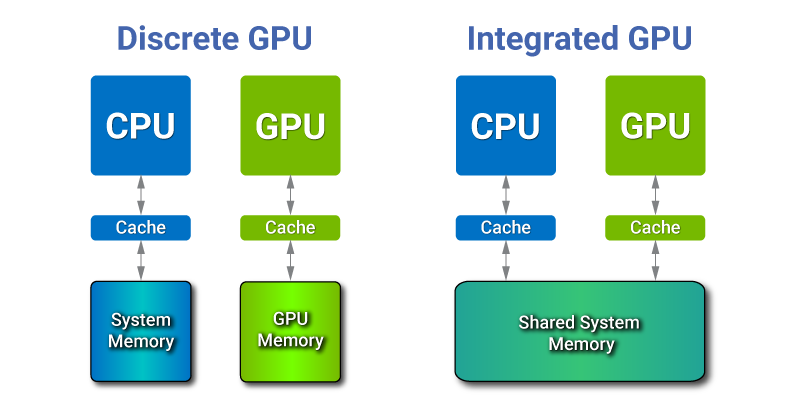
일반적인 (CPU와 GPU가 분리된) 컴퓨터에서 사용하는 메모리는 CPU에서 사용하는 RAM과 GPU에서 사용하는 VRAM으로 분리되어있다.
따라서 GPU에서 데이터를 사용하기 위해서는 RAM에서 GPU의 VRAM으로 PCIe 선을 통해서 데이터를 전송한다. 따라서 PCIe 선을 통해서 데이터를 전송하는데 delay가 걸린다.
이에 반해 SoC 칩 같은 경우 GPU와 CPU가 같은 마더보드에 있고, 메모리 또한 같이 사용한다.
PCIe 1.0
레인당 속도: 250 MB/s
x16 슬롯 속도: 4 GB/s (250 MB/s x 16 레인)
PCIe 2.0
레인당 속도: 500 MB/s
x16 슬롯 속도: 8 GB/s (500 MB/s x 16 레인)
PCIe 3.0
레인당 속도: 1 GB/s (약 985 MB/s)
x16 슬롯 속도: 약 16 GB/s (1 GB/s x 16 레인)
PCIe 4.0
레인당 속도: 2 GB/s (약 1969 MB/s)
x16 슬롯 속도: 약 32 GB/s (2 GB/s x 16 레인)
PCIe 5.0
레인당 속도: 4 GB/s (약 3938 MB/s)
x16 슬롯 속도: 약 64 GB/s (4 GB/s x 16 레인)
PCIe 6.0
레인당 속도: 8 GB/s (약 7877 MB/s)
x16 슬롯 속도: 약 128 GB/s (8 GB/s x 16 레인)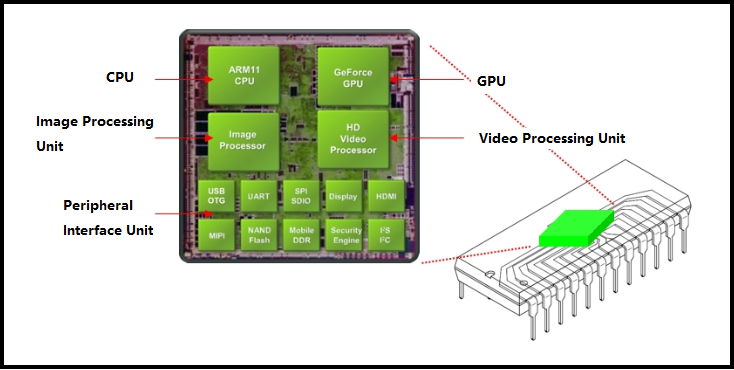
따라서 SoC에서는 PCIe 선을 통할 필요가 없으므로 이러한 딜레이가 사라진다.
하지만 실제 SoC에서 메모리를 확인해보면 GPU 메모리와 CPU 메모리가 분리되어있다.
이는 물리적으로는 하나의 메모리 이지만, GPU 메모리와 CPU 메모리는 가상적으로 분리되어있다.
SoC에서 메모리를 가상적으로 분리하는 이유는, CPU와 GPU가 각기 다른 메모리 영역을 사용하도록 하여 메모리 접근 충돌을 방지하고, 시스템 안정성을 높이기 위함이다.
즉, CPU 코드로 GPU Memory를 직접적으로 수정할 수 없도록 구현해놓은 것이다.
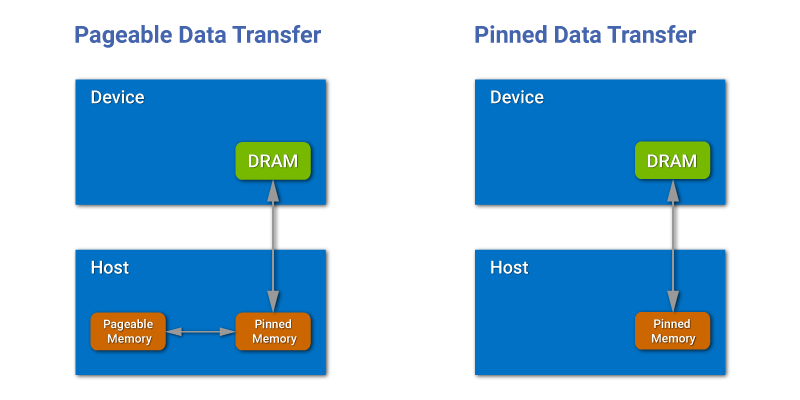
그리고 또 한 가지 이유가 있다.
CPU는 메모리 확장을 위해 스왑 공간을 사용하는데, 이는 주로 하드 디스크나 SSD의 일부를 사용하여 RAM을 확장하는 방식이다. 이와 달리, GPU는 이러한 스왑 공간을 활용하지 않고, 고정된 물리적 메모리(pinned memory)를 사용하여 데이터를 처리한다.
이러한 스왑은 RAM와 ROM 사이의 데이터 통신이 있기에 delay가 된다.
그렇기에 SoC에서는 CPU 메모리와 GPU 메모리를 분리해서 CPU에서는 page를 사용하고, GPU에서는 page가 없는 고정 메모리(pinned memory)를 사용한다.
다만 CUDA에서는 pinned 메모리를 CPU 단에서 설정할 수 있다.
이렇게 하면 CPU 메모리를 GPU에서 바로 사용하여 가상적으로 분리된 CPU 메모리에서 GPU 메모리로 복사할 필요가 없다(실제로는 같은 RAM 안에서 복사하기 때문에 PCIe 선을 통과하지 않는다.)
//example code
// Set flag to enable zero copy access
cudaSetDeviceFlags(cudaDeviceMapHost);
// Host Arrays (CPU pointers)
float* h_in = NULL;
float* h_out = NULL;
// Process h_in
// Allocate host memory using CUDA allocation calls
cudaHostAlloc((void **)&h_in, sizeIn, cudaHostAllocMapped); // pinned memory
cudaHostAlloc((void **)&h_out, sizeOut, cudaHostAllocMapped); // pinned memory
// Device arrays (CPU pointers)
float *d_out, *d_in;
// Get device pointer from host memory. No allocation or memcpy
cudaHostGetDevicePointer((void **)&d_in, (void *) h_in , 0);
cudaHostGetDevicePointer((void **)&d_out, (void *) h_out, 0);
// Launch the GPU kernel
kernel<<<blocks, threads>>>(d_out, d_in);
// No need to copy d_out back
// Continue processing on host using h_out이러한 고정 메모리가 아닌 CPU와 GPU에서 모두 접근할 수 있는 Unified Memory Programming(UM) 방법 또한 있다.
이는 자동으로 CPU와 GPU 메모리를 복사해주는 작업을 하게 된다.
일반 데스크톱에서도 사용이 가능한데, 이는 여전히 PCIe의 delay가 존재하는 문제점이 있다.
이에 반해 SoC에서는 이러한 제약이 없기 때문에 PCIe 선에 대한 delay 없이 동작할 수 있다.
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory -- pointers accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float)); // UM
cudaMallocManaged(&y, N*sizeof(float)); // UM
// initialize x and y arrays on the host (CPU)
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Launch kernel on 1M elements on the GPU
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
// Wait for GPU to finish before accessing on host**
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}Reference
https://www.fastcompression.com/blog/jetson-zero-copy.htm
https://developer.ridgerun.com/wiki/index.php/NVIDIA_CUDA_Memory_Management
