
서론
현재 일일 미션 인증 서비스는 로그인 이후 넘어가는 메인페이지로, 미션 리스트를 보여주고 있다. 즉, 사용자들이 접속할 때마다 미션 리스트에 대한 조회 쿼리를 api 서버가 수행하기 때문에, DB I/O 부하를 낮추고, 효율적으로 리소스를 사용하기 위해서 Redis로 글로벌 캐싱을 사용하고 있다.
본론
캐시 데이터는 메모리의 한정된 저장 공간을 효율적으로 사용하기 위해서와 데이터의 일관성을 이유로, TTL설정해서 데이터를 갱신한다. 개발하던 중, 문득 '그럼 TTL이 만료되서 캐시 데이터 갱신이 일어나는 시점에, 사용자가 동시에 접속하면 어떡하지'라는 생각이 들었다...
이러한 현상을 캐시 스탬피드라고 한다.
캐시 스탬피드
캐시가 만료된 상태로 요청이 몰리면, 순간적으로 DB에 동일한 데이터를 조회한 뒤 캐시 시스템에 중복된 쓰기 요청이 몰리는 현상
쓰기 요청이 몰리는 현상도 위험성이 크지만, 동일한 조회 쿼리를 DB에 질의할 때 DB 서버에 대한 부하가 가중된다는 점, 또 동일한 쿼리가 수백개, 수천개가 수행될 수 있기 때문에 이러한 부분에서 개선의 필요성을 느꼈다.
이를 해결하기 위한 방법으로 캐시가 만료되기 전 배치로 재생성할 수 있는 등이 있는데, PER 알고리즘이라는 키워드를 접했다.
PER(Probablistic Early Recomputation) 알고리즘
캐시 유효시간이 만료되기 전 일정 확률로 캐시를 재연산하는 방식
- 장점
- 시스템 부하 분산
- 캐시 만료가 동일한 시점에 집중되지 않고, 랜덤하게 확률적으로 분산되기 때문에 특정 순간에 발생할 수 있는 시스템 부하 완화
- 효율적 리소스 사용
- 만료 시점 이전에 캐시를 확률적으로 갱신하므로, 필요하지 않은 캐시 갱신을 줄이면서도 일정 수준의 데이터 신뢰성 유지
적용
Redis의 @cacheable, @cacheEvict 등 어노테이션이 AOP를 기반으로 동작하고 있고, 또 cache 클래스를 생성해서 기존의 서비스 계층에 의존성을 추가해야 하는 점 때문에, @Cacheable에 대한 AOP를 커스텀하여 작성했다.
PER 알고리즘 코드 작성
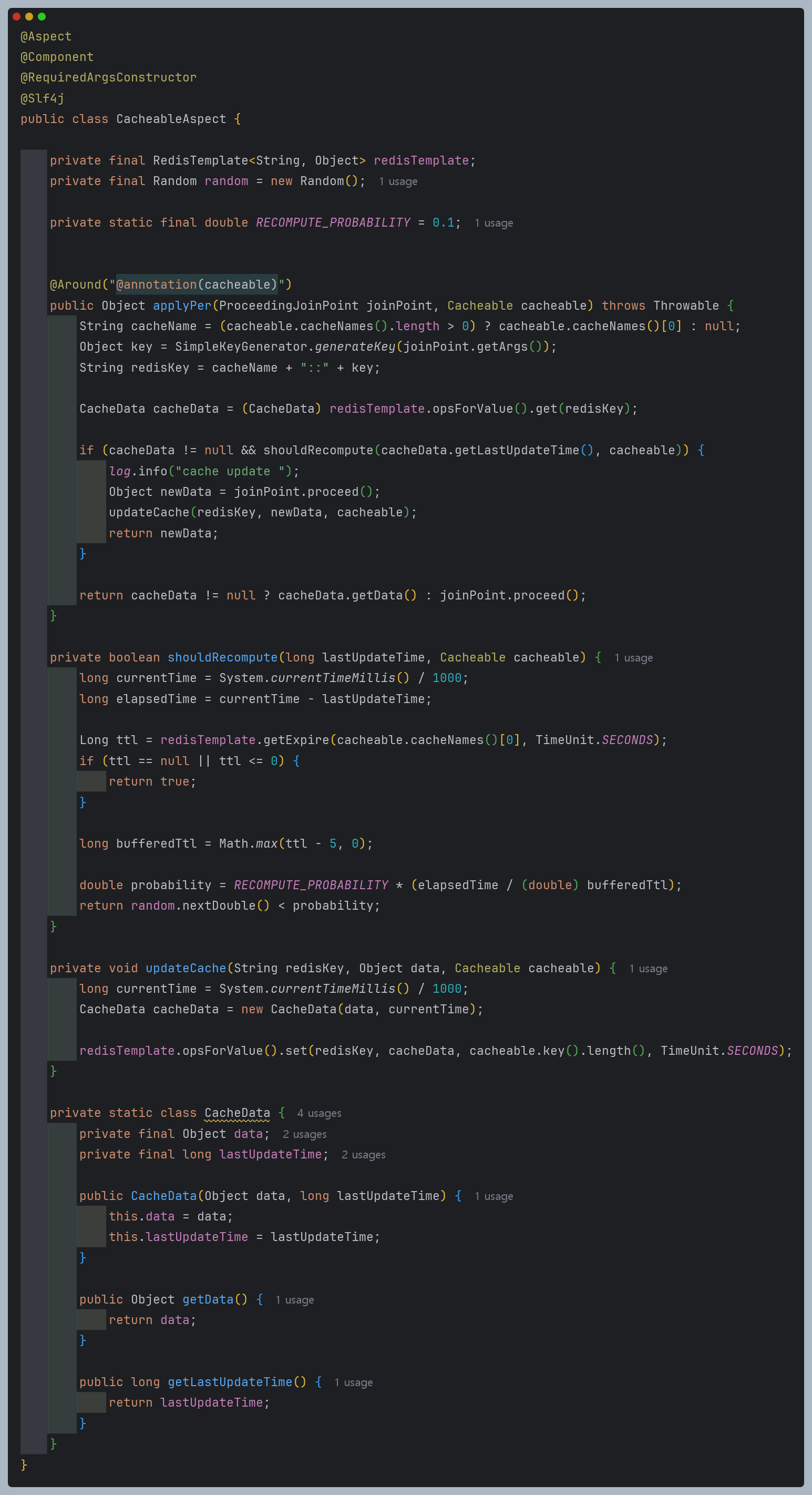
-
핵심 설명
갱신 확률 = 기본 확률 × (경과 시간 ÷ 만료 시간) -
기본확률(RECOMPUTE_PROBABILITY) : 처음에 설정된 갱신 확률인데, 개발자가 값을 높게 부여할수록 갱신 빈도수는 감소하고, 반대는 역이다.
-
경과 시간(elapsed Time) : 캐시를 마지막으로 갱신하고 얼마나 시간이 지났는지, 현재 시간과 - 연산 수행을 통해서 값을 가져온다.
-
비율 계산(elapsedTime ÷ EXPIRATION_TIME) : 경과 시간을 만료 시간으로 나누면, 현재까지 얼마나 시간이 흘렀는지 비율을 구할 수 있다.
즉, 기본 확률에 비율을 곱해, 시간이 흐를수록 갱신 확률이 점점 커지는 것이 해당 알고리즘이 핵심이다.
위 알고리즘 연산을 수행하는데 있어, 캐시가 마지막 갱신 시각을 가지고 있어야하기 때문에, CacheData 클래스를 작성했다.
마지막으로, 갱신 확률과 0.1 ~ 0.5 사이의 랜덤값과 비교해서 갱신하도록 코드를 작성했다.
추가적으로, 캐시 만료 시간을 Redis에서 꺼내오는 만큼 허점이 있는데, TTL 코드 부분을 보자.
허점 개선 사항
Long ttl = redisTemplate.getExpire(cacheable.cacheNames()[0], TimeUnit.SECONDS);
if (ttl == null || ttl <= 0) {
return true;
}
long bufferedTtl = Math.max(ttl - 5, 0);5초의 버퍼를 거는 로직이다.
캐시의 만료시간을 조회하고, 로직을 수행하는 중 캐시가 만료되는 것을 방지한다.
이로 인해 캐시 만료로 캐시 미스가 발생하지 않도록 예방할 수 있다.
정리하자면, TTL이 남아 있지만, 5초 이하로 줄어들면 데이터 갱신을 시도해 캐시 히트율을 높히는 코드라고 할 수 있겠다.
이전과 비교
Jmeter를 활용한 부하 테스트로 PER 알고리즘 도입 전과 후를 비교해보았다.
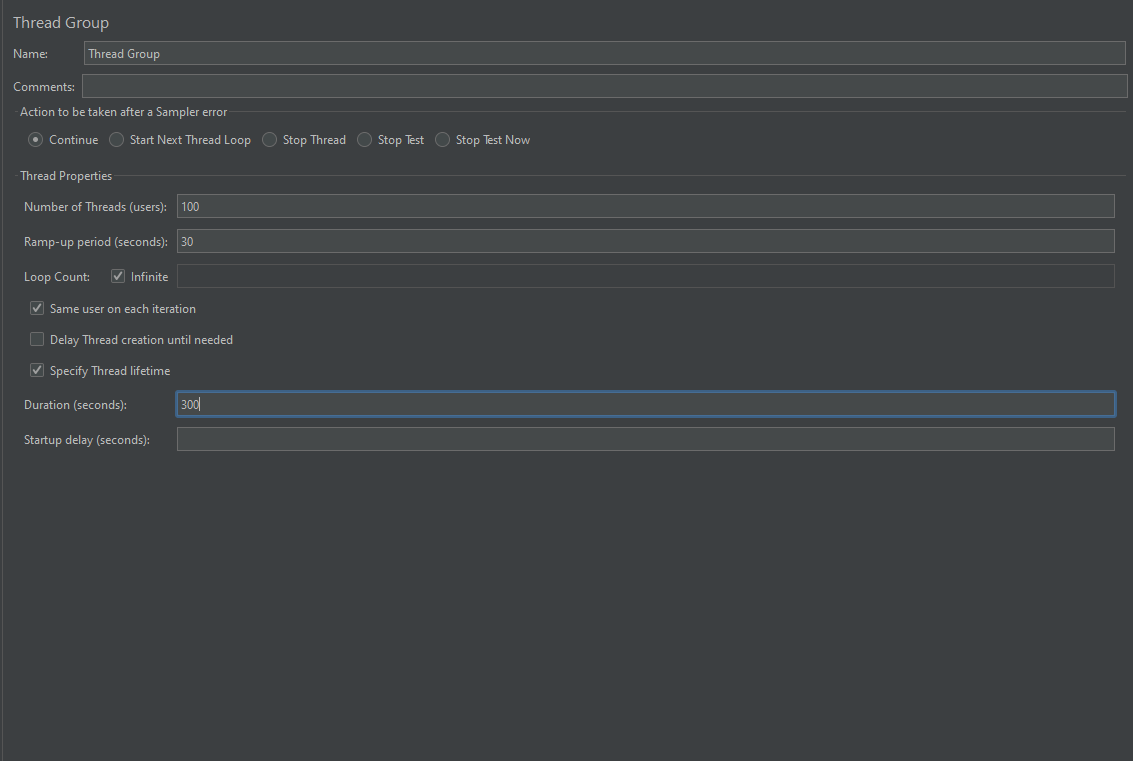
100개의 쓰레드, 30초당 요청, 5분동안 지속하도록 Thread Group을 설정했다.
- 캐시 데이터 조회에 대한 TPS 그래프
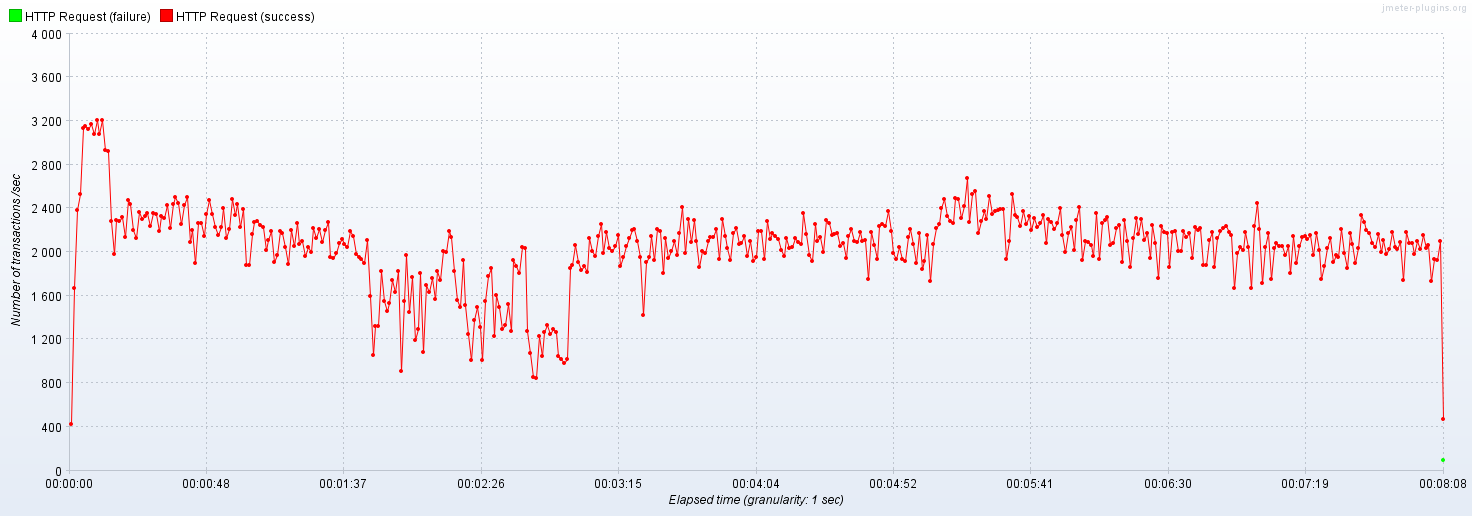
이전에는 ,캐시가 갱신하는 시점에 캐시 미스가 발생해서 TPS가 800까지도 떨어지는 구간이 있었다.
적용 후
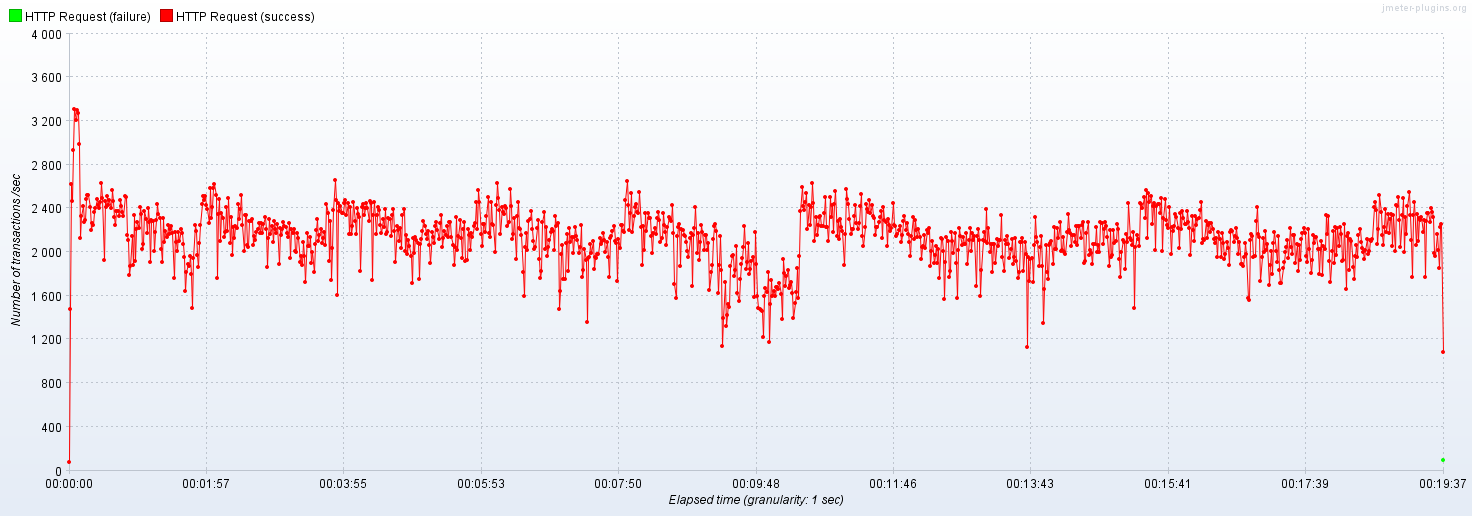
비록 1200 TPS으로 낮은 수치를 기록하지만, 캐시 미스를 어느정도 방어해서 TPS가 튀는 정도가 이전과 비교해서 좋아졌다.
결론
외부 의존성도 추가하지 않아도 되고, 대규모 서비스에서 어플리케이션이 동시에 캐시를 갱신하는 케이스로 인한 캐시 미스도 방지할 수 있는 효율적인 리소스 사용을 도모하는 알고리즘이라고 생각한다.
