Siamese CBOW: Optimizing Word Embeddings for Sentence Representations
‘siamese’ 의미
쌍둥이 신경망(Siamese Neural Network) 구조를 사용하기 때문에 이름을 따온 것. 쌍둥이 신경망은 두개의 동일한 신경망을 사용여 입력 쌍의 유사도를 학습&예측한다.
Abstract
Siamese CBOW(Continuous Bag of Words)는 고품질의 문장 임베딩을 효율적으로 예측하기 위한 신경망 모델이다.
문장의 단어 임베딩을 평균화하는 방법이 문장 임베딩을 얻는 데 매우 좋다는 것이 증명되었다. 하지만 기존의 방법으로 학습된 단어 임베딩은 문장 표현 작업에 최적화되지 않아 비효율적이다.
Siames CBOW는 평균화하기 위한 목적으로 직접 단어 임베딩을 훈련시켜 이러한 문제를 해결한다.
이 모델의 기본 신경망은 문장 표현으로부터 주변 문장들을 예측함으로써 워드 임베딩을 학습한다. 이를 다양한 데이터셋으로 검증하였다.
- Introduction
- 워드 임베딩은 자연어처리의 다양한 작업에서 유용성이 증명되었지만, 단어 임베딩을 어떻게 조합하여 문장, 단락 또는 문서와 같은 더 큰 텍스트 조각을 표현할지는 명확하지 않음. 워드 임베딩을 단순히 평균화하는 방식이 여러 작업에서 강력한 베이스라인 또는 특징으로 증명되었다.
- 하지만, 워드 임베딩이 문장 표현에 최적화되지는 않았음.
→ 따라서 단어 임베딩을 평균화하는 작업에 최적인 모델(Siamese CBOW)을 제시함. 모델의 비용함수에 문장 임베딩 (문장의 단어 임베딩을 평균화한 것)을 직접적으로 포함시켜 문장 임베딩을 학습과정에서 고려하도록 한다. - 워드 임베딩은 비지도 학습을 통해 빠르고 확장 가능한 방식으로 훈련된다. 레이블이 없으므로 단어 임베딩은 특정 작업에 한정되지 않는다. 대규모 훈련 corpus(말뭉치)에서 훈련된 단어 임베딩은 다양한 작업에 활용된다.
*corpus: 특정 언어 또는 주제에 대해 수집된 텍스트 데이터의 집합 다음 두 가지 특징-
대량의 레이블이 없는 데이터로 빠르게 훈련 가능하고
-
다양한 작업에서의 강력한 성능
으로 인해 단어 임베딩이 많은 대규모 응용작업에 사용될 수 있다.
-
- 목표/목적 : 문장 표현을 위한 단어 임베딩을 동일한 방식으로 최적화하는 것
- 여러 테스트 세트에서 강력한 성과를 기록할 수 있는 범용(general purpose) 문장 임베딩을 생성하고
- 대량의 레이블이 없는 훈련 데이터를 활용하고자 함
- word2vec 알고리즘에서, Mikolov는 모든 단어에 대해 주변 단어들을 예측함으로서 비지도 데이터로부터 워드 임베딩을 얻기 위한 지도학습 기준을 구축함. 여기서는 이 전략을 문장 수준에서 적용하여, 하나의 문장을 그 인접한 문장들로부터 예측하는 것을 목표로 한다. 이를 통해 구하기 쉬운 unlabeled 훈련 데이터를 사용할 수 있다. 단, 문서가 문장 단위로 나누어져 있어야 하며, 문장 간의 순서는 유지되어야 한다.
- 이 연구의 핵심 질문은 ‘문장 임베딩을 생성하기 위해 평균화하는 작업을 위한 단어 임베딩을 직접 최적화 하는 것이 word2vec보다 이 작업에 더 적합한 워드 임베딩으로 이어지는지’ 여부이다. 따라서, 임베딩을 비지도 학습 시나리오에서 테스트했고, 다양한 출처에서 유래한 20개의 평가 세트를 사용했다. 이 방법의 시간 복잡도를 분석하고 이를 베이스라인 방법들과 비교했다.
<주요 기여 요약>
- 문장 표현을 위해 직접 최적화된 고품질 워드 임베딩을 얻기 위한 효율적인 신경망 구조인 Siamese CBOW를 제시한다.
- 다양한 출처에서 유래한 20개의 데이터셋에서 Siamese CBOW가 생성한 임베딩을 평가하고, 다양한 환경(settings)에서 임베딩의 강건성을 입증
2. Siamese CBOW
- Siamese CBOW는 고품질 문장 임베딩을 효율적으로 추정하기 위한 신경망 모델
- 의미적으로 유사한 문장들의 임베딩이 서로 비슷하고, 다른 문장들의 임베딩은 서로 다른 것을 잘 나타낼수록 고품질
- 문장 임베딩을 계산하는 훌륭한 방법은 문장을 구성하는 단어들의 임베딩을 평균화하는 것. 최근 연구에서 이를 위해 사전 훈련된 단어 임베딩 (word2vec 및 GloVe)를 사용하지만, 이러한 임베딩은 문장 표현을 위해 최적화되어 있지 않음. → 이 논문에서는 이러한 접근 방식과 같이 단어 임베딩을 평균하여 문장 임베딩을 계산하지만, 그 단어 임베딩을 평균화하기 위해 직접 최적화한다.
- CBOW와의 차이점
- 문장 임베딩을 위해 최적화하여 의미적으로 유사한 문장들을 더 잘 반영한다. Siamese CBOW는 단어 임베딩을 직접 최적화하여 문장 임베딩의 품질을 높임. 유사한 문장들의 임베딩이 서로 비슷하고, 다른 문장들의 임베딩은 서로 다르게 만듦.
2.1 Training objective
- 문장 쌍과 확률 정의 훈련 데이터에서 문장 쌍 (, )에 대해 두 문장이 인접할 확률 을 정의
- 소프트맥스 함수를 사용하여 계산
- 소프트맥스 함수를 사용하여 계산
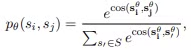
$s^θ_
x$는 모델 파라미터 θ를 기반으로 한 문장 $s_x$의 임베딩을 나타냄.
- 실제 구현 이론적으로는 분모의 합이 모든 가능한 문장 에 대해 계산되어야 하지만, 실제로는 비현실적 → 집합 를 두개의 집합 와 으로 대체한다.
- : 훈련 데이터에서 문장 에 인접한 실제로 등장하는 문장들
- : 인접하지 않는 무작위로 선택된 문장 n개
- 손실 함수
- 범주형 교차 엔트로피(categorial cross-entropy) 사용
- 범주형 교차 엔트로피(categorial cross-entropy) 사용
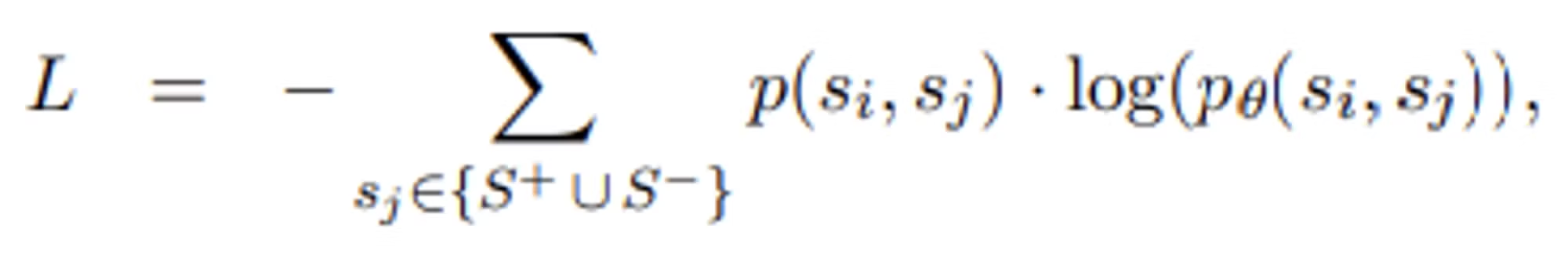
- $p(⋅)$는 실제 목표 확률
- $pθ(⋅)$는 파라미터 θ를 기반으로 모델이 예측한 확률-
목표 확률 분포
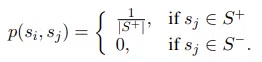
예를 들어, 2개의 긍정 예문과 2개의 부정 예문이 있으면 목표 확률 분포는 (0.5, 0.5, 0, 0)
2.2 Network architecture
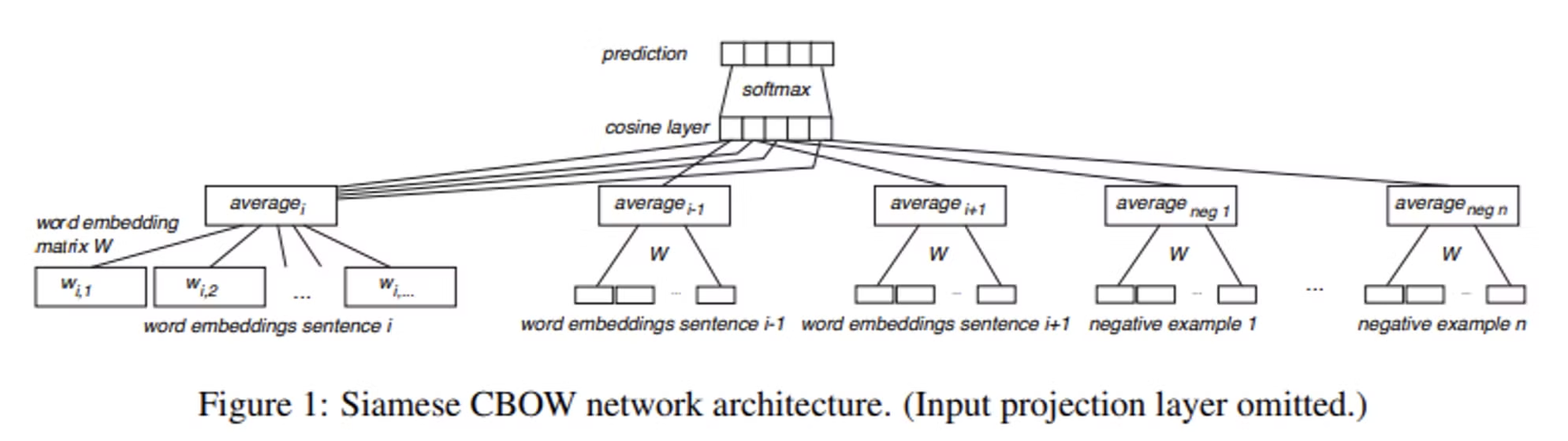
Siamese CBOW의 신경망 구조
- 입력은 단어 임베딩 행렬 W에서 임베딩을 선택하는 투사층(projection layer)
- 워드 임베딩은 다음 층(투사층?)에서 평균화된다. 입력 단어 임베딩과 동일한 차원을 가진 문장 표현을 생성한다.
- (마지막에서 두 번째) 코사인 레이어에서 문장 i에 대한 문장 표현과 다른 문장들의 코사인 유사도가 계산되고
- 마지막 출력층에서 소프트맥스가 적용되어 최종 확률 분포를 생성한다.
2.3 Training
- 단어 임베딩 매트릭스의 가중치
- Siamese CBOW 네트워크에서 학습 가능한 유일한 매개변수이다.
- 이는 확률적 경사 하강법(Stochastic Gradient Descent, SGD)을 사용하여 업데이트됨. 초기 학습률은 훈련 배치 수에 비례하여 단조롭게 감소한다.
3. Experimental Setup
- Siamese 네트워크의 문장 임베딩 효과를 평가하기 위해 여러 테스트 세트를 사용함. 라벨이 없는 말뭉치에서 단어 임베딩을 학습하기 위해 Siamese CBOW를 사용한다. 테스트 세트의 모든 문장 쌍에 대해, 각 문장의 단어 임베딩을 평균하여 두 개의 문장 표현을 계산한다. 두 문장 벡터 간의 코사인 유사도는 최종 의미적 유사도 점수로 생성
- 임베딩을 직접 평가하기 위해, Siamese CBOW모델과 비교대상 모델들에 모두 동일한 데이터를 사용한다.
- 논문의 주요 평가 목적(임베딩을 직접 테스트하는 것)에 영향을 주지 않도록 추가적인 단계는 생략한다.
3.1 Data
- 단어 임베딩 학습에 Toronto Book Corpus 사용
- 7,087권의 책에서 유래한, 1,057,070,918개의 토큰으로 구성된 총 74,004,228개의 전처리된 문장을 포함함.
- 본 연구에서는 5회 이상 등장하는 토큰을 고려하였고, 이는 315,643개의 단어이다.
3.2 Baselines
- 실험을 위한 베이스라인 모델로 다음 두 모델을 사용한다. 동일한 방식으로 문장 쌍 간의 유사도 점수를 얻는다. (즉, 생성한 문장 임베딩의 코사인 유사도를 계산한다.)
- Word2vec Skipgram과 CBOW 두가지 구조 모두 사용하며 기본 설정을 적용한다.
- min word frequency: 5
- word embedding size: 300 (벡터차원)
- context window: 5 (앞뒤로 단어 몇개를 고려할 것인가 범위)
- sample threshold:
- no hierarchical softmax
- 5 negative examples
- Skip-thought 순환 신경망을 사용하여 단어의 순서를 고려하는 방법이다. 라벨이 없는 데이터로 문장 임베딩을 학습하므로 비교 베이스라인으로 적합하다. Kiros에서 학습된 skip-thought 벡터를 사용하는데, 이는 문장 인코딩에 사용하는 어휘가 930,913개이므로, 본 연구와 word2vec이 사용하는 어휘 크기(315,643개)보다 세 배 크다는 점에서 advantage가 있다.
- Word2vec Skipgram과 CBOW 두가지 구조 모두 사용하며 기본 설정을 적용한다.
3.3 Evaluation
- 2012년, 2013년, 2014년, 2015년의 SemEval 의미적 텍스트 유사성 작업에서 제공된 20개의 데이터 세트를 사용
- 다양한 출처(예: 뉴스, 트윗, 비디오 설명)에서 수집된 문장 쌍으로 구성되어 있으며, 다수의 평가자들이 수동으로 5점 척도(1: 의미적으로 관련 없음, 5: 의미적으로 유사함)로 평가.
- 실제 유사도 점수는 평가자들의 점수의 평균값이며, 따라서 2.685와 같은 실수일 수 있다.
- SemEval에서 사용한 피어슨 상관계수(Pearson’s r)를 평가 지표로 사용한다. 스피어만 상관계수(Spearman’s r)도 자주 보고되므로, 여기서도 함께 보고한다.
- 통계적 유의성 동일한 입력 문장 쌍에 대해 유의미하게 다른 점수를 생성하는지 확인하기 위해, 모든 평가 세트에서 모든 실행 간의 윌콕슨 부호 순위 검정(Wilcoxon signed-rank test) 통계량을 계산한다.
- p값이 0.0001보다 작으면 실행이 통계적으로 유의미하게 다른 것으로 간주한다.
3.4 Network
- 임베딩 크기를 300으로 고정하고, 훈련 코퍼스에서 5회 이상 나타나는 단어만 고려한다.
- 2개의 부정적 예제를 사용한다.
- 임베딩은 평균 0과 표준편차 0.01을 갖는 정규 분포에서 무작위로 초기화된다.
- 배치 크기는 100
- 초기 학습률 α는 0.0001로 설정되며, 이는 훈련 데이터에서의 손실을 계산하여 결정
- 학습은 한 에포크로 구성된다.
- 네트워크는 Theano를 사용하여 구현하고, 실험은 DAS5 클러스터에서 GPU를 사용하여 수행했다.
4. Results
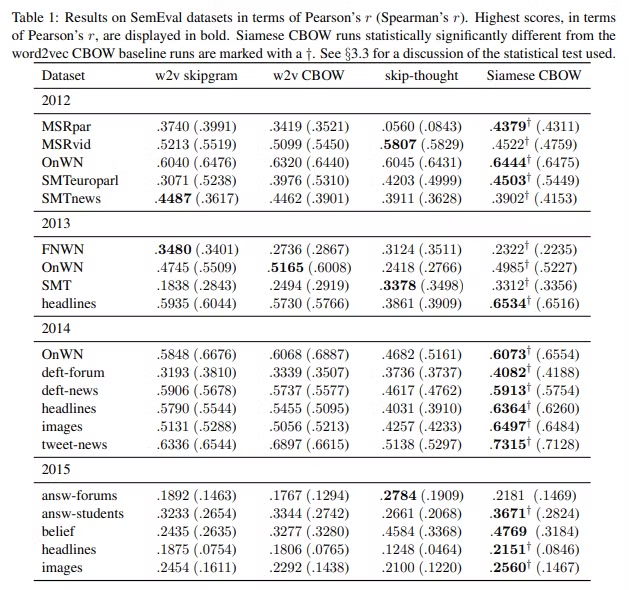
4.1 Main Experiments
- Siamese CBOW가 대부분의 케이스에서 다른 베이스라인 모델보다 뛰어났다.
- 문장 평균 길이가 가장 긴 세트(2013 SMT)에서 Siamese CBOW가 skip-thought(베이스라인 중 가장 뛰어난 모델)와 매우 가까운 수치를 보였다.
- 어휘 겹침이 적은 세트(7% 중복)에서 모든 모델이 저조한 수치를 보였다. 어찌보면 당연한 결과. 어휘 중복이 각각 11%, 14%인 세트(2015 belief, 2012 MSRpar)에서 Siamese CBOW가 가장 좋은 성능을 보였다.
- 모든 세트 통틀어 가장 높은 성능 수치는 0.7315으로, Siamese CBOW의 Pearson's r이 2014 tweet-news 세트에서 완전 비지도 학습임에도 불구하고 높은 성과를 보였다.
- 최신 연구에서 (Hill et al., 2016) FastSent가 소개되었으며 실증 결과가 보고되지 않아 FastSent와 Siamese CBOW 결과를 따로 비교하였다.(Table2) 평가 세트의 절반은 FastSent가 앞서고 또 다른 절반은 Siamese CBOW가 앞선다는 사실이 서로 보완적인 차이를 시사한다.
4.2 Analysis
하이퍼파라미터(이터레이션, 다양한 부정적 예시 수, 임베딩 차원)를 검토하여 Siamese CBOW의 안정성을 조사함.
- 4.2.1 Performance across iteration
- 이상적으로 학습 알고리즘의 최적화 기준은 손실 함수의 전체 도메인에서 작동해야 한다. 하지만, 본 연구의 손실 함수는 샘플만 관찰하므로 수렴이 보장되지 않는다. 그럼에도 불구하고 이상적인 학습 시스템은 학습데이터의 양에 따라 성능이 변도하지 않아야 하고, 충분한 양의 데이터가 제공되면 성능이 안정화되어야 한다.
- Siamese CBOW의 성능이 학습 과정동안 변동하는지 확인하기 위해 5 에포크 동안 10,000,000 예제마다 그리고 한 에포크가 끝날 때마다 성능을 모니터링했다. → 그 결과, 대부분의 데이터 세트에서 성능이 매우 적은 변동을 보였으나, 세 가지 예외가 있었다.

-
2014 deft-news : 성능이 꾸준히 감소.
-
2013 OnWN : 성능이 꾸준히 증가.
위의 두 세트 모두 에포크 5가 끝날 때쯤에는 안정화되는 것으로 보임
-
2012 MSRvid : 초기에는 성능이 증가하다 지속적으로 감소. 평가 세트가 주로 매우 짧은 문장으로 구성되어 있음을 유추할 수 있음. (평균 문장 길이는 6.63으로, 표준 편차는 1.812)
따라서 300차원 표현이 이 데이터 세트에는 너무 큼. 200차원 임베딩이 이 데이터 세트에서 약간 더 나은 성과를 보임.
-
- 이상적으로 학습 알고리즘의 최적화 기준은 손실 함수의 전체 도메인에서 작동해야 한다. 하지만, 본 연구의 손실 함수는 샘플만 관찰하므로 수렴이 보장되지 않는다. 그럼에도 불구하고 이상적인 학습 시스템은 학습데이터의 양에 따라 성능이 변도하지 않아야 하고, 충분한 양의 데이터가 제공되면 성능이 안정화되어야 한다.
- 4.2.2 Number of negative examples 다양한 부정적 예제의 수에 따른 Siamese CBOW의 Pearson 상관계수 성능 결과
 대부분의 데이터 세트에서 부정적 예제의 수가 Siamese CBOW의 성능에 미치는 영향은 제한적임을 나타냄. 부정적 예제의 수를 많이 설정하는 것은 상당한 계산 비용을 초래함 → 따라서 부정적 예제의 수를 1 또는 2로 설정하는 것이 적절하다.
대부분의 데이터 세트에서 부정적 예제의 수가 Siamese CBOW의 성능에 미치는 영향은 제한적임을 나타냄. 부정적 예제의 수를 많이 설정하는 것은 상당한 계산 비용을 초래함 → 따라서 부정적 예제의 수를 1 또는 2로 설정하는 것이 적절하다.
- 4.2.3 Number of dimensions 다양한 벡터 차원 수에 따른 Siamese CBOW의 결과
 일부 데이터 세트에서 임베딩 차원을 늘릴수록 성능이 일관되게 향상되는 것을 확인할 수 있음. 반면 차원이 50,100 정도로 너무 낮으면 대부분 성능이 떨어짐. 차원 수를 늘릴수록 계산 비용이 증가하므로 적절한 차원수는 200 또는 300이라고 결론지음.
일부 데이터 세트에서 임베딩 차원을 늘릴수록 성능이 일관되게 향상되는 것을 확인할 수 있음. 반면 차원이 50,100 정도로 너무 낮으면 대부분 성능이 떨어짐. 차원 수를 늘릴수록 계산 비용이 증가하므로 적절한 차원수는 200 또는 300이라고 결론지음.
4.3 Time Complexity (시간 복잡도와 효율)
결과적으로, 예측 시 속도가 중요한 상황에서는 word2vec 또는 Siamese CBOW와 같은 간단한 평균화 방법이 복잡한 skip-thought 방법보다 선호된다.
4.4 Qualitative Analysis (정성적 분석)
- Siamese CBOW는 문장을 위해 단어 임베딩을 직접 평균내기 때문에, 의미적으로 큰 영향을 미치지 않는 단어들은 낮은 벡터 노름(norm)을 가지게 된다
-
벡터 노름이 가장 낮은 10개 단어: to, of, and, the, a, in, that, with, on, and as
-
벡터 노름이 높은 단어들은 주로 개인 대명사이다. : had, they, we, me, my, he, her, you, she, I
이는 우리가 소설 텍스트(대화가 많이 포함된)에 대해 학습했기 때문에 자연스러운 결과이다.
-
- 동일한 코퍼스에서 학습했을 때 Siamese CBOW와 word2vec가 각각 예측한 관련 단어들의 차이 예를 들어 코사인 유사도가 0.6 이상인 경우,
-
her 과 관련된 단어
- word2vec은 she, his, my, hers
- Siamese CBOW에서는 she
-
me와 관련된 단어
- word2vec는 him
- Siamese CBOW는 I와 my이러한 몇 가지 예를 통해 Siamese CBOW는 단어들 간의 관련성을 선택할 때 매우 엄격하게 학습하는 것으로 보임.
-
위와 같은 결과를 바탕으로 다음과 같은 결론을 내림
- Siamese CBOW를 사용한 문장 내 평균화를 위한 단어 임베딩 최적화는 다양한 설정에서 효과적입니다.
- Siamese CBOW는 다양한 파라미터 설정에 대해 견고하며, 반복 학습 동안 성능이 안정적이다.
- Siamese CBOW는 예측 시 문장 임베딩을 빠르고 효율적으로 계산한다.
5. Conclusion
- 문장 표현을 생성하는 데 최적화된 워드 임베딩을 효율적으로 학습하는 신경망 구조인 Siamese CBOW를 제안함 레이블이 없는 비지도 텍스트 데이터로만 훈련되며, 입력 문장 표현으로부터 앞뒤 문장을 예측한다.
- 해당 모델을 20개의 테스트 세트로 평가하여 대부분의 케이스에서 Siamese CBOW가 word2vec 베이스라인 및 skip-thought 베이스라인 모델보다 우수함을 입증했고, 고품질의 문장 표현을 얻는 강력한 방법이 된다.
- 제언
-
Siamese CBOW 임베딩이 지도학습 작업 결과에 어떤 영향을 미칠지
-
대규모 텍스트(ex.문서)에 대한 임베딩이 문서 클러스터링 및 필터링 작업에서 어떻게 성능을 발휘할지
보는 것도 흥미로울 것이다.
-
