Reconstruct 3D scenes from 2D images over six different domains
https://www.kaggle.com/competitions/image-matching-challenge-2024/overview
Overview
목표: 다양한 시나리오와 환경에서 이미지 세트를 사용하여 정확한 3D 지도를 구성하는 것
(드론에서 촬영한 이미지, 울창한 숲 속, 야간 또는 6가지 문제 범주 중 하나 등 소스 도메인에 관계없이 정확한 공간 표현을 생성하는 모델을 개발)
설명:
랜드마크와 역사적 장소는 지구상에서 가장 자주 촬영되는 장소 중 일부입니다. 그러나 각 샷은 약간 다른 각도를 가지고 있으며 그림자는 하루 중 또는 연중 시간에 따라 다릅니다. 한 장의 사진은 땅에서, 다른 한 장은 몇 개의 계단 위에서, 세 번째 사진은 드론에서 촬영할 수 있습니다. 다양한 관점에서 많은 이미지를 일치시키는 것은 근본적인 컴퓨터 비전 문제로, 해결과는 거리가 멉니다. 표면 질감이나 주변 환경과 같은 요인은 그렇지 않으면 성능이 좋은 알고리즘을 저하시킬 수 있습니다.
이미지 모음에서 환경의 3D 모델을 재구성하는 프로세스를 Structure from Motion(SfM)이라고 합니다. 이러한 이미지는 종종 훈련된 운영자나 추가 센서 데이터와 함께 캡처됩니다. 이를 통해 균일하고 고품질의 데이터가 보장됩니다. 이 대회를 위해 함께 모은 실제 사례인 다양한 이미지에서 3D 모델을 구축하는 것은 훨씬 더 어렵습니다. 사실, 우리는 각각 고유한 과제가 있는 6가지 범주를 지정했습니다.
- 사진 관광 및 역사 보존: 다양한 시점, 센서 유형, 시간/연도 및 폐색. 고대 유적지는 독특한 도전 과제를 추가합니다
- 밤과 낮 및 시간적 변화: 조명이 약한 경우를 포함하여 낮과 밤의 사진 조합 또는 여러 날씨에서 몇 달 또는 몇 년 간격으로 촬영한 사진
- 공중 및 혼합 공중 지상: 임의의 평면 내 회전을 특징으로 하는 드론의 이미지를 유사한 이미지 및 지상에서 촬영한 이미지와 대조
- 반복되는 구조: 대칭 개체에는 관점을 명확하게 하기 위한 세부 정보가 필요합니다.
- 자연환경: 나무, 나뭇잎 등 매우 불규칙한 구조물
- 투명도 및 반사: 유리 제품과 같은 물체는 질감이 부족하고 반사 및 반사를 생성하여 다른 문제를 야기합니다.
여러분의 노력은 컴퓨터 비전의 이 근본적인 문제를 더 잘 이해하는 데 기여할 수 있습니다. 우리는 많은 카테고리를 포함하여 전통적인 이미지 매칭 기술과 최첨단 머신 러닝 간의 지식 공유를 장려하고자 합니다.
평가:
기준 mean Average Accuracy (mAA)
(행렬에 의해 매개변수화 된 장면의 카메라 세트가 주어지면, “the hidden ground truth” 를 통해 “ the best similarity transformation T”를 찾는다. (회전, 반전, 빛번짐 etc)
C와 t 는 주어진 임계값이다. RANSAC 와 유사한 접근 방식을 사용하면 간으한 모든 nCM실현 가능한 유사성 변환 “T” 은 카메라 중심의 삼중선에 대한 Horn 의 방법으로 파생될수 있습니다.
초기 트리플릿과 함께 이전에 등록된 카메라를 포함합니다.
가정하면 원래 카메라 중앙 트리플릿을 제외한 장면의 카메라의 백분율이 성공적으로 등록됨에따라 임게값을 설정, 해당 장면의 mAA는 평균을 통해 계산한다.
데이터 세트 설명
주변에서 촬영된 구조화되지 않은 이미지 모음을 바탕으로 장면의 3D 모델을 구축하는 것은 컴퓨터 비전 연구에서 오랫동안 해결되지 않은 문제입니다. 이 대회의 과제는 다양한 유형의 장면을 보여주는 이미지 세트에서 3D 재구성을 생성하고 해당 이미지의 위치를 정확하게 지정하는 것입니다.
이 대회는 숨겨진 테스트를 사용합니다. 제출한 노트북이 채점되면 실제 테스트 데이터(샘플 제출 포함)가 노트북에 제공됩니다. 숨겨진 테스트 세트에서 약 1,000개의 이미지를 찾을 수 있을 것으로 예상됩니다.
파일
Sample_submission.csv 다음 필드가 포함된 무작위로 생성된 유효한 샘플 제출입니다.
image_path: 경로를 포함한 이미지 파일 이름입니다.
dataset: 데이터세트의 고유 식별자입니다.
scene: 장면의 고유 식별자입니다.
rotation_matrix;: 첫 번째 대상 열. 3x3 행렬, 행 우선 규칙에 따라 벡터로 평면화, 값은 . 로 구분됨.
translation_vector;: 두 번째 대상 열. 값이 . 로 구분된 3차원 벡터입니다 .
[train/test]/*/images 동일한 위치 근처에서 촬영된 이미지 배치입니다. 일부 교육 데이터 세트에는 추가 이미지가 포함 된 Images_full 이라는 폴더가 포함될 수도 있습니다. 게시된 테스트 폴더는 church기차 장면의 하위 집합으로 구성되며 예시 목적으로만 제공됩니다. 훈련 데이터는 일반적으로 순차적 캡처 순서와 상당한 이미지 대 이미지 콘텐츠 중첩을 갖는 반면, 테스트 세트는 이미지 대 이미지 중첩이 제한적이고 이미지 순서는 무작위입니다.
train/*/sfm 이번 대회와 함께 번들로 제공되는 모션의 3D 구조 라이브러리인 colmap을 사용하여 열 수 있는 이 이미지 배치에 대한 3D 재구성입니다 .
train/*/LICENSE.txt 이 데이터 세트의 라이센스입니다.
train/train_labels.csv 실제 데이터와 함께 이러한 데이터세트의 이미지 목록입니다.
dataset: 데이터세트의 고유 식별자입니다.
scene: 장면의 고유 식별자입니다.
image_path: 경로를 포함한 이미지 파일 이름입니다.
rotation_matrix;: 첫 번째 대상 열. 3x3 행렬, 행 우선 규칙에 따라 벡터로 평면화, 값은 . 로 구분됨.
translation_vector;: 두 번째 대상 열. 값이 . 로 구분된 3차원 벡터입니다 .
참고한 코드:
활용한 모델에 대하여:
aliked-lightglue-example.ipynb
코드 따라해보기: https://www.kaggle.com/code/badaju/fork-of-imc2024-1st-place-solution
배운 점:
co-orientation model
조직의 정의 및 평가
###활용한 모델
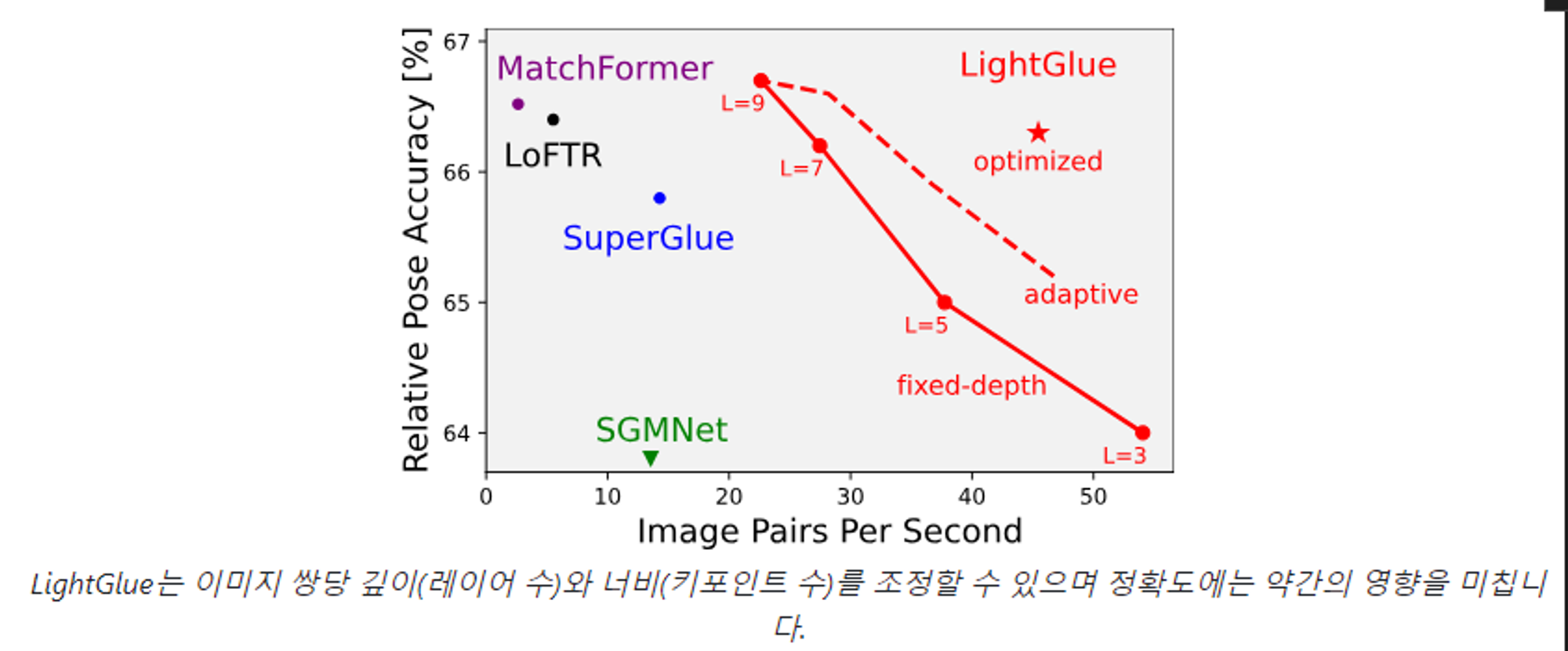
LightGlue(Local Feature Matching at Light Speed)
높은 정확도와 초고속 추론을 제공하는 light feature matcher이다.
The Architecture 의 각 이미지에 대한 키포인트와 설명자(descriptors)를 입력받고 ,
해당 포인트의 인덱스를 반환한다.

#kaggle/docer-python 의 환경 라이브러리 설정이 필요하다
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
!mkdir -p ~/.cache/torch/hub/checkpoints
!cp /kaggle/input/aliked/pytorch/aliked-n16/1/* ~/.cache/torch/hub/checkpoints
!cp /kaggle/input/lightglue/pytorch/aliked/1/aliked_lightglue.pth ~/.cache/torch/hub/checkpoints/aliked_lightglue_v0-1_arxiv.pth/%%capture
!wget https://github.com/kornia/data/raw/main/matching/kn_church-2.jpg
!wget https://github.com/kornia/data/raw/main/matching/kn_church-8.jpg/c#Detect ALIKED features and match them
import cv2 #opencv2 library(이미지 불러오기 위한 목적)
import torch #pytorch 로 오픈소스 머신 러닝 라이브러리
from lightglue import match_pair #lightglue 모델
from lightglue import ALIKED, LightGlue
from lightglue.utils import load_image, rbd
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
extractor = ALIKED(max_num_keypoints=4096, detection_threshold=0.01).eval().to(device)
matcher = LightGlue(features='aliked').eval().to(device) # load the matcher
image0 = load_image('kn_church-2.jpg').to(device)
image1 = load_image('kn_church-8.jpg').to(device)
with torch.inference_mode():
feats0, feats1, matches01 = match_pair(extractor, matcher, image0, image1)from lightglue.utils import load_image, rbd
from lightglue import viz2d
kpts0, kpts1, matches = feats0["keypoints"], feats1["keypoints"], matches01["matches"]
m_kpts0, m_kpts1 = kpts0[matches[..., 0]], kpts1[matches[..., 1]]
axes = viz2d.plot_images([image0, image1])
viz2d.plot_matches(m_kpts0, m_kpts1, color="lime", lw=0.2)
viz2d.add_text(0, f'Stop after {matches01["stop"]} layers', fs=20)
kpc0, kpc1 = viz2d.cm_prune(matches01["prune0"]), viz2d.cm_prune(matches01["prune1"])
viz2d.plot_images([image0, image1])
viz2d.plot_keypoints([kpts0, kpts1], colors=[kpc0, kpc1], ps=10)LightGlue: Local Feature Matching at Light Speed (ICCV 2023)
- 문제상황: 두 이미지에서 추출된 로컬 특징들 간의 부분 할당을 예측
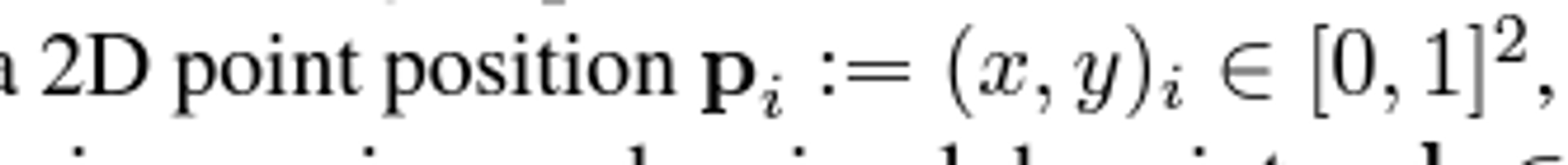
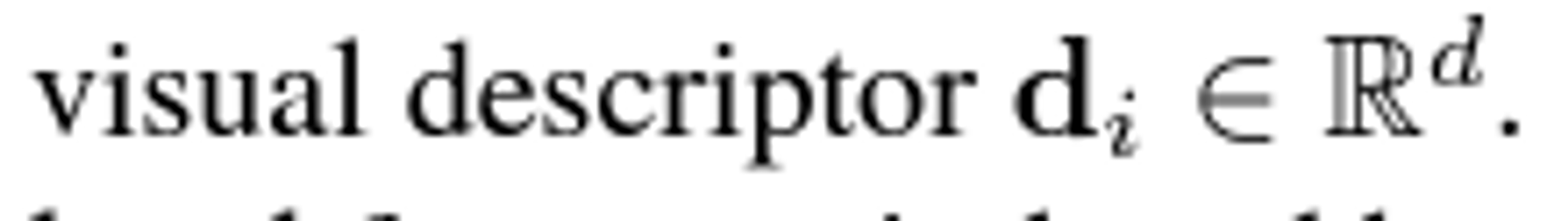
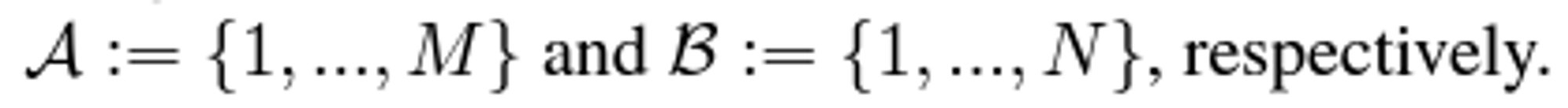
두 이미지의 로컬 특징들 간의 일치 세트(외적을 통해서 두 이미지간의 시야각이 얼마인지 구할수 있다. )
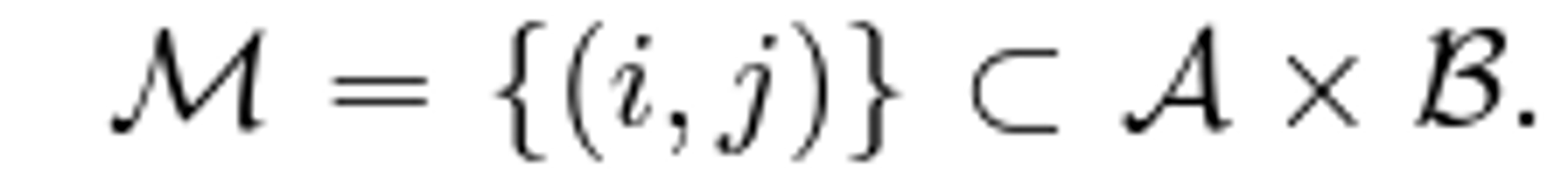

each image pulls information from the other image and S = {A,B}\I.


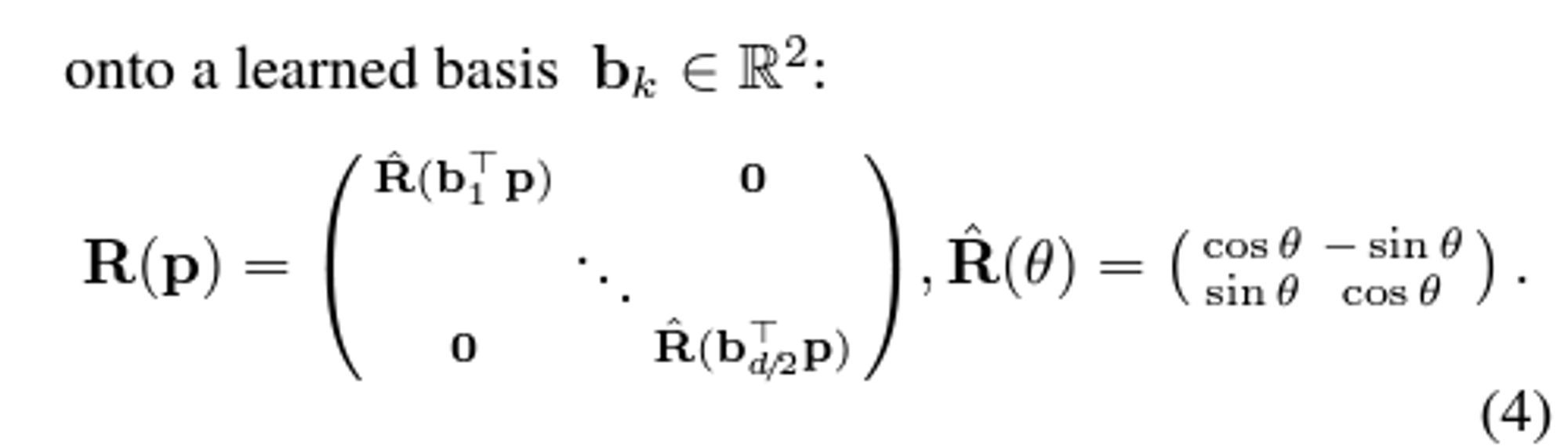
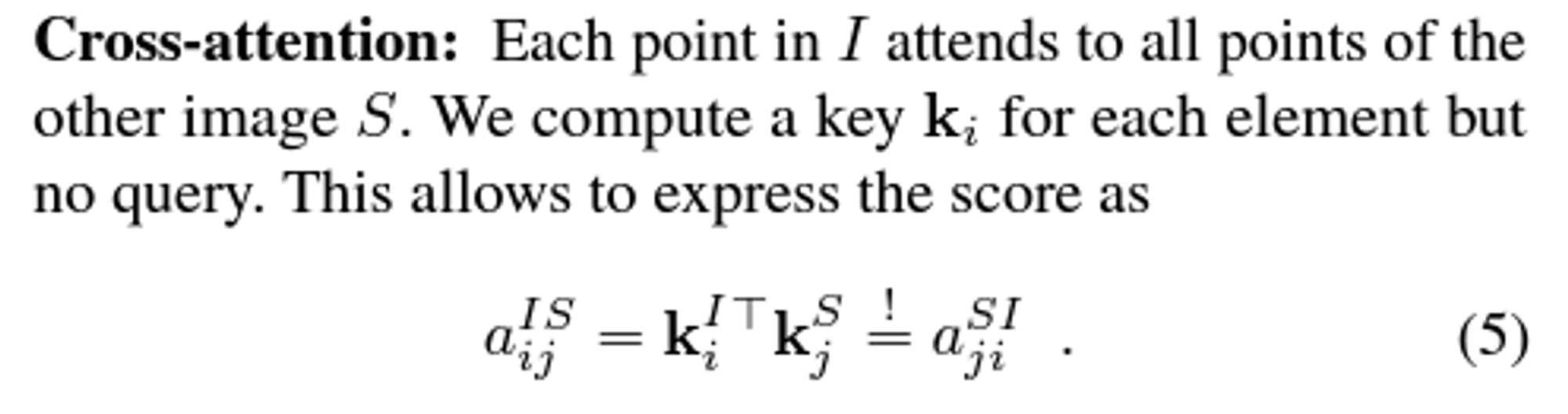

2D projections of the same 3D points.
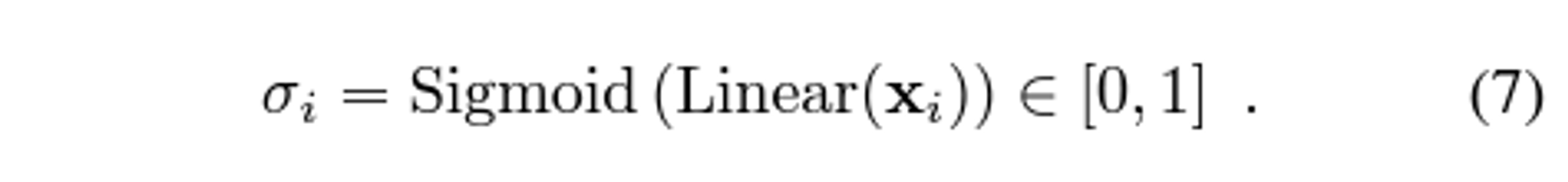

confidence classifier: the backbone of light glue auguments inpuut visual discription
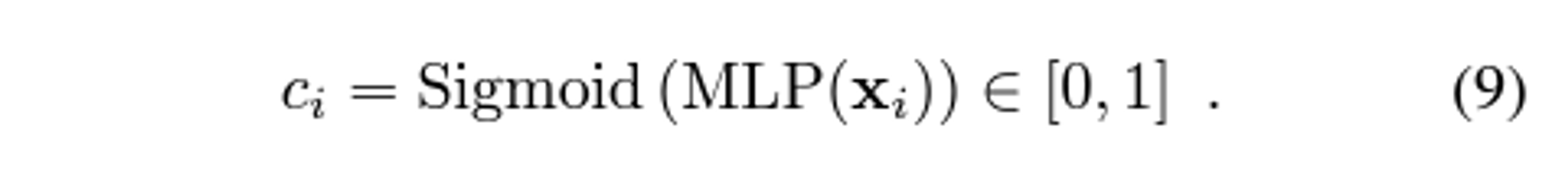

-
point pruning
-
Supervision(이해 못함)

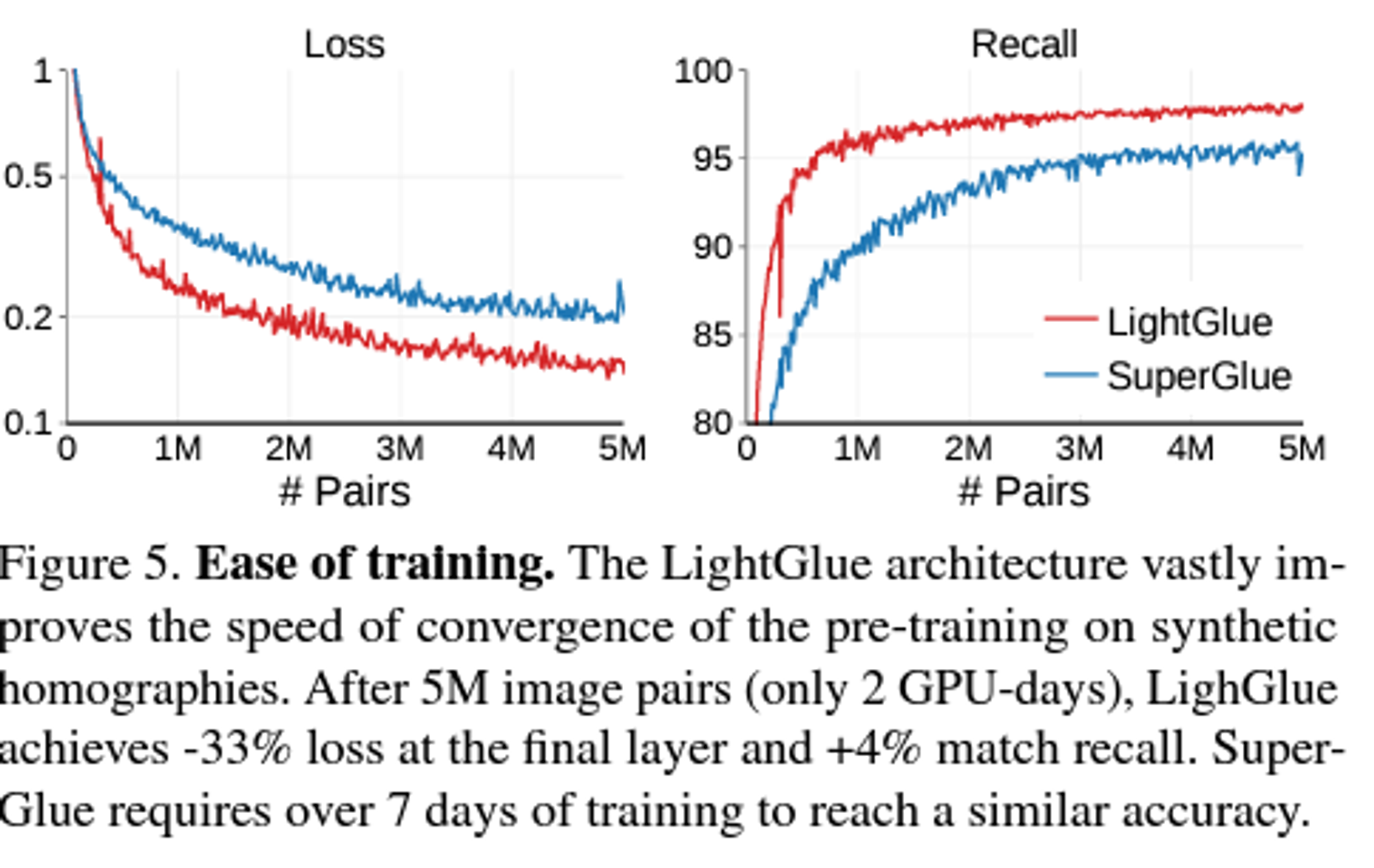
LIght Glue 모델의 원리
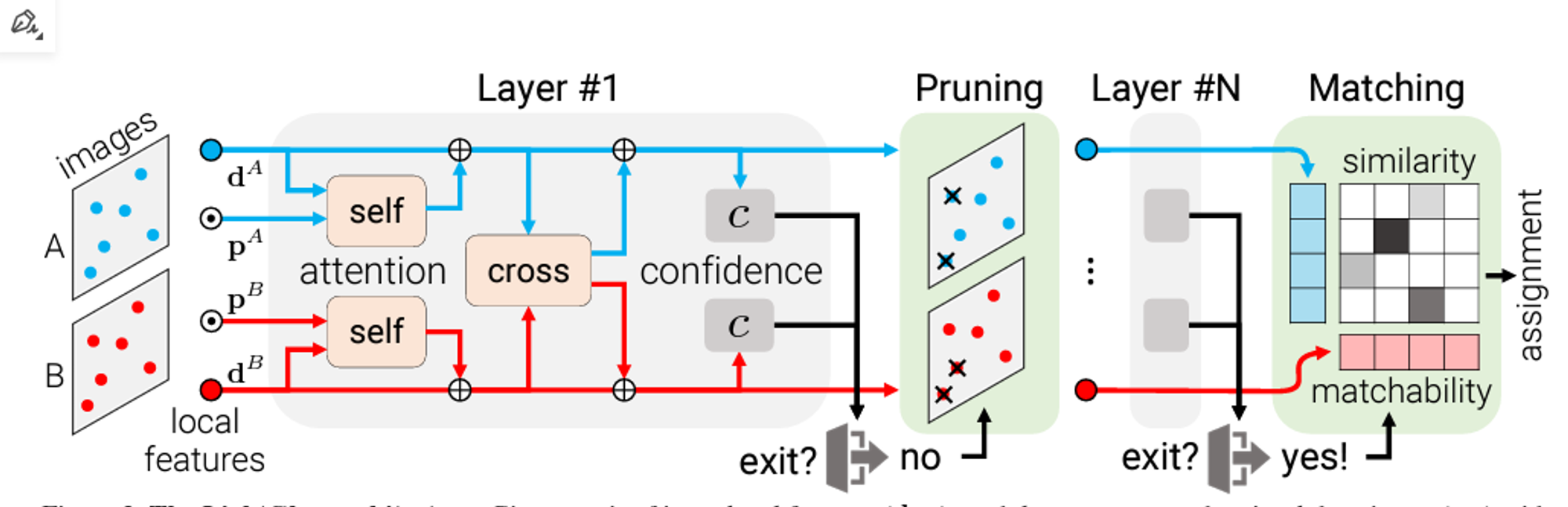
ex

- Homography estimation on HPatches
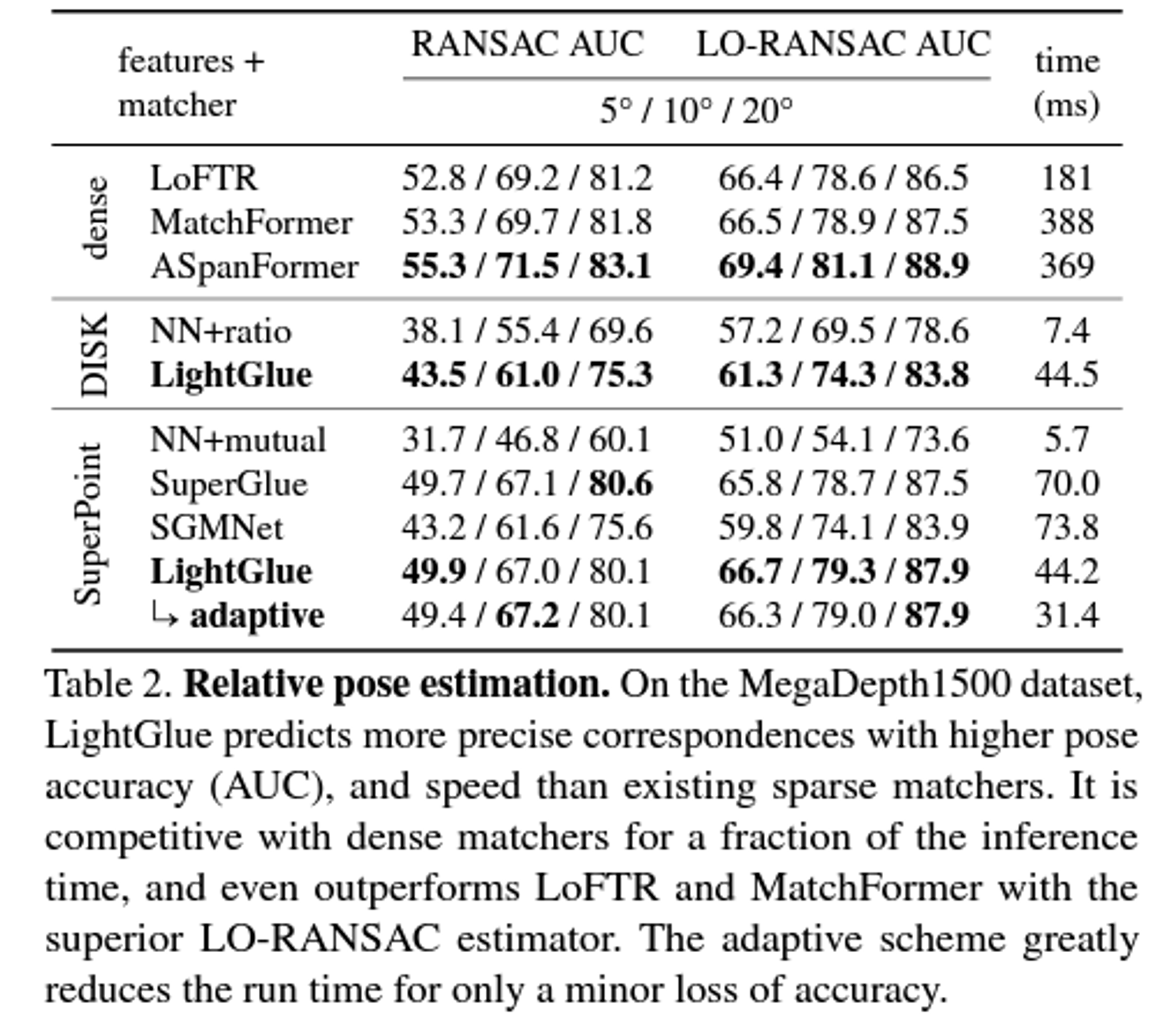
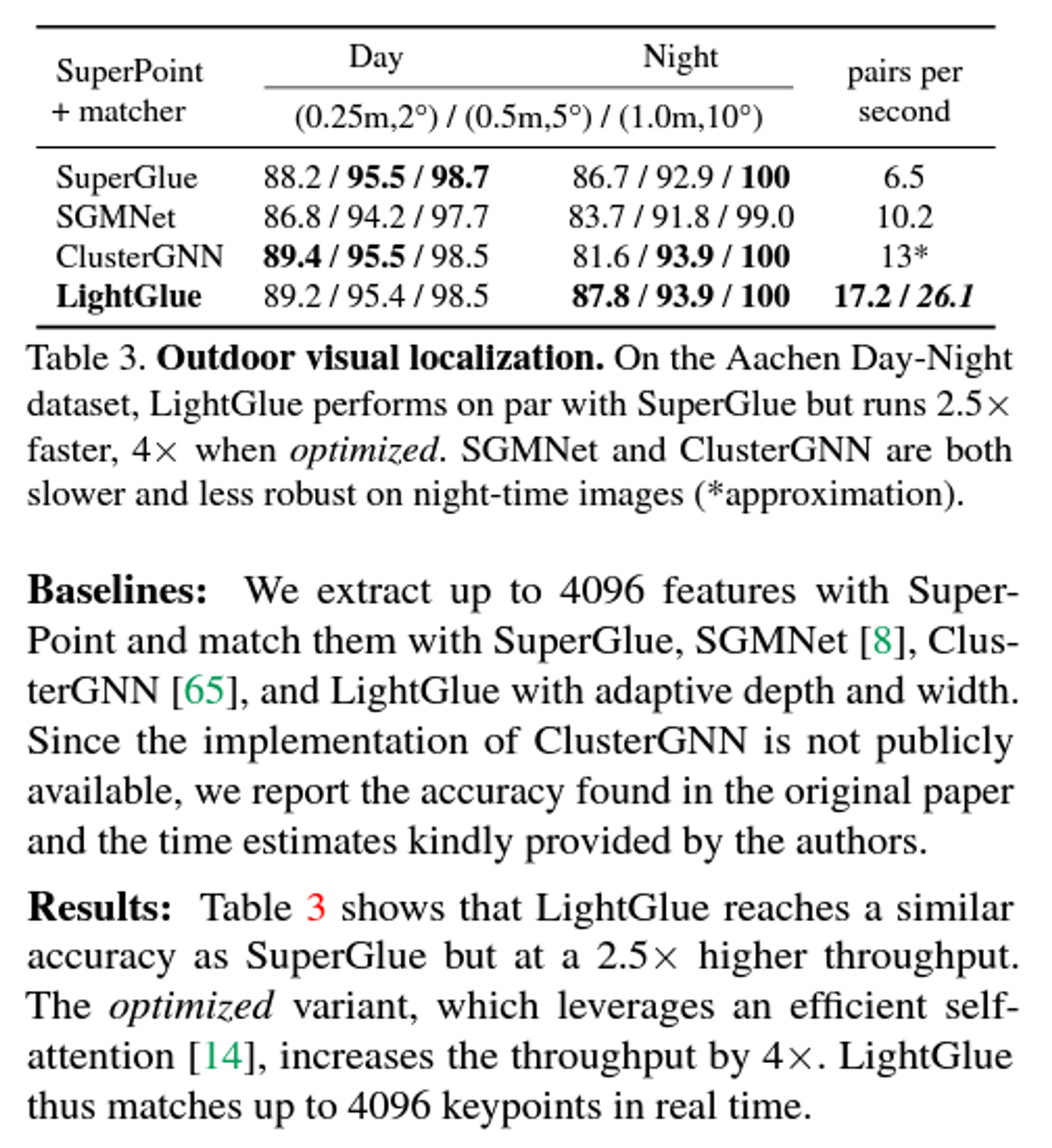
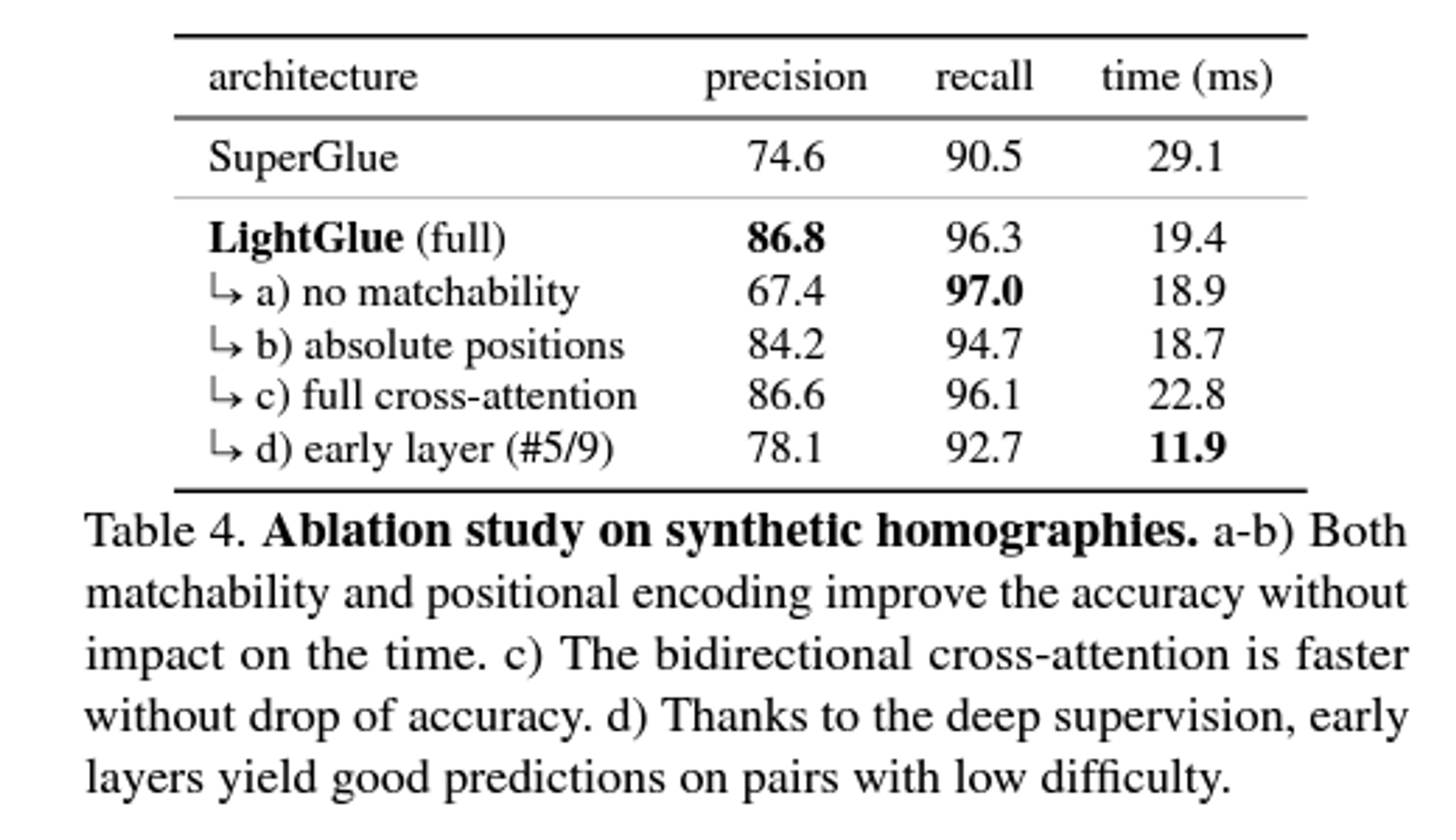
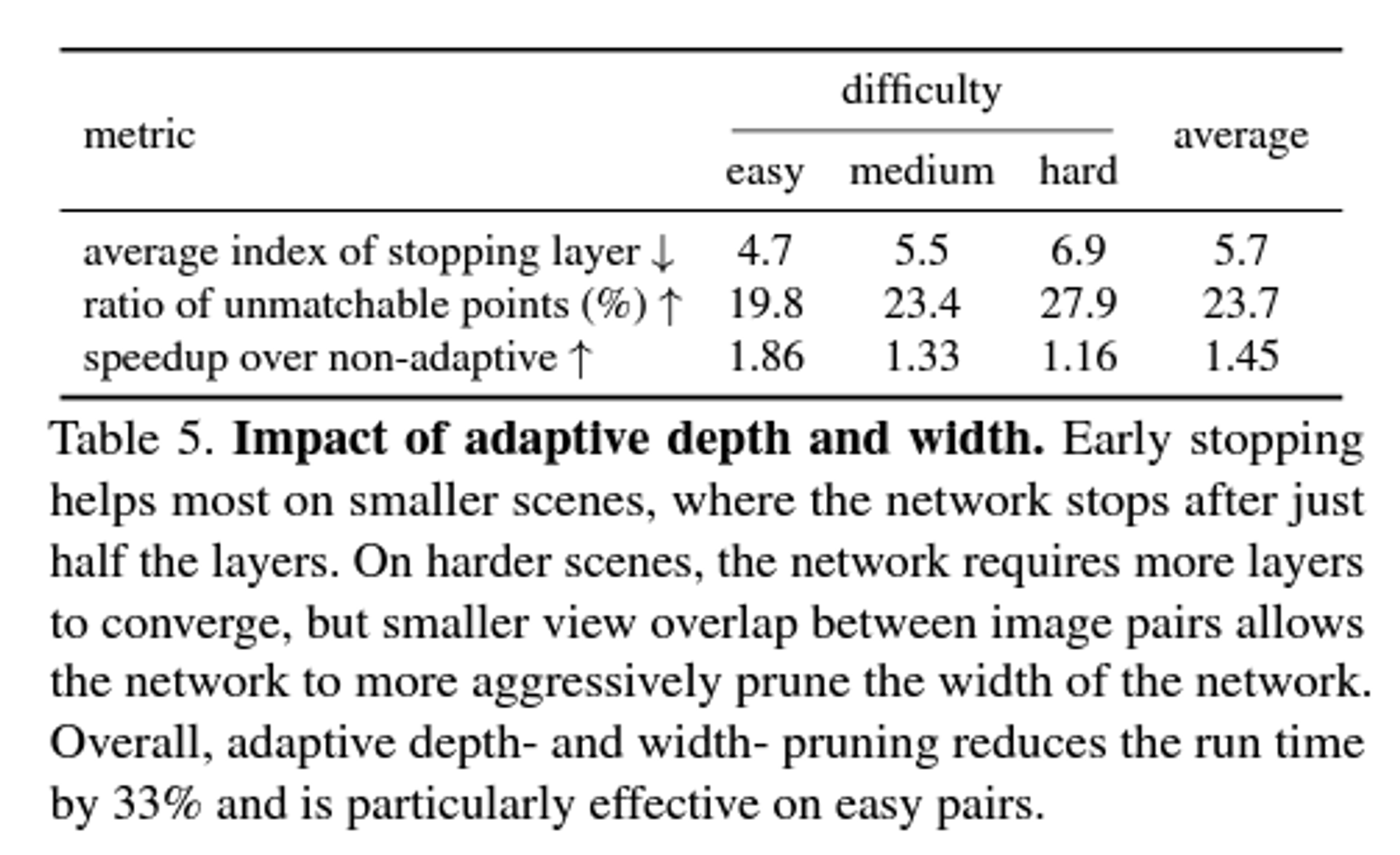
Matchability 라는 보정 알고리즘을 통해 outliers 를 inlier 로 모은다.(clustering)

key point 의 갯수와 run time 의 상관관계
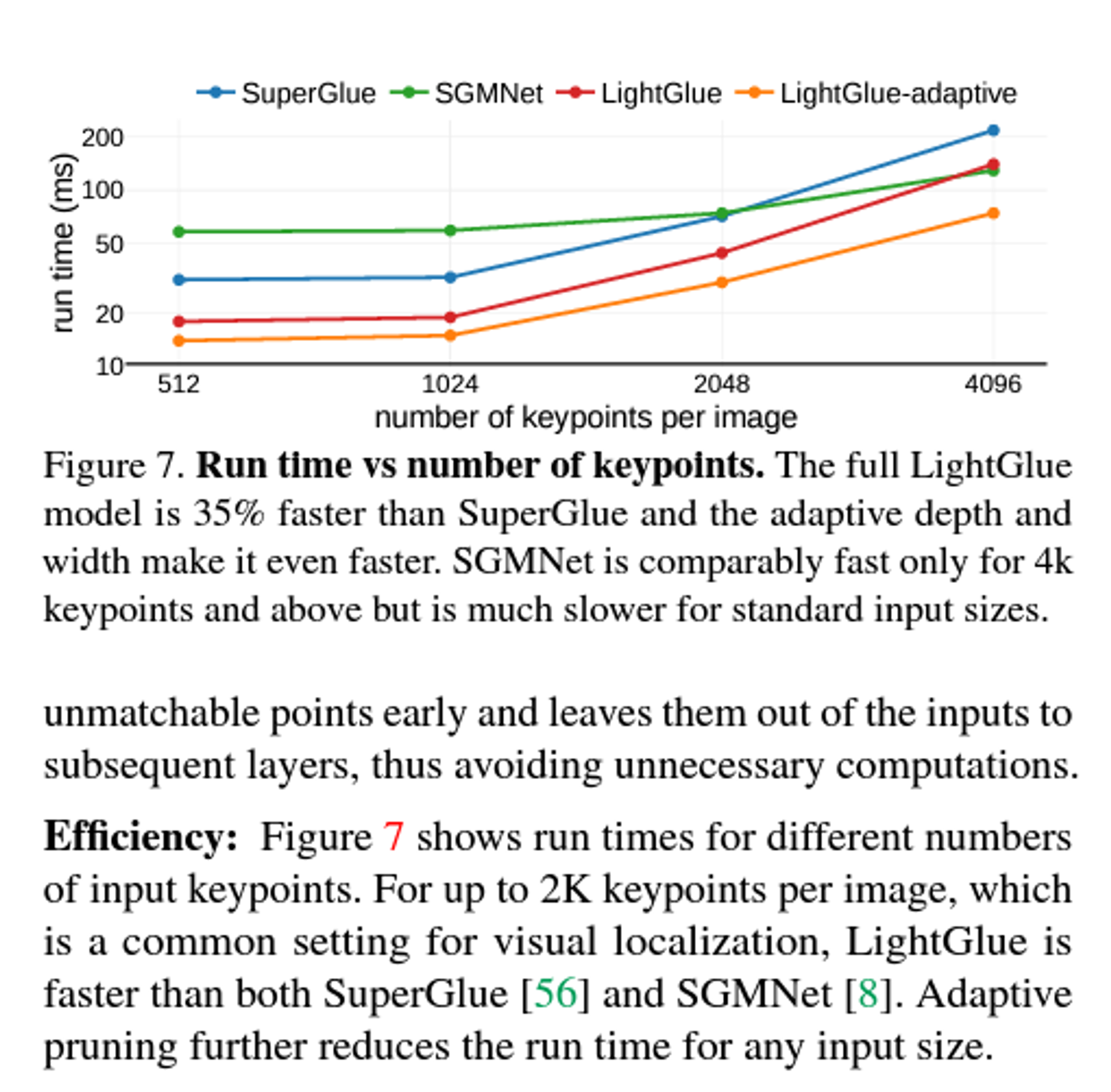
실내와 실외/랜드마크 등의 matches를 비교한 사례



ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
딥 뉴럴 네트워크는 키포인트 및 디스크립터 추출 성능을 개선하는 데 널리 사용>>기존의 컨볼루션 연산은 디스크립터에 필요한 기하학적 불변성을 제공하지 못함
Aliked 모델은 Alike 모델을 개선한 것으로, 변형 가능한 디스크립터를 효율적으로 추출하기 위해 Sparse Deformable Descriptor Head(SDDH)를 도입(서포팅 피처의 변형 가능한 위치를 학습하고 변형 가능한 디스크립터를 구성)
조밀한 디스크립터 맵 대신 희소한 키포인트에서 디스크립터를 추출하여 효율적이고 표현력이 뛰어난 디스크립터를 추출
Neural Reprojection Error(NRE) 손실을 조밀한 디스크립터 맵에서 희소한 디스크립터로 완화하여 희소한 디스크립터를 학습할 수 있게 함
실험 결과 제안된 네트워크는 이미지 매칭, 3D 재구성, 비주얼 재현 위치 측정 등 다양한 비주얼 메저먼트 작업에서 효율적이고 강력한 성능
- 기학학적 불변 디스크립터 추출(Geometric Invariant Descriptor Extraction)
- 스케일 불변성:
- 방향 불변성:
- SIFT는 스케일 공간에서 검출된 키포인트의 스케일을 추정함. 그리고 각 검출된 키포인트의 방향을 계산 추청된 스케일과 방향을 사용하여 이미지 패치를 추출/ 이를 기반으로 디스크립터를 생성
- ORB는 효율성을 위해 키포인트의 질량 중심에서 방향을 추출/ 이미지 패치를 회전시켜 방향 불변성을 달성
학습 방법
패치 기반 디스크립터 추출 방법: 데이터 증강을 통해 스케일 및 방향 불변성을 달성
키포인트 및 디스크립터 학습 방법: 키포인트의 방향과 스케일을 명시적으로 모델링
LIFT: SIFT를 모방하여 키포인트를 검출하고, 키포인트의 방향과 스케일을 추정한 후, 다른 신경망으로 디스크립터를 추출
`AffNet, UCN, LF-Net: **STN**을 사용하여 이미지 특징에 애피인 변환을 적용하여 불변 디스크립터를 추출 **GIFT:**다양한 스케일과 방향의 이미지 그룹을 생성한 후, 이러한 이미지에서 특징을 추출하여 불변 디스크립터를 생성 **HDD-Net:`** 특징을 회전시키는 대신 컨볼루션 커널을 회전시켜 방향 불변 디스크립터를 추출
제안된 **ALIKED** 네트워크는 ASLFeat에서 영감을 받아 DCN을 사용하여 기하학적 불변 특징을 추출합니다. 또한, SDDH 모듈을 설계하여 효율적으로 기하학적 불변 디스크립터를 추출
- 키포인트 및 디스크립터 학습 (Joint Keypoint and Descriptor Learning)
- 변형 가능한 컨볼루션 (Joint Keypoint and Descriptor Learning)
키포인트 및 디스크립터 학습
공동으로 추정하고, 점수 맵에서 키포인트를 검출하며, 디스크립터 맵에서 디스크립터를 샘플링하는 방법을 제안
그외의 방법들,
SuperPoint : 호모그래피 이미지 쌍을 사용하여 학습된 경량 네트워크를 제안
2D2 : 키포인트 검출을 위해 반복성과 신뢰성 맵을 계산하며, AP 손실로 디스크립터를 학습
DISK:강화 학습을 사용하여 점수 맵과 디스크립터 맵을 학습
ALIKE :정확한 키포인트 학습을 위한 차별화 가능한 키포인트 검출 모듈을 포함하고, 실시간 비주얼 메저먼트 애플리케이션에 적용할 수 있는 가장 가벼운 네트워크를 제공
D2-Net:네트워크를 사용하여 점수 맵을 추정하지 않고, 특징 맵에서 키포인트를 채널 및 공간 최대값을 사용하여 검출 그러나 저해상도 특징 맵에서 키포인트를 추출하기 때문에 위치 정확도가 떨어짐
ASLFeat:다중 레벨 특징을 사용하여 키포인트를 검출/ 변형 가능한 컨볼루션으로 지역 형상을 모델링하여 위치 정확도와 디스크립터를 개선
`D2D,D2-Net:`영감을 받아 특징 맵에서 절대적 및 상대적 중요도를 사용하여 키포인트를 검출

변형 가능한 컨볼루션
기존 CNN은 고정된 컨볼루션 커널을 사용하여 장거리 정보를 활용하는 데 한계
변형 가능한 컨볼루션은 학습 가능한 오프셋을 컨볼루션 커널에 도입
(객체 검출, 의미론적 분할, 동작 인식, 인간 포즈 추정과 같은 고수준 작업에서 효과적이다.)
DCN ASLFeat에서도 디스크립터 추출을 위해 사용
SDDH ASLFeat는 DCN을 사용하여 조밀한 특징을 계산
비전 트랜스포머가 뛰어난 성능으로 주목받고 있지만, 높은 계산 부담
이를 해결하기 위해, 변형 가능한 DETR 모델은 작은 샘플 위치 집합에 주목하도록 제안
최근에 InternImage는 DCNv3를 도입하여 비전 트랜스포머의 계산 부담을 줄임
기본 비전 작업에서 최첨단 성능을 달성/ 우리의 접근법도 유사한 철학을 따르며, 희소한 키포인트에서만 디스크립터를 계산하여 계산 효율성과 성능을 향상

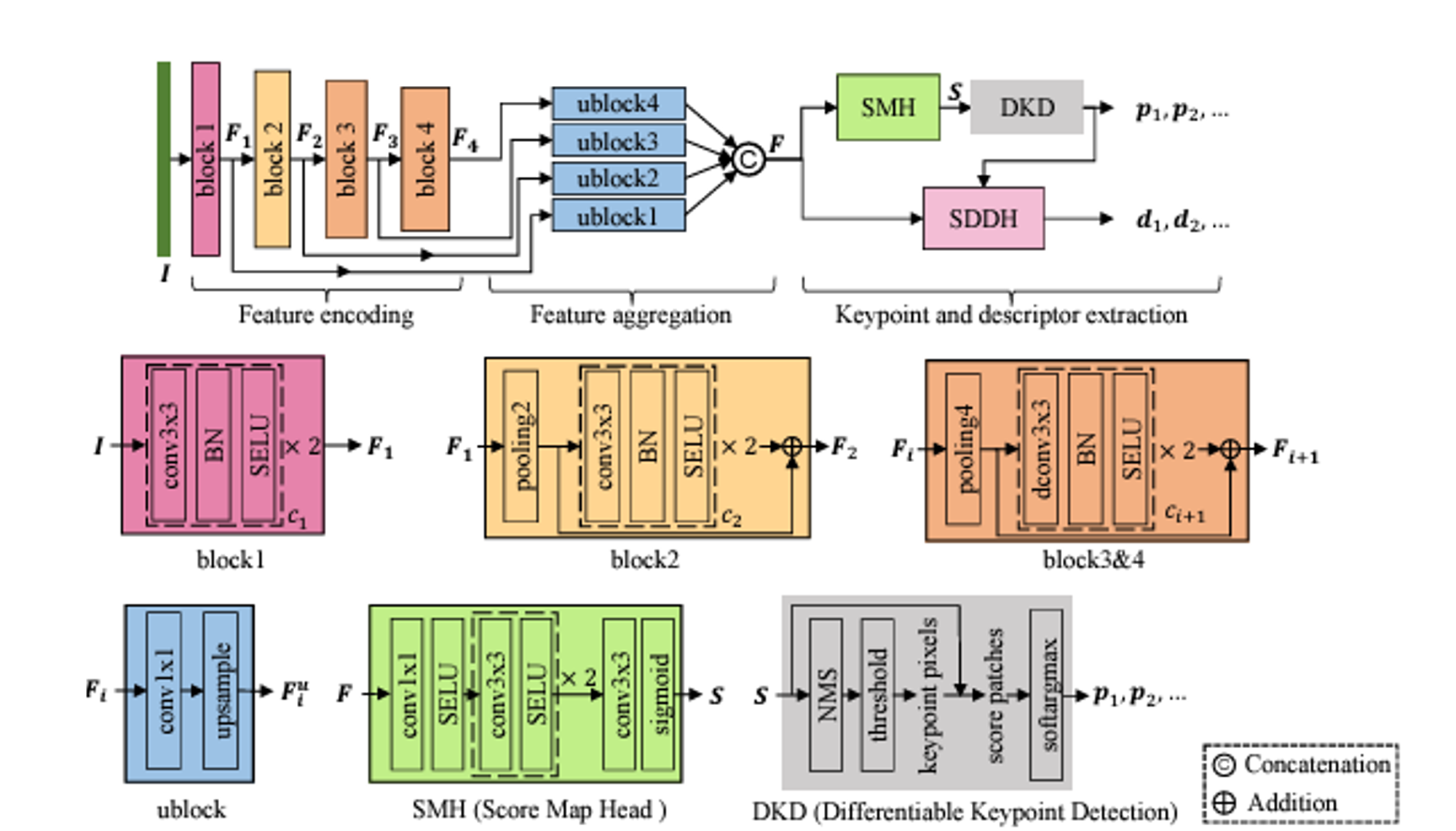
ALIKED의 네트워크 아키텍처
A. 특징 인코딩 (Feature Encoding)
입력 이미지
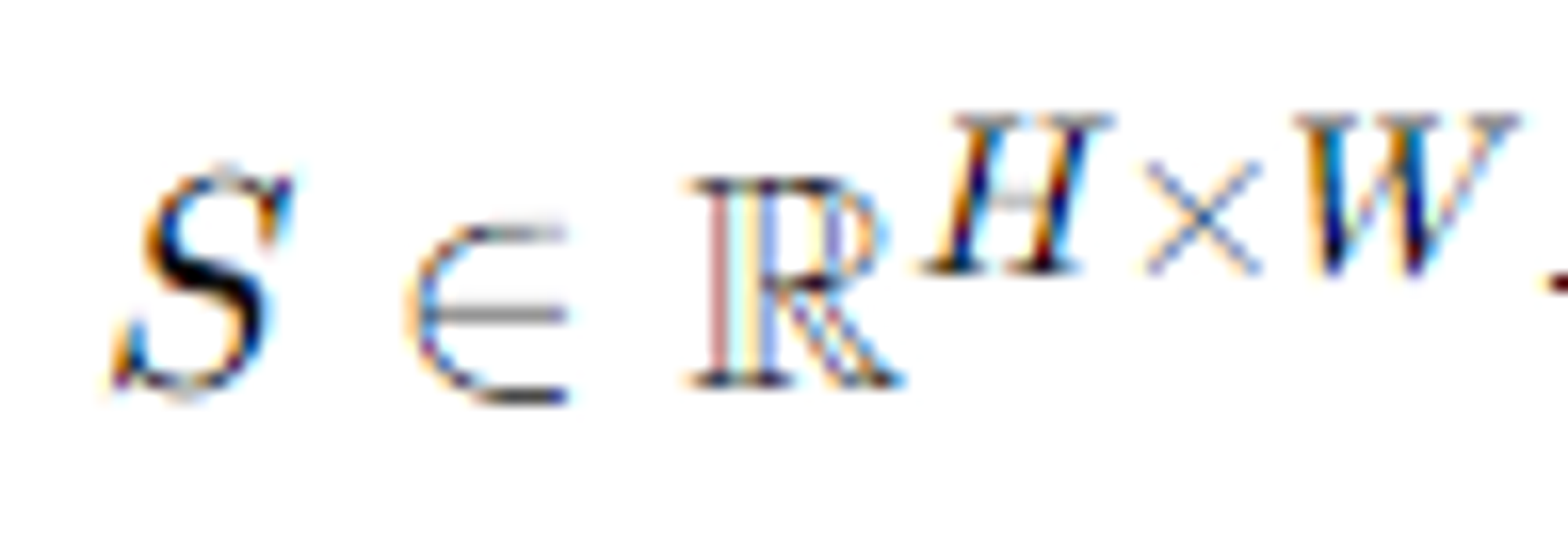
네 가지 인코딩 블록을 사용하여 다중 스케일 특징 F1, F2,F3, F4 로 변환한다.
각 인코딩 블록은 채널 수 C1~C4까지 다양한 채널 범위를 가지며
첫 번째 블록: 저수준 이미지 특징 F1를 추출하는 두 개의 컨볼루션
두 번째 블록: 2×2 평균 풀링을 사용하여 F1을 다운샘플링하여 더 큰 수용 영역을 커버하고 계산 효율성을 증가
세 번째 및 네 번째 블록: 4×4 평균 풀링을 사용하여 특징을 다운샘플링한 후 3×3 변형 가능한 컨볼루션(DCN)을 사용하여 이미지 특징을 추출
B. 특징 집계 (Feature Aggregation)
다중 스케일 특징 F1,F2,F3,F4 결합하여 키포인트 및 디스크립터 추출에 필요한 종합적인 특징 F를 생성 (4 개의 업샘플 블록(ublock)를 사용하며 각 Ublock 은 1*1 컨볼루션고 ㅏ업샘플 레이어로 구성 )
C. 키포인트 및 디스크립터 추출 (Differentiable Keypoint Detection)
Score Map Head (SMH): SMH는 종합적인 특징 F를 사용하여 점수 맵 S∈RH×W를 추정
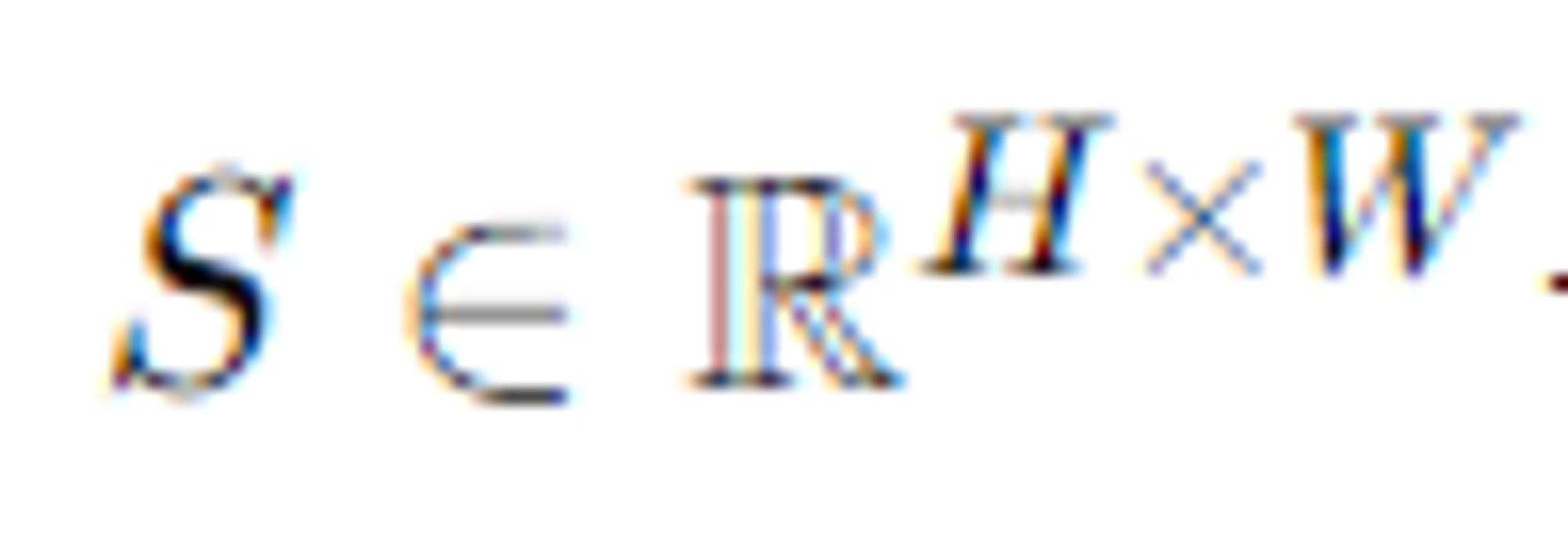
1×1 컨볼루션 레이어로 채널 수를 8로 줄인 후, 두 개의 3×3 컨볼루션 레이어를 사용하여 특징을 인코딩합니다. 마지막으로, 3×3 컨볼루션 레이어와 시그모이드 활성화 레이어를 사용하여 점수 맵 S를 얻는다.
Differentiable Keypoint Detection (DKD) :
DKD 모듈은 점수 맵 S에 비최대 억제(NMS)를 적용하여 로컬 최대값을 식별 그런 다음, 로컬 최대값 점수에 대한 임계값을 설정하여 픽셀 수준의 키포인트를 결정. DKD 모듈은 소프트아그맥스(softargmax)를 사용하여 위치를 정제하여 차별화 가능한 서브픽셀 키포인트를 추출.
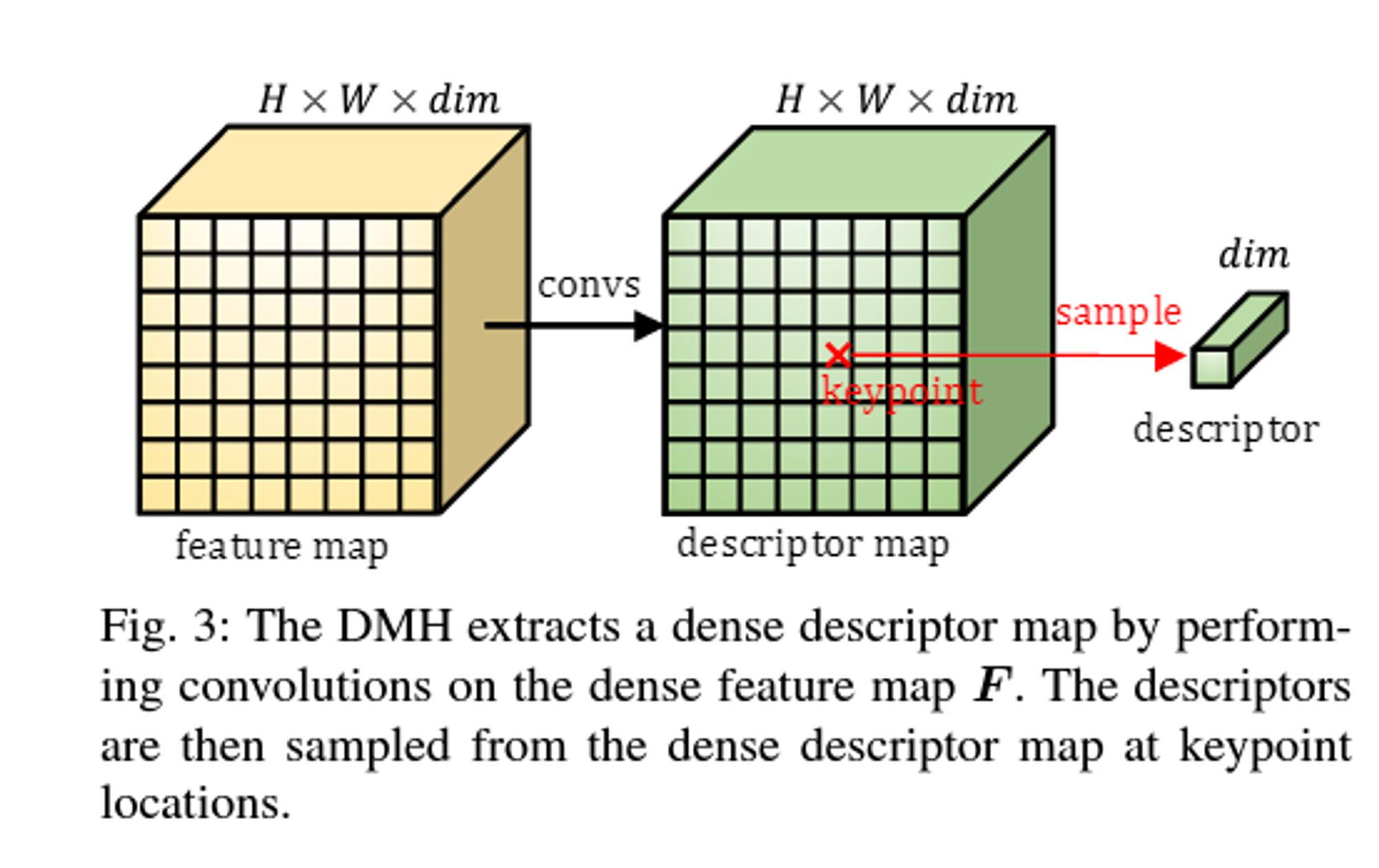
(feature map 과 descriptor map 의 차이? )
D. Sparse Deformable Descriptor Head (SDDH)
SDDH는 희소한 키포인트에서 변형 가능한 디스크립터를 추출
- 변형 가능 불변 디스크립터 모델링: SDDH는 키포인트의 위치에서 K×K 크기의 특징 패치를 추출하고, 변형 가능한 샘플 위치를 추정
- 변형 가능한 샘플 위치 추정: 변형 가능한 샘플 위치 ps를 추정하고, 이를 기반으로 특징 맵에서 지원 특징을 샘플링
- 디스크립터 추출: 추출된 지원 특징을 사용하여 디스크립터 d를 계산
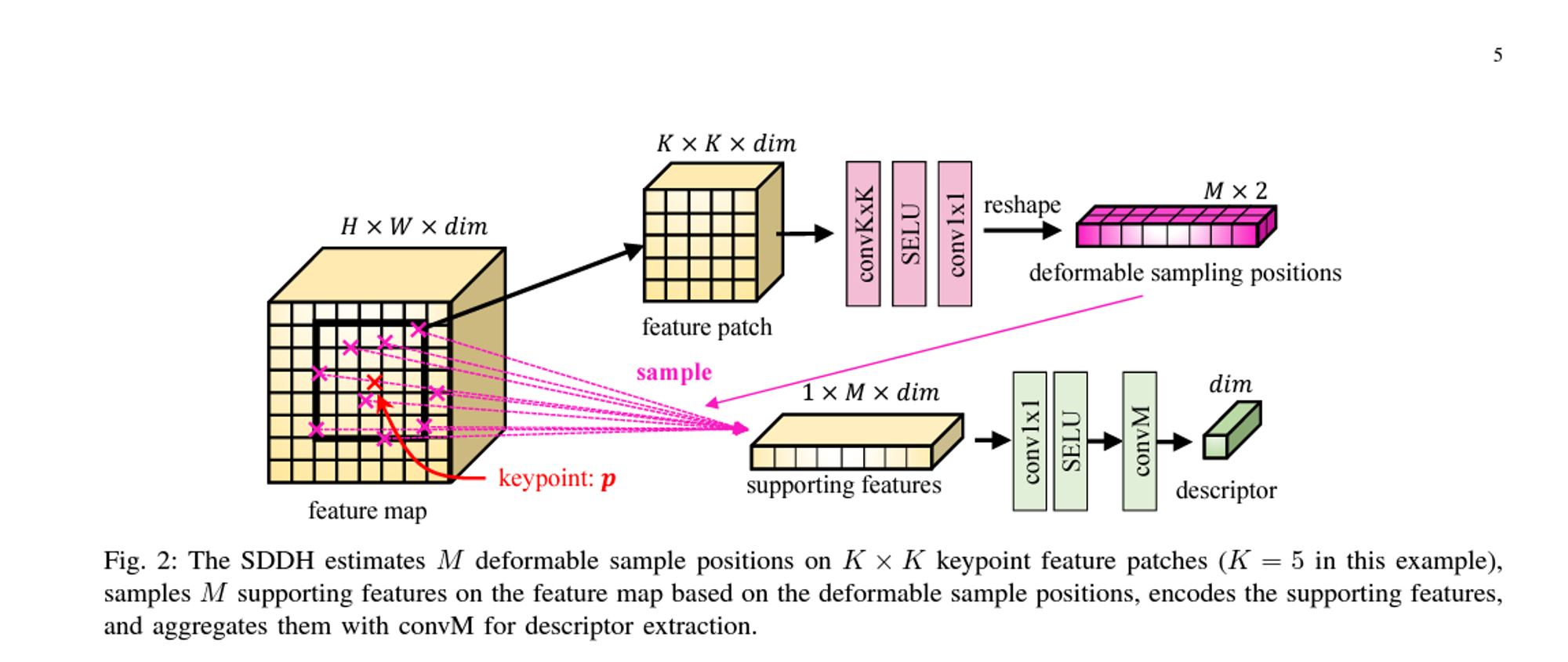
loss function
- Reprojection Loss (사영 오차 )
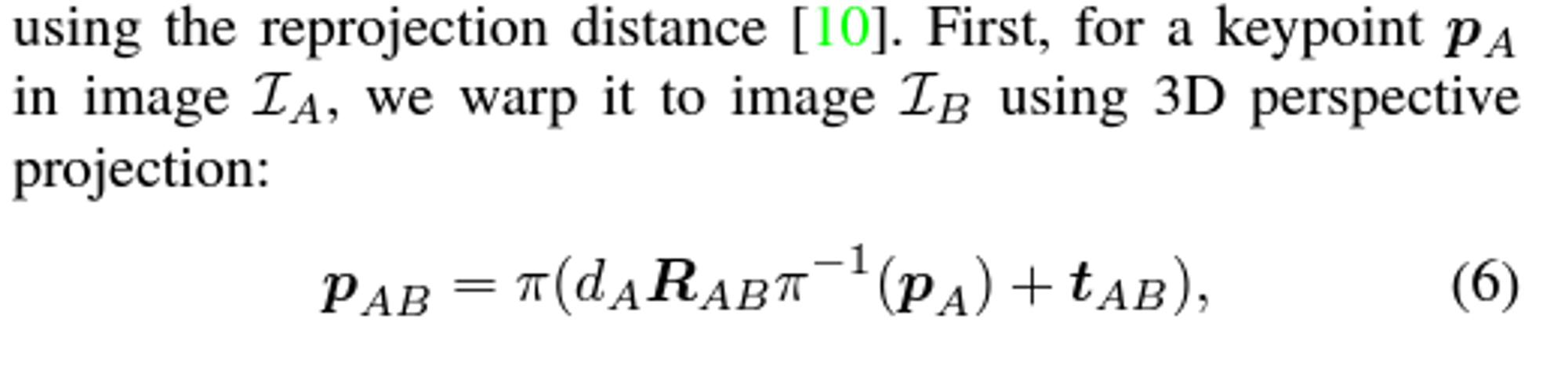
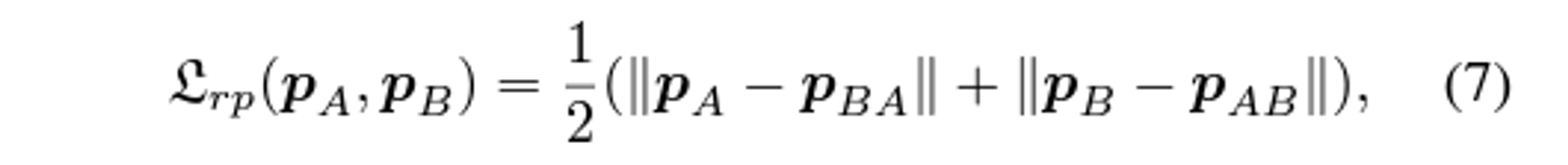
-
Dispersity Peak Loss (분산성 피크 오차)
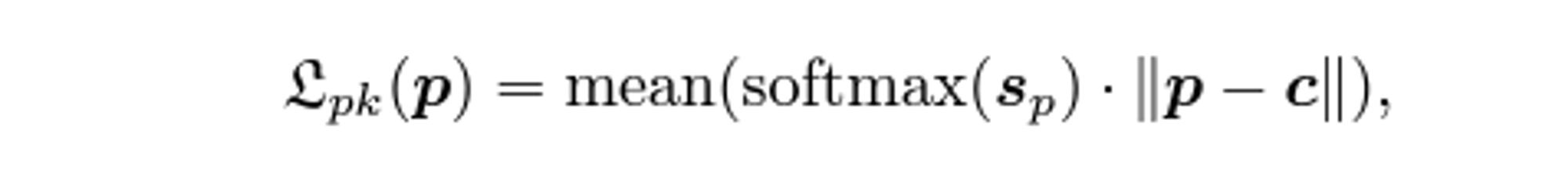
-
sparse neural reprojection error loss

-
Reliable Loss
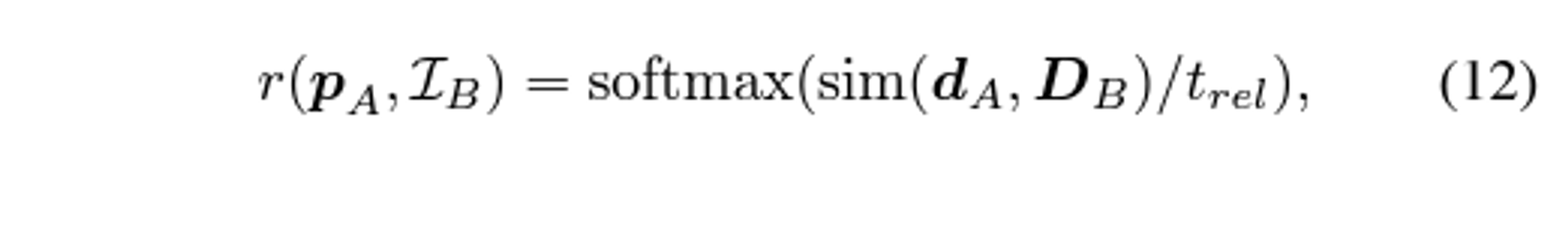
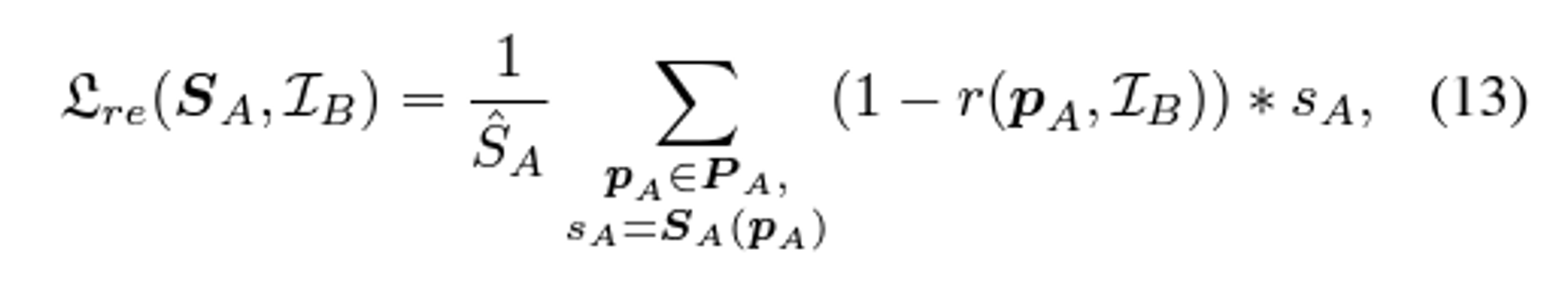
-
Overall Loss
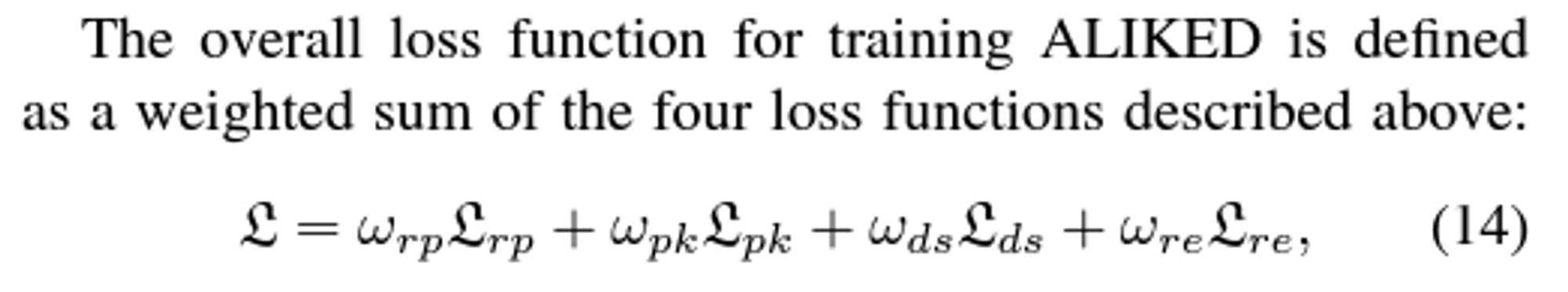
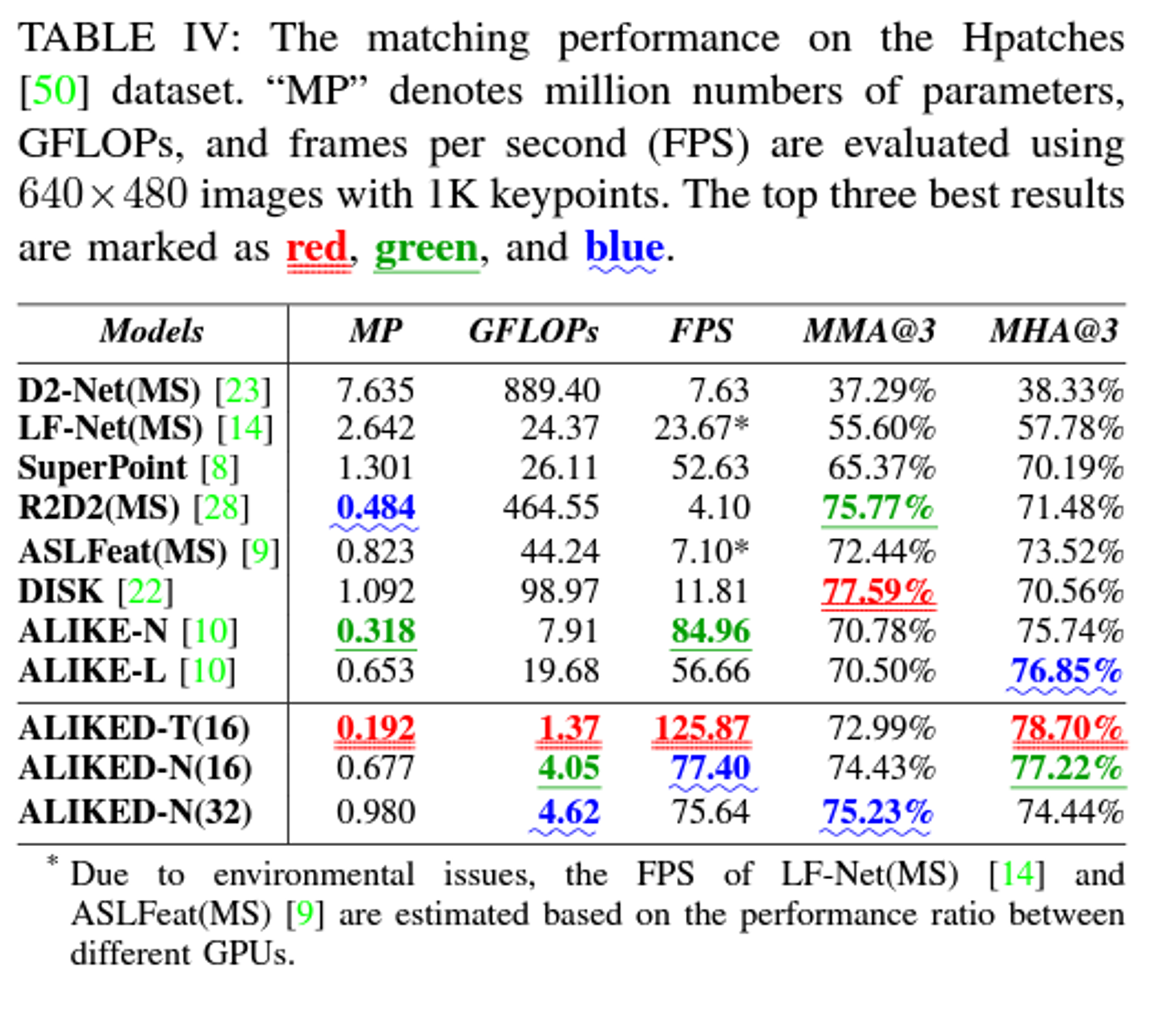
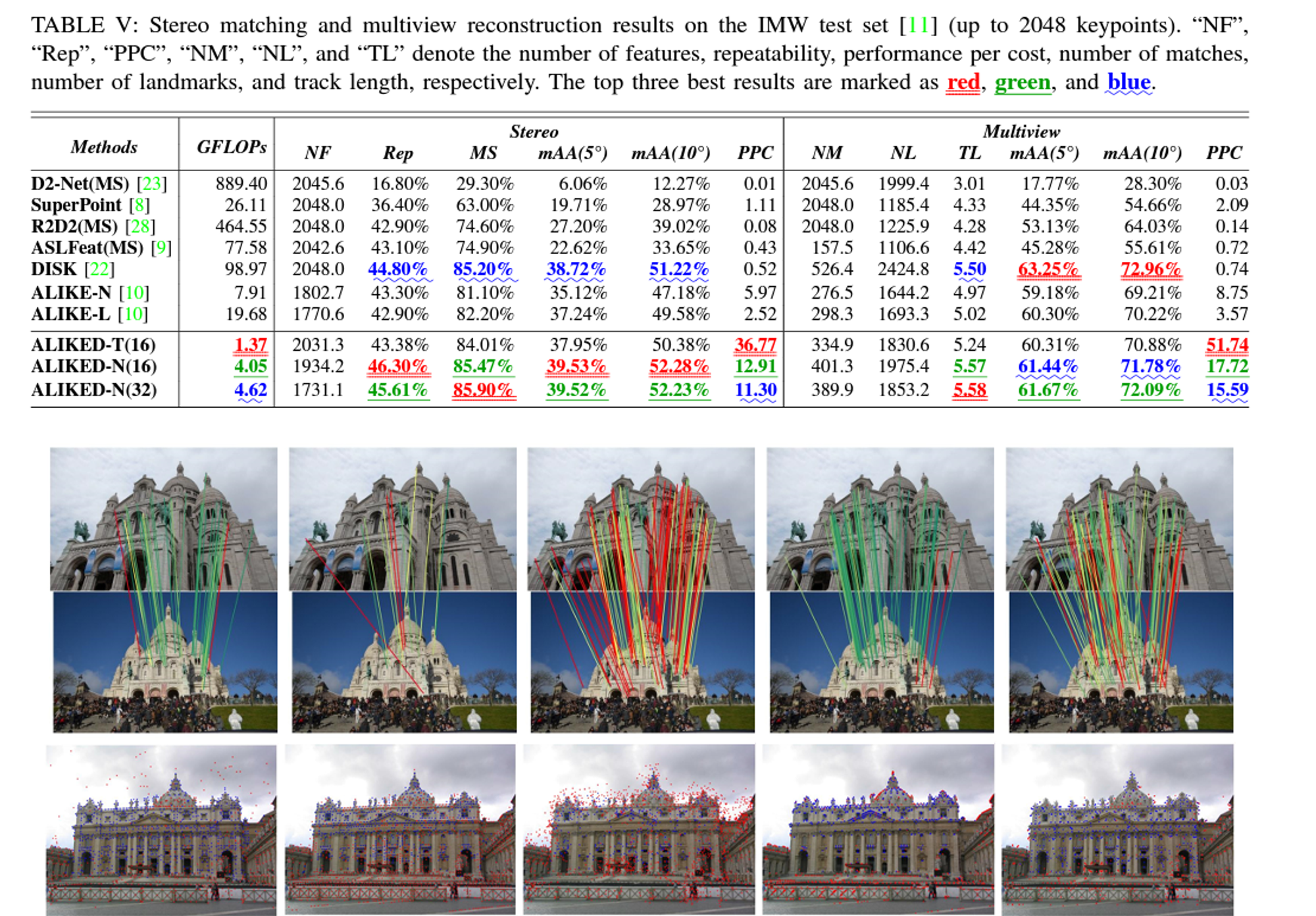
Experiments

엮어진 abbreviation
추가:
- Ray-tracing algorithms

{kind=link}
저도 작년에 이 분야 되게 흥미롭게 봤었는데ㅎㅎ 성은님 리뷰 보니까 더 이해가 잘 되네용~!! 굿굿!!