
JPA 탄생 배경-1에 이어 작성합니다:)
https://velog.io/@sungjin0757/JPA-%ED%83%84%EC%83%9D-%EB%B0%B0%EA%B2%BD-1
Java Persistence API
- 자바 진영의 ORM 기술 표준
ORM이란?
- Object relational mapping (객체 관계 매핑)
- 객체는 객체대로 설계, 관계형 데이터베이스는 관계형 데이터베이스대로 설계
- ORM 프레임워크가 중간에서 매핑 (객체와 관계형 데이터베이스 사이를 매핑)
즉, 애플리케이션과 JDBC사이에서 동작!- 대중적인 언어에는 대부분 ORM 기술이 존재
- 동작
- 저장 (Persist)
- Entity 분석
- Insert Sql 생성
- 애플리케이션과 Jdbc 간 매핑
- 조회(find)
- SELECT SQL 생성
- 애플리케이션과 Jdbc 간 매핑
- 조회된 데이터를 객체에 매핑
- 저장 (Persist)
- JPA는 표준 명세
- 인터페이스의 모음
- 표준 명세를 구현한 3가지 구현체
- 하이버네이트
- EclipseLink
- DataNucleus
- 버전 이력
- JPA 1.0 (2006) : 초기 버전, 복합 키와 연관관계 기능이 부족했음
- JPA 2.0 (2009) : 대부분의 ORM 기능을 포함 ,JPA Criteria 추가
- JPA 2.1 (2013) : 스토어드 프로시저 접근, 컨버터(Converter), 엔티
티 그래프 기능이 추가
JPA 사용 이유
탄생 배경 1탄에서 보셨다시피, SQL 중심적인 개발의 문제점과 객체 답게 모델링을 할 수록 처리해야하는 일이 너무 많아진다는 것을 볼 수 있었습니다! 이는 생산성 및 유지보수성의 저하를 이끌 수 있죠
- SQL 중심적인 개발을 벗어난 객체 중심의 개발
- 생산성
JPA가 애플리케이션과 Jdbc 사이 간, 즉 객체와 데이터베이스의 데이터 사이를 매핑하여 주기 때문에 별도의 매핑작업 없이 JPA에서 제공하는 기능만 사용하면 됩니다.
//저장
jpa.persist(member);
//조회
Member member=jpa.find(memberId)
//수정
member.serName(name);
//삭제
jpa.remmove(member);- 유지보수성
기존에는 객체의 필드 이름을 변경을 추가하거나 변경하면 모든 SQL문을 수정 해야하는 경우가 발생 했습니다.
ex)
public class Book {
private String boolId;
private Item item;
private int price;
//추가 되었다고 가정
private String name;
} #기존
select bookId,price from Book;
#필드의 추가로 인해 기존의 SQL문도 변경해줘야 처리 가능
select bookId,price,name from Book;위의 코드와 같은 문제가 발생합니다. 하지만 JPA는 SQL문을 알아서 매핑해주기 때문에 저런 고민을 할 필요가 없어집니다.
-
패러다임 불일치의 해결
- 상속
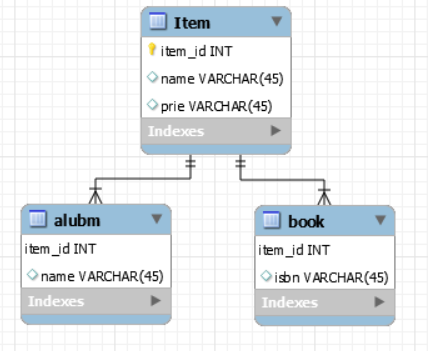
이와 같은 상속 관계에서
//저장 jpa.persist(book); //조회 jpa.find(Book.class,bookId);개발자는 이런 코드만만 쳐주시면 나머지(객체 분해,객체 생성...)는 JPA가 알아서 다 처리하여 줍니다.
- 데이테베이스에서 조회한 객체간 불일치
Book book1=bookDAO.getBook(100); Book book2=bookDAO.getBook(100); book1==book2 //기존 SQL만 이용하여 조회했을 시 달랐지만 JPA를 사용했기 때문에 같음JPA는 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장 합니다~!
- 상속
-
성능 최적화
- 1차 캐시와 동일성 보장
- 같은 트랜잭션 안에서는 같은 엔티티를 반환 - 약간의 조회 성능 향상
즉, 동일 트랜잭션 내에서 한번 SQL문으로 조회를 하면 조회한 데이터는 캐시에 저장 되므로 다음 번 조회시에는 캐시에 있는 데이터를 읽어오면 됨. SQL이 1번만 실행 된다는 뜻!
- 같은 트랜잭션 안에서는 같은 엔티티를 반환 - 약간의 조회 성능 향상
- 트랜잭션을 지원하는 쓰기 지연
- 트랜잭션을 커밋할 때 까지 INSERT SQL을 모음
- 커밋 하는 순간 UPDATE,DELETE SQL 실행, JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송
- 지연 로딩과 즉시 로딩
- 지연 로딩: 객체가 실제 사용될 때 로딩
- 즉시 로딩: JOIN SQL로 한번에 연관된 객체 까지 미리 조회
실무에서는 지연 로딩만 사용된다고 합니다.. 지연 로딩과 즉시 로딩의 예는 많은 양의 개념을 담고 있기 때문에 따로 포스팅 하도록 하겠습니다!
두 편에 걸쳐 JPA의 탄생 배경에 대하여 알아봤습니다. 이상으로 포스팅을 마치겠습니다. 감사합니다 :)
- 1차 캐시와 동일성 보장
이 글은 인프런 김영한님의 '자바 ORM 표준 JPA 프로그래밍 - 기본편'을 수강하고 작성합니다.
출처:https://www.inflearn.com/course/ORM-JPA-Basic

WEB STUDY & etc.. HELLO!