[JAVA] Collection과 Collections
Goal
- Collection 프레임워크를 간략히 알아보자
- Collection과 Collections의 차이점을 설명할 수 있다
- 주요 인터페이스인 List, Set 인터페이스를 알아보고, 어떠한 차이가 있는지 설명 할 수 있다
Introduction
처음 JAVA를 배우면서 조금 많이 낯설었던 것이 ArrayList와 같은 자료구조를 구현하고 있는 구현체를 사용하는 것이었다. 찾아보니 Collection Interface를 구현하고 있는 구현체이며 JAVA에서는 데이터를 효율적으로 다루기 위해서 저장, 조작 및 관리를 위해서 사용한다.
Collection
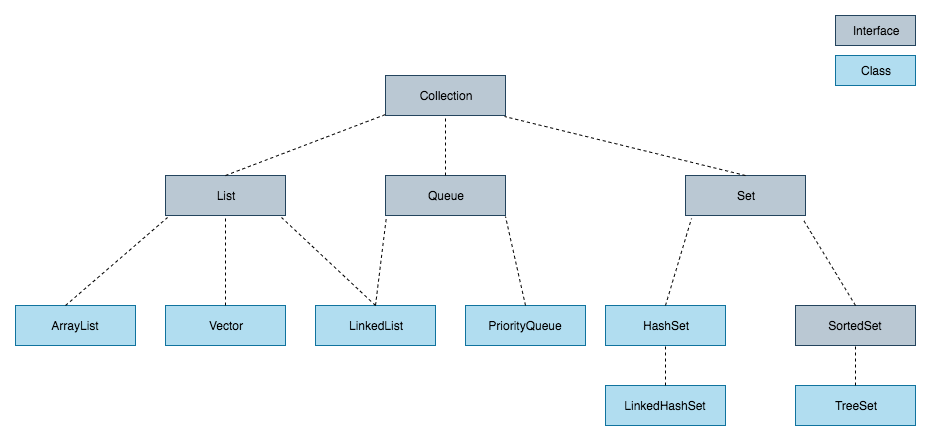
컬렉션 프레임워크(Collection Framework)란 다수의 데이터를 쉽고 효과적인 처리를 할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미합니다.
즉, 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래소 구현한 것입니다.
이러한 컬렉션 프레임워크는 자바의 인터페이스(interface)를 사용하여 구현됩니다.
출처: https://dzone.com/articles/understand-javautilcollection-interface
1. Collection Interface
Collection은 인터페이스로, 컬렉션 프레임워크의 모든 컬렉션 인터페이스의 상위 인터페이스입니다. Collection은 객체의 그룹을 나타내는 데이터 구조를 정의하고, 객체를 추가, 제거, 조회, 순회하는 등의 기본적인 동작을 제공합니다. 주요 인터페이스는 'List', 'Set', 'Queue', 'Deque'등이 있습니다.
Collection 인터페이스를 구현하는 클래스는 'ArrayList', 'HashSet', 'LinkedList'등이 있습니다.
Collection의 메소드
| 메소드 | 설명 |
|---|---|
| boolean add(E e) | 해당 컬렉션(collection)에 전달된 요소를 추가함. (선택적 기능) |
| void clear() | 해당 컬렉션의 모든 요소를 제거함. (선택적 기능) |
| boolean contains(Object o) | 해당 컬렉션이 전달된 객체를 포함하고 있는지를 확인함. |
| boolean equals(Object o) | 해당 컬렉션과 전달된 객체가 같은지를 확인함. |
| boolean isEmpty() | 해당 컬렉션이 비어있는지를 확인함. |
| Iterator iterator() | 해당 컬렉션의 반복자(iterator)를 반환함. |
| boolean remove(Object o) | 해당 컬렉션에서 전달된 객체를 제거함. (선택적 기능) |
| int size() | 해당 컬렉션의 요소 총 개수를 반환함. |
| Object[] toArray() | 해당 컬렉션의 모든 요소를 Object 타입의 배열로 반환함. |
2. Collections Class
Collections는 유틸리티 클래스로, 정적 메소드를 제공하여 컬렉션(Collection)에 대한 다양한 작업을 수행할 수 있도록 도와줍니다. Collections 클래스는 컬렉션의 정렬, 검색, 변환, 동기화 등의 작업을 지원합니다. 이 클래스의 메소드는 주로 정적(static)으로 제공되므로 클래스 이름을 통해 접근합니다. 예를 들어, Collections.sort()는 주어진 컬렉션을 정렬하는 데 사용되고, Collections.synchronizedList()는 동기화된 리스트를 생성하는데 사용됩니다.
'Collection'은 컬렉션 인터페이스를 정의하고, 컬렉션을 조작하는데 필요한 기본 동작을 제공합니다.
반면에 'Collections'는 유틸리티 클래스로, 컬렉션에 대한 다양한 작업을 수행하기 위한 정적 메소드를 제공합니다.
Collections 클래스의 메소드
| 메소드 | 설명 |
|---|---|
| Collections.sort(List l) | 리스트를 정렬합니다. |
| Collections.sort(List L, reverseOrder()) | 리스트를 역순으로 정렬합니다. |
| max(List L), min(List L) | 리스트에서 최대 최소값 |
| shuffle(List L) | 리스트를 랜덤으로 섞음 |
| binarySearch(List L, Key) | 오름차순으로 정렬된 리스트에서 이진검색을 통해 위치를 반환, 실패시에는 -1 반환 |
| disjoint(List L1, List L2) | 두 리스트의 값이 완전히 다른지 검사, 하나라도 같은 값이 있으면 False 반환 |
메소드 code 예제
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Stack<Integer> stack = new Stack<>();
// 0 ~ 9까지 채움
for (int i = 0; i < 10; i++) {
list.add(i);
stack.add(i);
}
// 최대값 max 메소드, 최소값 min 메소드
System.out.println("list max() : " + Collections.max(list));
System.out.println("stack min() : " + Collections.min(stack));
// sort()
Collections.sort(stack);// 오름차순
Collections.reverse(stack); // 내림차순
Collections.sort(stack, Collections.reverseOrder()); // 내림차순
System.out.print("역순 출력: ");
for (int i : stack) {
System.out.print(i + " ");
}
System.out.println();
// 섞기(shuffling) 랜덤하게 섞는다
Collections.shuffle(stack);
System.out.print("랜덤 출력: ");
for (int i : stack) {
System.out.print(i + " ");
}
System.out.println();
// binarySearch() -> 해당값의 index를 반환(실패시 -1 반환)
// 오름차순 정렬이 되어있어야 사용가능핟.
Collections.sort(stack); // 오름차순
System.out.print("정방향 정렬: ");
for (int i : stack) {
System.out.print(i + " ");
}
System.out.println();
System.out.print("이진 탐색 5 값의 위치: " + Collections.binarySearch(stack,5));
System.out.println();
// 두 리스트가 다른지 확인 disjoint
// 두 리스트중 공통 값이 있으면 false
ArrayList<Integer> list2 = new ArrayList<>(Arrays.asList(99,98));
System.out.println("list가 완전히 다른가? : "+ Collections.disjoint(list, list2)); // true
System.out.println("list가 완전히 다른가? : "+ Collections.disjoint(list, stack)); // false
}자료구조 별 대략적인 특징
| Class | Base Class | Base Interface | 중복 | 순서 | 정렬 | Thread-safe |
|---|---|---|---|---|---|---|
| ArrayList | AbstractList | List | Yes | Yes | No | No |
| LinkedList | AbstractSequentialList | List; Deque; | Yes | Yes | No | No |
| Vector | AbstractList | List | Yes | Yes | No | Yes |
| HashSet | AbstractSet | Set | No | No | No | No |
| LinkedHashSet | HashSet | Set | No | Yes | No | No |
| TreeSet | AbstractSet | NavigableSet | No | Yes | Yes | No |
| HashMap | AbstractMap | Map | No | No | No | No |
| LinkedHashMap | HashMap | Map | No | Yes | No | No |
| Hashtable | Dictionary | Map | No | No | No | Yes |
| TreeMap | AbstractMap | NavigableMap | No | Yes | Yes | No |
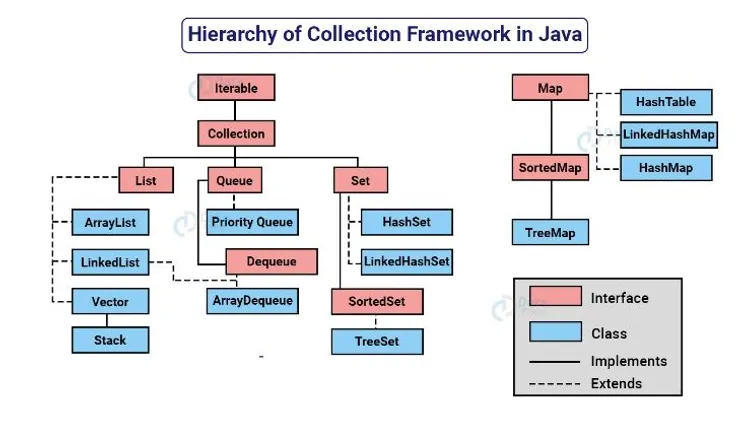
출처 : https://www.numpyninja.com/post/all-you-need-to-know-about-java-collections-framework
자바에서 해당 Collections의 사용법을 아는 것도 중요하지만,
해당 자료구조가 어떨때 사용 되어야 하며, 언제 유리한지, 어느 정도의 시간복잡도와 성능을 가지는지도 알아야 합니다.
2. Collection 하위 인터페이스
List는 순서가 있는 요소의 그룹이 필요한 경우에 주로 사용됩니다.
Set은 중복을 허용하지 않고 고유한 요소를 유지해야 하는 경우에 사용됩니다. 예를 들어, 집합(set)의 개념을 구현하거나 고유한 값을 추적하는 경우에 유용합니다.
1) List 인터페이스
- 순서가 있는 컬렉션입니다. 즉, 요소들은 추가된 순서대로 유지
- 동일한 요소를 중복해서 포함될 수 있습니다. 따라서 List는 중복 요소를 허용합니다.
- 인덱스를 사용하여 요소에 접근합니다. 요소의 위치를 변경하거나 삭제하는 등의 작업도 가능
- 일반적인 구현체는 'ArrayList', 'LinkedList', 'Vector'등이 있습니다.
ArrayList
- 내부적으로 배열(Array)을 사용하여 요소를 저장하고 관리합니다.
- 배열의 크기를 동적으로 조정할 수 있으며, 요소를 인덱스를 통해 빠르게 접근 할 수 있습니다.
- 요소의 추가나 삭제 시 해당 위치에서 요소들을 이동하거나 재배치해야 하므로, 리스트의 중간에 요소를 삽입하거나 삭제하는 연산은 비용이 높을 수 있습니다.
- 인덱스를 통한 임의의 요소 접근과 반복문에서의 순차적인 접근에 강점을 가지며, 검색 연산에도 빠릅니다.
- ‘ArrayList’는 스레드에 안전하지 않은(non-thread-safe) 클래스이므로, 동시에 여러 스레드에서 사용될 경우 외부에서 동기화 해주어야 합니다.
LinkedList
- 이중 연결 리스트(Doubly Linked List)로 구현됩니다. 각 요소는 이전 노드와 다음 노드의 링크로 연결되어 있습니다.
- 요소의 추가나 삭제 시 링크만 변경하면 되므로, 리스트의 중간에 요소를 삽입하거나 삭제하는 연산이 빠릅니다.
- 하지만 인덱스를 통한 임의의 접근은 느리며, 특정 위치의 요소에 접근하기 위해서는 처음부터 순차적으로 이동해야 합니다.
- ‘LinkedList’는 큐(Queue)나 스택(Stack)과 같은 특정 동작을 구현하기 위해 유용합니다.
- ‘LinkedList’는 스레드에 안전하지 않는(not-thead-safe) 클래스이므로, 동시에 여러 스레드에서 사용될 경우 외부에서 동기화 해주어야 합니다.
‘ArrayList’은 요소의 접근과 반복에 효율적이며, 크기가 동적으로 변하는 리스트에 적합하고
‘LinkedList’는 요소의 삽입과 삭제가 빈번하게 발생하는 경우에 효율적이며, 큐나 스택과 같은 특정 동작을 구현할 때 활용됩니다.
2) Set 인터페이스
- 순서가 없는 고유한 요소의 컬렉션입니다. 즉, 요소들은 임의의 순서로 저장됩니다.
- 동일한 요소를 중복해서 포함될 수 없습니다. 따라서 Set은 중복 요소를 허용하지 않습니다.
- 주로 멤버십 테스트(특정 요소가 Set에 속하는지 여부 확인)와 검색에 사용됩니다.
- 일반적인 구현체는 'HashSet', 'TreeSet', 'LinkedHashSet'등이 있습니다.
HashSet
- 해시 테이블을 사용하여 요소를 저장하고 검색하는데 효율적인 방식으로 구현됩니다.
- 순서를 보장하지 않으며, 요소들이 임의의 순서로 저장됩니다.
- null 요소를 허용
hashCode()와equals()메서드를 사용하여 요소의 고유성과 동등성을 확인합니다.- 요소의 추가, 삭제, 검색 연산의 평균적인 시간 복잡도는 O(1)입니다.
TreeSet
- 이진 검색 트리(Binary Search Tree)를 사용하여 요소를 저장하고 검색하는데 효율적인 방식으로 구현됩니다.
- 요소들이 정렬된 순서로 저장됩니다. 기본적으로 요소의 "자연적인 순서"에 따라 정렬되며, 또는
Comparator를 통해 사용자 정의 순서로 정렬할 수도 있습니다. - null 요소를 허용하지 않음
- 요소의 추가, 삭제, 검색 연산의 평균적인 시간 복잡도는 O(log n)입니다.
‘HashSet’은 순서가 중요하지 않고 검색 속도가 빠른 경우에 유용하고
‘TreeSet’은 정렬된 순서가 필요하거나 범위 검색 등의 연산이 필요한 경우에 유용합니다.
