
[OSTEP] Virtualization) 7. CPU Scheduling
이 포스팅은 Operating Systems: Three Easy Pieces, Remzi H. Arpaci-Dusseau & Andrea C. Arpaci-Dusseau을 읽고 개인 학습용으로 정리한 글입니다.
CH 7. 스케쥴링
- 스케쥴링 정책은 어떻게 개발하는가?
1. 워크로드에 대한 가정
- 워크로드(work load) : 일련의 프로세스들이 실행하는 상황

2. 스케쥴링 평가 항목
-
스케쥴링 평가 항목(scheduling metric)
-
반환 시간(turnaround time): 작업이 완료된 시각 - 작업이 시스템에 도착한 시각
T_turnaround = T_completion – T_arrival -
모든 작업은 동시에 도착한다고 가정
-> T_arrival = 0
-> T_turnaround = T_completion -
반환 시간은 성능 측면의 평가 기준
-
다른 평가 기준: 공정성(fairness)
-> 성능과 공정성은 스케쥴링에서는 서로 상충되는 목표
3. 선입선출
- 선입선출 (FIFO,First In First Out) 또는 선도착선처리(FCFS,First Come First Served)
예 1
-
3개의 작업 A, B, C 동시에 도착했다고 가정 (T_arrival = 0)
(간발의 차로 A, B, C 순서대로 도착했음) -
각 작업은 10초 동안 실행된다고 가정
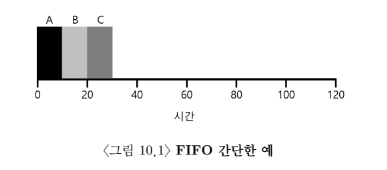
- 세 작업의 평균 반환 시간 = (10 + 20 + 30) / 3 = 20
예 2
- 작업 실행 시간이 모두 같지 않다고 가정
A는 100초, B와 C는 10초동안 실행된다

- 평균 반환 시간 = (100 + 110 + 120) / 3 = 110
convey effect
- 짧은 시간동안 자원을 사용할 프로세스들이 자원을 오랫동안 사용하는 프로세스의 종료를 기다리는 현상
4. 최단 작업 우선
- SJF(Shortest Job First): 가장 짧은 실행 시간을 가진 작업을 먼저 실행시킨다
예 1

-
평균 반환 시간 = (10 + 20 + 120)/3 = 50
-
모든 작업이 동시에 도착한다면 최적(optimal)의 스케쥴링 알고리즘
-> 평균 반환 시간 최소
예 2
- 모든 작업이 동시에 도착하는 것이 아니라 임의의 시간에 도착할 수 있다고 가정
A는 t=0, B와 C는 t=10에 도착한다
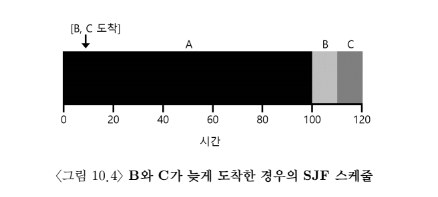
-
평균 반환 시간 (100 + (110 - 10) + (120 - 10))/ 3 = 103.33
-
convey 문제 다시 발생
5. 최소 잔여시간 우선
-
작업은 끝날 때까지 계속 실행된다는 가정을 완화해야 한다
-
최단 잔여시간 우선 (STCF,Shortest Time-to-Complete First) : SJF에 선점 기능을 추가한 스케쥴러
(선점형 최단 작업 우선(PSJF, Preemptive SJF)) -
언제든 새로운 작업이 시스템에 들어오면, 이 스케쥴러는 남아 있는 작업과 새로운 작업의 잔여 실행 시간 계산
-> 그 중 가장 적은 실행 시간을 가진 작업을 스케쥴
예
- STCF는 A를 선점하고 B와 C를 끝날 때까지 실행시킨다
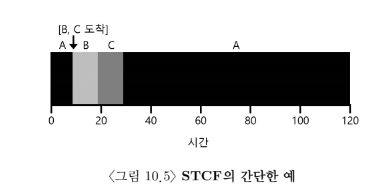
-
평균 반환 시간: ((120 – 0) + (20-10) + (30-10)) / 3 = 50
-
작업이 임의의 시간에 도착할 수 있는 경우 STCF가 최적의 스케쥴링 알고리즘
6. 새로운 평가 기준: 응답시간
-
시분할 컴퓨터의 등장 -> 사용자 터미널에서 작업
-> 시스템에게 상호작용을 원활히 하기 위한 성능을 요구 -
응답 시간(response time): 작업이 도착할 때부터 처음 스케쥴될 때까지의 시간
T_responce = T_firstrun – T_arrival
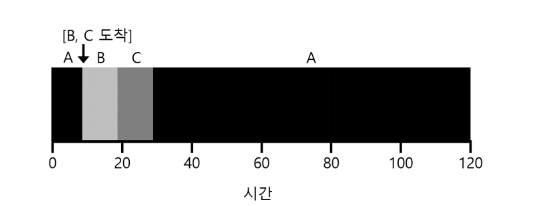
- A의 응답 시간 = 0
B의 응답 시간 = 0
C의 응답 시간 = 10
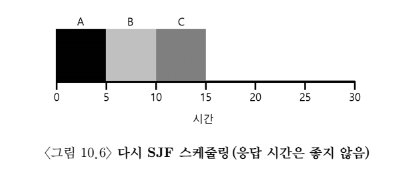
예
- 작업 실행이 같은 3개의 작업이 동시에 도착한 경우
-
세 번째 작업은 딱 한 번 스케쥴 되기 위해 먼저 실행된 두 작업이 완전히 끝날 때까지 기다린다 (STCF도 마찬가지)
-
평균 응답 시간 = (0 + 5 + 10) / 3 = 5 (bad)
7. 라운드 로빈
-
RR(Round-Robin): 작업이 끝날 때까지 기다리지 않고, 일정 시간 동안 실행한 후 실행 큐의 다음 작업으로 전환
-
타임 슬라이스(time slice) or 스케쥴링 퀀텀(scheduling quantum): 작업이 실행되는 일정 시간
-> RR은 타임 슬라이싱이라고 불리기도 함 -
타임 슬라이스의 길이는 타이머의 인터럽트 주기의 배수여야 함
-> 짧을수록 응답 시간 기준 성능 좋아짐
-> 그러나, 너무 짧으면 문맥 교환 비용이 성능에 영향
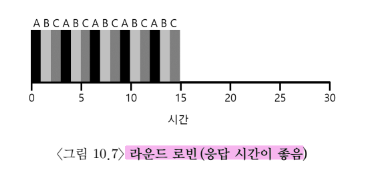
예
- 1초의 타임 슬라이스를 가지는 RR에서 작업 실행이 같은 3개의 작업이 동시에 도착한 경우
-
평균 응답시간 = (0+1+2)/3 = 1 (good)
-
평균 반환시간 = (13 + 14 + 15)/3 = 14 (bad)
-
반환 시간이 유일한 측정 기준인 경우 RR은 최악의 정책
(단순한 FIFO보다도 좋지 않음) -
일반적으로 RR과 같은 공정한 정책 (작은 시간 단위로 모든 프로세스에게 CPU를 분배하는 정책)은 반환 시간의 평가 기준에서 성능이 나쁘다
2종류의 스케쥴러
- 반환 시간을 최적화하지만 응답 시간은 나쁜 유형: SJF, STCF
- 응답 시간을 최적화하지만 반환 시간은 나쁜 유형: RR
8. 입출력 연산의 고려
-
입출력 작업을 요청한 경우: 현재 실행 중인 작업은 입출력이 완료될 때까지 CPU를 사용하지 않음
-> 입출력 완료를 기다리며 대기 상태가 됨
-> 스케쥴러는 다음에 어떤 작업을 실행할지 결정해야 -
입출력 작업이 완료된 경우: 인터럽트 발생 -> 운영체제 실행
-> 입출력을 요청한 프로세스를 대기 상태에서 준비 상태로 이동시킴
-> 스케쥴러는 다음에 어떤 작업을 실행할지 결정해야
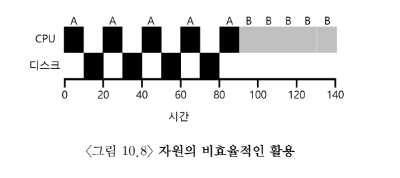
예
-
A는 10msec동안 실행된 후, 입출력 요청
(입출력 시간 10msec으로 가정) -
B는 입출력 요청을 하지 않고 50msec동안 실행
-
STCF 스케쥴러를 구축한다고 가정
-> 입출력을 고려하지 않고 작업을 하나씩 실행시키는 것은 의미 X -
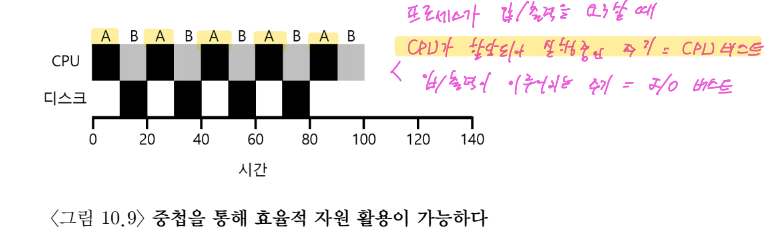
일반적인 접근 방식은 A의 각 10msec 하위 작업을 독립적인 작업으로 다루는 것
-> 10msec 작업들(A)과 50msec 작업(B)을 스케쥴
-
STCF는 가장 짧은 작업 선택 -> A 10msec동안 실행
A의 첫번째 소작업이 완료되면 A는 입출력 요청 -> B만 남게 됨 -> B 실행
A의 입출력이 완료됨 -> B를 선점하며 10msec동안 실행
A의 두번째 소작업이 완료되면 A는 입출력 요청 -> B만 남게 됨 -> B 실행
A의 입출력이 완료됨 -> B를 선점하며 10msec동안 실행
... -
CPU가 할당되어 실행중인 주기 = CPU 버스트
입출력이 이루어지는 주기 = I/O 버스트 -
각 CPU 버스트틑 하나의 작업으로 간주
-> 스케쥴러는 대화형 프로세스가 더 자주, 유리하게 실행되는 것 보장
9. 만병 통치약은 없다
-
사실 범용 운영체제에서는 작업의 길이에 대해서 알 수 없다 (= 미래를 예측할 수 없음)
-
아무런 사전 지식 없이 SJF/STCF 처럼 행동하는 알고리즘을 구축할 수 있을까?
-
응답 시간을 좋게하기 위해 RR 스케쥴러의 아이디어를 포함시킬 수 있을까?
10. 요약
-
스케쥴링의 두 가지 부류의 접근법
-> 남아있는 작업 중 실행 시간이 제일 짧은 작업을 수행시키고 반환시간을 최소화
-> 모든 작업을 번갈아 실행시키고 응답시간을 최소화 -
반환시간과 응답시간 중 하나를 최적화하면 나머지 하나는 좋지 않은 특성을 나타낸다
