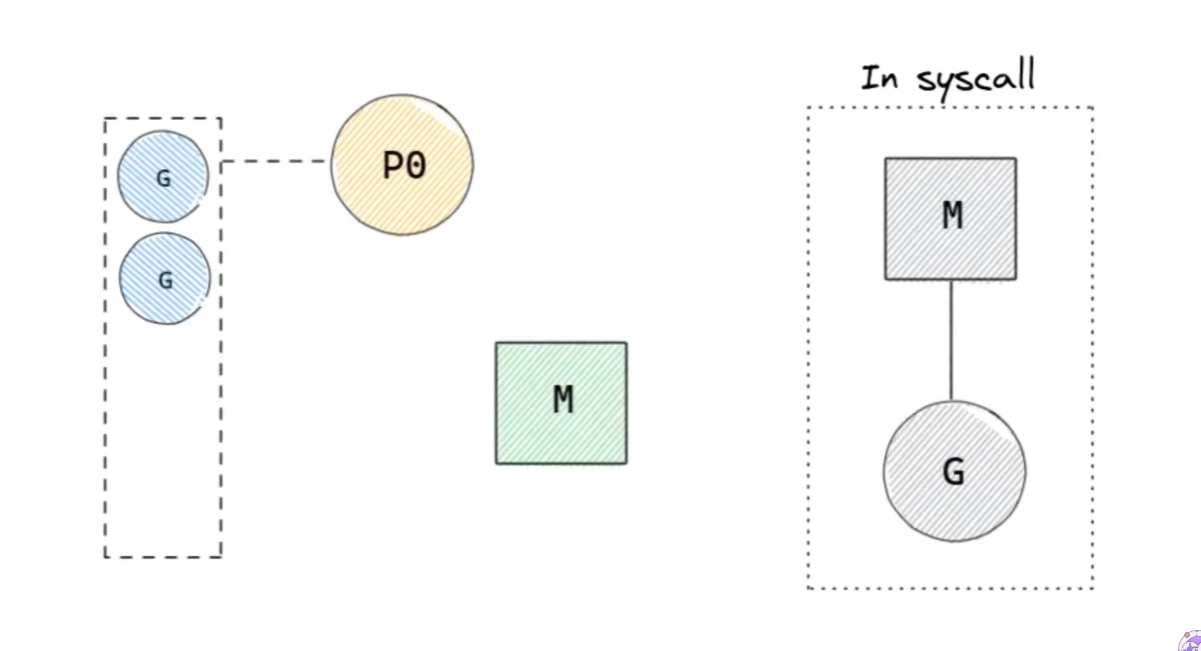
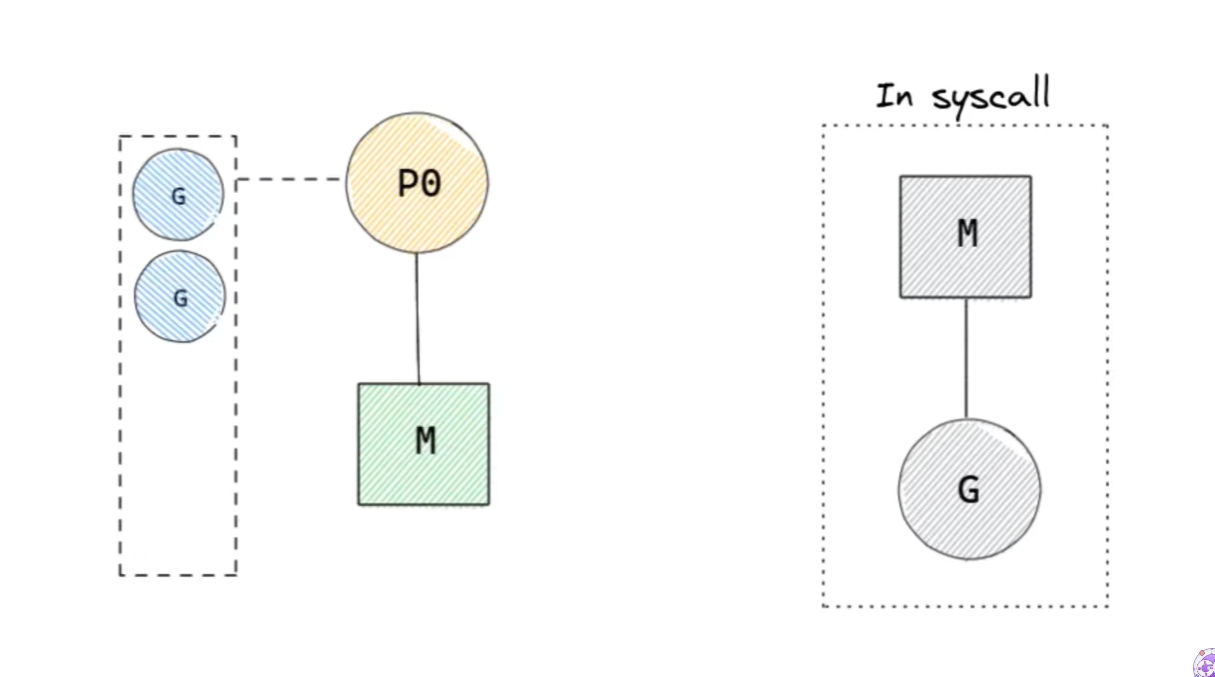
G의 system call로 인해 M이 block당하면, P와 M-G를 통째로 분리시킨다. 이후에 다른 M을 생성하거나, idle 상태였던 M을 가져와 연결시킨다.
근데 만약 idle 상태인 M이 존재했다면 상관 없지만 새로 만들어야 한다면 그 비용은 비싸다. 또, 모든 system call이 긴 시간이 걸리는 것은 아니기 때문에 짧은 system call에도 hand off를 남발한다면 성능상 문제가 생길 것이다.
따라서 scheduler는 긴 시간이 걸린다는 걸 알 수 있는 system call에만 즉시 hand off를 사용한다. 나머지 짧은 system call에는 block당한 상태로 내비둔다. system call로부터 값을 return 받으면 unblock되고 다시 일을 재개한다.
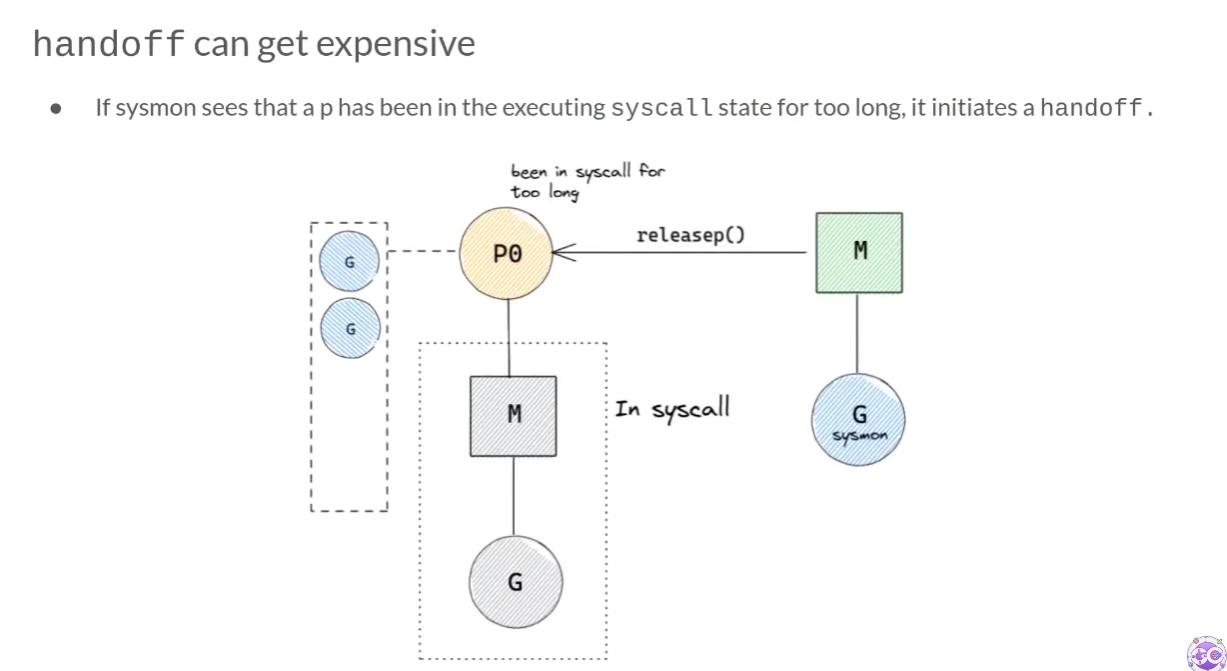
하지만 짧은 시간이 걸린다고 예측한 system call이 여러 사유에 의해 오래 걸릴 수 있다. 이런 경우에는 지켜보고 있던 sysmon이 handoff를 실행한다.
system call이 끝나고 나면 block당한 M-G는 unblock된다.
scheduler는 locality를 유지하기 위해 G를 system call 전에 있었던 P에 넣으려고 시도한다. 만약 이것이 불가능하다면, idle 상태의 다른 P에 넣는다.
idle 상태의 P가 존재하지 않는다면 global queue에 넣는다.
끝 마치며
길었던 Go scheduler를 알아보는 과정이 끝났다.
지금까지의 동작은 전부 Go scheduler 스스로 하는 행동이며, 만약 프로그래머가 무언가 최적화할 필요가 있다면 go runtime의 여러 메서드를 통해 조작할 수 있다.
Go scheduler의 이해에 도움이 되었으면 좋겠다.
Reference
https://www.youtube.com/watch?v=wQpC99Xu1U4
https://medium.com/@blanchon.vincent/go-sysmon-runtime-monitoring-cff9395060b5
https://rokrokss.com/post/2020/01/01/go-scheduler.html

첨부해 주신 영상과 이 포스팅 내용이 고루틴을 공부하는데 많은 도움이 되었습니다! 감사합니다 ㅎㅎ