Java
Sorting
- 이름, 학번, 키 등 핵심 항목(key)의 대소 관계에 따라 데이터 집합을 일정한 순서로 줄지어 늘어서도록 바꾸는 작업
- 오름차순(ascending order), 내림차순(descending order) 등
- 내부 정렬(internal sorting)
- 정렬할 모든 데이터를 하나의 배열에 저장할 수 있는 경우에 사용하는 알고리즘
- 외부 정렬(external sorting)
- 정렬할 데이터가 너무 많아서 하나의 배열에 저장할 수 없는 경우에 사용하는 알고리즘
- 내부 정렬을 응용한 것
- 구현하기 위해 파일 등이 필요하고 알고리즘도 복잡
- 정렬의 핵심 요소는 교환, 선택, 삽입이며 대부분 정렬 알고리즘은 이 세 가지 요소를 응용한 것
버블 정렬 - bubble sort
- 이웃한 두 요소의 대소 관계를 비교하여 교환을 반복
- 요소의 개수가 n개인 배열에서 n-1회 비교, 교환을 하면 가장 작은 요소가 맨 처음으로 이동
- 이 과정을 패스(pass)라고 한다
- 두번째로 작은 요소의 경우 n-2회 비교
단순 선택 정렬 - straight selection sort
- 가장 작은 요소부터 선택해 알맞은 위치로 옮겨 순서대로 정렬
단순 삽입 정렬 - straight insertion sort
- 선택한 요소를 그보다 더 앞쪽의 알맞은 위치에 삽입하는 작업을 반복
- 단순 선택 정렬과는 가장 작은 요소를 선택할지, 단순하게 선택할지 차이
- 왼쪽부터 오른쪽으로 오름차순으로 정렬한다는 기준 하에 특정 수를 선택하고 특정 수 왼쪽에 위치한 요소와 비교하며 적절한 위치 찾음
셸 정렬 - shell sort
- 단순 삽입 정렬의 장점은 살리고 단점은 보완한 정렬 알고리즘
- 그룹으로 그룹 별로 정렬 실행
- h - 정렬
- h칸만큼 떨어져 있는 요소를 그룹으로 묶어 정렬하는 방법으로 h는 1을 향해 감소
- ex) 요소수 8개일 때 4-정렬, 4개의 그룹, 2-정렬, 2개의 그룹 ,1-정렬, 1개의 그룹
- 이 과정은 단순 삽입 정렬과 같은 과정이지만 단순 삽입 정렬보다 계산 수를 확연히 줄어주며 단점을 개선해준다
- 여기서 그룹이 섞이지 않는 경우를 방지하기 위해 h값은 서로 배수가 되지 않도록 하며 요소수 n을 9로 나눈 값을 넘지 않도록 해야 효율적인 정렬을 기대할 수 있다
- 정렬해야 하는 횟수는 늘지만 전체적으로는 요소 이동의 횟수가 줄어들어 효율적인 정렬을 할 수 있다
Python
정렬 - Sorting
- 데이터를 특정한 기준에 따라서 순서대로 나열
- 정렬 알고리즘은 이진 탐색의 전처리 과정이기도 하다
- 내림차순 <=> 오름차순
- reverse 이용 : O(N)의 복잡도
- 내림차순 or 오름차순을 수행하는 알고리즘에서 크기 비교를 반대로 진행
- 선택, 삽입, 퀵 정렬은 데이터의 값을 직접 비교한 뒤에 위치를 변경하기에 비교 기반의 정렬 알고리즘이라 한다
스와프 - Swap
- A, B 변수 존재할 때 A <=> B의 경우는
A, B = B, A```
선택 정렬 - Selection Sort
- 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 교체하고 그 다음 작은 데이터를 선택해 앞에서 두번째 데이터와 바꾸는 과정을 반복
- 10개의 데이터가 있다는 조건 하에서
제일 작은 데이터를 선정해 맨 앞으로 이동하는 경우 9번(N-1)의 비교 필요
두번째로 작은 데이터를 선정해 맨 앞에서 두번째로 이동하는 경우 8번(N-2)의 비교 필요
이를 반복하며 (N-1) + (N-2) + (N-3) + (N-4) + (N-5)... 반복
- 매우 비효율적
삽입 정렬 - Insertion Sort
- 선택 정렬에 비해 구현 난이도 높지만 실행 시간 측면에서 더 효율적
- 특정한 데이터가 적절한 위치에 들어가기 이전에 그 앞까지의 데이터는 이미 정렬되어 있다고 가정
- 정렬되어 있다는 기준 이후부터 비교를 진행하며 자신보다 작은 경우를 만났을 때 바로 뒤 위치로 이동, 만약 정렬이 아예 안되어 있는 상태에서 첫번째 index가 정렬되어 있다는 조건으로 진행한다면 선택 정렬과 마찬가지의 시간 복잡도 가짐
- 하지만 정렬되어 있는 상태가 클수록 시간복잡도 줄어들며 최선의 경우 O(N)의 시간 복잡도를 가진다
- 정렬 상태가 매우 크다면 퀵 정렬 알고리즘보다도 효율적
- 시간복잡도 : O(N2)
퀵 정렬
- 기준을 설정한 다음 큰 수와 작은 수를 교환한 후 리스트를 반으로 나누는 방식
여기서의 기준은 피벗(Pivot)이라 칭한다.
피벗을 기준으로 퀵 정렬 알고리즘의 분할 방식이 결정된다
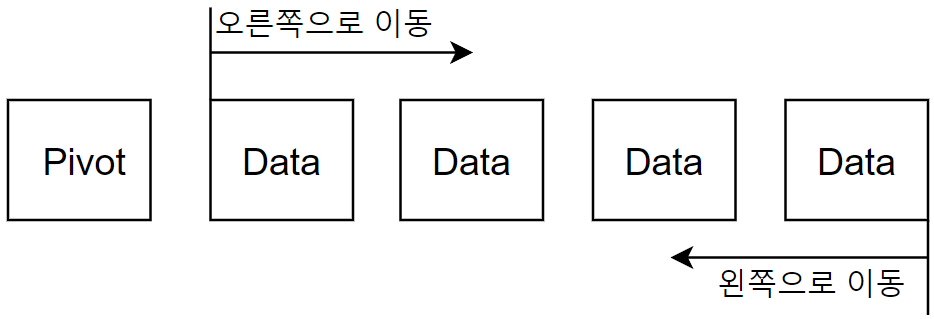
- 리스트에서 첫번째 데이터를 피벗으로 정하고 두번째 데이터 - 마지막 데이터 구간을 시작으로 피벗보다 작은 경우와 큰 경우를 왼쪽에서 오른쪽, 오른쪽에서 왼쪽으로 찾는다
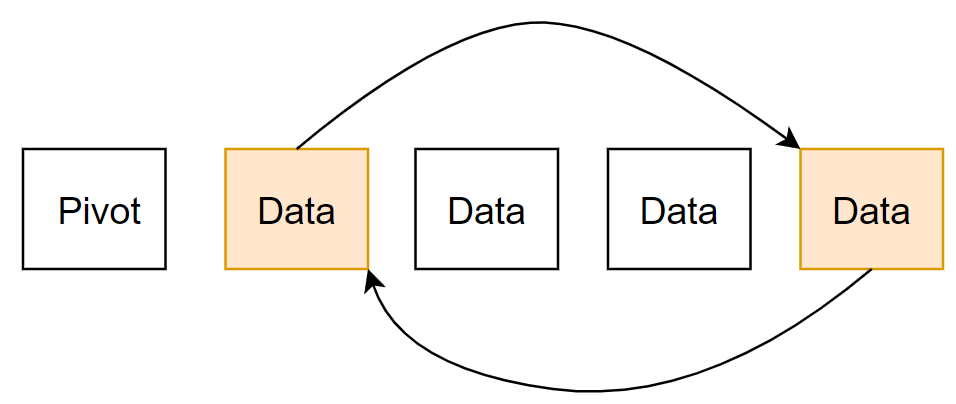
- Pivot보다 작은 경우와 큰 경우를 찾은 경우 서로 자리를 교체
- Pivot보다 작은 경우와 큰 경우의 탐색이 엇갈리는 경우 작은 데이터의 위치와 Pivot의 위치 교체해 Pivot을 기준으로 오른편의 큰 부분과 왼편의 작은 부분으로 분할시킨다
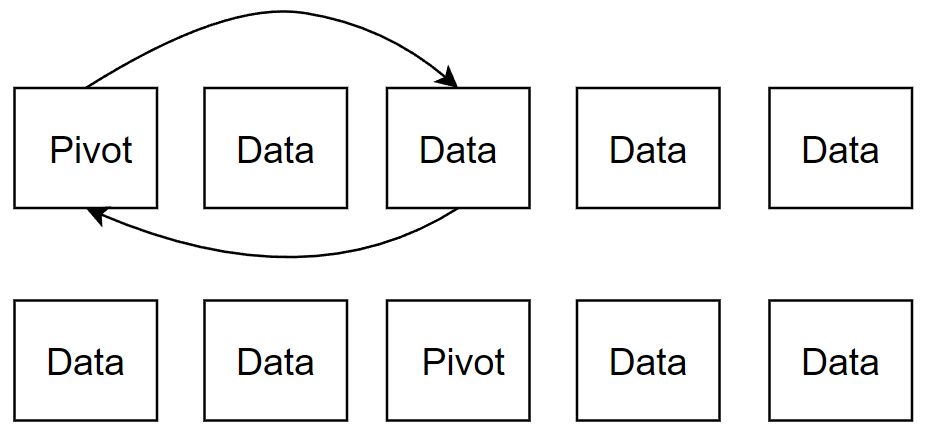
- 분할하는 부분을 축소시키며 반복하는 것이 원리
- 평균 시간 복잡도는 O(NlogN)으로 앞서 설명한 선택, 삽입 정렬보다 효율적
- Pivot을 기준으로 반씩 나눈다해도 과언이 아니기에 log 형태의 시간 복잡도가 나온다
- 최악의 경우 O(N2)가 나오기도 한다
- 때문에 일부 lib는 O(N2)가 나오지 않게끔 Pivot을 설정하는 logic을 추가하기도 한다
- 시간복잡도 : O(NlogN)
계수 정렬 - Count Sort
- 특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠른 알고리즘
- 데이터의 크기 범위가 제한되어 정수 형태로 표현 가능한 경우만 사용 가능
- 데이터의 값이 무한하거나 실수형 데이터가 주어지는 경우는 사용 어렵다
- 가장 작은 데이터, 큰 데이터의 차이가 1,000,000을 넘지 않을 때 효과적으로 사용 가능
- 비교 기반의 정렬 알고리즘이 아니다
- 가장 작은 수부터 가장 큰 수 갯수 크기만큼 리스트를 선언 후 모두 0으로 초기화
데이터를 하나씩 확인하며 데이터의 값과 동일한 인덱스의 데이터를 1씩 증가시킨다
결과적으로 리스트에 각 데이터(index와 동일)가 몇 번 등장했는지 그 횟수가 기록되며 이를 순차적으로 출력 시에 정렬된 형태를 볼 수 있다
013142 처럼 0~4로 이루어진 경우를 예로 들 때
- 순차적으로 출력하면 011234로 출력되며 이는 정렬이 된 결과이다
- 만약 0, 999,999 단 2개만 존재하는 경우 데이터는 2개이지만 리스트의 크기는 100만개가 되도록 선언해야된다
- 데이터와 관련해 제한적인 조건 존재하며 공간 복잡도의 영향 많이 받음
- 시간 복잡도 : O(N+K)
- K : 데이터 중에 가장 큰 양수
lib
sorted()
- 퀵 정렬과 동작 방식이 비슷한 병합 정렬 기반으로 만들어짐
- 퀵정렬보다 느리지만 최악의 경우에도 시간 복잡도 O(NlogN)을 보장
- 별도의 리스트 반환 X
sort()
