SQL 중심적인 개발의 문제점
- 패러다임의 불일치
- 객체 지향 : 필드와 메서드로 객체를 구성해서 사용하는 것에 초점
- 관계형DB : 데이터를 잘 정규화해서 저장하는 것에 초점
객체와 관계형 DB의 차이
1. 상속
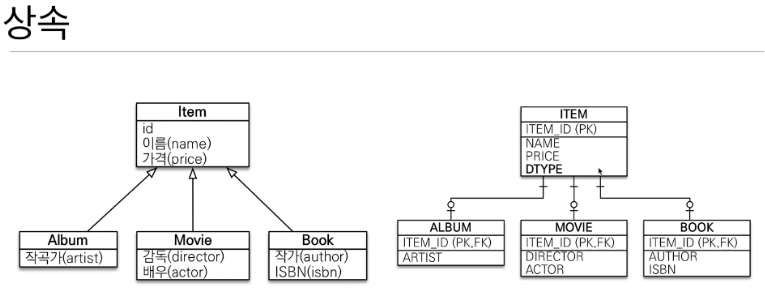
- 객체
- 저장 : 공통된 특징을 부모로 정의한 후 자식이 상속받아 특징을 가지는 필드 및 메서드 정의
- 조회 : .을 통해서 바로 접근 가능
- 관계형 DB
- 저장 : 부모와 자식을 다른 테이블로 저장
- 모든 필드가 필요한 경우 반드시 Join을 사용해야 한다.(비용 발생)
결국 객체를 효율적으로 설계해도 관계형 DB에 넣게 되면 구조적 차이 때문에 추가적인 반복된 과정이 많이 필요하다.
2. 연관관계
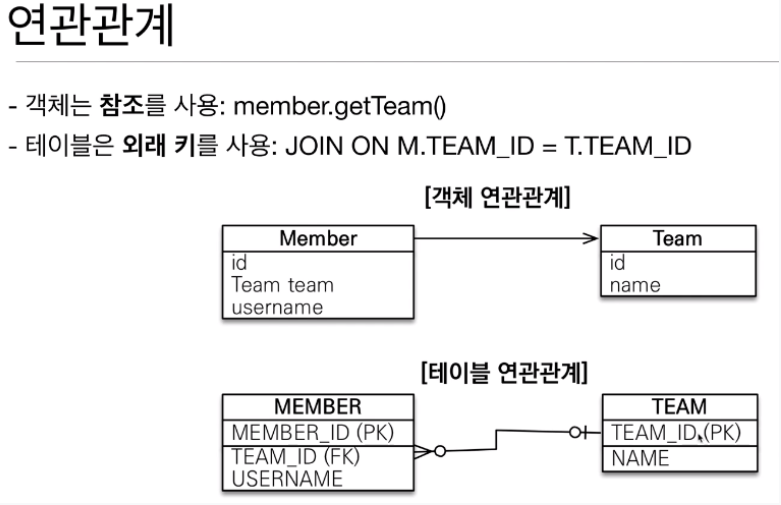
- 객체
- 한 방향으로 접근을 한다(단방향)
- 단방향이 양쪽에서 이루어줘 양방향을 만든다.
- 관계형 DB
- Key를 통해 양방향으로 접근이 가능하다.
정리
- 객체다운 모델링을 할수록 SQL 매핑 작업이 늘어난다
- 많은 Join이 발생
- SQL매핑 작업에 의한 시간이 많이 소요된다는 단점이 존재한다.
- 이러한 차이점을 극복하기 위해서 Collection에 저장하듯 하기 위한 결과물이 JPA이다.
JPA란?
- Java Persistence API
- 자바의 ORM 기술의 표준
- Object Relational Mapping : 객체는 객체대로 설계, RDB는 RDB대로 설계하도록 중간에도 도와준다.
JPA 동작 원리
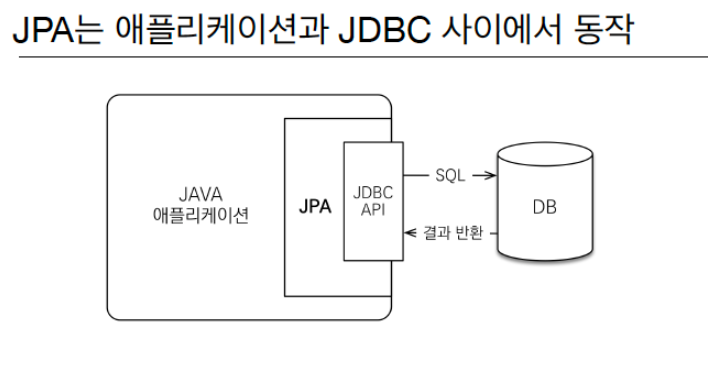
- 자바 어플리케이션과 JDBC API사이에 우리 대신 SQL Mapping과정을 수행해준다.
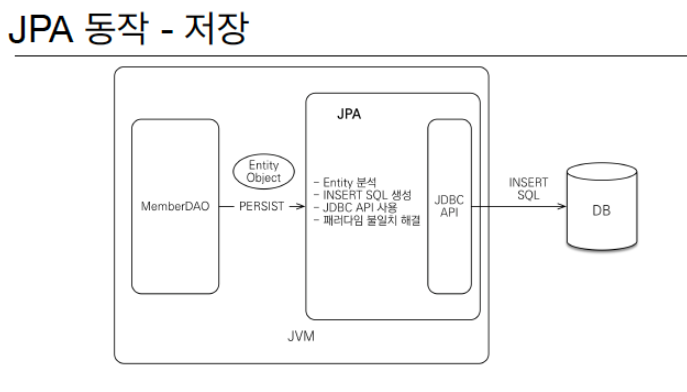
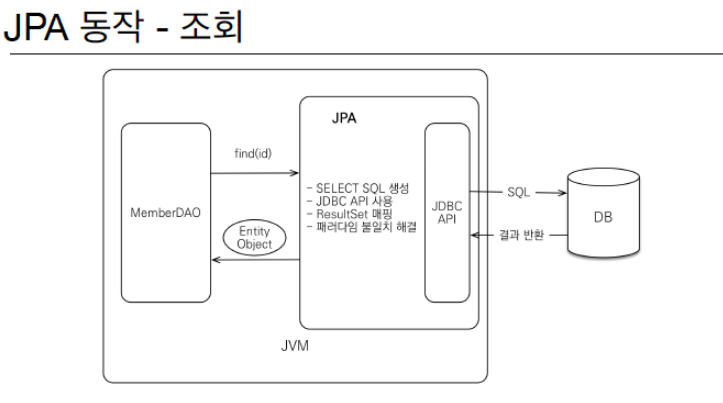
JPA를 왜 사용하는가
1. 생산성 향상
CRUD과정이 매우 간단하게 해결된다.

2. 유지보수

- DB에 column이 추가되어도 쿼리를 직접 수정할 일이 없다.
- SQL을 작성하지 않기 때문에 유지보수가 편해진다.
3. 패러다임 불일치 해결

- find()을 통해서 자식 객체의 타입을 명시해주기만 하면 JPA가 내부적으로 Join을 알아서 처리해준다.
JPA의 성능 최적화 기능
1. 1차 개시와 동일성 보장

2. 트랜잭션을 지원하는 쓰기 지연

- 특징이 비슷한 쿼리들을 모아서 한번의 처리
- 네트워크 성능 향상
3. 지연로딩 & 즉시로딩

- 지연로딩
- 참조된 객체를 실제 사용되는 시점에서 조회한다.(참조된 객체의 사용이 적을 때 효율적이다.)
- 즉시로딩
- 참조된 객체를 최초 조회시 함께 조회한다.(참조된 객체의 사용이 많을 때 효율적이다.)

https://github.com/beombu