
Instance Acceleration Structure의 필요성을 느낀 것은 다음과 같이 AS에 Transformation을 적용하기 위해서이다.
해당 코드는 아래에서 확인할 수 있다.
코드 작성에 참고한 코드는 아래 사이트이다.
https://github.com/NVIDIA/OptiX_Apps/blob/master/apps/intro_runtime/src/Application.cpp
void OptiXRenderer::createInstances() {
for (int i = 0; i < geoTraversableHandle.size(); i++) {
OptixInstance instance = {};
Transformation transformation;
size_t size;
float* transformationMatrix = transformation.getMatrix(&size);
memcpy(instance.transform, transformationMatrix, sizeof(float) * size);
delete[] transformationMatrix;
Material material;
materialList.push_back(material);
instance.instanceId = instances.size();
instance.sbtOffset = i* RAY_TYPE_COUNT;
instance.visibilityMask = OptixVisibilityMask(255);
instance.flags = OPTIX_INSTANCE_FLAG_NONE;
instance.traversableHandle = geoTraversableHandle[i];
instances.push_back(instance);
transformationList.push_back(transformation);
}
}
OptixTraversableHandle OptiXRenderer::createInstancesAS() {
instancesBuffer.alloc_and_upload<OptixInstance>(instances);
instanceInput.type = OPTIX_BUILD_INPUT_TYPE_INSTANCES;
instanceInput.instanceArray.instances = instancesBuffer.d_pointer();
instanceInput.instanceArray.numInstances = static_cast<unsigned int>(instances.size());
accelBuildOptions.buildFlags = OPTIX_BUILD_FLAG_NONE | OPTIX_BUILD_FLAG_ALLOW_UPDATE;
accelBuildOptions.operation = OPTIX_BUILD_OPERATION_BUILD;
OPTIX_CHECK(optixAccelComputeMemoryUsage(optixContext, &accelBuildOptions, &instanceInput, 1, &accelBufferSizes));
tempBuffer.alloc(accelBufferSizes.tempSizeInBytes);
outputBuffer.alloc(accelBufferSizes.outputSizeInBytes);
OptixTraversableHandle traversableHandle;
OPTIX_CHECK(optixAccelBuild(optixContext, cudaStream,
&accelBuildOptions, &instanceInput, 1,
tempBuffer.d_pointer(), accelBufferSizes.tempSizeInBytes,
outputBuffer.d_pointer(), accelBufferSizes.outputSizeInBytes,
&traversableHandle, nullptr, 0));
CUDA_SYNC_CHECK();
// tempBuffer.free();
// instancesBuffer.free();
insTraversableHandle = traversableHandle;
return traversableHandle;
}
void OptiXRenderer::updateInstancesAS() {
size_t size;
float* matrix;
for (int i = 0; i < instances.size(); i++) {
matrix = transformationList[i].getMatrix(&size);
memcpy(instances[i].transform, matrix, size * sizeof(float));
delete[] matrix;
}
instancesBuffer.upload<OptixInstance>(instances.data(), instances.size());
accelBuildOptions.operation = OPTIX_BUILD_OPERATION_UPDATE;
OPTIX_CHECK(optixAccelBuild(optixContext, cudaStream,
&accelBuildOptions, &instanceInput, 1,
tempBuffer.d_pointer(), accelBufferSizes.tempSizeInBytes,
outputBuffer.d_pointer(), accelBufferSizes.outputSizeInBytes,
&insTraversableHandle, nullptr, 0));
}핵심 코드는 다음과 같다.
void OptiXRenderer::createInstances() {
for (int i = 0; i < geoTraversableHandle.size(); i++) {
OptixInstance instance = {};
Transformation transformation;
size_t size;
float* transformationMatrix = transformation.getMatrix(&size);
memcpy(instance.transform, transformationMatrix, sizeof(float) * size);
delete[] transformationMatrix;
Material material;
materialList.push_back(material);
instance.instanceId = instances.size();
instance.sbtOffset = i* RAY_TYPE_COUNT;
instance.visibilityMask = OptixVisibilityMask(255);
instance.flags = OPTIX_INSTANCE_FLAG_NONE;
instance.traversableHandle = geoTraversableHandle[i];
instances.push_back(instance);
transformationList.push_back(transformation);
}
}먼저 GAS에 대한 instance를 만들어줘야 한다. 그래야지 IAS에 instance를 child로 삼을 수 있다.
OptiXInstance를 선언한 후 값을 초기화해준다.
여기서 OptiXInstance의 transform은 3x4 row-major matrix이다.
float* getMatrix(size_t* size) {
*size = 12;
mTransfomation = glm::mat4(1.0f);
glm::mat4 scaleMatrix = glm::scale(glm::mat4(1.0f), mScale);
glm::mat4 rotationXMatrix = glm::rotate(glm::mat4(1.0f), glm::radians(mRotation.x), glm::vec3(1,0,0));
glm::mat4 rotationYMatrix = glm::rotate(glm::mat4(1.0f), glm::radians(mRotation.y), glm::vec3(0,1,0));
glm::mat4 rotationZMatrix = glm::rotate(glm::mat4(1.0f), glm::radians(mRotation.z), glm::vec3(0,0,1));
glm::mat4 translationMatrix = glm::translate(glm::mat4(1.0f), mTanslation);
mTransfomation = translationMatrix * rotationZMatrix * rotationYMatrix * rotationXMatrix * scaleMatrix * mTransfomation;
mTransfomation = glm::transpose(mTransfomation); // row-major
float* ret = new float[*size];
memcpy(ret, &mTransfomation, *size * sizeof(float));
return ret;
}Matrix를 얻는 함수는 다음과 같다.
glm은 column major이다. 따라서 transpose를 통해서 반환해줘야 한다.
OptiXInstance의 transform이 받는 것은 3x4 row-major matrix이기 때문에 identity matrix는 다음과 같을 것이다.
float identityMatrix[12] = {1,0,0,0,
0,1,0,0,
0,0,1,0};
// identityMatrix[3] -> Tx
// identityMatrix[7] -> Ty
// identityMatrix[11] -> TzOptiXInstance의 instanceId는 사용자 정의로 설정한다.
OptiX Shader 부분에서 optixGetInstanceId, optixGetInstanceIndex를 통해서 instance를 구분할 수 있다.
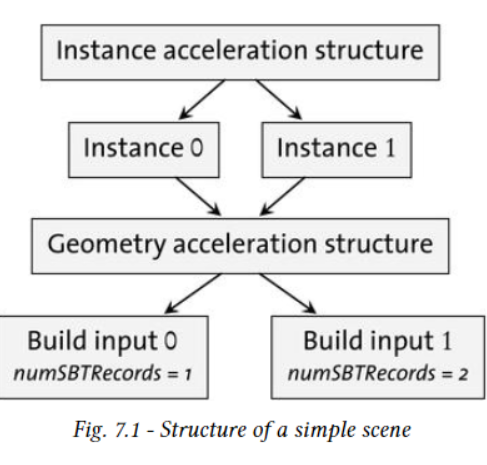

sbt index는 다음과 같이 IAS 기준으로 작성한다.
visibilityMask는 optixTrace에서와 맞춰주면된다.
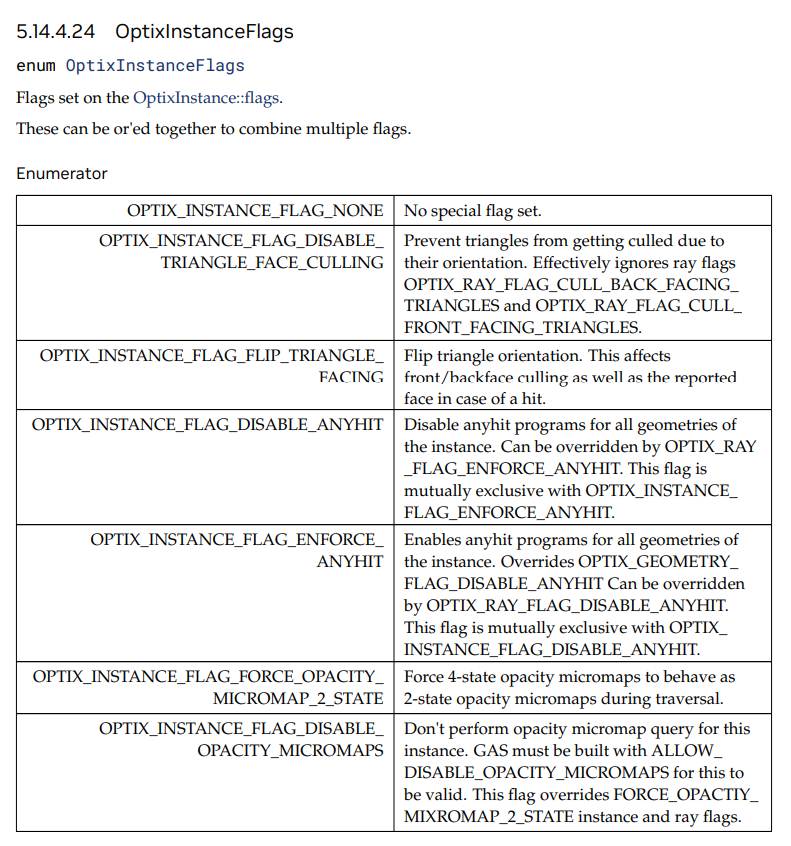
flags는 아래와 같다.
OptiXInstance의 traversableHandle에 들어가야 할 부분이 GAS의 handle 값이다.
이러면 GAS에 대한 Instance를 생성할 수 있다.
OptixTraversableHandle OptiXRenderer::createInstancesAS() {
instancesBuffer.alloc_and_upload<OptixInstance>(instances);
instanceInput.type = OPTIX_BUILD_INPUT_TYPE_INSTANCES;
instanceInput.instanceArray.instances = instancesBuffer.d_pointer();
instanceInput.instanceArray.numInstances = static_cast<unsigned int>(instances.size());
accelBuildOptions.buildFlags = OPTIX_BUILD_FLAG_NONE | OPTIX_BUILD_FLAG_ALLOW_UPDATE;
accelBuildOptions.operation = OPTIX_BUILD_OPERATION_BUILD;
OPTIX_CHECK(optixAccelComputeMemoryUsage(optixContext, &accelBuildOptions, &instanceInput, 1, &accelBufferSizes));
tempBuffer.alloc(accelBufferSizes.tempSizeInBytes);
outputBuffer.alloc(accelBufferSizes.outputSizeInBytes);
OptixTraversableHandle traversableHandle;
OPTIX_CHECK(optixAccelBuild(optixContext, cudaStream,
&accelBuildOptions, &instanceInput, 1,
tempBuffer.d_pointer(), accelBufferSizes.tempSizeInBytes,
outputBuffer.d_pointer(), accelBufferSizes.outputSizeInBytes,
&traversableHandle, nullptr, 0));
CUDA_SYNC_CHECK();
// tempBuffer.free();
// instancesBuffer.free();
insTraversableHandle = traversableHandle;
return traversableHandle;
}이제 Instance들에 대한 IAS를 만들어줘야 한다.
GAS를 만들 때와 유사하다.
다만 type을 OPTIX_BUILD_INPUT_INSTANCES로 하고, device 메모리의 포인터를 넘겨준다. (instance 수와 함께)
후에 Transformation에 대해서 움직여야 하므로 OPTIX_BUILD_FLAG_ALLOW_UPDATE를 넘겨서 업데이트를 가능하게 만든다.
tempBuffer와 instanceBuffer를 release하지 않는 이유는 update 부분에서 그대로 사용하기 때문이다.
void OptiXRenderer::updateInstancesAS() {
size_t size;
float* matrix;
for (int i = 0; i < instances.size(); i++) {
matrix = transformationList[i].getMatrix(&size);
memcpy(instances[i].transform, matrix, size * sizeof(float));
delete[] matrix;
}
instancesBuffer.upload<OptixInstance>(instances.data(), instances.size());
accelBuildOptions.operation = OPTIX_BUILD_OPERATION_UPDATE;
OPTIX_CHECK(optixAccelBuild(optixContext, cudaStream,
&accelBuildOptions, &instanceInput, 1,
tempBuffer.d_pointer(), accelBufferSizes.tempSizeInBytes,
outputBuffer.d_pointer(), accelBufferSizes.outputSizeInBytes,
&insTraversableHandle, nullptr, 0));
}