다익스트라
1. 최단경로 알고리즘
특정 지점까지 가장 빠르게 도달할 수 있는 경로를 찾는 알고리즘.
- 다익스트라(Dijkstra)
- 플로이드-워셜(Floyd-Warshall)
- 벨만-포드(Bellman-Ford)
노드의 개수가 적을 경우 플로이드-워셜을 사용하는 것이 효율적입니다.
노드와 간선의 개수가 모두 많을 때 다익스트라를 사용하는 것이 효율적입니다.
오늘은 다익스트라를 배워봅시다.
2. 특징
- 간선에서 음의 가중치를 허용 않음(거리 또는 비용)
- 순환 포함 허용
- 기본적으로, 탐욕 알고리즘에 속함
- 매번 가장 비용이 적은 노드를 선택하려고 함
3. 동작
- 출발노드와 도착노드를 설정합니다.
- 최단거리 테이블을 최대값으로 초기화 시켜 줍니다. (INF)
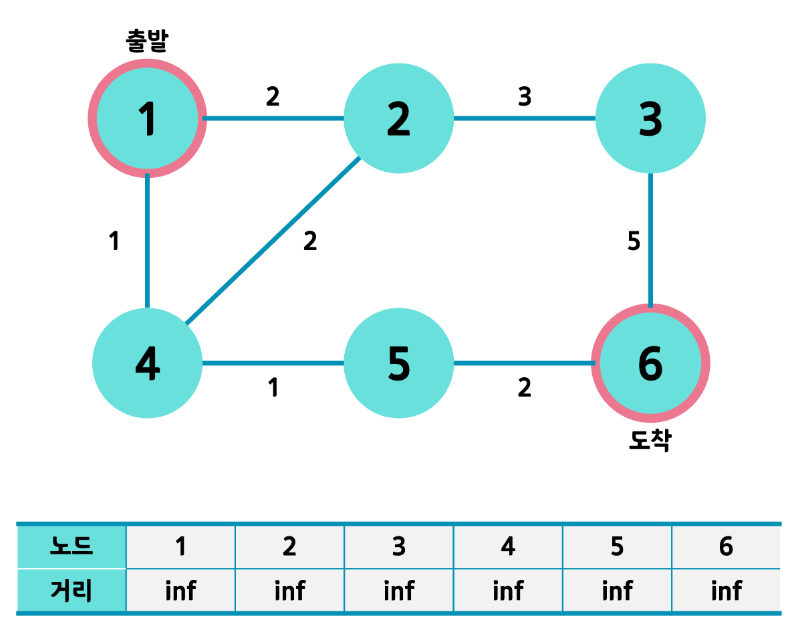
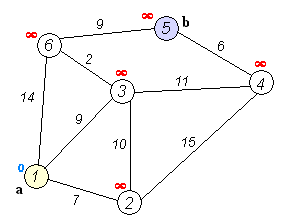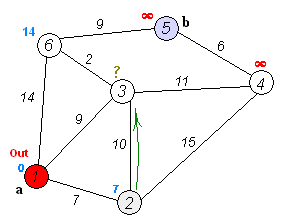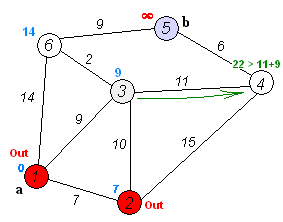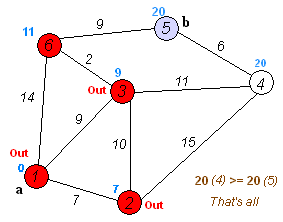
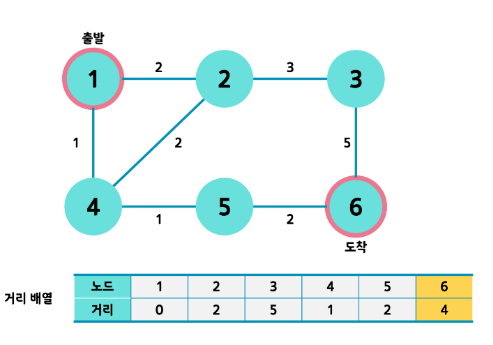
- 1번 노드가 Start 노드 , 6번 노드가 End 노드입니다.
- 테이블은 정점의 갯수 만큼 1차원 list로 만들고 각 원소를 INF로 초기화 합니다.
INF = int(1e9) dist = [INF]*(N+1)
- 또한 노드를 그리면서 각 가중치도 같이 해줍니다.(아래 코드는 양방향입니다.)
for _ in range(M): start, end, cost = map(int, input().split()) graph[start].append([end, cost]) graph[end].append([start, cost])
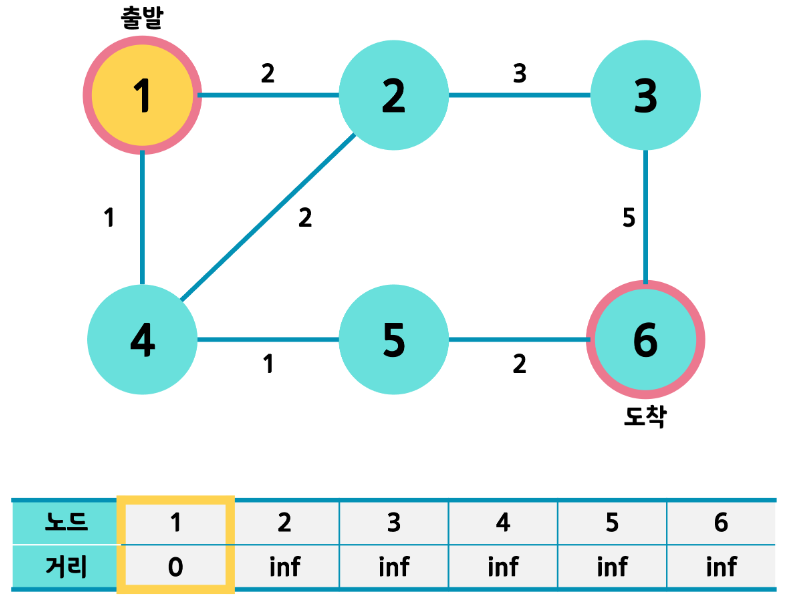
- 출발노드를 선택하여 0 으로 초기화 해줍니다.
dist[start] = 0
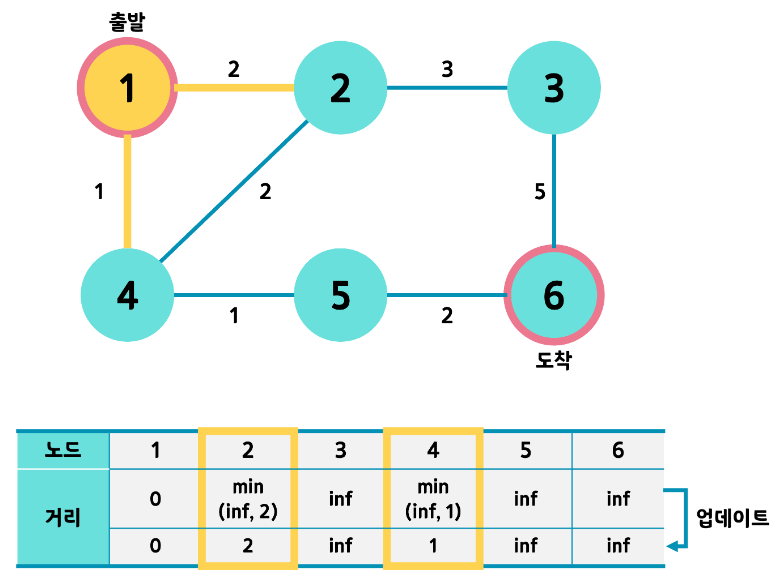
- 1번 노드에서는 2번,4번을 방문할 수 있습니다. 각 노드로 가는 거리를 기존에 테이블에 초기화 된 값과 비교하여 최소값으로 테이블을 초기화 해줍니다. 또한 방문하지 않은 노드 중 가장 거리값이 작은 번호를 다음 노드로 선택합니다.
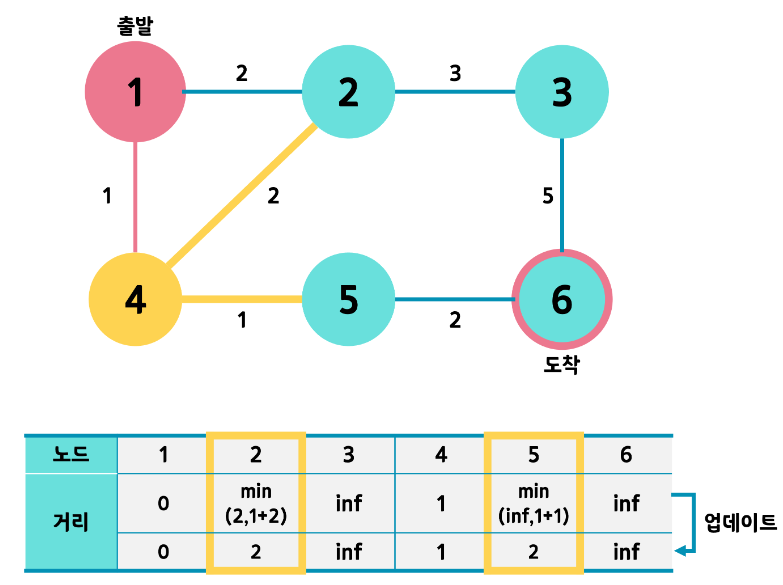
- 4번 노드에서도 위와 같은 작업을 반복합니다. 2번, 5번을 방문 가능합니다.
5번의 경우 (1->4) + (4->5) 와 기존 값을 비교하여 작은 값으로 초기화 해줍니다.
2번의 경우 기존 2와 (1->4) +(4->2) 즉 2와 3을 비교하면 최소값이 2이므로 업데이트 하지 않습니다.
거리값이 같다면 인덱스가 작은 노드를 다음 노드로 선택합니다.
2번과 5번 중 2번으로 갑시다.
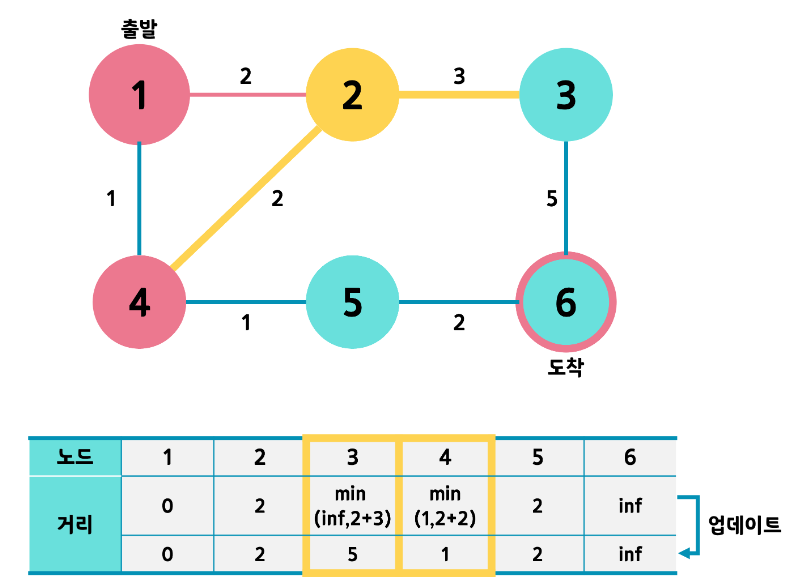
- 같은 과정을 반복합니다. 다음은 5번으로 가야겠죠?
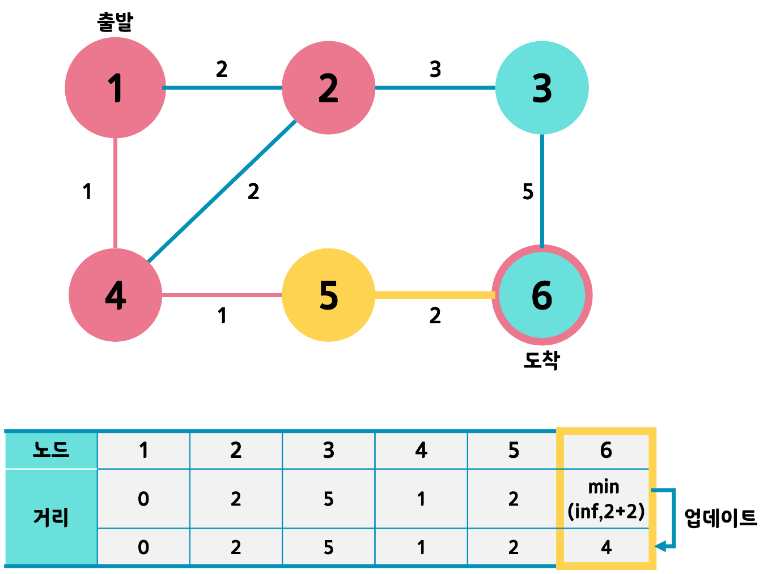
- 같은 과정을 반복하고 나면 남은 노드는 3번과 6번입니다. 거리값을 비교하면 6번이 더 작네요? 그럼 6번으로 갑니다. 과정을 반복하려 보니 6번은 도착노드였죠. 따라서 반복을 끝냅니다.
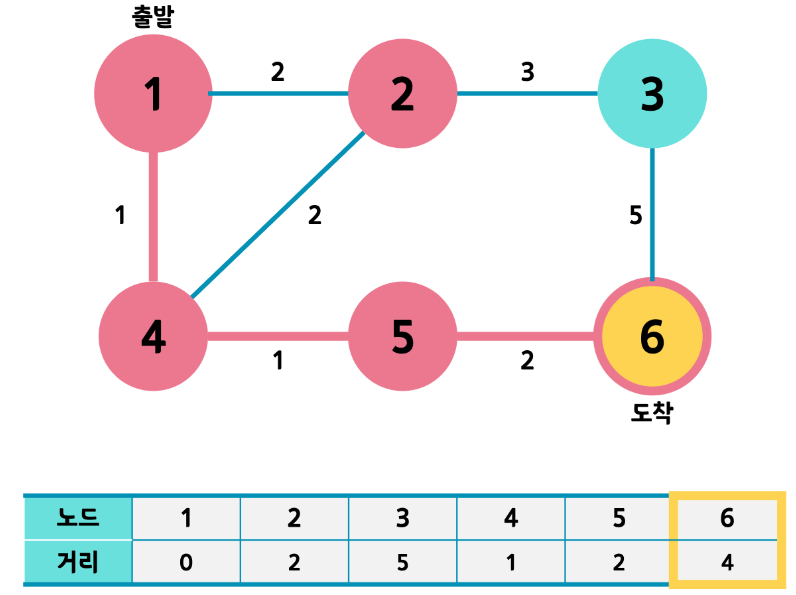
- 따라서 최단 경로는 1->4->5->6 즉 거리는 4가 됩니다.
3. 결론
위 과정에서 볼 수 있듯 다익스트라 알고리즘은 방문하지 않은 노드들 중 최단거리 노드를 선택하는 과정을 반복합니다. 도착노드에서는 다른 노드를 찾을 필요가 없습니다. 또한 탐색된 노드는 최단거리를 업데이트 하고 그 후에는 다시 갱신되지 않습니다. 이 말이 뭐냐..? 설명 갑시다.
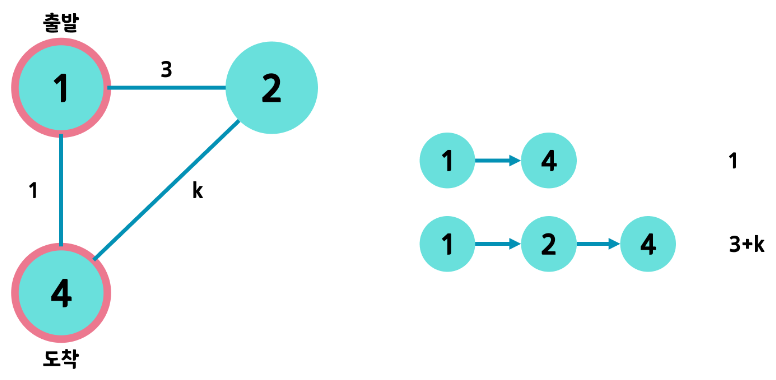
그림에서 보면 1->4가 최단거리가 아니려면 1->2->4 즉 3+K < 1 이 성립해야 합니다.
정리하게 되면 K < -2 즉, 가중치 K 가 음수가 되겠죠. 처음 특징에서 말했듯 다익스트라는 음의 가중치는 허용하지 않습니다.
그렇기 때문에탐색된 노드는 최단거리를 업데이트 하고 그 후에는 다시 갱신되지 않습니다.
- 거리 테이블의 앞에서부터 찾아내야 하므로 노드의 개수만큼 순차 탐색, 따라서 노드 개수가 N이라고 할 때 각 노드마다 최소 거리값을 갖는 노드를 선택해야 하므로 (N−1)×N 의 시간이 걸립니다.
O(N^2)
4. 구현해보자
이론은 익혔습니다. 하지만 구현을 못하면 그건 배운게 아니죠. 자격증도 필기를 따고 실기까지 합격해야 비로소 자격증이 나옵니다. 구현은 2가지 방법으로 나뉩니다. 2가지로 문제를 함께 풀어봅시다.
- heapq(우선순위 큐)
- 순차탐색
우선 익숙한 순차탐색부터 요리해 봅시다!
4-1. 코딩(순차탐색) - 시간복잡도[O(N^2)]
def get_smallest_node():
#초기값을 최대값으로....!!
min_value = INF
# 인덱스를 저장합시다
idx = 1
# 모두 돌며 최소값을 찾아 저장합니다.
for i in range(1, N+1):
if dist[i] < min_value and not visited[i]:
min_value = dist[i]
idx = i
# 가장 최소값을 return
return idx
def dijkstra(start):
# 자기자신은 비용이 들지 않습니다.
dist[start] = 0
visited[start] = True
# 거리를 비교해 작은값을 넣습니다.
for j in graph[start]:
if dist[j[0]] > j[1]:
dist[j[0]] = j[1]
# 다음 노드 선택하고... 뭐 그런거 위에서 했죠?
for _ in range(N-1):
now = get_smallest_node()
visited[now] = True
for j in graph[now]:
cost = dist[now] + j[1]
if cost < dist[j[0]] and not visited[j[0]]:
dist[j[0]] = cost
INF = int(1e9) # 10억입니당!
N = int(input())
M = int(input())
graph = [[] for _ in range(N+1)]
dist = [INF for _ in range(N+1)]
visited = [False]*(N+1)
for _ in range(M):
start, end, cost = map(int, input().split())
graph[start].append((end, cost))
start, end = map(int, input().split())
dijkstra(start)
# start와 end가 같으면 0이겠죠?
if end == start:
print(0)
else:
print(dist[end])
4-2. 코딩(우선순위 큐)
import sys
from heapq import heappush, heappop
input = sys.stdin.readline
INF = int(1e9)
N = int(input())
M = int(input())
graph = [[] for _ in range(N + 1)]
dist = [INF for _ in range(N + 1)]
for i in range(M):
start, end, cost = map(int, input().split())
graph[start].append([end, cost])
start, end = map(int, input().split())
def dijkstra(start):
dist[start] = 0
heap = []
heappush(heap, [0, start])
while heap:
cost, start = heappop(heap)
if dist[start] < cost:
continue
for end_node, distance in graph[start]:
real_cost = cost + distance
if dist[end_node] > real_cost:
dist[end_node] = real_cost
heappush(heap, [real_cost, end_node])
dijkstra(start)
print(dist[end])5. 번외 (우선순위 큐)
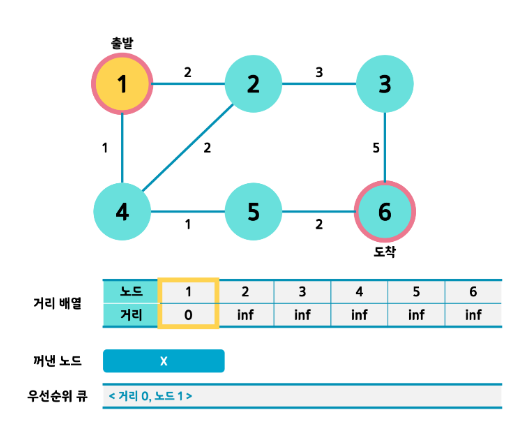
- 출발노드 1번의 거리를 갱신해줍니다. 0 이겠죠?
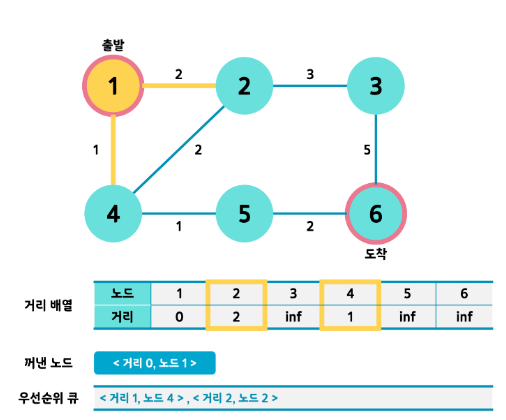
- 큐에서 heappop하여 인접노드를 탐색합니다. 그리고 최단거리로 갱신할 수 있는 노드만 heappush 합니다. 아닌경우는 continue 합시다. 큐는 거리값이 작은 순서대로 정렬된다.
if dist[start] < cost: continue
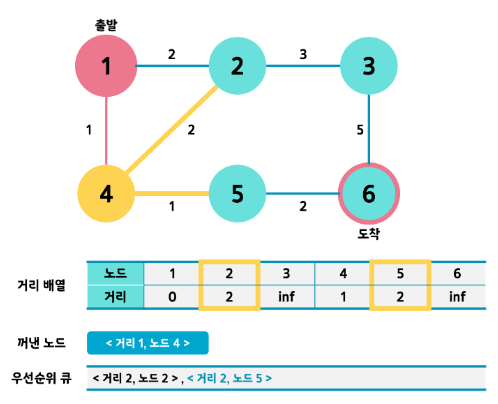
- <거리1, 노드 4>를 pop 하여 인접노드 조사를 합니다. 최단거리가 갱신되는 5번 노드만 큐에 넣어줍니다. 이같은 과정을 반복합시다.
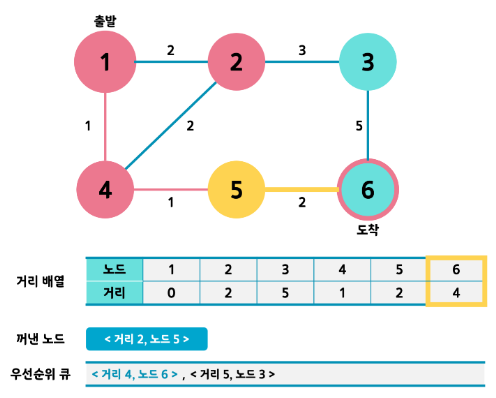
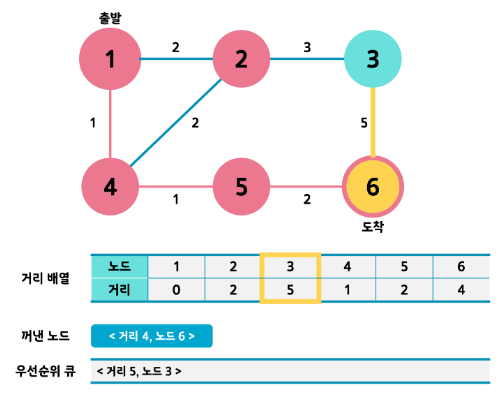
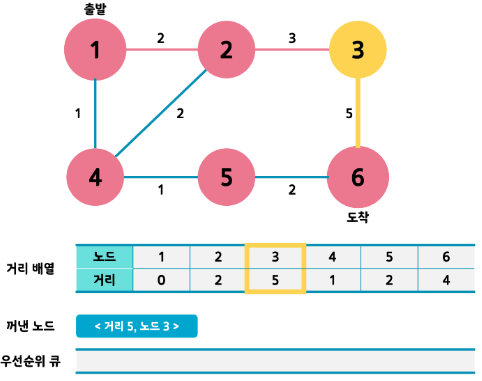
- 과정을 반복하다보면 큐가 비게 됩니다. 그럼 동작이 끝나겠죠??
- 그때 도착노드의 거리값이 최단거리가 되게 됩니다.
- 시간복잡도 - 간선의 수를 E, 노드의 수를 V라고 했을 때 O(E logV)가 됩니다. 우선순위 큐에서 꺼낸 노드는 연결 노드만 탐색하여 최악의 경우에도 E만큼 반복합니다. 즉 하나의 간선에 대해서는 O(logE), 또한 E는 항상 V^2 보다 작기 때문에 O(E logV) 가 됩니다.
O(E logV)
참고 : LUMOS MAXIMA

만두 선생님