
1. 큐와 스택에 대하여 설명하시오.(필수)
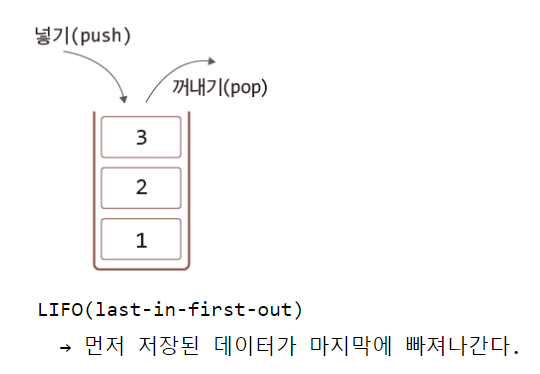
① 스택(Stack)
LIFO(last-in-first-out)
후입선출 > 먼저 저장된 데이터가 마지막에 빠져나간다.
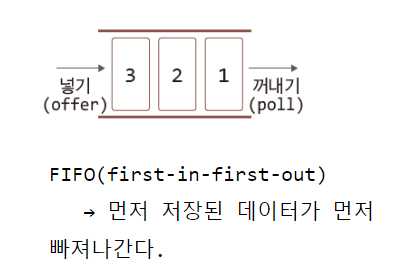
② 큐(Queue)
FIFO(first-in-first-out)
선입선출 > 먼저 저장된 데이터가 먼저 빠져나간다.
2. HashMap, TreeMap 의 차이는?
① HashMap<K, V>
HashMap<K, V> 클래스는 Iterable 인터페이스를 구현하지 않아서 for-each ,Iterator로 순차적 접근을 할 수 없다.
그래서 Key는 Set으로 관리! 키값을 기준으로 for-each, Iterator 사용함
public Set ks = map.keySet();
→ set 호출 메소드 / Key만 담고 있는 컬렉션 인스턴스 생성
② TreeMap<K, V>
Tree 자료구조 특성상 반복자가 정렬된 순서대로 key들에 접근함
(반복자의 접근 순서는 컬렉션 인스턴스에 따라 달라질 수 있다.)
3. 아래의 TreeMap의 Value를 확인 하기 위한 소스를 짜시오.(필수)
TreeMap<Integer, String> map = new TreeMap<>(); map.put(45, "Brown"); map.put(37, "James"); map.put(23, "Martin");
✅ 소스 구현
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
public class HashMapIteration {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
map.put(45, "Brown");
map.put(37, "James");
map.put(23, "Martin");
// key만 담고 있는 컬렉션 인스턴스 생성
Set<Integer> ks = map.keySet();
// 전체 key 출력 (for-each문 기반)
for(Integer n : ks) {
System.out.print(n.toString()+'\t');
}
System.out.println();
// 전체 value 출력 (for-each문 기반)
for(Integer n : ks) {
System.out.print(map.get(n).toString()+'\t');
}
System.out.println();
// 전체 value 출력 (반복자 기반)
for(Iterator<Integer> itr = ks.iterator(); itr.hasNext();) {
System.out.print(map.get(itr.next())+'\t');
}
System.out.println();
}
}4. Set 호출되는 원리와 순서를 설명하시오.
-
탐색 1단계
Object 클래스에 정의된 hashCode 메소드의 반환 값을 기반으로 부류 결정 -
탐색 2단계
선택된 부류 내에서 equals 메소드를 호출하여 동등 비교 -
따라서 동등 비교의 과정에서 hashCode 메소드의 반환 값을 근거로 탐색의 대상이
확! 줄어든다.
5. hashcode() 를 호출 하여 나오는 값은?
객체를 식별할 수 있는 고유(주소)값
6. 아래가 돌아 가도록 하시오.
HashSet<Person> hSet = new HashSet<Person>(); hSet.add(new Person("LEE", 10)); hSet.add(new Person("LEE", 10)); hSet.add(new Person("PARK", 35)); hSet.add(new Person("PARK", 35)); System.onut.println("저장된 데이터 수: " + hSet.size()); System.out.println(hSet); /* ============ 저장된 데이터 수: 2 [LEE(10세), PARK(35세)]
7.아래의 SQL 구문을 정리 하시오.
-- 사원 테이블의 사원들 중에서 커미션(COMM)을 받은 사원의 수를 구하는 쿼리문
select count(comm) from emp;
-- 사원들의 업무수
select count(distinct job) 업무수 from emp;
-- 소속 부서별 급여의 최대값을 구하는 쿼리문
select deptno, max(sal) from emp group by deptno;
-- 소속 부서별 급여 총액과 평균 급여를 구하는 쿼리문
select deptno, sum(sal),avg(sal) from emp group by deptno;
-- GROUP BY절에 명시하지 않은 컬럼을 SELECT절에 사용하지 못한다.
-- 소속 부서별 최대 급여와 최소 급여를 구하는 쿼리문
select deptno, max(sal),min(sal) from emp group by deptno;
-- 부서별 사원의 수와 커미션을 받는 사원의 수를 계산하는 쿼리문
select deptno, count(*),count(comm) from emp group by deptno;
-- 그룹 지어진 부서별 평균 급여가 2000 이상인 부서의 번호와 부서별 평균 급여를 출력하는 쿼리문
select deptno, avg(sal) from emp group by deptno having avg(sal) >= 2000;
-- 부서의 최대값과 최소값을 구하되, 최대 급여가 2900 이상인 부서만 출력하는 쿼리문
select deptno, max(sal),min(sal) from emp group by deptno having max(sal) >=2900 ;
