
💡 설문분석시스템 AI API 도입기
사내 설문분석시스템 리뉴얼 프로젝트를 진행하면서 AI API를 사용한 신규 기능 개발 과정을 정리해보려 합니다!
✨ 신규 기능 개발이 필요했던 이유, 그리고 GPT API
사내에서 사용하고 있던 기존의 설문분석시스템은 주관식 답변을 받는 문항에 대해서는 단순히 답변리스트를 주루룩 나열해주는 방식으로만 구성되어 있었습니다.
그러다보니, 설문결과를 분석하는 사용자 입장에서는 모든 답변리스트를 읽은 후, 대충 이러한 내용이 나왔구나를 파악하는 방식으로만 사용해 왔습니다.
여기서 발생하는 불편한 점은,
- 설문결과를 분석하는 시간이 굉장히 오래걸린다.
- 사용자의 주관적인 관점에서 설문결과를 분석하게 된다.
위와 같은 불편한 이슈들이 발생할 수 밖에 없었죠...
그렇다면, 위의 이슈들을 조금은 해결하고 사용자들의 능률을 향상시킬 수 있는 방식은 뭐가 있을까 생각해봤습니다.
일단, 모든 설문 답변리스트를 요약한 짧은 글이 있다면, 사용자는 1차적으로 전체 설문결과에 대한 대략적인 분위기를 파악한 후 디테일한 분석이 가능하기 때문에 좋은 데이터가 될 수 있을 거라 생각했습니다.
두번째로, 전체 답변 리스트 중 많이 등장하는 단어를 확인할 수 있는 워드 그래프 (Word Graph)가 있으면 더 빠르게 그리고 정확하게 설문 결과 데이터를 파악할 수 있겠다고 생각했습니다.
자, 필요한 신규개발 기능은 나왔고, 이제 어떻게 구현할 지에 대한 고민을 해야되는데 우선 요약글 구현에 있어서 좋은 레퍼런스라고 생각했던 것이 야놀자 서비스의 후기에 대한 GPT요약 글이었습니다.
GPT API가 수용할 수 있는 후기를 요약하여 사용자들에게 해당 숙소에 대한 대략적인 평판을 제공해주는 기능이었죠.
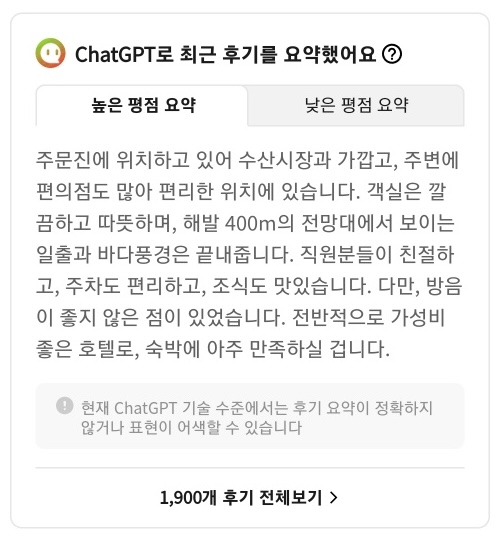
우리 서비스에도 적절하겠다라는 생각이 들었습니다.
요약이 가능하고, Open ai의 gpt 서비스는 지금도 계속 활발히 디벨롭이 되고 있으니까 지속적으로 성능개선이 가능하겠다는 생각이 들었기 때문에 GPT서비스를 이용하여 신규기능을 개발해 보기로 결정했습니다.
✨ 쉽지 않았던 첫 삽 뜨기
뭘 개발해야할지는 결정되었지만 어떻게 어떤 디자인으로 개발할 지는 정해진게 없었습니다.
무엇보다 신입이 이 모든것을 결정해야 했기에 굉장히 막막했죠...ㅎ
그치만 어쩌겠습니까! 해내야죠!
일단 UI 디자인을 간략하게 해보기로 했습니다.
화면에 보여줘야하는 데이터는 총 2개!
- 설문데이터에 많이 등장하는 단어에 대한 그래프
- 설문데이터를 요약한 요약 글
일단 사용자가 해당 페이지를 접속했을 때, 워드 그래프를 통해 빠르고 직관적으로 설문결과에 대한 대략적인 키워드를 파악하는 것이 좋겠다고 생각해서 그래프를 최상단에 배치시키기로 했습니다.
그리고 바로 하단에 요약글 컴포넌트를 배치하여 조금 더 디테일하게 분석결과를 파악하는 거죠.
즉, 위에서 아래로 내려갈 수록 점점 디테일한 분석결과를 파악할 수 있도록 구성하기로 했습니다.
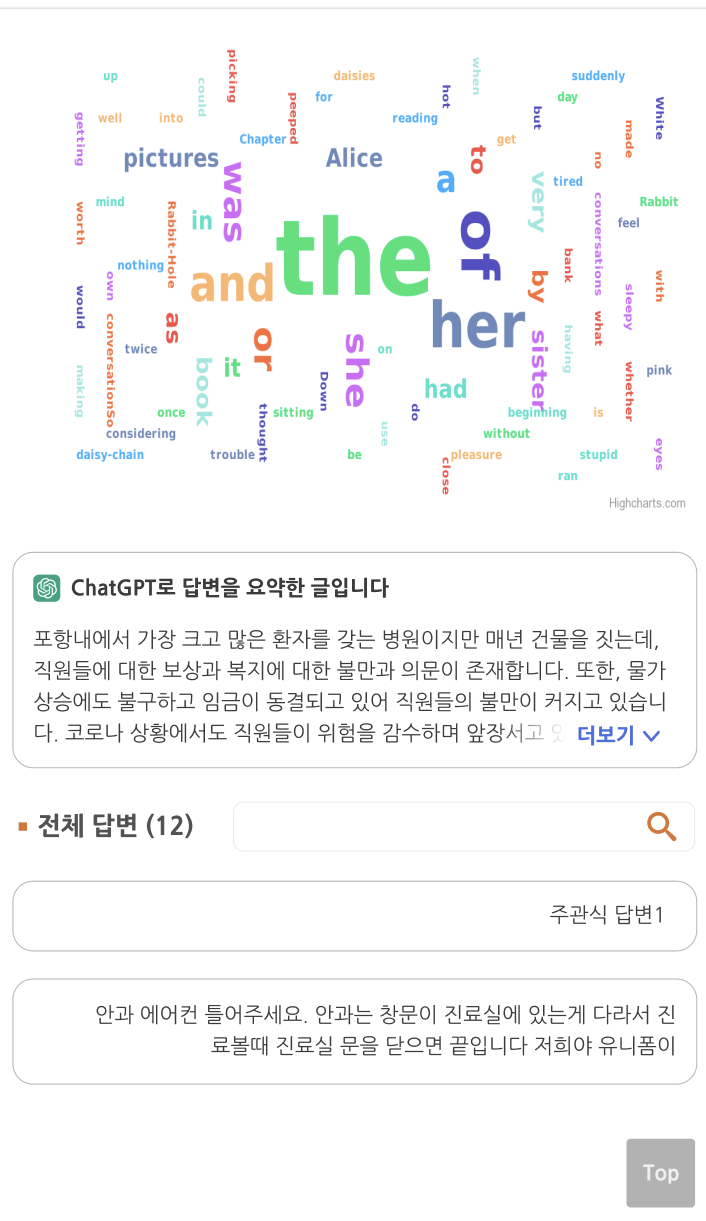
위의 워드그래프는 리뉴얼 전에 사용했던 HighCharts를 사용하기로 했고, 요약글 컴포넌트는 Chat GPT API를 사용해서 개발하기로 결정했습니다.
✨ 다사다난한 워드그래프
드디어 개발을 시작했습니다!
하지만 예상한대로 잘 흘러가면 신입개발자가 아니죠!..ㅎ
워드그래프 구현 과정에서 이슈가 발생했습니다.
설문결과 string값을 모두 하나의 string으로 합친 후,
// 단어 빈도수 추출 함수
const extractWordCount = (text) => {
const lines = text ? text?.replace(/[():'?0-9]+/g, "").split(/[,\. \n]+/g) : [""];
const data = lines
.reduce((arr, word, idx) => {
let obj = Highcharts.find(arr, (obj) => obj.name === word);
if (obj) {
obj.weight += 1;
} else {
obj = {
name: word,
weight: 1,
};
arr.push(obj);
}
return arr;
}, [])
return data;
};그 string값을 위의 함수의 파라미터로 전달하여 키워드에 대한 카운트를
[
{
name : "단어",
weight : 10
},
{
name : "단어2",
weight : 6
},
]객체형태로 리턴하는 방식이었습니다.
여기서 발생한 이슈는 바로, 불필요한 빈번하게 반복되는 단어가 리턴된다는 것입니다.
무슨말인지 잘 모르겠죠?
저는 처음 머리속으로 구상했을때는 명사형태의 단어들이 추출되는 것을 기대했습니다.
"의사", "불친절", "비효율적인 프로세스"와 같은 단어들을 예상한거죠.
하지만! 설문데이터는 명사형태로 되어있지않죠?
"의사들이 너무 불친절해요!"와 같은 글 형태로 되어있습니다.
그러다보니 단어를 추출할 때,
"의사들이", "너무", "을", "가", "했습니다"와 같은 의미없는 조사나 깔끔하지 못한 데이터들이 추출되었죠.
심지어 조사나 "했습니다"와 같은 단어는 거의 매 답변마다 붙어있으니 가장 많이 등장하는 단어로 한 자리 차지하고 있는 꼴이 되었습니다.
예상대로 안된거죠...ㅎ
그러면 어떻게 해결을 해야할까요?
이것도 ChatGPT API로 명사만 추출해달라고 할까?
일단 결과를 json형태로 받아와야되는데 당시 gpt model 3.5버전에서는 모든 리턴값이 string이었고,
"해당 데이터에 많이 등장한 단어에 대한 결과 입니다.
단어 1 : 12,
단어 2: 30
..."
이런 꼴로 나오기도 했기 때문에, 답변 속에서 데이터를 추출하기가 쉽지 않았습니다.
그러면 단어추출에 특화된 ai 서비스는 없을까?
다른 ai 서비스를 찾아보다가 Eden AI라는 서비스를 알게되었습니다.
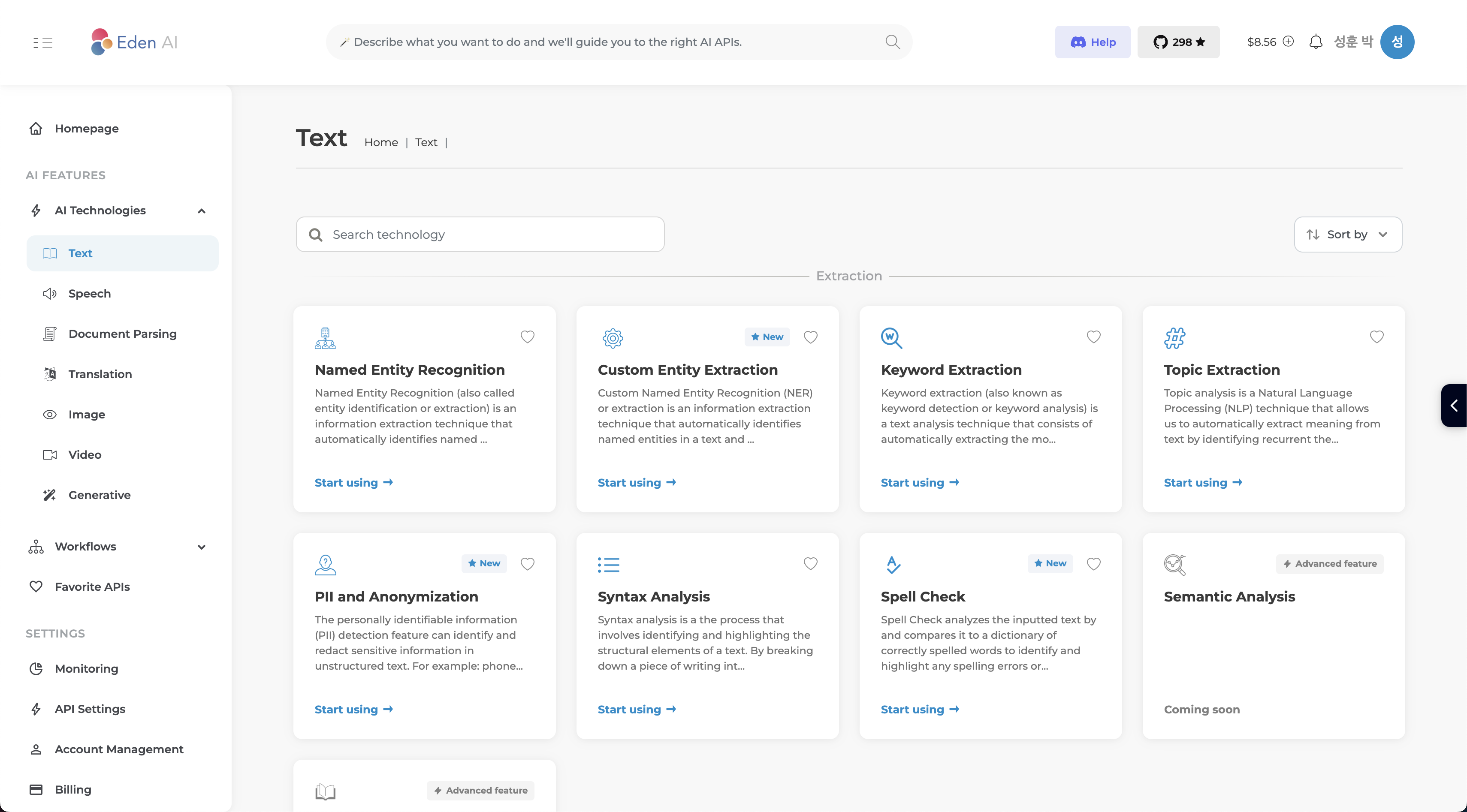 Keyword Extraction이라는 단어추출 전용 api가 있더군요!
Keyword Extraction이라는 단어추출 전용 api가 있더군요!
const options = {
method: "POST",
url: "https://api.edenai.run/v2/text/keyword_extraction",
headers: {
authorization: "Bearer 🔑 Your_API_Key",
},
data: {
providers: "ibm",
text: "this is a test",
language: "kr",
fallback_providers: "",
},
};로그인 시 발급받은 키값을 헤더에 넣고, 데이터와 함께 요청을 보내면 json형태의 값을 리턴해주는 방식이었습니다.
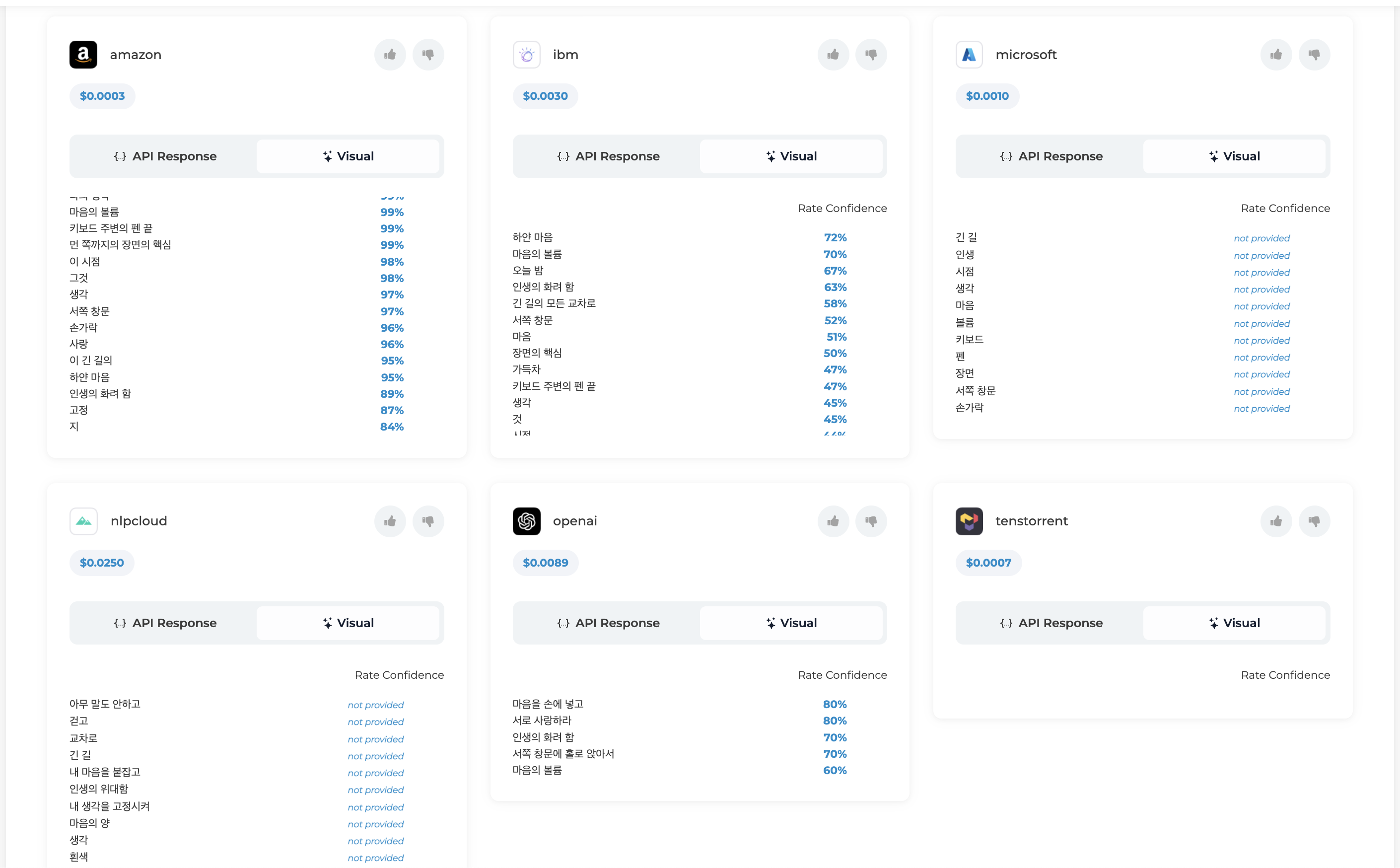
Open Ai에서 제공하는 ai모델을 각각 테스트해본 결과, 일단 가격도 10000 string length당 0.3달러이고, 리턴되는 단어의 퀄리티를 보았을 때, ibm모델이 가격과 정확도 면에서 가장 적합하다고 판단되었습니다.
그래서 ibm 모델을 사용해서 구현을 해보았죠.
하지만, 또 문제가 발생했습니다...
이 keyword extraction 모델들은 빈도수로 리턴값을 결정하는 것이 아니라, 중요도로 결정하는 것 같았습니다.
짧은 글일 경우, 불필요한 조사나 단어들을 제거해주고 주요단어들을 리턴해주기때문에 괜찮았지만 제가 구현하고자 하는 방식은 모든 답변 string을 하나로 합쳐서 그걸 파라미터로 보내주는 방식이었습니다.
이랬을 때, 단어의 빈도수가 높은것이 중요도가 높게 나오는 것이 아니라, 뭔가 앞의 문장 또는 뒷 문장에 핵심이 되는 단어가 리턴되는 느낌이더군요.
여기서 굉장히 많은 고민을 했습니다.
텍스트가 짧을때는 괜찮게 나온다... 그렇다면? 설문데이터가 저장되는 시점에 데이터베이스에 답변 원본과 컬럼하나를 추가해서 해당 답변의 키워드를 추출한 데이터를 콤마를 기준으로 하나의 string으로 합쳐서 저장하면?
그러면 그 데이터를 위에서 소개한 단어추출 함수에 넣어주면 더 정확도가 높은 데이터를 차트에 뿌려줄 수 있지 않을까?
위의 고민처럼 구현해본 결과, 드디어 만족스러운 데이터를 얻을 수 있었습니다.
애초에 데이터가 불필요한 조사나 단어가 제거된 상태의 정제된 데이터이고, 그 데이터의 빈도수를 리턴하는 함수를 실행시켰으니, 깔끔하고 정확도가 높은 만족스러운 데이터가 추출되었고, 이를 그래프에 보여주니 직관적이고 빠르게 설문결과에 대한 키워드를 파악할 수 있었습니다.
 구현된 워드그래프 컴포넌트!
구현된 워드그래프 컴포넌트!
✨ 역시나 다사다난한 GPT 요약 컴포넌트
자 이제 요약 컴포넌트를 만들 차례입니다...ㅎ
일단 모델마다 비용이 다르기 때문에 가격정책부터 파악해보기로 했습니다.
✨ 가격 정책
일단 GPT model 중, gpt-3.5-turbo-16k을 사용하기로 했습니다.
Open AI는 첫 결제이후 기간과 총 결제 비용에 따라 Tier를 분류하고 있었습니다.
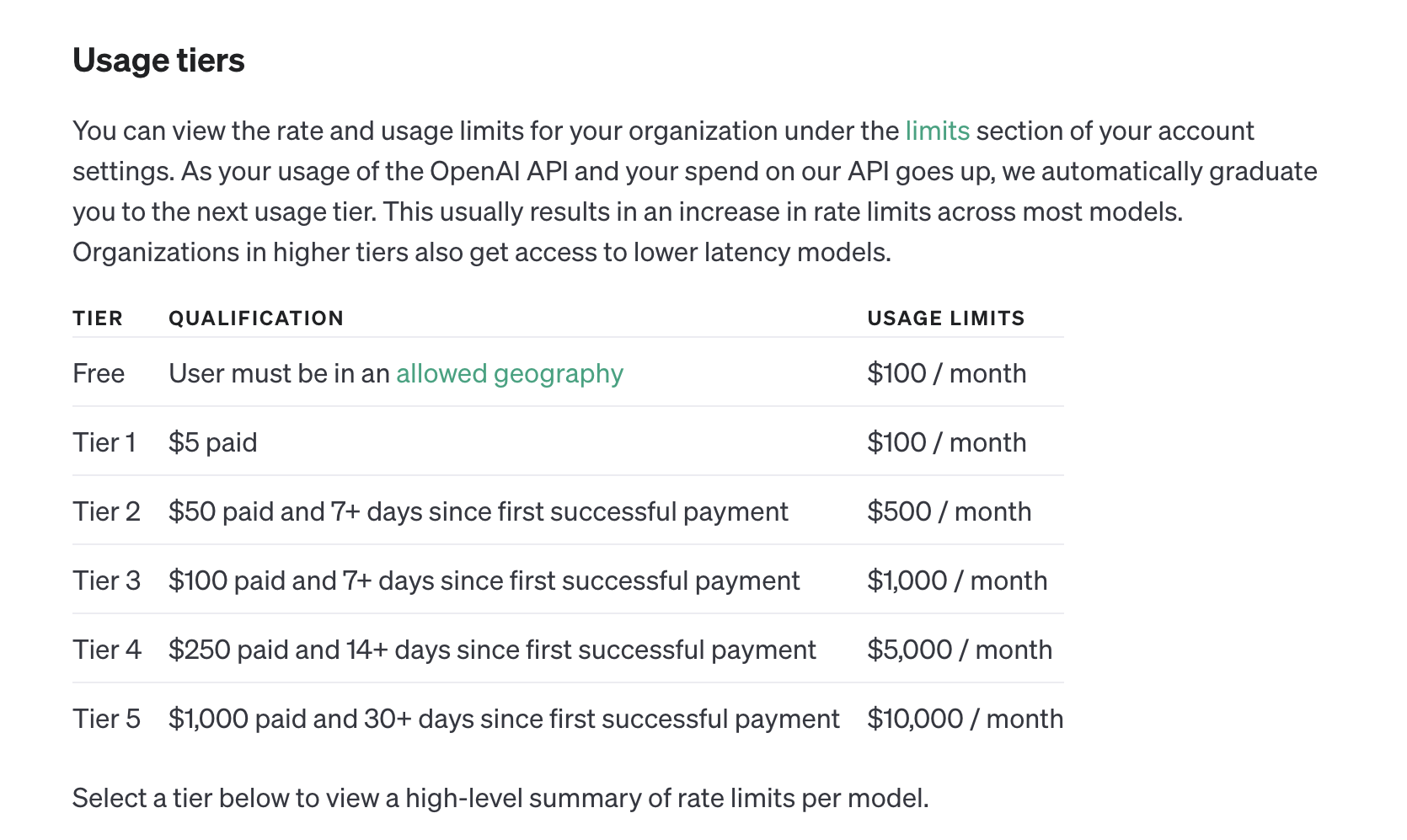
그래서 최초 가입했던 시기에는 아직 Free Tier였기 때문에 사용할 수 있는 모델이 한정되어 있었죠.
그당시 Free tier에서 사용할 수 있는 모델 중, 가장 큰 TPM을 가지고 있는 모델이 gpt-3.5-turbo-16k 모델이었습니다.

가격은 $0.0010 / 1K tokens -> 1000토큰 당 0.0010달러
일단, 티어가 업그레이드 되기 전까진 이 모델을 사용하여 구현하기로 했습니다.
✨ 어떻게 질문해야 잘 질문했다고 소문이 날까..?
자 그럼, 과연 gpt에 어떻게 질문해야 적절한 요약정보를 얻을 수 있을까요?
일단, 명확한 답변을 얻기 위해서 역할을 지정해주기로 했습니다.
너는 병원 컨설턴트야
그리고 이 설문을 하는 목적을 알려줬습니다.
병원 운영 개선을 위해 설문조사를 실시했어
마지막으로 원하는 답변에 대해서 구체적으로 설명해줬습니다.
병원 컨설턴트 입장에서 설문 답변 중 가장 많이 제시된 내용을 중심으로 400자 이내의 존대말을 사용하여 요약해줘
✨ TPM에 걸리는 설문데이터의 양
처음 주관식 문항에 대한 답변데이터를 하나의 string으로 합쳐서 gpt에 넘겨준다고 했습니다.
이때, 문제가 발생한 게 gpt 모델의 TPM limit에 걸린다는 점이었습니다.
여기서 TPM이란 Token Per Minutes - 분당 허용 토큰양을 뜻합니다.
일단, 공식문서를 보니 현재 사용하고 있는 모델의 TPM은
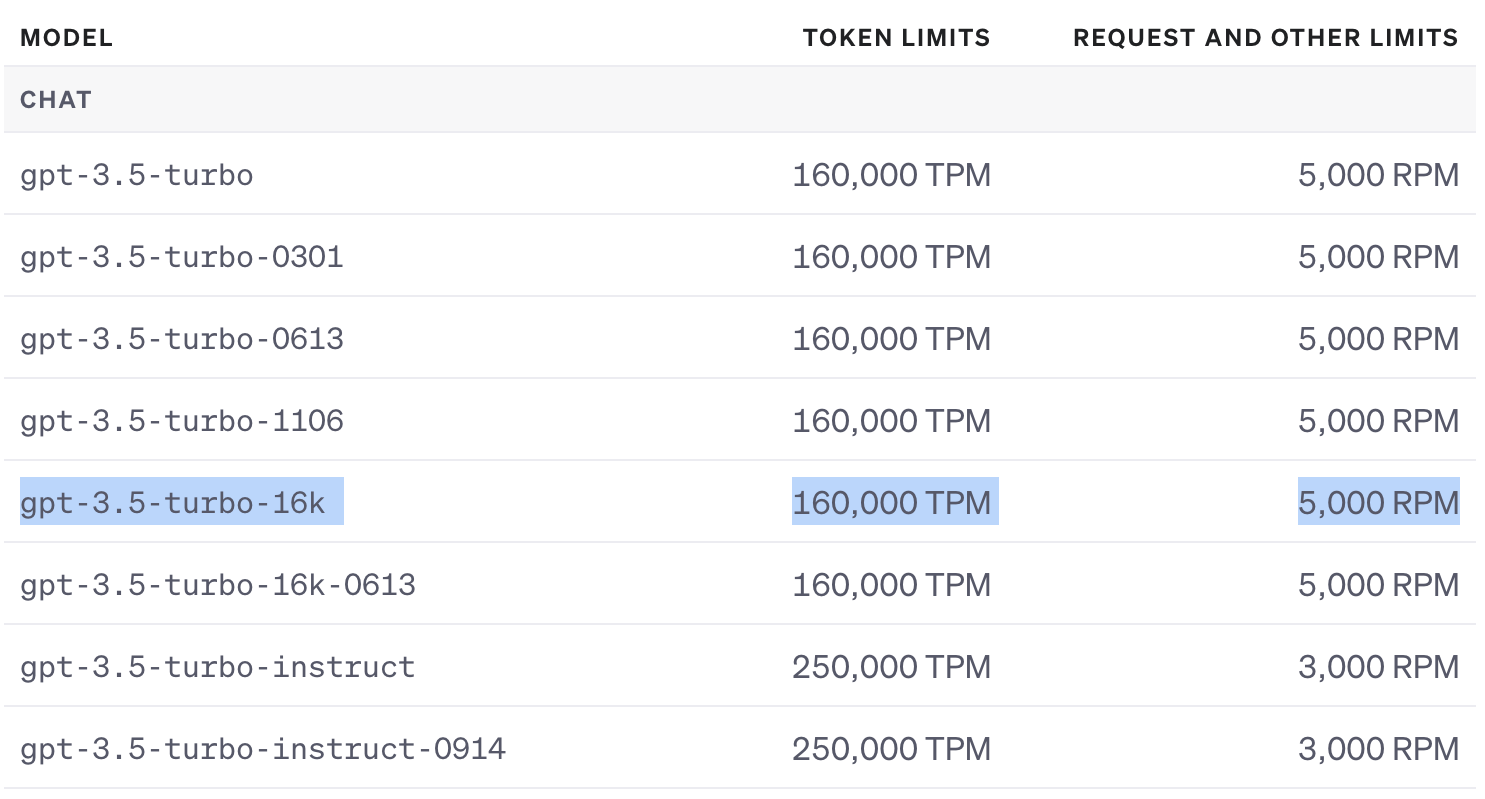
16만 토큰!
여기서 한번 요청할때 담을 수 있는 텍스트 양이 약 16000토큰 정도 였습니다.
실제 API로 테스트를 해보니 string length로 9000자 정도까지 요청 성공이 되더군요.
아직, 토큰과 string length의 정확한 허용 용량에 대해서는 파악이 조금 부족해서 조금 더 공부를 해봐야될 것 같습니다.
일단, 분당 16만 토큰은 허용되고, 한번 요청시 9000자 정도라는 limit을 알아냈으니, 여기에 맞춰서 알고리즘을 짜보려고 합니다.
설문 참여자가 많은 프로젝트의 경우, 전체 답변에 대한 string length를 구해봤을 때, 50만 length정도가 나오더군요.
이런 경우에는 아무리 잘라내도 TPM에 걸리기때문에, 최신 순으로 35만 length로 잘라줬습니다.
그리고 한번 요청 시 담을 수 있는 text양을 맞추기 위해 9000자를 기준으로 잘라서 배열로 나누어주었고, 그 배열의 길이만큼 for문을 돌아 api를 요청하는 방식으로 구현했습니다.
마지막으로 각각 모인 요약문을 다시 하나의 텍스트로 합쳐서 최종 요약문을 받아왔습니다.
정리하자면,
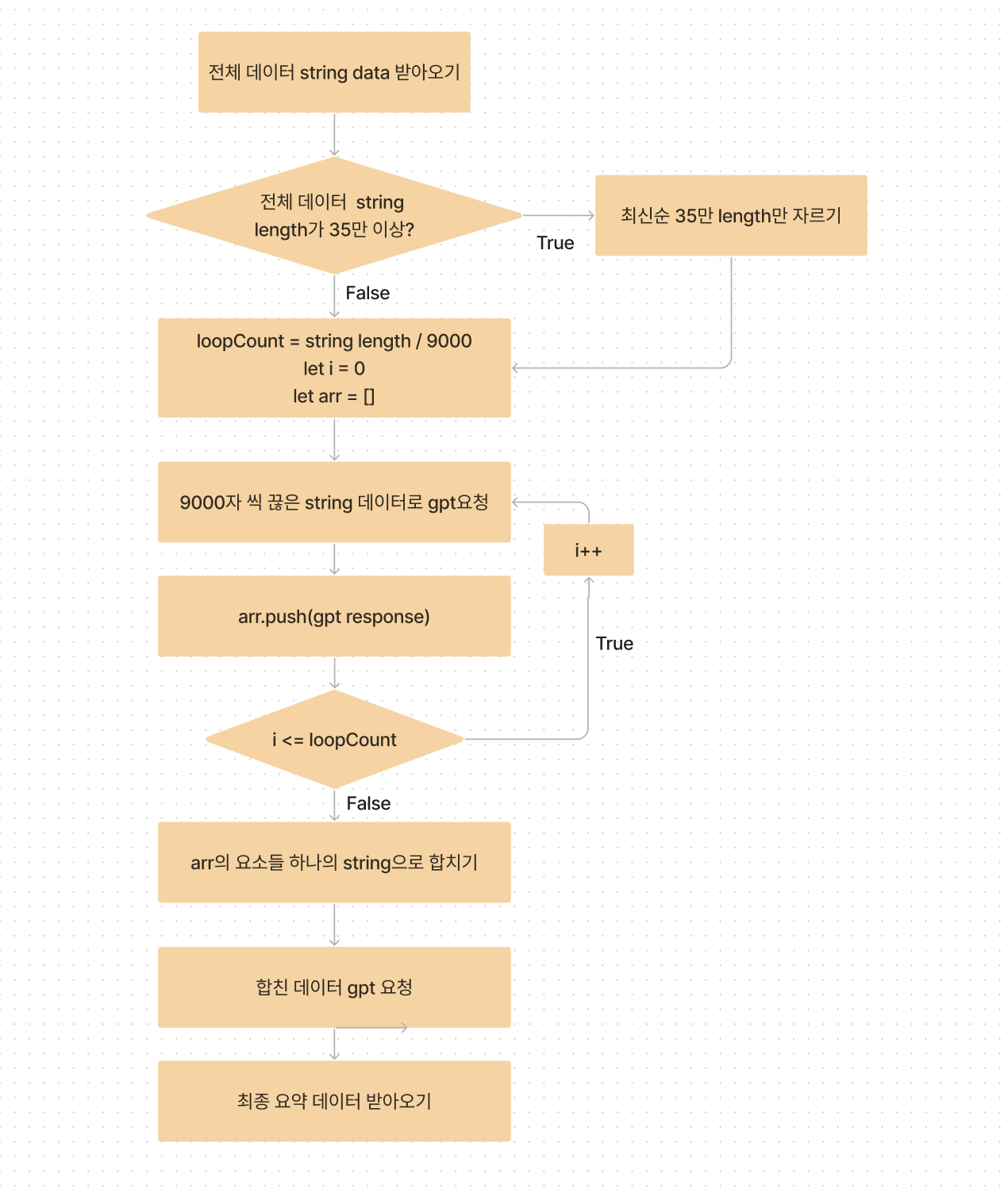 이러한 알고리즘으로 흘러가는 거죠!
이러한 알고리즘으로 흘러가는 거죠!
이렇게 최종적으로

GPT API를 사용한 요약 정보 컴포넌트도 구현을 완료했습니다!
✨ 드디어 GPT4! 그리고 Tier upgrade!
1차 구현이 완료되고, 어느정도 서비스가 운영되다보니 자연스럽게 티어가 업그레이드 되더군요!
서비스 오픈 후, 약 2달 반 정도 되었을때 누적 비용이 100달러를 초과되게 되면서 Tier 3으로 업그레이드 되었습니다.
드디어! GPT4모델을 사용할 수 있게 된거죠!
일단 업그레이드되면서 가장 좋았던 점은 TPM이 대폭 상승했다는 점입니다.
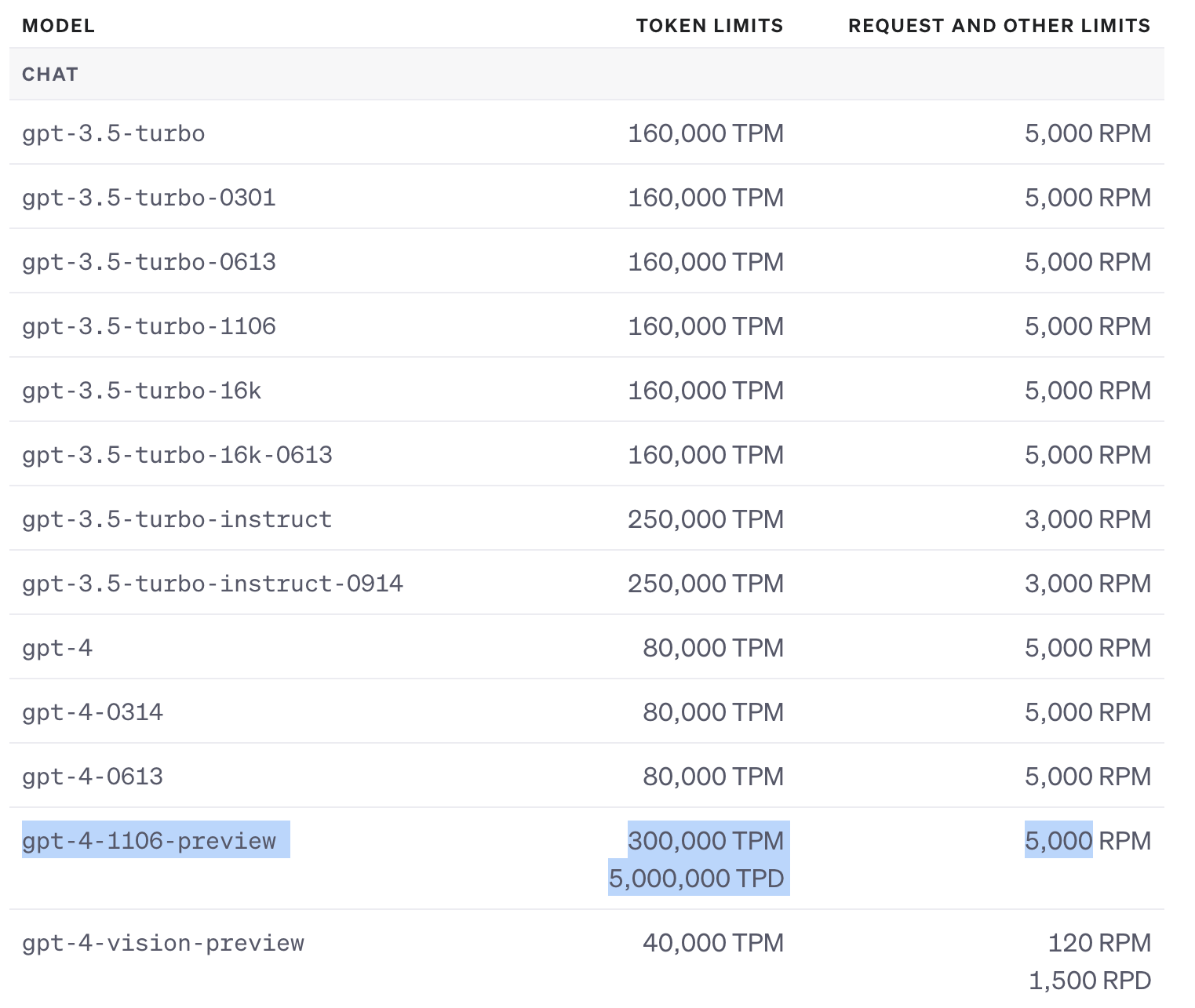 16만에서 30만으로 증가된거죠.
16만에서 30만으로 증가된거죠.
그리고 기존 9000자로 잘랐던 알고리즘을 무려 100,000자로 잘라도 요청 성공이 뜨더군요!
배열에 9000자로 자른 덩어리가 여러개 생기면 그만큼 api호출 횟수가 증가하기때문에, 딜레이가 많이 발생했었는데 이번 업그레이드로 그런 딜레이를 정말 많이 단축시킬수 있었습니다!
✨ 막막하기만 했던 신규기능 개발 과정... 그래도 해피엔딩!
어떻게보면 요즘 핫한 기술을 사용한 첫번째 프로젝트여서 재미있었던 점도 있었지만, 정말 많이 힘들었습니다.
위에서 작성한 알고리즘을 어떻게 짜야할지도 막막했고, 화면 디자인이며 비용 관련된 점, 그리고 api요청 당 허용되는 토큰의 양도 open ai의 공식문서를 다 뒤져가며, 수많은 테스트를 하면서 아.. 그냥 하지말까..라는 생각도 정말 많이 했습니다.
그치만, 이런 경험들이 신입개발자로서 계속 개발자를 해나갈 수 있는 원동력이 될 수 있을 거라고 생각했고 어찌저찌 구현에 성공하였습니다.
뭐.. 아직 확실히 알지 못한 부분들도 많고 부족한 점도 많은 개발이었지만, 신입개발자로서 주체적으로 도전했던 개발이었기 때문에 여러모로 조금은 성장할 수 있었던 경험이었다고 생각이 듭니다!
