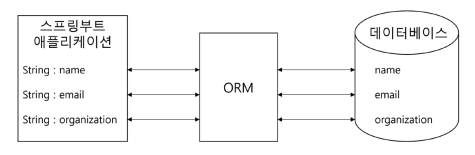
ORM
-
Object Relational Mapping의 줄임말로 객체 관계 매핑을 의미
-
RDB(Relational Database)의 테이블을 자동으로 매핑
-
클래스는 데이터베이스의 테이블과 매핑하기 위해 만들어진 것이 아니기 때문에 RDB와의 불일치와 제약사항을 해결하는 역할
[스프링부트 애플리케이션 <-> ORM <-> 데이터베이스]
🧡 ORM의 장점
-
데이터베이스 쿼리를 객체지향적으로 조작할 수 있음
-
쿼리문을 작성하는 양이 줄어들어 개발 비용이 줄어든다.
-
객체지향적으로 데이터베이스에 접근할 수 있어 코드의 가독성이 높아진다.
-
-
재사용 및 유지보수가 편리하다.
-
ORM을 통해 매핑되는 객체는 모두 독립적으로 작성되어 있어 재사용이 용이하다.
-
객체들은 각 클래스로 나뉘어 있어 유지보수가 수월하다.
-
-
데이터베이스에 대한 종속성이 줄어든다.
-
ORM을 통해 작성된 SQL문은 객체를 기반으로 데이터베이스 테이블을 관리하기에 데이터베이스에 종속적이지 않다.
-
데이터베이스를 교체하는 상황에서도 비교적 적은 리스크를 부담한다.
-
💛 ORM의 단점
-
ORM만으로 온전한 서비스를 구현하기에 한계가 명확
-
복잡한 서비스의 경우 직접 쿼리를 구현하지 않고 코드로 구현하기 어려움.
-
복잡한 쿼리를 정확한 설계 없이 ORM만으로 구성하면 속도 저하 등의 성능 문제가 발생.
-
-
애플리케이션의 객체 관점과 데이터베이스의 관계 관점의 불일치가 발생
-
세분성(Granularity) : ORM의 자동 설계 방법에 따라 데이터베이스에 있는 테이블 와 애플리케이션의 엔티티 클래스의 수가 다른 경우가 발생.(클래스가 테이블보다 많아질 수 있음)
-
RDBMS에는 상속이라는 개념이 존재하지 않음.
-
RDBMS는 primary key로 동일성을 정의하지만 자바는 두 객체의 값이 같아도 다르다고 판단할 수 있음.
-
객체지향 언어에서는 객체를 참조할 때 방향성이 존재하지만 RDBMS에서 외래키를 삽입하는 것은 양방향의 관계를 지녀 방향성이 없음.
-
자바와 RDBMS는 객체에 접근하는 방식이 다름. 자바는 객체 참조같은 연결 수단을 활용하지만 RDBMS는 조인(Join)을 통해 여러 테이블을 로드하고 값을 추출하는 방식을 채택.
-
💚 JPA
-
자바 진영의 ORM 기술 표준으로 채택된 인터페이스의 모음.
-
내부적으로 JDBC를 사용함.
-
구현체로는 하이버네이트(Hibernate), 이클립스 링크(EclipseLink), 데이터 뉴클리어스(DataNucleus)가 있고, 그 중 가장 많이 사용되는 구현체는 하이버네이트임.
💙 하이버네이트
- 자바의 ORM 프레임워크로, JPA가 정의하는 인터페이스를 구현하고 있는 JPA 구현체 중 하나.
💜 Spring Data JPA
-
JPA를 편리하게 사용할 수 있도록 지원하는 스프링 하위 프로젝트 중 하나.
-
CRUD 처리에 필요한 인터페이스 제공. 하이버네이트에서 자주 사용되는 기능을 더 쉽게 사용할 수 있게 구현한 라이브러리.
🧡 Spring Data JPA 설정 부분
build.gradle에 Spring Data JPA 의존성을 추가해준 후
application.properties 파일에 설정을 추가해준다.
// application.properties
spring.datasource.driverClassName=org.mariadb.jdbc.Driver
spring.datasource.url=jdbc:mariadb://localhost:3306/springboot
spring.datasource.username=root
spring.datasource.password=password
spring.jpa.hibernate.ddl-auto=create
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.foumat_sql=true💛 Entity 관련 기본 어노테이션
@Entity
해당 클래스가 엔티티임을 명시하기 위한 어노테이션.
@Table
클래스의 이름과 테이블의 이름을 다르게 지정해야 하는 경우 @Table(name = 값) 형태로 사용.
@Id
이 어노테이션이 선언된 필드는 테이블의 기본값 역할로 사용되므로 모든 엔티티는 @Id 어노테이션이 필요.
@GeneratedValue
일반적으로 @Id와 함께 사용되며 해당 필드의 값을 어떤 방식으로 자동으로 생성할지 결정할 때 사용.
-
사용하지 않는 방식
애플리케이션에서 자체적으로 고유한 기본값을 생성할 경우 사용하는 방식. -
AUTO
기본값을 사용하는 데이터베이스에 맞게 자동 생성. -
IDENTITY
기본값 생성을 데이터베이스에 위임. -
SEQUENCE
@SequenceGenerator 어노테이션으로 식별자 생성기를 설정하고 이를 통해 값을 자동 주입받음. -
TABLE
어떤 DBMS를 사용하더라도 동일하게 동작하기를 원할 경우 사용. 식별자로 사용할 숫자의 보관 테이블을 별도로 생성하여 엔티티를 생성할 때마다 값을 갱신하며 사용.
@Column
필드에 몇 가지 설정을 더할 때 사용.
@Transient
엔티티 클래스에는 선언돼 있는 필드지만 데이터베이스에서는 필요 없을 경우 사용해 데이터베이스에서 이용하지 않게 할 수 있음.
💚 리포지토리 메서드 생성 규칙
-
FindBy : SQL문의 where절 역할을 수행.
예) findByName(String name) -
AND, OR : 조건을 여러 개 설정하기 위해 사용
예) findByNameAndEmail(String name, String email) -
Like / NotLike : SQL문의 like와 동일한 기능을 수행.
-
StartsWith / StartingWith : 특정 키워드로 시작하는 문자열 조건 설정.
-
EndsWith / EndingWith : 특정 키워드로 끝나는 문자열 조건 설정.
-
IsNull / IsNotNull : 레코드 값이 Null이거나 Null이 아닌 값을 검색.
-
True / False : Boolean 타입의 레코드를 검색할 때 사용.
-
Before / After : 시간을 기준으로 값을 검색.
-
LessThan / GreaterThan : 특정 값(숫자)을 기준으로 대소 비교를 할 때 사용
-
Between : 두 값(숫자) 사이의 데이터를 조회.
-
OrderBy : Sql문에서 order by와 동일한 기능 수행.
-
countBy : Sql문의 count와 동일한 기능을 수행.
Lombok
롬복은 데이터 클래스를 생성할 때 반복적으로 사용하는 getter/setter과 같은 메서드를 어노테이션으로 대체하는 기능을 제공하는 라이브러리.
💙 Lombok의 장점
-
어노테이션을 기반으로 코드를 자동 생성하므로 생산성이 높아짐.
-
반복되는 코드를 생략할 수 있어 가독성이 좋아짐.
-
롬복을 안다면 간단하게 코드를 유추할 수 있어 유지보수에 용이함.
💔 코드가 어노테이션을 자동 생성하기 때문에 메서드를 개발자의 의도대로 정확하게 구현하지 못해 좋아하지 않는 개발자도 존재함.
@EqualsAndHashCode
객체의 동등성과 동일성을 비교하는 연산 메서드를 생성한다.
-
equals : 두 객체의 내용이 같은지 동등성을 비교한다.
-
hashCode : 두 객체가 같은 객체인지 동일성을 비교한다.
❗동등성과 동일성
동일성 : 객체가 가진 값과 가리키는 주소가 전부 같아 두 객체가 완전히 같음.
동등성 : 두 객체가 같은 값을 갖고 있지만 가리키는 주소는 다름.
@Data
@Getter + @Setter + @RequiredArgsConstructer + @ToString + @EqualsAndHashCode를 한 번에 생성 가능하다.
