네이버 웹툰 프리인터뷰 면접을 통해
- 자바에서 Error와 Exception이 있는데 이 둘의 차이는 무엇일까요?
- NullPointException은 checkedException일까요? uncheckedException일까요?
- checkedException, uncheckedException, RuntimeException의 차이점은 무엇일까요?
와 같은 질문을 받은 적이 있다. 기본적인 자바 개념들을 고민하지 않고 주입식으로 학습하였고, 언제 어떠한 상황에서 사용해야 되는지에 대한 고민을 해보지 못했다. 그렇기에 두루뭉실한 답변을 뱉을 수밖에 없었다.
이러한 나의 과거 상황을 반성하며 자바 예외에 대한 기본기를 탄탄하게 쌓고 스프링에서 예외를 처리하는 여러가지 매커니즘에 대해 확실히 이해하고자 한다.
오류와 예외의 차이는 무엇인가?
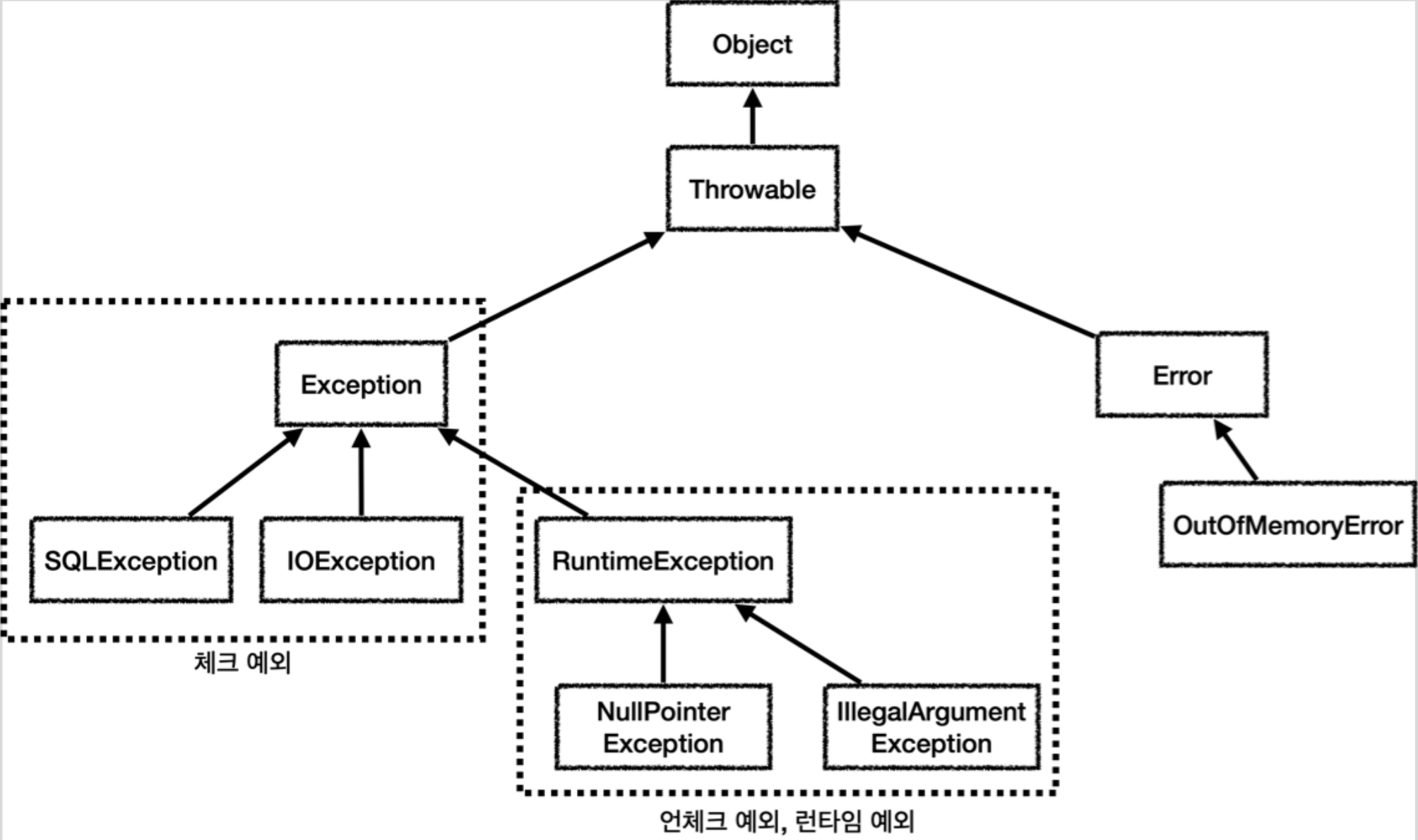
자바의 모든 예외는 기본적으로 Throwable에서 시작하고, 예외 역시도 자바 객체이기 때문에 Throwable의 최상위 부모도 Object다. Throwable을 상속받는 클래스는 Exception과 Error가 있다.
Error는 메모리 부족이나 심각한 시스템 오류와 같이 시스템 레벨에서 발생하기 때문에 애플리케이션 수준에서 예외를 잡으려고 해서는 안된다.
Exception은 애플리케이션 수준에서 사용할 수 있는 실질적인 최상위 예외이다. 예외는 발생할 상황을 미리 예측할 수 있다. 즉, 개발자가 처리할 수 있기 때문에 예외를 구분하고 그에 따른 처리 방법을 명확히 알고 적용하는 것이 중요하다.
checkedException과 uncheckedException
Exception의 하위 클래스 중 RuntimeException을 제외한 모든 Exception은 컴파일러가 체크하는 checkedException이며, RuntimeException과 그 하위 클래스들은 컴파일러가 체크하지 않는 uncheckedException이라고 부른다.
체크 예외는 컴파일 타임에 체크가 되기 때문에 예외를 잡아서 처리하거나 throws를 지정해서 예외를 밖으로 던진다는 선언을 필수로 해야 한다. 그렇지 않으면 컴파일 오류가 발생한다.
체크 예외는 어떠한 장/단점을 가질까?
우선 장점은 컴파일 타임에 문제가 발견되기 때문에 개발자가 실수로 예외를 누락하지 않도록 만들 수 있다. 처리할 수 있는 예외라면 서비스나 컨트롤러에서 처리할 수 있겠지만 데이터베이스나 네트워크와 같은 시스템 레벨에서 올라온 예외들은 대부분 복구가 불가능하다. 이런 아래에서 올라온 복구 불가능한 예외를 서비스, 컨트롤러 같은 각각의 클래스가 모두 알고 있어야 한다. 그래서 불필요한 의존관계 문제가 발생하게 된다.
SQLException 을 예로 들면 데이터베이스에 무언가 문제가 있어서 발생하는 예외이다. SQL 문법에 문제가 있을 수도 있고, 데이터베이스 자체에 뭔가 문제가 발생했을 수도 있다. 데이터베이스 서버가 중간에 다운 되었을 수도 있다. 이런 문제들은 대부분 복구가 불가능하다. 특히나 대부분의 서비스나 컨트롤러는 이런 문제를 해결할 수는 없다. 따라서 이런 문제들은 일관성 있게 공통으로 처리해야 한다. 오류 로그를 남기고 개발자가 해당 오류를 빠르게 인지하는 것이 필요하다. 서블릿 필터, 스프링 인터셉터, 스프링의 ControllerAdvice 를 사용하면 이런 부분을 깔끔하게 공통으로 해결할 수 있다.
또한 서비스 계층 그리고 컨트롤러 계층까지 SQLException과의 의존관계가 생기게 된다. 향후 데이터베이스 접근 기술을 JDBC 기술이 아닌 다른 기술로 변경한다면 JDBC 기술에 종속된 SQLException이 아닌 다른 예외가 발생하게 되고 의존 관계에 있는 코드들을 찾아서 모두 수정해야만 한다. 이는 결과적으로 OCP, DI를 통해 클라이언트 코드의 변경 없이 대상 구현체를 변경할 수 있다는 장점이 체크 예외 때문에 발목을 잡게 된다.
언체크 예외는 런타임에 발견되기 때문에 명시적으로 처리를 강제하지 않는다.
언체크 예외는 어떠한 장/단점을 가질까?
throws를 생략할 수 있다. → 신경쓰고 싶지 않은 예외의 의존관계를 참조하지 않아도 되는 장점이 존재
반면 개발자가 명시적으로 코드를 짜지 않는 이상 실수로 예외를 누락시킬 수 있는 가능성이 존재한다.
체크 예외와 언체크 예외의 차이는 예외를 처리할 수 없을 때 예외를 밖으로 던지는 부분에 있다. 이 부분을 필수로 선언해야 하는가 혹은 생략할 수 있는가의 차이다.
위의 체크 예외를 사용함으로써 발생하는 문제를 언체크 예외를 사용함으로써 해결할 수 있다.
시스템에서 발생한 예외는 대부분 복구 불가능한 예외이기 때문에 이를 uncheckedException으로 추상화하면 서비스나 컨트롤러에서 이런 복구 불가능한 예외를 신경쓰지 않아도 된다. 하지만 이렇게 복구 불가능한 예외는 위에서 말한 것과 같이 일관성 있게 공통으로 처리해야 한다. 이는 의존 대상이 변경할 경우 공통 처리하는 곳에서만 변경하면 되기 때문에 변경의 영향 범위도 최소화 된다. 또한 체크 예외처럼 예외를 강제로 의존하지 않아도 된다.
두 예외를 어떠한 상황에 사용해야 하는가에 대한 기준을 확립해야 한다
- 기본적으로 언체크(런타임) 예외를 사용한다.
- 체크 예외는 비즈니스 로직 상 의도적으로 던지는 예외에만 사용한다.
- 예. 계좌 이체 실패 예외, 결제 시 포인트 부족 예외, 로그인 ID, PW 불일치 예외 등
- 위의 예와 같은 예외들은 개발자가 실수로 놓칠 경우 애플리케이션 운영 시에 심각한 문제 상황을 발생시키기 때문에 컴파일 타임에 체크할 수 있도록 체크 예외를 사용하는 것이 좋다. 하지만 무조건 체크 예외로 만들어야 하는 것은 아니다. 상황을 깊이 들여다보고 판단하자.
범위 밖의 내용이지만 예외를 전환할 경우 기존 예외를 포함해야한다. 스택 트레이스 확인을 통해 어떤 예외가 발생하는지 확인하는 것이 중요하기 때문
오개념 지우기
checkedException은 예외 발생 시 트랜잭션 롤백을 하지 않음 vs uncheckedException은 예외 발생 시 트랜잭션 롤백을 함으로 정리된 표가 많은 블로그에서 참조되고 있다. 하지만 이는 특정 부분에 국한되어 이야기되는 것으로 트랜잭션은 이런 예외일 때 이렇게 하고, 저런 예외일 때는 저렇게 한다가 사실 정해져 있는 것이 아니다. 트랜잭션의 종류도 다양한데다가(DB 트랜잭션, 메세징 큐 트랜잭션.. 등)
모든 트랜잭션을 저 개념에 국한시켜 말하는 것은 아니라고 한다. checkedException이냐 uncheckedException 이냐에 따라 롤백을 할 것인가는 우리가 정하는 것이다.
스프링 트랜잭션의 예외 발생 시 롤백 여부는 트랜잭션의 옵션을 통해 설정이 가능하다. 자세한 사항은 스프링 도큐먼트 rollbackFor, rollbackForClassName, noRollbackFor, noRollbackForClassName 옵션을 확인하기 바란다.
rollbackFor
트랜잭션 작업 중 런타임 예외가 발생하면 롤백한다. 반면에 예외가 발생하지 않거나 체크 예외가 발생하면 커밋한다.
체크 예외를 커밋 대상으로 삼는 이유는 체크 예외가 예외적인 상황에서 사용되기 보다는 리턴 값을 대신해서 비즈니스 적인 의미를 담은 결과로 돌려주는 용도로 사용되기 때문이다.
스프링에서는 데이터 엑세스 기술의 예외를 런타임 예외로 전환해서 던지므로 런타임 예외만 롤백대상으로 삼는다.
하지만 원한다면 체크예외지만 롤백 대상으로 삼을 수 있다. rollbackFor또는 rollbackForClassName 속성을 이용해서 예외를 지정한다.
