insert all vs insert into ~ union all
oracle에서 많은 양의 row을 한 번에 입력할 일이 있어서 처음에 insert all을 사용했다. insert all을 사용하는 문장은 다음과 같다.
insert all
into dummy(id, col1, col2, col3) values (1001,'30841','30842','30843')
into dummy(...) values (...)
...
select * from dual;처음엔 이 문장이 mysql의 insert into values()... 와 비슷하게 생겼길래 그냥 갖다썼다. 근데 알고보니 성능이 떨어진다고 한다. union all 을 이용한 insert into가 훨씬 더 빠르다는 것이다.
union all을 사용하는 문장은 다음과 같다.
insert into dummy(id, col1, col2, col3)
select 1001,'35723','35724','35725' from dual union all
select 1978,'20495','20496','20497' from dual union all
....
select .... from dual;그래서 이 둘을 한 번 테스트 해보기로 했다. 1000, 2000, 3000, 4000, 5000개까지 데이터를 입력해봤다.
걸린 시간
1000개
insert all

union all
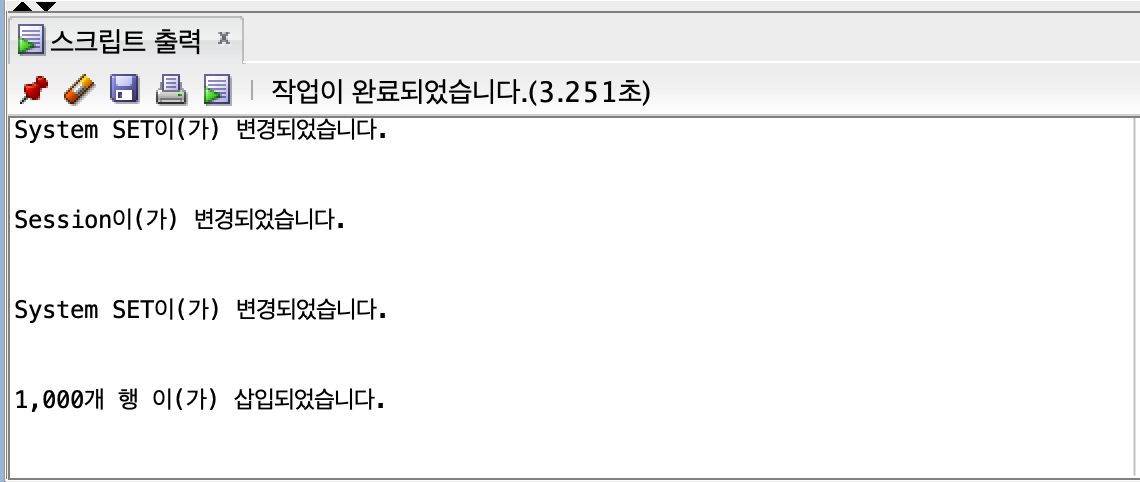
2000개
insert all
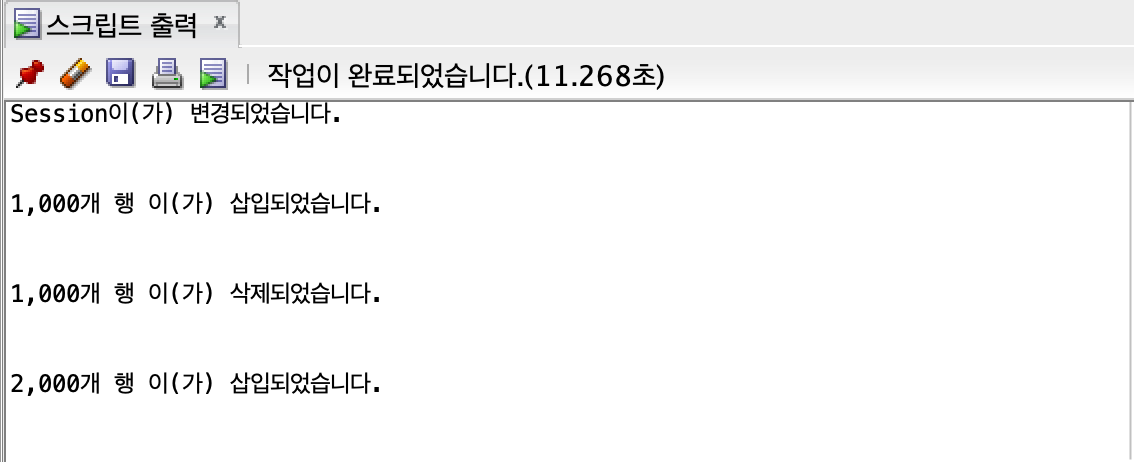
union all
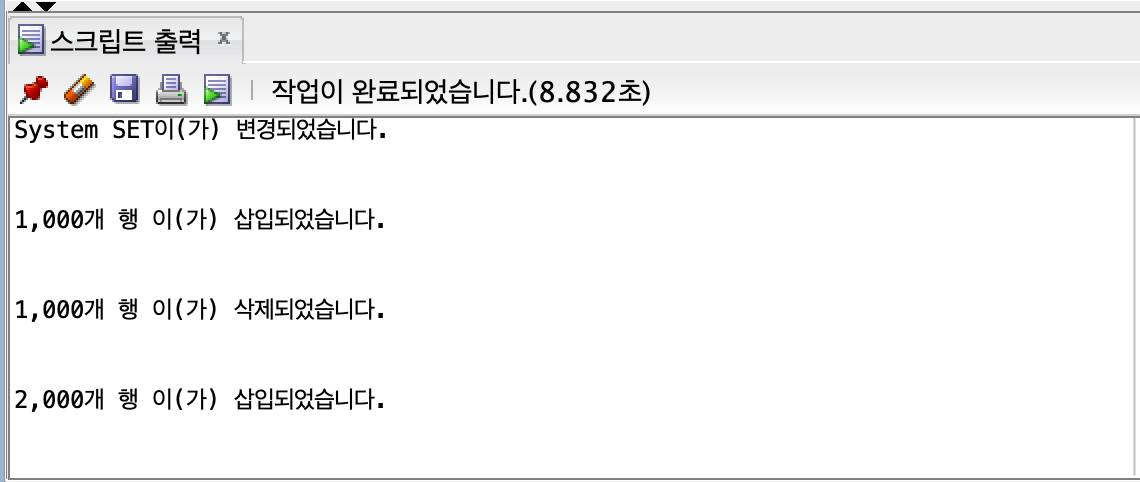
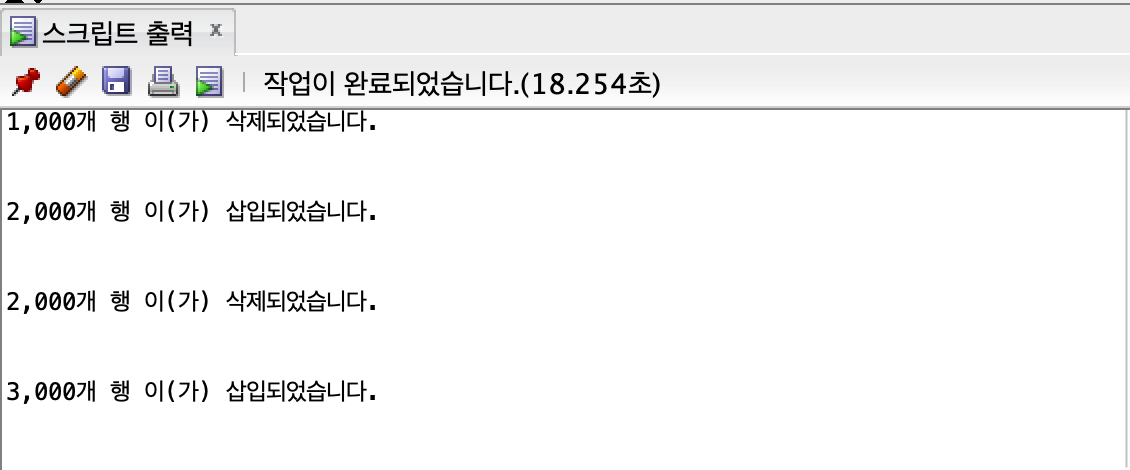
3000개
insert all
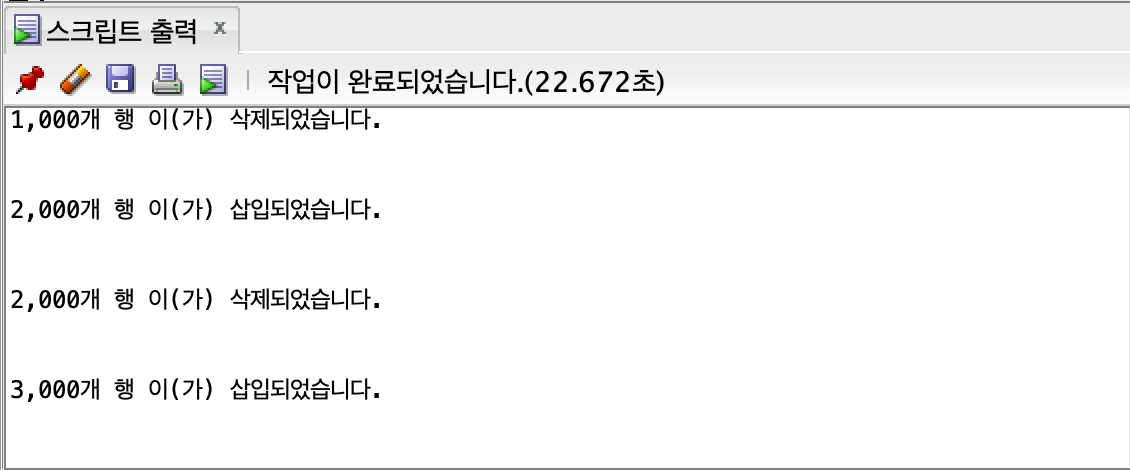
union all
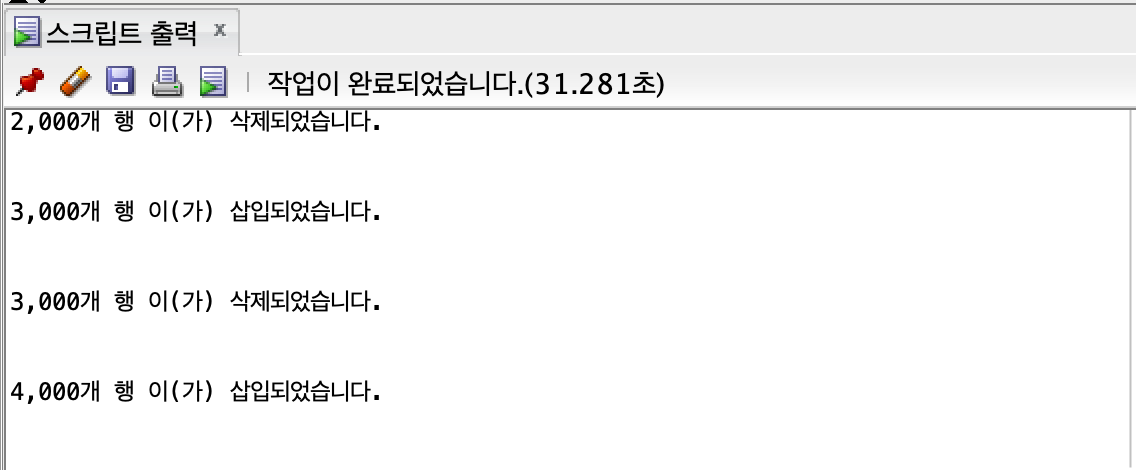
4000개
insert all

union all
5000개
insert all
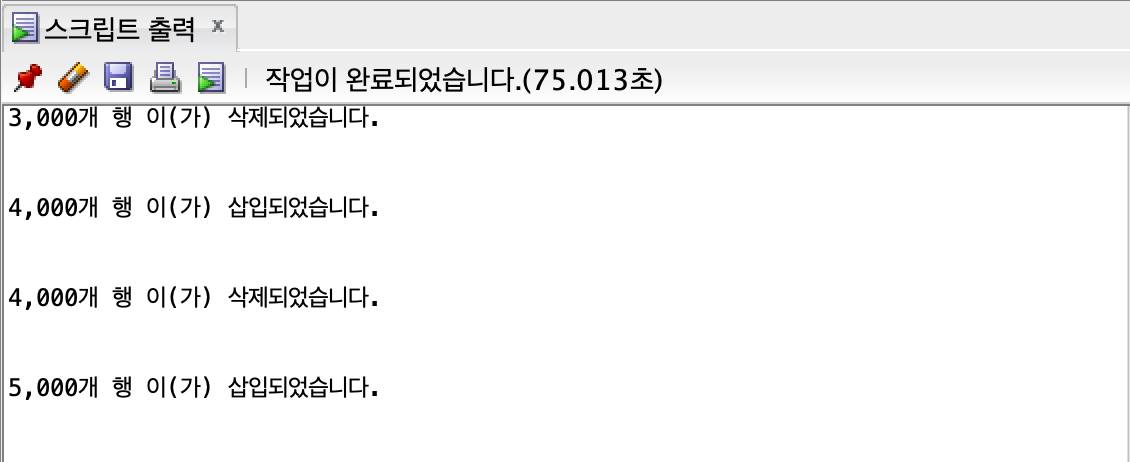
union all
insert all
3.701, 11.268, 22.672, 42.917, 75.013
union all
3.251, 8.832, 18.254, 31.281, 53.177
숫자가 적을 때는 큰 차이가 없지만, row 수가 점점 늘어날수록 차이가 커진다.
trace
그래서 기록된 trace를 찾아봤다.
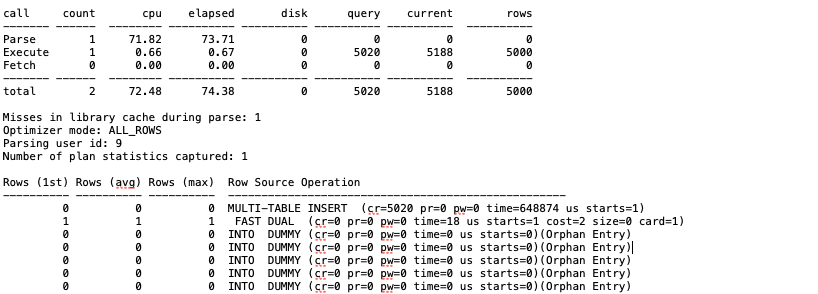
insert all의 경우에는 읽은 버퍼 블록의 수가 5020개, 5188개.. 그리고 무엇보다 parse에 시간을 많이 쓰고 있고 excute에는 0.67초 정도를 쓰고 있다.
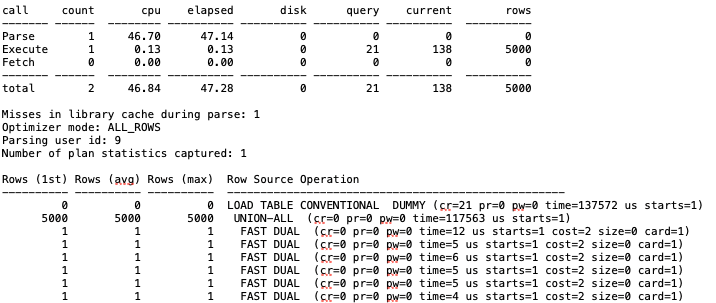
union all의 경우에는 버퍼 블록 수가 상대적으로 많이 적다. 그리고 parse는 물론 excute에도 insert all보다 시간이 상대적으로 적게 걸렸다.
무엇보다 Row Source Operation을 보면 union all은 전부 fast dual을 사용하고 있다. 알아보니 메모리를 사용하여 쿼리의 결과를 내는 것이라고 한다.
결론
- 연속해서 새로운 데이터를 삽입해야 하는 경우 Union all 쪽이 훨씬 빠르다.
- Parse 속도 면에서 Insert all이 딸리는 이유는 실제로 이쪽이 글자 수가 더 많다. 그래서 딸리는 것일 수도?
- Excute 속도 면에서는 Union all은 뭔가 최적화 기법이 들어가는 것 같다. 그래서 더 빠른 것 같다.
