서론
RabbitMQ를 간단하게 다뤄보면서, 분산 메세지큐 기술에 관심을 가지게 되었다.
엄밀하게 말하자면, 오늘 포스팅할 카프카는 메시지큐 기술이 아닌, 이벤트 브로커 기술이다. 그중에서도 가장 많이 쓰이는 Apache Kafka는 왜 쓰이는지 알아보자.
본론
메시지 지향 미들웨어(MOM)이란 ?
- 응용 소프트웨어간의
비동기적 데이터 통신을 위한 시스템 - 메시지 지향 미들웨어는
메시지를 전달하는 과정에서 보관하거나 라우팅 및 변환할 수 있다는 장점을 가진다. - 즉 메시지큐는 FIFO(선입선출) 자료구조인 Queue를 통해 메시지 지향 미들웨어를 구현한 시스템이라고 보면 된다.
메시지 브로커 vs 이벤트 브로커
-
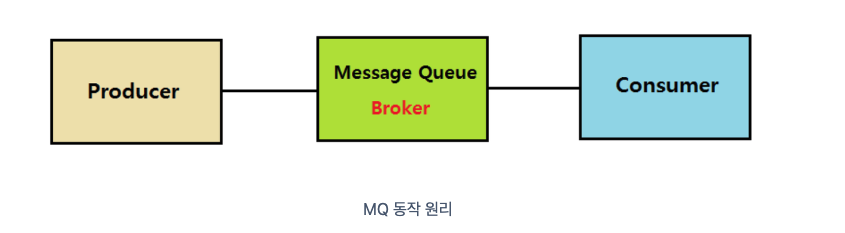
메시지 브로커 :
- 메세지 브로커는 Producer가 생산한 메시지를 메세지 큐에 저장하고, 저장된 메시지를 Consumer가 가져가고, 메시지큐에서 삭제되는 구조다. -
이벤트 브로커 :
- 메시지 브로커에서는 Consumer가 메시지를 가져가면 삭제되지만,이벤트 브로커에서는 얼마든지 다시 소비할 수 있다.
✨ 카프카란 ?
카프카(Kafka)는 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된 고성능 분산 이벤트 스트리밍 플랫폼이다.
카프카 도입 이전의 문제점
- 기존 애플리케이션과 DB가 end-to-end구조
-> 파이프라인이 파편화되어 있고, 요구사항이 추가될 때마다, 데이터 시스템의 복잡도가 높아짐에 따라 파이프라인 관리가 어려워짐
이러한 문제를 해결하기 위해 모든 이벤트/데이터의 흐름을 중앙에서 관리하는 시스템인 Kafka가 개발되었다.
카프카 개념
브로커
- 카프카 클라이언트와 데이터를 주고받기 위해 사용하는 주체
데이터를 분산 저장하여 장애 발생 시 안정성 확보1 : 1관계로 서버, 카프카 프로세스가 매칭되는 프로세스- 안정성을 위해
3대 이상의 브로커 서버를 한 개의 클러스터로 묶어 운영 - 카프카 클러스터로 묶인 브로커들은 프로듀서가 보낸 데이터를 안전하게 분산 저장 및 복제하는 열할을 수행한다.
데이터 전송, 저장
- Producer : 데이터 생산
- Consumer : 데이터 소비
- Broker : 프로듀소가 요청한 토픽의 파티션에 데이터를 저장하고, 컨슈머가 데이터를 요청하면 저장된 데이터를 전달하는 역할을 수행
프로듀로서부터 전달된 데이터는DB, Memory에 저장되는 것이 아닌 File System에 저장된다.
데이터 복제, 싱크
카프카를 장애 허용 시스템으로 동작하도록 하는 원동력이다.
- 데이터 복제는 파티션 단위로 이루어짐
- 복제된 파티션은
리더, 팔로워로 나뉘어져 관리된다. - 리더 : 프로듀서, 컨슈머와 직접 통신하는 파티션
- 팔로워 : 나머지 복제 데이터
리더 파티션을 가지고 있는 브로커에 에러가 발생하면, 팔로워 파티션 중 하나가 리더를 넘겨받는다.
데이터 삭제
- 카프카는 컨슈머가 데이터를 가져가더라도 토픽의 데이터를 삭제하지 않는다. (메시지큐와 가장 큰 차이점이다.)
- 프로듀서나 컨슈머는 삭제를 요청하지 않는다. 오직 데이터 관리는 브로커가 수행한다.
데이터 삭제는 파일 단위(로그 세그먼트)로 이루어지기 때문에, 일반적인 DB처럼특정 DB를 선발해서 삭제가 불가능하다.
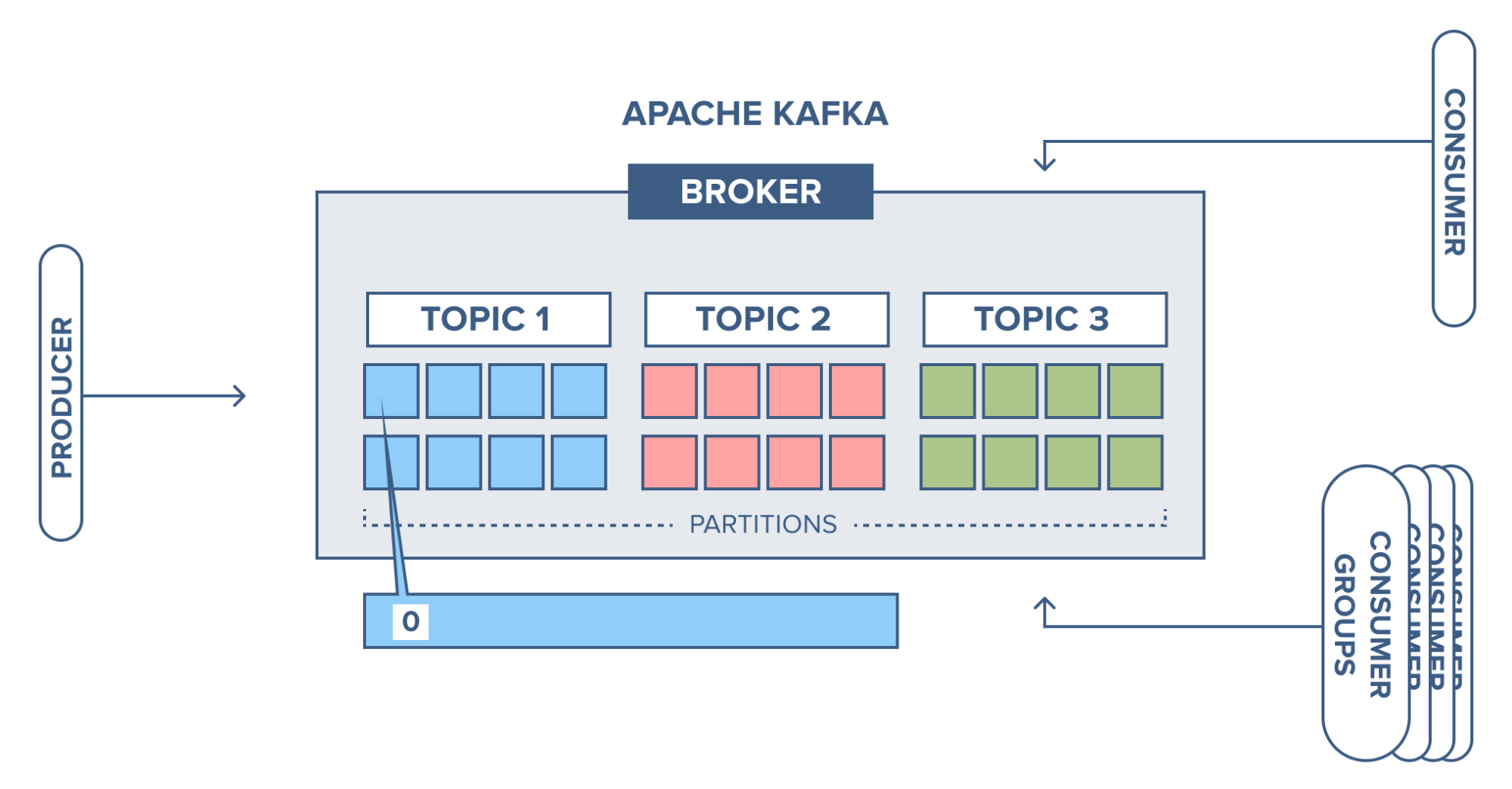
토픽
- 토픽 삭제 -> 데이터 삭제 -> 파이프라인 중단
- 1개 이상의 파티션 보유
파티션
- 토픽은 1개 이상의 파티션
- 프로듀서가 보낸 데이터들은 파티션에 저장된다. 해당 데이터를 "레코드"라고 부른다.
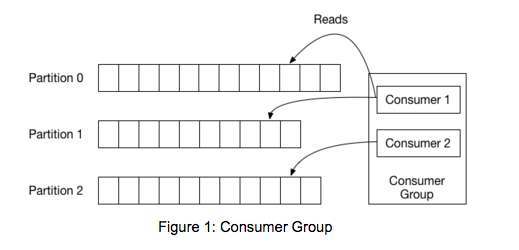
- 카프카의 병렬 처리의 핵심
- 컨슈머의 처리량이 한정된 상황에서, 많은 레코드를 병렬로 처리하는 가장 좋은 방법은
컨슈머의 개수를 늘려 스케일 아웃하는 것이다.
컨슈머 그룹
- 컨슈머 그룹으로 묶은 컨슈머들은 토픽의 1개 이상의 파티션에 할당되어 데이터를 가져온다.
- 컨슈머 그룹의 개수 <= 토픽의 파티션 개수
Offset 커밋
- 컨슈머는 카프카 브로커로부터
데이터를 어디까지 가져갔는지커밋을 통해 기록 - 커밋 방법은 비명시 커밋과 명시 커밋으로 나뉜다.
- 비명시 커밋 : 일정 간격마다 자동으로 수행된다.
- 명시 커밋 : 사용자가 직접 커밋을 수행하는 방식으로, 데이터 유실과 중복을 허용하지 않는다. (데이터 정합성을 유지하는데 더 뛰어난 방법이다)
명시 커밋
명시 커밋은 또 동기 오프셋 커밋과, 비동기 오프셋 커밋으로 나뉜다.
- 동기 오프셋 커밋 : 브로커로 커밋 요청 이후 커밋이 완료되기까지 대기하는 방식
-> 완료 응답을 대기하기 때문에 처리량이 낮아 속도가 오래걸린다. - 비동기 오프셋 커밋 : 대기하지 않고 callback 함수를 통해 결과를 얻는다.

내 기억보단 내가 작성한 기록을 보자..