
https://github.com/ingowald/optix7course마찬가지로 이전 Example에서 달라진 점만 설명한다.
// main.cpp
extern "C" int main(int ac, char **av)
{
try {
std::vector<TriangleMesh> model(2);
// 100x100 thin ground plane
model[0].color = vec3f(0.f, 1.f, 0.f);
model[0].addCube(vec3f(0.f,-1.5f, 0.f),vec3f(10.f,.1f,10.f));
// a unit cube centered on top of that
model[1].color = vec3f(0.f,1.f,1.f);
model[1].addCube(vec3f(0.f,0.f,0.f),vec3f(2.f,2.f,2.f));
Camera camera = { /*from*/vec3f(-10.f,2.f,-12.f),
/* at */vec3f(0.f,0.f,0.f),
/* up */vec3f(0.f,1.f,0.f) };
// something approximating the scale of the world, so the
// camera knows how much to move for any given user interaction:
const float worldScale = 10.f;
SampleWindow *window = new SampleWindow("Optix 7 Course Example",
model,camera,worldScale);
window->run();
} catch (std::runtime_error& e) {
std::cout << GDT_TERMINAL_RED << "FATAL ERROR: " << e.what()
<< GDT_TERMINAL_DEFAULT << std::endl;
exit(1);
}
return 0;
}물체별로 데이터를 설정한다.
// SampleRenderer.cpp
SampleRenderer::SampleRenderer(const std::vector<TriangleMesh> &meshes)
: meshes(meshes)// SampleRenderer.cpp
OptixTraversableHandle SampleRenderer::buildAccel()
{
// meshes.resize(1);
vertexBuffer.resize(meshes.size());
indexBuffer.resize(meshes.size());
OptixTraversableHandle asHandle { 0 };
// ==================================================================
// triangle inputs
// ==================================================================
std::vector<OptixBuildInput> triangleInput(meshes.size());
std::vector<CUdeviceptr> d_vertices(meshes.size());
std::vector<CUdeviceptr> d_indices(meshes.size());
std::vector<uint32_t> triangleInputFlags(meshes.size());
for (int meshID=0;meshID<meshes.size();meshID++) {
// upload the model to the device: the builder
TriangleMesh &model = meshes[meshID];
vertexBuffer[meshID].alloc_and_upload(model.vertex);
indexBuffer[meshID].alloc_and_upload(model.index);
triangleInput[meshID] = {};
triangleInput[meshID].type
= OPTIX_BUILD_INPUT_TYPE_TRIANGLES;
// create local variables, because we need a *pointer* to the
// device pointers
d_vertices[meshID] = vertexBuffer[meshID].d_pointer();
d_indices[meshID] = indexBuffer[meshID].d_pointer();
triangleInput[meshID].triangleArray.vertexFormat = OPTIX_VERTEX_FORMAT_FLOAT3;
triangleInput[meshID].triangleArray.vertexStrideInBytes = sizeof(vec3f);
triangleInput[meshID].triangleArray.numVertices = (int)model.vertex.size();
triangleInput[meshID].triangleArray.vertexBuffers = &d_vertices[meshID];
triangleInput[meshID].triangleArray.indexFormat = OPTIX_INDICES_FORMAT_UNSIGNED_INT3;
triangleInput[meshID].triangleArray.indexStrideInBytes = sizeof(vec3i);
triangleInput[meshID].triangleArray.numIndexTriplets = (int)model.index.size();
triangleInput[meshID].triangleArray.indexBuffer = d_indices[meshID];
triangleInputFlags[meshID] = 0 ;
// in this example we have one SBT entry, and no per-primitive
// materials:
triangleInput[meshID].triangleArray.flags = &triangleInputFlags[meshID];
triangleInput[meshID].triangleArray.numSbtRecords = 1;
triangleInput[meshID].triangleArray.sbtIndexOffsetBuffer = 0;
triangleInput[meshID].triangleArray.sbtIndexOffsetSizeInBytes = 0;
triangleInput[meshID].triangleArray.sbtIndexOffsetStrideInBytes = 0;
}
// ==================================================================
// BLAS setup
// ==================================================================
OptixAccelBuildOptions accelOptions = {};
accelOptions.buildFlags = OPTIX_BUILD_FLAG_NONE
| OPTIX_BUILD_FLAG_ALLOW_COMPACTION
;
accelOptions.motionOptions.numKeys = 1;
accelOptions.operation = OPTIX_BUILD_OPERATION_BUILD;
OptixAccelBufferSizes blasBufferSizes;
OPTIX_CHECK(optixAccelComputeMemoryUsage
(optixContext,
&accelOptions,
triangleInput.data(),
(int)meshes.size(), // num_build_inputs
&blasBufferSizes
));
// ==================================================================
// prepare compaction
// ==================================================================
CUDABuffer compactedSizeBuffer;
compactedSizeBuffer.alloc(sizeof(uint64_t));
OptixAccelEmitDesc emitDesc;
emitDesc.type = OPTIX_PROPERTY_TYPE_COMPACTED_SIZE;
emitDesc.result = compactedSizeBuffer.d_pointer();
// ==================================================================
// execute build (main stage)
// ==================================================================
CUDABuffer tempBuffer;
tempBuffer.alloc(blasBufferSizes.tempSizeInBytes);
CUDABuffer outputBuffer;
outputBuffer.alloc(blasBufferSizes.outputSizeInBytes);
OPTIX_CHECK(optixAccelBuild(optixContext,
/* stream */0,
&accelOptions,
triangleInput.data(),
(int)meshes.size(),
tempBuffer.d_pointer(),
tempBuffer.sizeInBytes,
outputBuffer.d_pointer(),
outputBuffer.sizeInBytes,
&asHandle,
&emitDesc,1
));
CUDA_SYNC_CHECK();
// ==================================================================
// perform compaction
// ==================================================================
uint64_t compactedSize;
compactedSizeBuffer.download(&compactedSize,1);
asBuffer.alloc(compactedSize);
OPTIX_CHECK(optixAccelCompact(optixContext,
/*stream:*/0,
asHandle,
asBuffer.d_pointer(),
asBuffer.sizeInBytes,
&asHandle));
CUDA_SYNC_CHECK();
// ==================================================================
// aaaaaand .... clean up
// ==================================================================
outputBuffer.free(); // << the UNcompacted, temporary output buffer
tempBuffer.free();
compactedSizeBuffer.free();
return asHandle;
}triangle input(OptixBuildInput)에 대해서 각 물체에 대해서 입력을 받는다.
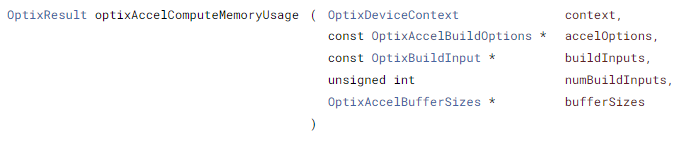
optixAccelComputeMemoryUsage에서 numBuildInputs의 수를 물체의 수 만큼 넣는다.
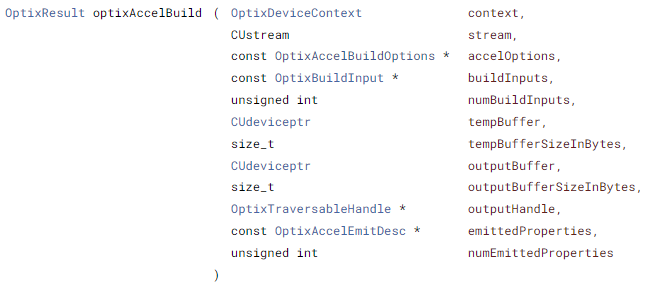
마찬가지로 optixAccelBuild할 때도 numBuildInputs의 수만큼 넣어준다.
// SampleRenderer.cpp
/*! constructs the shader binding table */
void SampleRenderer::buildSBT()
{
// ------------------------------------------------------------------
// build raygen records
// ------------------------------------------------------------------
std::vector<RaygenRecord> raygenRecords;
for (int i=0;i<raygenPGs.size();i++) {
RaygenRecord rec;
OPTIX_CHECK(optixSbtRecordPackHeader(raygenPGs[i],&rec));
rec.data = nullptr; /* for now ... */
raygenRecords.push_back(rec);
}
raygenRecordsBuffer.alloc_and_upload(raygenRecords);
sbt.raygenRecord = raygenRecordsBuffer.d_pointer();
// ------------------------------------------------------------------
// build miss records
// ------------------------------------------------------------------
std::vector<MissRecord> missRecords;
for (int i=0;i<missPGs.size();i++) {
MissRecord rec;
OPTIX_CHECK(optixSbtRecordPackHeader(missPGs[i],&rec));
rec.data = nullptr; /* for now ... */
missRecords.push_back(rec);
}
missRecordsBuffer.alloc_and_upload(missRecords);
sbt.missRecordBase = missRecordsBuffer.d_pointer();
sbt.missRecordStrideInBytes = sizeof(MissRecord);
sbt.missRecordCount = (int)missRecords.size();
// ------------------------------------------------------------------
// build hitgroup records
// ------------------------------------------------------------------
int numObjects = (int)meshes.size();
std::vector<HitgroupRecord> hitgroupRecords;
for (int meshID=0;meshID<numObjects;meshID++) {
HitgroupRecord rec;
// all meshes use the same code, so all same hit group
OPTIX_CHECK(optixSbtRecordPackHeader(hitgroupPGs[0],&rec));
rec.data.color = meshes[meshID].color;
rec.data.vertex = (vec3f*)vertexBuffer[meshID].d_pointer();
rec.data.index = (vec3i*)indexBuffer[meshID].d_pointer();
hitgroupRecords.push_back(rec);
}
hitgroupRecordsBuffer.alloc_and_upload(hitgroupRecords);
sbt.hitgroupRecordBase = hitgroupRecordsBuffer.d_pointer();
sbt.hitgroupRecordStrideInBytes = sizeof(HitgroupRecord);
sbt.hitgroupRecordCount = (int)hitgroupRecords.size();
}hitgroupRecords에서 물체의 수만큼 record를 만들고 삽입한다.
그리고 sbt.hitgroupRecordCount를 record의 수만큼으로 설정해줘야 한다.
devicePrograms.cu는 변경사항이 없다.
단일 GAS에 build input이 다수일 때, build input list의 index가 optixGetSbtDataPointer() 함수를 호출할 때, SBT record list의 index와 매칭해서 해당 record를 불러온다.
정리하면 GAS에 build input이 다수일 때
ray가 특정 triangle과 closest hit가 발생하고 optixGetSbtDataPointer()를 호출하, triangle이 속한 build input을 확인한다. 그리고 build input의 index 값을 갖고, SBT record list에 index 값을 넣어 해당 data pointer를 반환한다.
